Informazioni di riferimento sullo schema di configurazione di Generatore API dati
Il motore del generatore di API dati richiede un file di configurazione. Il file di configurazione di Generatore API dati offre un approccio strutturato e completo per configurare l'API, illustrando in dettaglio tutti gli elementi, dalle variabili di ambiente alle configurazioni specifiche dell'entità. Questo documento in formato JSON inizia con una proprietà $schema. Questa configurazione convalida il documento.
Le proprietà database-type e connection-string garantire una perfetta integrazione con i sistemi di database, dal database SQL di Azure all'API NoSQL di Cosmos DB.
Il file di configurazione può includere opzioni come:
- Informazioni di connessione e servizio di database
- Opzioni di configurazione globali e di runtime
- Set di entità esposte
- Metodo di autenticazione
- Regole di sicurezza necessarie per accedere alle identità
- Regole di mapping dei nomi tra API e database
- Relazioni tra entità che non possono essere dedotti
- Funzionalità univoche per servizi di database specifici
Panoramica della sintassi
Ecco una rapida suddivisione delle "sezioni" primarie in un file di configurazione.
{
"$schema": "...",
"data-source": { ... },
"data-source-files": [ ... ],
"runtime": {
"rest": { ... },
"graphql": { .. },
"host": { ... },
"cache": { ... },
"telemetry": { ... },
"pagination": { ... }
}
"entities": [ ... ]
}
Proprietà di primo livello
Ecco la descrizione delle proprietà di primo livello in un formato di tabella:
| Proprietà | Descrizione |
|---|---|
| $schema | Specifica lo schema JSON per la convalida, assicurando che la configurazione sia conforme al formato richiesto. |
| origine dati | Contiene i dettagli sul tipo di database e sulla stringa di connessione , necessario per stabilire la connessione al database. |
| file di origine dati | Matrice facoltativa che specifica altri file di configurazione che potrebbero definire altre origini dati. |
| di runtime | Configura i comportamenti e le impostazioni di runtime, incluse le sottoproprietà per REST, GraphQL, host, cachee telemetria. |
| entità | Definisce il set di entità (tabelle di database, viste e così via) esposte tramite l'API, inclusi i mapping , le autorizzazioni e le relazioni . |
Configurazioni di esempio
Ecco un file di configurazione di esempio che include solo le proprietà necessarie per una singola entità semplice. Questo esempio è progettato per illustrare uno scenario minimo.
{
"$schema": "https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json",
"data-source": {
"database-type": "mssql",
"connection-string": "@env('SQL_CONNECTION_STRING')"
},
"entities": {
"User": {
"source": "dbo.Users",
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
]
}
}
}
Per un esempio di scenario più complesso, vedere la configurazione di esempio end-to-end .
Ambienti
Il file di configurazione del generatore di API dati può supportare scenari in cui è necessario supportare più ambienti, in modo analogo al file di appSettings.json in ASP.NET Core. Il framework fornisce tre valori di ambiente comuni ; Development, Staginge Production; ma è possibile scegliere di usare qualsiasi valore di ambiente scelto. L'ambiente usato dal generatore di API dati deve essere configurato usando la variabile di ambiente DAB_ENVIRONMENT.
Si consideri un esempio in cui si vuole una configurazione di base e una configurazione specifica dello sviluppo. Questo esempio richiede due file di configurazione:
| Ambiente | |
|---|---|
| dab-config.json | Base |
| dab-config.Development.json | Sviluppo |
Per usare la configurazione specifica dello sviluppo, è necessario impostare la variabile di ambiente DAB_ENVIRONMENT su Development.
I file di configurazione specifici dell'ambiente sostituiscono i valori delle proprietà nel file di configurazione di base. In questo esempio, se il valore connection-string è impostato in entrambi i file, viene usato il valore del file *.Development.json.
