Diagnosticare e risolvere i problemi di Azure Cosmos DB relativi alla frequenza troppo elevata delle richieste (eccezioni 429)
SI APPLICA A: ![]() NoSQL
NoSQL
Questo articolo contiene cause note e soluzioni per vari errori con codice di stato 429 per l'API per NoSQL. Se si usa l'API per MongoDB, vedere l'articolo Risolvere problemi comuni nell'API per MongoDB per informazioni su come eseguire il debug del codice di stato 16500.
Un'eccezione "La frequenza delle richieste è troppo elevata", nota anche come codice errore 429, indica che la frequenza delle richieste in Azure Cosmos DB viene limitata.
Quando si usa la velocità effettiva con provisioning, si imposta la velocità effettiva, misurata in unità richiesta al secondo (UR/s), necessaria per il carico di lavoro in corso. Ogni operazione di database eseguita sul servizio, ad esempio letture, scritture e query, utilizza una determinata quantità di unità richiesta (UR). Altre informazioni sulle unità richiesta.
In un determinato secondo, se le operazioni utilizzano più unità richiesta di quelle di cui è stato effettuato il provisioning, Azure Cosmos DB restituirà un'eccezione 429. Ogni secondo, viene reimpostato il numero di unità richiesta disponibili per l'uso.
Prima di intervenire per modificare le UR/s, è importante comprendere la causa radice della limitazione della frequenza e risolvere il problema sottostante.
Suggerimento
Le indicazioni contenute in questo articolo si applicano ai database e ai contenitori che usano la velocità effettiva con provisioning, sia quella con scalabilità automatica che manuale.
Diversi messaggi di errore corrispondono a tipi diversi di eccezioni 429:
- La frequenza delle richieste è troppo elevata. Potrebbero essere necessarie più unità richiesta, quindi non sono state apportate modifiche.
- La richiesta non è stata completata a causa di una frequenza elevata di richieste di metadati.
- La richiesta non è stata completata a causa di un errore temporaneo del servizio.
La frequenza delle richieste è troppo elevata
Questo è lo scenario più comune. Si verifica quando le unità richiesta utilizzate dalle operazioni sui dati superano il numero di UR/s con provisioning. Se si usa la velocità effettiva manuale, questo errore si verifica quando si utilizzano più UR/s rispetto alla velocità effettiva manuale di cui è stato effettuato il provisioning. Se si usa la scalabilità automatica, questo errore si verifica quando sono state utilizzate più UR/s del numero massimo di cui è stato effettuato il provisioning. Ad esempio, se è stato effettuato il provisioning di una risorsa con velocità effettiva manuale pari a 400 UR/s, si genererà un errore 429 quando si utilizzano più di 400 unità richiesta in un secondo. Se è stato effettuato il provisioning di una risorsa con numero massimo di UR/s con scalabilità automatica pari a 4.000 UR/s (scalabilità compresa tra 400 UR/s e 4.000 UR/s), verranno visualizzate risposte 429 quando si usano più di 4.000 unità richiesta in un secondo.
Suggerimento
Tutte le operazioni vengono addebitate in base al numero di risorse utilizzate. Questi addebiti vengono misurati in unità richiesta. Includono richieste che non vengono completate correttamente a causa di errori dell'applicazione, ad esempio 400, 412, 449 e così via. Quando si considera la limitazione o l'utilizzo, è consigliabile esaminare se alcuni modelli sono cambiati nell'utilizzo, con conseguente aumento delle operazioni. In particolare, verificare la presenza di tag 412 o 449 (conflitto effettivo).
Per altre informazioni sulla velocità effettiva con provisioning, vedere Velocità effettiva con provisioning in Azure Cosmos DB.
Passaggio 1: Controllare le metriche per determinare la percentuale di richieste con errore 429
La visualizzazione di messaggi di errore 429 non significa necessariamente che si sia verificato un problema con il database o il contenitore. Una piccola percentuale di risposte 429 è normale se si usa la velocità effettiva manuale o con scalabilità automatica e indica che si stanno ottimizzando le UR/s di cui è stato effettuato il provisioning.