Fare riferimento a questa matrice per comprendere meglio quale valore viene usato a seconda della posizione in cui tale valore viene specificato (o non specificato) in entrambi i file.
| specificato nella configurazione di base | Non specificato nella configurazione di base | |
|---|---|---|
| specificato nella configurazione dell'ambiente corrente | Ambiente corrente | Ambiente corrente |
| Non specificato nella configurazione dell'ambiente corrente | Base | Nessuno |
Per un esempio di uso di più file di configurazione, vedere usare Generatore API dati con ambienti.
Proprietà di configurazione
Questa sezione include tutte le possibili proprietà di configurazione disponibili per un file di configurazione.
Schema
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
$root |
$schema |
corda | ✔️ Sì | Nessuno |
Ogni file di configurazione inizia con una proprietà
Formato
{
"$schema": <string>
}
Esempi
I file di schema sono disponibili per le versioni 0.3.7-alpha successive in URL specifici, assicurandosi di usare la versione corretta o lo schema disponibile più recente.
https://github.com/Azure/data-api-builder/releases/download/<VERSION>-<suffix>/dab.draft.schema.json
Sostituire VERSION-suffix con la versione desiderata.
https://github.com/Azure/data-api-builder/releases/download/v0.3.7-alpha/dab.draft.schema.json
La versione più recente dello schema è sempre disponibile in https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json.
Ecco alcuni esempi di valori di schema validi.
| Versione | URI | Descrizione |
|---|---|---|
| 0.3.7-alpha | https://github.com/Azure/data-api-builder/releases/download/v0.3.7-alpha/dab.draft.schema.json |
Usa lo schema di configurazione da una versione alfa dello strumento. |
| 0.10.23 | https://github.com/Azure/data-api-builder/releases/download/v0.10.23/dab.draft.schema.json |
Usa lo schema di configurazione per una versione stabile dello strumento. |
| Ultimissimo | https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json |
Usa la versione più recente dello schema di configurazione. |
Nota
Le versioni del generatore di API dati precedenti a 0.3.7-alpha possono avere un URI dello schema diverso.
Origine dati
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
$root |
data-source |
corda | ✔️ Sì | Nessuno |
La sezione data-source definisce il database e l'accesso al database tramite la stringa di connessione. Definisce anche le opzioni di database. La proprietà data-source configura le credenziali necessarie per connettersi al database di backup. La sezione data-source descrive la connettività del database back-end, specificando sia il database-type che connection-string.
Formato
{
"data-source": {
"database-type": <string>,
"connection-string": <string>,
// mssql-only
"options": {
"set-session-context": <true> (default) | <false>
},
// cosmosdb_nosql-only
"options": {
"database": <string>,
"container": <string>,
"schema": <string>
}
}
}
Proprietà
| Obbligatorio | Digitare | |
|---|---|---|
database-type |
✔️ Sì | stringa enumerazione |
connection-string |
✔️ Sì | corda |
options |
❌ No | oggetto |
Tipo di database
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
data-source |
database-type |
enum-string | ✔️ Sì | Nessuno |
Stringa enumerazione utilizzata per specificare il tipo di database da utilizzare come origine dati.
Formato
{
"data-source": {
"database-type": <string>
}
}
Valori di tipo
La proprietà type indica il tipo di database back-end.
| Digitare | Descrizione | Versione minima |
|---|---|---|
mssql |
Azure SQL Database | Nessuno |
mssql |
Istanza gestita di SQL di Azure | Nessuno |
mssql |
SQL Server | SQL 2016 |
sqldw |
Azure SQL Data Warehouse | Nessuno |
postgresql |
PostgreSQL | v11 |
mysql |
MySQL | v8 |
cosmosdb_nosql |
Azure Cosmos DB per NoSQL | Nessuno |
cosmosdb_postgresql |
Azure Cosmos DB per PostgreSQL | Nessuno |
Stringa di connessione
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
data-source |
connection-string |
corda | ✔️ Sì | Nessuno |
Stringa valore contenente una stringa di connessione valida per connettersi al servizio di database di destinazione. Stringa di connessione ADO.NET per connettersi al database back-end. Per altre informazioni, vedere ADO.NET stringhe di connessione.
Formato
{
"data-source": {
"connection-string": <string>
}
}
Resilienza della connessione
Il generatore di API dati ritenta automaticamente le richieste di database dopo aver rilevato errori temporanei. La logica di ripetizione dei tentativi segue una strategia r): $r^2$
Usando questa formula, è possibile calcolare il tempo per ogni tentativo di ripetizione in secondi.
| Secondi | |
|---|---|
| first | 2 |
| secondo | 4 |
| terzo | 8 |
| quarto | 16 |
| quinto | 32 |
SQL di Azure e SQL Server
Il generatore di API dati usa la libreria SqlClient per connettersi ad Azure SQL o SQL Server usando la stringa di connessione specificata nel file di configurazione. Un elenco di tutte le opzioni della stringa di connessione supportate è disponibile qui: Proprietà SqlConnection.ConnectionString.
Il generatore di API dati può anche connettersi al database di destinazione usando identità del servizio gestito (MSI) quando il generatore di API dati è ospitato in Azure. Il DefaultAzureCredential definito nella libreria Azure.Identity viene usato per connettersi usando identità note quando non si specifica un nome utente o una password nella stringa di connessione. Per altre informazioni, vedere DefaultAzureCredential esempi.
'identità gestita assegnata dall'utente (UMI): aggiungere le proprietà di autenticazionee ID utente alla stringa di connessione sostituendo l'ID client dell'identità gestita assegnata dall'utente:. 'identità gestita assegnata dal sistema (SMI): aggiungere la proprietà Authenticationed escludere gli argomenti UserId e password dalla stringa di connessione: . L'assenza del UserId e proprietà della stringa di connessione segnalerà daB per l'autenticazione tramite un'identità gestita assegnata dal sistema.
Per altre informazioni sulla configurazione di un'identità del servizio gestita con SQL di Azure o SQL Server, vedere identità gestite in Microsoft Entra for Azure SQL.
Esempi
Il valore usato per la stringa di connessione dipende in gran parte dal servizio di database usato nello scenario. È sempre possibile scegliere di archiviare la stringa di connessione in una variabile di ambiente e accedervi usando la funzione @env().
| Valore | Descrizione | |
|---|---|---|
| Usare il valore stringa del database SQL di Azure | Server=<server-address>;Database=<name-of-database>;User ID=<username>;Password=<password>; |
Stringa di connessione a un account del database SQL di Azure. Per altre informazioni, vedere stringhe di connessione del database SQL di Azure. |
| Usare il valore stringa di Database di Azure per PostgreSQL | Server=<server-address>;Database=<name-of-database>;Port=5432;User Id=<username>;Password=<password>;Ssl Mode=Require; |
Stringa di connessione a un account di Database di Azure per PostgreSQL. Per altre informazioni, vedere stringhe di connessione di Database di Azure per PostgreSQL. |
| Usare il valore della stringa Azure Cosmos DB per NoSQL | AccountEndpoint=<endpoint>;AccountKey=<key>; |
Stringa di connessione a un account Azure Cosmos DB per NoSQL. Per altre informazioni, vedere stringhe di connessione di Azure Cosmos DB per NoSQL. |
| Usare il valore stringa di Database di Azure per MySQL | Server=<server-address>;Database=<name-of-database>;User ID=<username>;Password=<password>;Sslmode=Required;SslCa=<path-to-certificate>; |
Stringa di connessione a un account di Database di Azure per MySQL. Per altre informazioni, vedere stringhe di connessione di Database di Azure per MySQL. |
| della variabile di ambiente Access | @env('SQL_CONNECTION_STRING') |
Accedere a una variabile di ambiente dal computer locale. In questo esempio viene fatto riferimento alla variabile di ambiente SQL_CONNECTION_STRING. |
Mancia
Come procedura consigliata, evitare di archiviare informazioni riservate nel file di configurazione. Quando possibile, usare @env() per fare riferimento alle variabili di ambiente. Per altre informazioni, vedere @env() funzione.