Come indagare
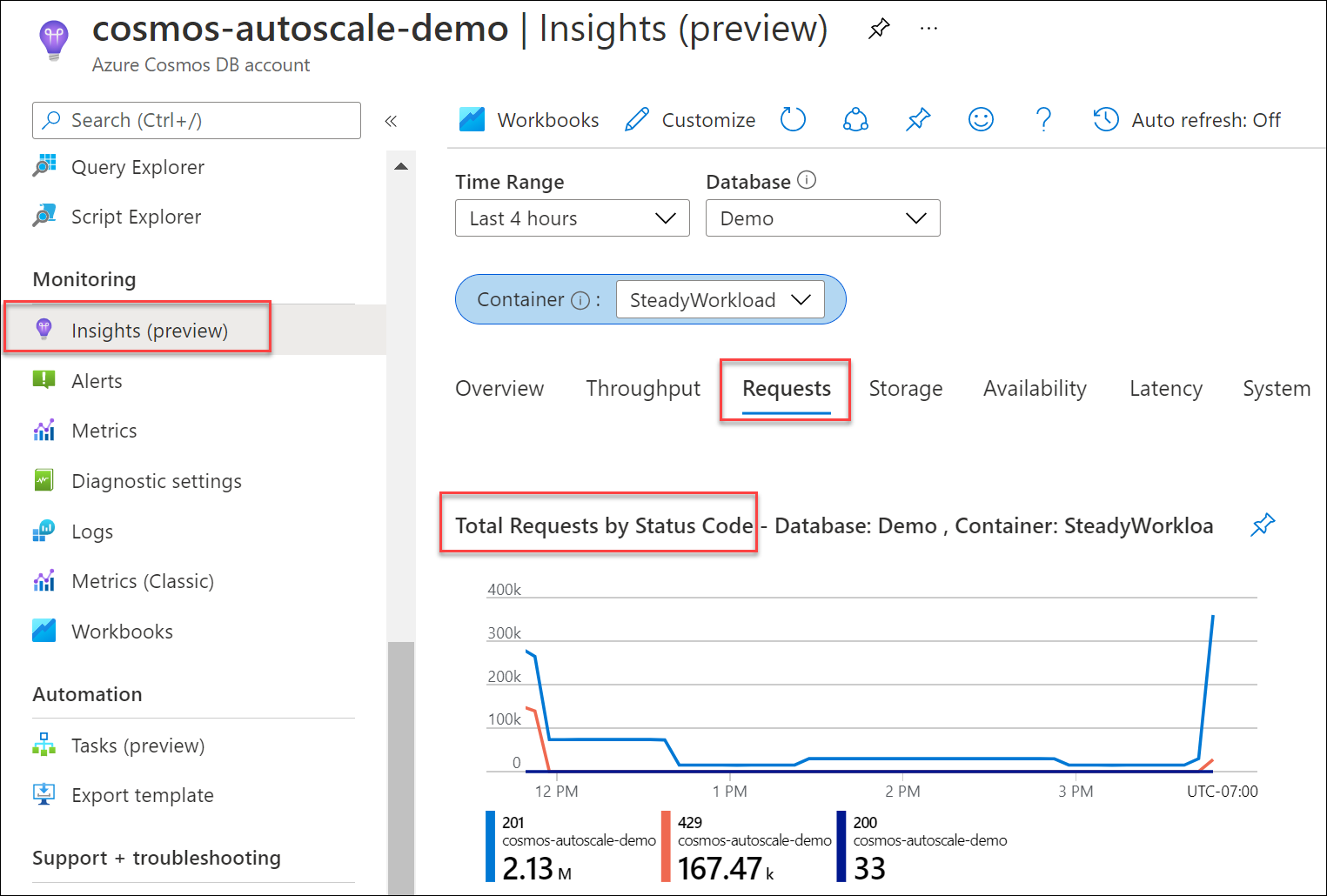
Determinare la percentuale di richieste inviate al database o al contenitore che ha generato risposte 429 rispetto al numero complessivo di richieste riuscite. Dall'account Azure Cosmos DB passare a Informazioni dettagliate>Richieste>Totale richieste per codice di stato. Filtrare in base a un database e a un contenitore specifico.