Questi esempi illustrano semplicemente come configurare ogni tipo di database. Lo scenario potrebbe essere univoco, ma questo esempio è un buon punto di partenza. Sostituire i segnaposto, ad esempio myserver, myDataBase, mylogine myPassword con i valori effettivi specifici dell'ambiente.
mssql"data-source": { "database-type": "mssql", "connection-string": "$env('my-connection-string')", "options": { "set-session-context": true } }-
formato tipico della stringa di connessione:
"Server=tcp:myserver.database.windows.net,1433;Initial Catalog=myDataBase;Persist Security Info=False;User ID=mylogin;Password=myPassword;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;"
-
formato tipico della stringa di connessione:
postgresql"data-source": { "database-type": "postgresql", "connection-string": "$env('my-connection-string')" }-
formato tipico della stringa di connessione:
"Host=myserver.postgres.database.azure.com;Database=myDataBase;Username=mylogin@myserver;Password=myPassword;"
-
formato tipico della stringa di connessione:
mysql"data-source": { "database-type": "mysql", "connection-string": "$env('my-connection-string')" }-
formato tipico della stringa di connessione:
"Server=myserver.mysql.database.azure.com;Database=myDataBase;Uid=mylogin@myserver;Pwd=myPassword;"
-
formato tipico della stringa di connessione:
cosmosdb_nosql"data-source": { "database-type": "cosmosdb_nosql", "connection-string": "$env('my-connection-string')", "options": { "database": "Your_CosmosDB_Database_Name", "container": "Your_CosmosDB_Container_Name", "schema": "Path_to_Your_GraphQL_Schema_File" } }-
formato tipico della stringa di connessione:
"AccountEndpoint=https://mycosmosdb.documents.azure.com:443/;AccountKey=myAccountKey;"
-
formato tipico della stringa di connessione:
cosmosdb_postgresql"data-source": { "database-type": "cosmosdb_postgresql", "connection-string": "$env('my-connection-string')" }-
formato tipico della stringa di connessione:
"Host=mycosmosdb.postgres.database.azure.com;Database=myDataBase;Username=mylogin@mycosmosdb;Password=myPassword;Port=5432;SSL Mode=Require;"
-
formato tipico della stringa di connessione:
Nota
Le "opzioni" specificate, ad esempio database, containere schema sono specifiche dell'API NoSQL di Azure Cosmos DB anziché dell'API PostgreSQL. Per Azure Cosmos DB usando l'API PostgreSQL, le "opzioni" non includono database, containero schema come nell'installazione di NoSQL.
Opzioni
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
data-source |
options |
oggetto | ❌ No | Nessuno |
Sezione facoltativa di parametri chiave-valore aggiuntivi per connessioni di database specifiche.
Indica se la sezione options è obbligatoria o meno dipende in gran parte dal servizio di database in uso.
Formato
{
"data-source": {
"options": {
"<key-name>": <string>
}
}
}
options: { set-session-context: boolean }
Per SQL di Azure e SQL Server, Il generatore di API dati può sfruttare SESSION_CONTEXT per inviare i metadati specificati dall'utente al database sottostante. Tali metadati sono disponibili per il generatore di API dati in virtù delle attestazioni presenti nel token di accesso. I dati SESSION_CONTEXT sono disponibili per il database durante la connessione al database fino a quando tale connessione non viene chiusa. Per altre informazioni, vedere contesto di sessione.
Esempio di stored procedure SQL:
CREATE PROC GetUser @userId INT AS
BEGIN
-- Check if the current user has access to the requested userId
IF SESSION_CONTEXT(N'user_role') = 'admin'
OR SESSION_CONTEXT(N'user_id') = @userId
BEGIN
SELECT Id, Name, Age, IsAdmin
FROM Users
WHERE Id = @userId;
END
ELSE
BEGIN
RAISERROR('Unauthorized access', 16, 1);
END
END;
Esempio di configurazione JSON:
{
"$schema": "https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json",
"data-source": {
"database-type": "mssql",
"connection-string": "@env('SQL_CONNECTION_STRING')",
"options": {
"set-session-context": true
}
},
"entities": {
"User": {
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
},
"permissions": [
{
"role": "authenticated",
"actions": ["execute"]
}
]
}
}
}
Spiegazione:
stored procedure (
GetUser):- La procedura controlla il
SESSION_CONTEXTper verificare se il chiamante ha il ruoloadmino corrisponde aluserIdfornito. - L'accesso non autorizzato genera un errore.
- La procedura controlla il
configurazione JSON:
-
set-session-contextè abilitato per passare i metadati utente dal token di accesso al database. - La proprietà
parametersesegue il mapping del parametrouserIdrichiesto dalla stored procedure. - Il blocco
permissionsgarantisce che solo gli utenti autenticati possano eseguire la stored procedure.
-
File di origine dati
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
$root |
data-source-files |
matrice di stringhe | ❌ No | Nessuno |
Il generatore di API dati supporta più file di configurazione per origini dati diverse, con uno designato come file di primo livello che gestisce le impostazioni runtime. Tutte le configurazioni condividono lo stesso schema, consentendo runtime impostazioni in qualsiasi file senza errori. Le configurazioni figlio vengono unite automaticamente, ma è consigliabile evitare riferimenti circolari. Le entità possono essere suddivise in file separati per una migliore gestione, ma le relazioni tra entità devono trovarsi nello stesso file.
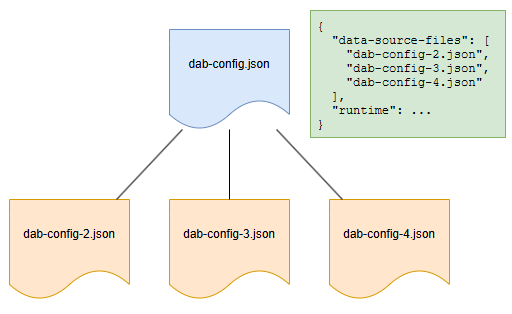
Formato
{
"data-source-files": [ <string> ]
}
Considerazioni sul file di configurazione
- Ogni file di configurazione deve includere la proprietà
data-source. - Ogni file di configurazione deve includere la proprietà
entities. - L'impostazione
runtimeviene usata solo dal file di configurazione di primo livello, anche se incluso in altri file. - I file di configurazione figlio possono includere anche i propri file figlio.
- I file di configurazione possono essere organizzati in sottocartelle in modo desiderato.
- I nomi delle entità devono essere univoci in tutti i file di configurazione.
- Le relazioni tra entità in file di configurazione diversi non sono supportate.
Esempi
{
"data-source-files": [
"dab-config-2.json"
]
}
{
"data-source-files": [
"dab-config-2.json",
"dab-config-3.json"
]
}
È supportata anche la sintassi delle sottocartelle:
{
"data-source-files": [
"dab-config-2.json",
"my-folder/dab-config-3.json",
"my-folder/my-other-folder/dab-config-4.json"
]
}
Runtime
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
$root |
runtime |
oggetto | ✔️ Sì | Nessuno |
La sezione runtime descrive le opzioni che influisce sul comportamento di runtime e le impostazioni per tutte le entità esposte.
Formato
{
"runtime": {
"rest": {
"path": <string> (default: /api),
"enabled": <true> (default) | <false>,
"request-body-strict": <true> (default) | <false>
},
"graphql": {
"path": <string> (default: /graphql),
"enabled": <true> (default) | <false>,
"allow-introspection": <true> (default) | <false>
},
"host": {
"mode": "production" (default) | "development",
"cors": {
"origins": ["<array-of-strings>"],
"allow-credentials": <true> | <false> (default)
},
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<client-id>",
"issuer": "<issuer-url>"
}
}
}
},
"cache": {
"enabled": <true> | <false> (default),
"ttl-seconds": <integer; default: 5>
},
"pagination": {
"max-page-size": <integer; default: 100000>,
"default-page-size": <integer; default: 100>,
"max-response-size-mb": <integer; default: 158>
},
"telemetry": {
"application-insights": {
"connection-string": <string>,
"enabled": <true> | <false> (default)
}
}
}
Proprietà
| Obbligatorio | Digitare | |
|---|---|---|
rest |
❌ No | oggetto |
graphql |
❌ No | oggetto |
host |
❌ No | oggetto |
cache |
❌ No | oggetto |
Esempi
Di seguito è riportato un esempio di sezione di runtime con più parametri predefiniti comuni specificati.