Per impostazione predefinita, gli SDK client di Azure Cosmos DB e gli strumenti di importazione dei dati quali Azure Data Factory e la libreria di esecuzione bulk ritentano automaticamente le richieste in caso di codice di stato 429. In genere riprovano fino a nove volte. Di conseguenza, anche se nelle metriche potrebbero essere visualizzate risposte 429, questi errori potrebbero persino non essere stati restituiti all'applicazione.
Soluzione consigliata
In generale, per un carico di lavoro di produzione, se tra l'1 e il 5% delle richieste genera risposte 429 e la latenza end-to-end è accettabile, si tratta di un segno positivo che indica che le UR/s vengono completamente usate. Non è necessaria alcuna azione. In caso contrario, passare alla procedura di risoluzione dei problemi successiva.
Importante
Questo intervallo tra l'1% e il 5% presuppone che le partizioni dell'account vengano distribuite in modo uniforme. Se le partizioni non vengono distribuite uniformemente, la partizione del problema potrebbe restituire un numero elevato di errori 429, mentre la frequenza complessiva potrebbe essere bassa.
Se si usa la scalabilità automatica, è possibile visualizzare risposte 429 nel database o nel contenitore, anche se le UR/s non sono state dimensionate fino al numero massimo di UR/s. Per una spiegazione, vedere la sezione La frequenza delle richieste è elevata con la scalabilità automatica.
Una domanda che generalmente viene posta è "Perché le risposte 429 vengono visualizzate nelle metriche di Monitoraggio di Azure, ma non nel monitoraggio dell'applicazione?" Se le metriche di Monitoraggio di Azure mostrano che sono presenti risposte 429, ma queste non sono state visualizzate nell'applicazione, il motivo è che per impostazione predefinita, gli SDK client di Azure Cosmos DB automatically retried internally on the 429 responses e la richiesta ha avuto esito positivo nei tentativi successivi. Di conseguenza, il codice di stato 429 non viene restituito all'applicazione. In questi casi, la frequenza complessiva di risposte 429 è in genere minima e può essere tranquillamente ignorata, presupponendo che la frequenza complessiva sia compreso tra l'1% e il 5% e la latenza end-to-end sia accettabile per l'applicazione.
Passaggio 2: Determinare la presenza di una partizione ad accesso frequente
Una partizione ad accesso frequente si genera quando una o alcune chiavi della partizione logica utilizzano una quantità sproporzionata di UR/s totali a causa di un maggior volume di richieste. Ciò può essere causato da una progettazione della chiave di partizione che non distribuisce uniformemente le richieste e comporta l'indirizzamento di molte richieste a un piccolo subset di partizioni logiche (incluse le partizioni fisiche) che diventano "ad accesso frequente". Poiché tutti i dati di una partizione logica si trovano in una partizione fisica e le UR/s totali vengono distribuite uniformemente tra le partizioni fisiche, una partizione ad accesso frequente può portare a risposte 429 e a un uso inefficiente della velocità effettiva.
Ecco alcuni esempi di strategie di partizionamento che portano a partizioni ad accesso frequente:
- L'utente ha un contenitore che archivia i dati dei dispositivi IoT per un carico di lavoro con un numero elevato di operazioni di scrittura partizionate per
date. Tutti i dati per una singola data si trovano nella stessa partizione logica e fisica. Poiché tutti i dati scritti ogni giorno hanno la stessa data, si ottiene una partizione ad accesso frequente quotidiana.- Per questo scenario, invece, una chiave di partizione come
id(un GUID o un ID dispositivo) o una chiave di partizione sintetica che combinaidedateprodurrebbe una cardinalità più elevata di valori e una migliore distribuzione del volume di richieste.
- Per questo scenario, invece, una chiave di partizione come
- L'utente ha uno scenario multi-tenant con un contenitore partizionato per
tenantId. Se un tenant è molto più attivo rispetto agli altri, viene restituita una partizione ad accesso frequente. Ad esempio, se il tenant più grande ha 100.000 utenti, ma la maggior parte dei tenant ha meno di 10 utenti, si avrà una partizione ad accesso frequente se partizionata pertenantID.- Per questo scenario precedente, prendere in considerazione la possibilità di avere un contenitore dedicato per il tenant più grande, partizionato in base a una proprietà più granulare, ad esempio
UserId.
- Per questo scenario precedente, prendere in considerazione la possibilità di avere un contenitore dedicato per il tenant più grande, partizionato in base a una proprietà più granulare, ad esempio
Come identificare la partizione ad accesso frequente
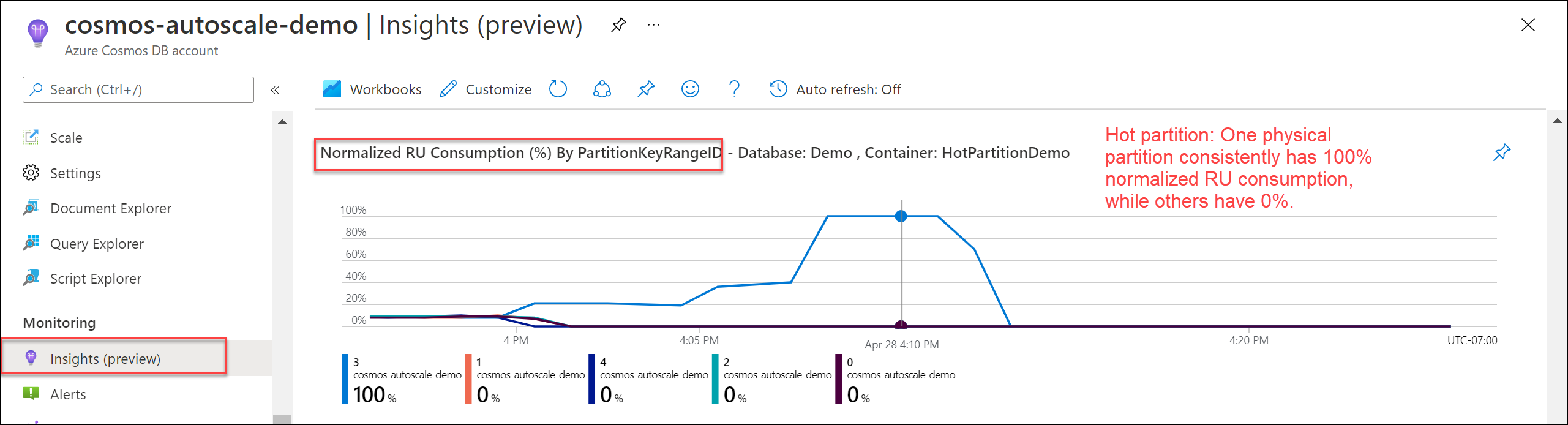
Per verificare la presenza di una partizione ad accesso frequente, passare a Informazioni dettagliate>Velocità effettiva>Consumo UR normalizzato (%) per PartitionKeyRangeID. Filtrare in base a un database e a un contenitore specifico.
Ogni PartitionKeyRangeId esegue il mapping in una partizione fisica. Se è presente un PartitionKeyRangeId che ha un consumo di UR normalizzato molto più elevato rispetto agli altri (ad esempio, uno è sempre al 100%, ma gli altri sono al 30% o meno), questo può essere un segno di una partizione ad accesso frequente. Altre informazioni sulla metrica Consumo UR normalizzato.