{
"runtime": {
"rest": {
"enabled": true,
"path": "/api",
"request-body-strict": true
},
"graphql": {
"enabled": true,
"path": "/graphql",
"allow-introspection": true
},
"host": {
"mode": "development",
"cors": {
"allow-credentials": false,
"origins": [
"*"
]
},
"authentication": {
"provider": "StaticWebApps",
"jwt": {
"audience": "<client-id>",
"issuer": "<identity-provider-issuer-uri>"
}
}
},
"cache": {
"enabled": true,
"ttl-seconds": 5
},
"pagination": {
"max-page-size": -1 | <integer; default: 100000>,
"default-page-size": -1 | <integer; default: 100>,
"max-response-size-mb": <integer; default: 158>
},
"telemetry": {
"application-insights": {
"connection-string": "<connection-string>",
"enabled": true
}
}
}
}
GraphQL (runtime)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime |
graphql |
oggetto | ❌ No | Nessuno |
Questo oggetto definisce se GraphQL è abilitato e il nome[s] usato per esporre l'entità come tipo GraphQL. Questo oggetto è facoltativo e viene usato solo se il nome o le impostazioni predefinite non sono sufficienti. Questa sezione descrive le impostazioni globali per l'endpoint GraphQL.
Formato
{
"runtime": {
"graphql": {
"path": <string> (default: /graphql),
"enabled": <true> (default) | <false>,
"depth-limit": <integer; default: none>,
"allow-introspection": <true> (default) | <false>,
"multiple-mutations": <object>
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
enabled |
❌ No | booleano | Vero |
path |
❌ No | corda | /graphql (impostazione predefinita) |
allow-introspection |
❌ No | booleano | Vero |
multiple-mutations |
❌ No | oggetto | { create: { enabled: false } } |
Abilitato (runtime GraphQL)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.graphql |
enabled |
booleano | ❌ No | Nessuno |
Definisce se abilitare o disabilitare gli endpoint GraphQL a livello globale. Se disabilitato a livello globale, nessuna entità sarà accessibile tramite richieste GraphQL indipendentemente dalle singole impostazioni dell'entità.
Formato
{
"runtime": {
"graphql": {
"enabled": <true> (default) | <false>
}
}
}
Esempi
In questo esempio l'endpoint GraphQL è disabilitato per tutte le entità.
{
"runtime": {
"graphql": {
"enabled": false
}
}
}
Limite di profondità (runtime GraphQL)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.graphql |
depth-limit |
numero intero | ❌ No | Nessuno |
Profondità massima consentita delle query di una query.
La capacità di GraphQL di gestire query annidate basate sulle definizioni di relazione è una funzionalità incredibile, consentendo agli utenti di recuperare dati correlati complessi in una singola query. Tuttavia, man mano che gli utenti continuano ad aggiungere query annidate, la complessità della query aumenta, che alla fine può compromettere le prestazioni e l'affidabilità del database e dell'endpoint API. Per gestire questa situazione, la proprietà runtime/graphql/depth-limit imposta la profondità massima consentita di una query GraphQL (e mutazione). Questa proprietà consente agli sviluppatori di raggiungere un equilibrio, consentendo agli utenti di usufruire dei vantaggi delle query annidate, posizionando limiti per evitare scenari che potrebbero compromettere le prestazioni e la qualità del sistema.
Esempi
{
"runtime": {
"graphql": {
"depth-limit": 2
}
}
}
Percorso (runtime GraphQL)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.graphql |
path |
corda | ❌ No | "/graphql" |
Definisce il percorso URL in cui viene reso disponibile l'endpoint GraphQL. Ad esempio, se questo parametro è impostato su /graphql, l'endpoint GraphQL viene esposto come /graphql. Per impostazione predefinita, il percorso è /graphql.
Importante
I percorsi secondari non sono consentiti per questa proprietà. Un valore di percorso personalizzato per l'endpoint GraphQL non è attualmente disponibile.