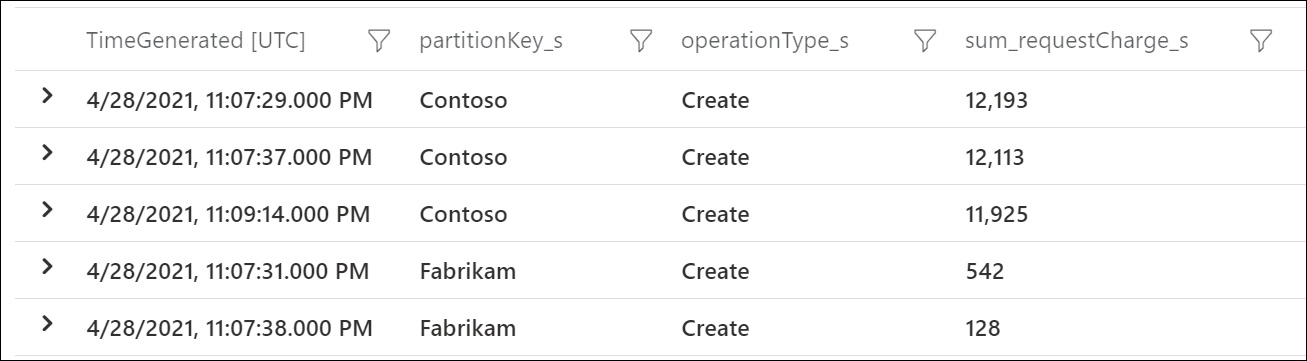
Per vedere quali chiavi della partizione logiche utilizzano la maggior parte delle UR/s, usare i log di diagnostica di Azure. Questa query di esempio somma le unità richiesta totali utilizzate al secondo in ogni chiave di partizione logica.
Importante
L'abilitazione dei log di diagnostica comporta un addebito separato per il servizio Log Analytics, che viene fatturato in base al volume dei dati inseriti. È consigliabile attivare i log di diagnostica per un periodo di tempo limitato per il debug e disattivarli quando non sono più necessari. Per informazioni dettagliate, vedere la pagina dei prezzi.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= ago(24hour)
| where CollectionName == "CollectionName"
| where isnotempty(PartitionKey)
// Sum total request units consumed by logical partition key for each second
| summarize sum(RequestCharge) by PartitionKey, OperationName, bin(TimeGenerated, 1s)
| order by sum_RequestCharge desc
Questo output di esempio mostra che in un determinato momento la chiave di partizione logica con valore "Contoso" ha utilizzato circa 12.000 UR/s, mentre la chiave di partizione logica con valore "Fabrikam" ha utilizzato meno di 600 UR/s. La coerenza di questo modello durante il periodo di tempo in cui si è verificata la limitazione della frequenza indica una partizione ad accesso frequente.
Suggerimento
In un carico di lavoro qualsiasi, ci sarà una variazione naturale del volume delle richieste tra partizioni logiche. È necessario determinare se la partizione ad accesso frequente è causata da un indice di asimmetria fondamentale causato dalla scelta della chiave di partizione (che potrebbe richiedere la modifica della chiave) o da un picco temporaneo dovuto a variazioni naturali nei modelli del carico di lavoro.
Soluzione consigliata
Esaminare le indicazioni su come scegliere una chiave di partizione valida.
Se è presente una percentuale elevata di richieste limitate e nessuna partizione ad accesso frequente:
- È possibile aumentare le UR/s nel database o nel contenitore usando gli SDK client, il portale di Azure, PowerShell, l'interfaccia della riga di comando o il modello di Resource Manager. Seguire le procedure consigliate per il dimensionamento della velocità effettiva con provisioning (UR/s) per determinare il numero corretto di UR/s da impostare.
Se c'è una percentuale elevata di richieste limitate e c'è una partizione ad accesso frequente sottostante:
- A lungo termine, per ottenere costi e prestazioni ottimali, prendere in considerazione la modifica della chiave di partizione. La chiave di partizione non può essere aggiornata sul posto, pertanto è necessario eseguire la migrazione dei dati in un nuovo contenitore con una chiave di partizione diversa. A questo scopo Azure Cosmos DB supporta uno strumento di migrazione dei dati in tempo reale.
- A breve termine, è possibile aumentare temporaneamente le UR/s complessive della risorsa per consentire una maggiore velocità effettiva nella partizione ad accesso frequente. Non è consigliabile adottare questa strategia a lungo termine, perché comporta un provisioning eccessivo delle UR/s e un costo più elevato.
- A breve termine, è possibile usare la funzionalità di ridistribuzione della velocità effettiva tra partizioni (anteprima) per assegnare più UR/s alla partizione fisica ad accesso frequente. Questa operazione è consigliata solo quando la partizione fisica ad accesso frequente è prevedibile e coerente.
Suggerimento
Quando si aumenta la velocità effettiva, l'operazione di aumento delle prestazioni viene completata istantaneamente o richiede fino a 5-6 ore per il completamento, a seconda del numero di UR/s che si vuole raggiungere. Se si vuole conoscere il numero massimo di UR/s che è possibile impostare senza attivare l'operazione asincrona di aumento delle prestazioni (che richiede ad Azure Cosmos DB di effettuare il provisioning di più partizioni fisiche), moltiplicare il numero di diversi PartitionKeyRangeId per 10.000 UR/s. Ad esempio, se è stato effettuato il provisioning di 30.000 UR/s e 5 partizioni fisiche (6.000 UR/s allocate per partizione fisica), è possibile passare a 50.000 UR/s (10.000 UR/s per partizione fisica) in un'operazione di aumento istantaneo delle prestazioni. Superare le 50.000 UR/s richiede un'operazione asincrona di aumento delle prestazioni. Seguire le procedure consigliate per il dimensionamento della velocità effettiva con provisioning (UR/s).
Passaggio 3: Determinare quali richieste restituiscono risposte 429
Come analizzare le richieste con risposte 429
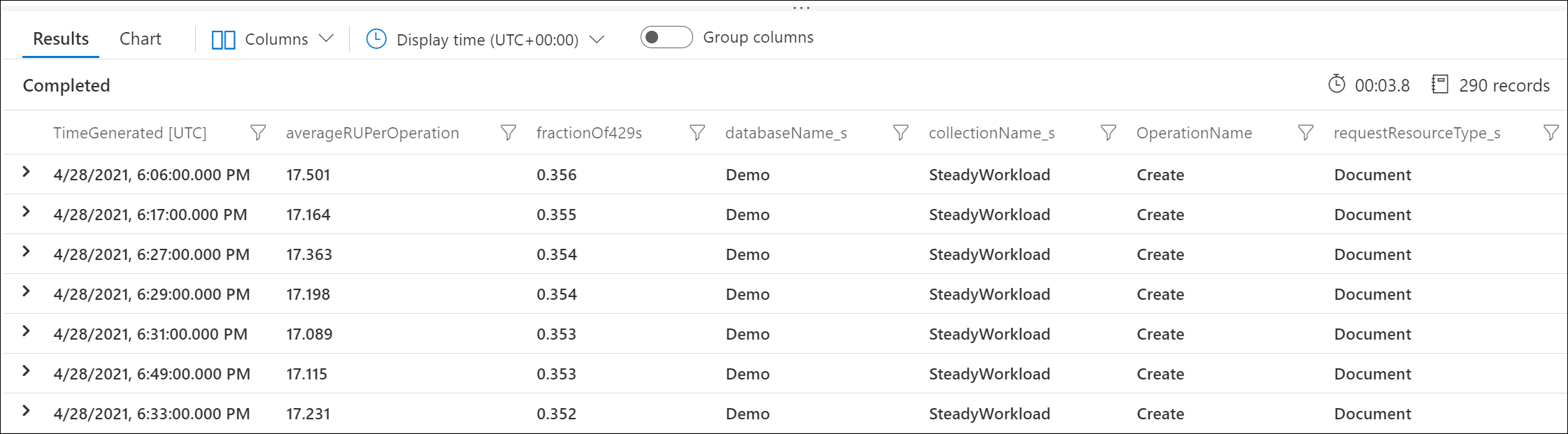
Usare i log di diagnostica di Azure per identificare le richieste che restituiscono risposte 429 e il numero di UR utilizzate. Questa query di esempio esegue l'aggregazione a livello di minuto.
Importante
L'abilitazione dei log di diagnostica comporta un addebito separato per il servizio Log Analytics, che viene fatturato in base al volume dei dati inseriti. È consigliabile attivare i log di diagnostica per un periodo di tempo limitato per il debug e disattivarli quando non sono più necessari. Per informazioni dettagliate, vedere la pagina dei prezzi.
CDBDataPlaneRequests
| where TimeGenerated >= ago(24h)
| summarize throttledOperations = dcountif(ActivityId, StatusCode == 429), totalOperations = dcount(ActivityId), totalConsumedRUPerMinute = sum(RequestCharge) by DatabaseName, CollectionName, OperationName, RequestResourceType, bin(TimeGenerated, 1min)
| extend averageRUPerOperation = 1.0 * totalConsumedRUPerMinute / totalOperations
| extend fractionOf429s = 1.0 * throttledOperations / totalOperations
| order by fractionOf429s desc
Ad esempio, questo output di esempio mostra che ogni minuto, il 30% delle richieste di creazione dei documenti veniva limitato e che ogni richiesta utilizzava in media 17 UR.
Soluzione consigliata
Uso dello strumento di pianificazione della capacità di Azure Cosmos DB
È possibile usare lo strumento di pianificazione della capacità di Azure Cosmos DB per comprendere qual è la velocità effettiva con provisioning migliore in base al carico di lavoro (volume e tipo di operazioni e dimensioni dei documenti). È possibile personalizzare ulteriormente i calcoli fornendo dati di esempio per ottenere una stima più accurata.
Risposte 429 per richieste di creazione, sostituzione o upsert dei documenti
- Per impostazione predefinita, nell'API per NoSQL tutte le proprietà vengono indicizzate per impostazione predefinita. Ottimizzare i criteri di indicizzazione per indicizzare solo le proprietà necessarie. Ciò ridurrà le unità richiesta necessarie per ogni operazione di creazione del documento, riducendo così la probabilità di visualizzare risposte 429 o consentendo di ottenere un numero maggiore di operazioni al secondo per la stessa quantità di UR/s con provisioning.
Risposte 429 alle richieste di query sui documenti
- Seguire le indicazioni per risolvere i problemi relativi alle query con un addebito elevato di UR
Risposte 429 sulle stored procedure di esecuzione
- Le stored procedure sono destinate a operazioni che richiedono transazioni di scrittura in un valore della chiave di partizione. Non è consigliabile usare le stored procedure per un numero elevato di operazioni di lettura o query. Per ottenere prestazioni ottimali, è consigliabile eseguire queste operazioni di lettura o query sul lato client usando Azure Cosmos DB SDK.
La frequenza delle richieste è elevata con la scalabilità automatica
Tutte le indicazioni contenute in questo articolo si applicano sia alla velocità effettiva manuale che alla velocità effettiva con scalabilità automatica.
Quando si usa la scalabilità automatica, una domanda che generalmente viene posta è "È ancora possibile visualizzare risposte 429 con la scalabilità automatica?"
Sì. Gli scenari principali in cui ciò può verificarsi sono due.
Scenario 1: quando le UR/s utilizzate superano il numero massimo di UR/s del database o del contenitore, il servizio limita le richieste di conseguenza. Questo avviene anche quando si supera la velocità effettiva complessiva con provisioning manuale di un database o di un contenitore.
Scenario 2: nel caso di una partizione ad accesso frequente, ovvero se un valore di chiave di partizione logica ha una quantità di richieste sproporzionatamente più elevata rispetto ad altri valori di chiave di partizione, è possibile che la partizione fisica sottostante superi il budget di UR/s. Come procedura consigliata, per evitare partizioni con accesso frequente, scegliere una chiave di partizione adeguata che comporti una distribuzione uniforme sia dello spazio di archiviazione che della velocità effettiva. Questo avviene anche quando è presente una partizione ad accesso frequente quando si usa la velocità effettiva manuale.
Se ad esempio si seleziona l'opzione di velocità effettiva massima di 20.000 UR/s e si hanno 200 GB di spazio di archiviazione, con quattro partizioni fisiche, ogni partizione fisica può essere ridimensionata automaticamente fino a 5.000 UR/s. Se in una determinata chiave di partizione logica è presente una partizione ad accesso frequente, vengono visualizzate risposte 429 quando la partizione fisica sottostante in cui risiede supera 5.000 UR/s, ovvero supera il 100% di utilizzo normalizzato.
Seguire le indicazioni riportate nel Passaggio 1, nel Passaggio 2 e nel Passaggio 3 per eseguire il debug di questi scenari.
Un'altra domanda che generalmente viene posta è Perché il consumo di UR normalizzato è al 100%, ma la scalabilità automatica non è stata dimensionata in base al numero massimo di UR/s?
Ciò si verifica in genere per i carichi di lavoro con picchi di utilizzo temporanei o intermittenti. Quando si usa la scalabilità automatica, Azure Cosmos DB dimensiona solo le UR/s fino alla velocità effettiva massima quando il consumo normalizzato di UR è del 100% per un periodo di tempo costante e continuo in un intervallo di 5 secondi. Questa operazione viene eseguita per garantire che la logica di dimensionamento sia conveniente per l'utente, in quanto garantisce che i singoli picchi momentanei non portino a un dimensionamento non necessario e a costi più elevati. Quando si verificano picchi momentanei, il sistema in genere aumenta le prestazioni fino a un valore superiore a quello delle UR/s raggiunto precedentemente, ma inferiore al numero massimo di UR/s. Altre informazioni su come interpretare la metrica di consumo normalizzato di UR con scalabilità automatica.
Limitazione della frequenza sulle richieste di metadati
La limitazione della frequenza dei metadati può verificarsi quando si esegue un volume elevato di operazioni di metadati sui database e/o i contenitori. Le operazioni sui metadati includono:
- Creare, leggere, aggiornare o eliminare un contenitore o un database
- Elencare database o contenitori in un account Azure Cosmos DB
- Eseguire una query per offerte per visualizzare la velocità effettiva con provisioning corrente
Esiste un limite di UR riservate al sistema per queste operazioni, quindi l'aumento delle UR/s con provisioning del database o del contenitore non avrà alcun impatto e non è consigliato. Consultare i limiti del servizio del piano di controllo.
Come indagare
Passare a Informazioni dettagliate>Sistema>Richieste di metadati per codice di stato. Filtrare in base a un database e a un contenitore specifico, se desiderato.
Soluzione consigliata
Se l'applicazione deve eseguire operazioni sui metadati, prendere in considerazione l'implementazione di un criterio di backoff per inviare le richieste a una velocità inferiore.
Usare istanze di client statiche di Azure Cosmos DB. Quando DocumentClient o CosmosClient viene inizializzato, Azure Cosmos DB SDK recupera i metadati relativi all'account, incluse le informazioni sul livello di coerenza, sui database, sui contenitori, sulle partizioni e sulle offerte. Questa inizializzazione può consumare un numero elevato di UR e non dovrebbe essere eseguita di frequente. Usare una sola istanza DocumentClient per tutta la durata dell'applicazione.
Memorizzare nella cache i nomi dei database e dei contenitori. Recuperare i nomi dei database e dei contenitori dalla configurazione oppure memorizzarli nella cache all'avvio. Chiamate come ReadDatabaseAsync/ReadDocumentCollectionAsync o CreateDatabaseQuery/CreateDocumentCollectionQuery causeranno chiamate al servizio che utilizzeranno il limite di UR riservate al sistema. Queste operazioni devono essere eseguite raramente.
Limitazione della frequenza a causa di un errore temporaneo del servizio
L'errore 429 viene restituito quando la richiesta rileva un errore di servizio temporaneo. L'aumento delle UR del database o del contenitore non avrà alcun impatto ed è sconsigliato.
Soluzione consigliata
ripetere la richiesta. Se l'errore persiste per alcuni minuti, inviare un ticket di supporto dal portale di Azure.
Passaggi successivi
- Monitorare il consumo di UR/s normalizzato del database o del contenitore.
- Diagnosticare e risolvere i problemi che si verificano durante l'uso di .NET SDK di Azure Cosmos DB.
- Informazioni relative alle linee guida sulle prestazioni per .NET v3 e .NET v2.
- Diagnosticare e risolvere i problemi che si verificano durante l'uso di Java v4 SDK di Azure Cosmos DB.
- Informazioni relative alle linee guida sulle prestazioni per Java v4 SDK.