Formato
{
"runtime": {
"graphql": {
"path": <string> (default: /graphql)
}
}
}
Esempi
In questo esempio, l'URI GraphQL radice è /query.
{
"runtime": {
"graphql": {
"path": "/query"
}
}
}
Consenti introspezione (runtime GraphQL)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.graphql |
allow-introspection |
booleano | ❌ No | Vero |
Questo flag booleano controlla la possibilità di eseguire query di introspezione dello schema nell'endpoint GraphQL. L'abilitazione dell'introspezione consente ai client di eseguire query sullo schema per ottenere informazioni sui tipi di dati disponibili, sui tipi di query che possono eseguire e sulle mutazioni disponibili.
Questa funzionalità è utile durante lo sviluppo per comprendere la struttura dell'API GraphQL e per gli strumenti che generano automaticamente query. Tuttavia, per gli ambienti di produzione, potrebbe essere disabilitato per nascondere i dettagli dello schema dell'API e migliorare la sicurezza. Per impostazione predefinita, l'introspezione è abilitata, consentendo un'esplorazione immediata e completa dello schema GraphQL.
Formato
{
"runtime": {
"graphql": {
"allow-introspection": <true> (default) | <false>
}
}
}
Esempi
In questo esempio l'introspezione è disabilitata.
{
"runtime": {
"graphql": {
"allow-introspection": false
}
}
}
Mutazioni multiple (runtime GraphQL)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.graphql |
multiple-mutations |
oggetto | ❌ No | Nessuno |
Configura tutte le operazioni di mutazione multiple per il runtime GraphQL.
Nota
Per impostazione predefinita, più mutazioni non sono abilitate e devono essere configurate in modo esplicito per l'abilitazione.
Formato
{
"runtime": {
"graphql": {
"multiple-mutations": {
"create": {
"enabled": <true> (default) | <false>
}
}
}
}
}
Proprietà
| Obbligatorio | Digitare | |
|---|---|---|
create |
❌ No | oggetto |
Mutazioni multiple : creazione (runtime GraphQL)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.graphql.multiple-mutations |
create |
booleano | ❌ No | Falso |
Configura più operazioni di creazione per il runtime GraphQL.
Formato
{
"runtime": {
"graphql": {
"multiple-mutations": {
"create": {
"enabled": <true> (default) | <false>
}
}
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
enabled |
✔️ Sì | booleano | Vero |
Esempi
Di seguito viene illustrato come abilitare e usare più mutazioni nel runtime GraphQL. In questo caso, l'operazione create è configurata per consentire la creazione di più record in una singola richiesta impostando la proprietà runtime.graphql.multiple-mutations.create.enabled su true.
Esempio di configurazione
Questa configurazione abilita più mutazioni create:
{
"runtime": {
"graphql": {
"multiple-mutations": {
"create": {
"enabled": true
}
}
}
},
"entities": {
"User": {
"source": "dbo.Users",
"permissions": [
{
"role": "anonymous",
"actions": ["create"]
}
]
}
}
}
Esempio di mutazione graphQL
Usando la configurazione precedente, la mutazione seguente crea più record User in un'unica operazione:
mutation {
createUsers(input: [
{ name: "Alice", age: 30, isAdmin: true },
{ name: "Bob", age: 25, isAdmin: false },
{ name: "Charlie", age: 35, isAdmin: true }
]) {
id
name
age
isAdmin
}
}
REST (runtime)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime |
rest |
oggetto | ❌ No | Nessuno |
Questa sezione descrive le impostazioni globali per gli endpoint REST. Queste impostazioni fungono da impostazioni predefinite per tutte le entità, ma possono essere sostituite in base alle rispettive configurazioni.
Formato
{
"runtime": {
"rest": {
"path": <string> (default: /api),
"enabled": <true> (default) | <false>,
"request-body-strict": <true> (default) | <false>
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
enabled |
❌ No | booleano | Vero |
path |
❌ No | corda | /API |
request-body-strict |
❌ No | booleano | Vero |
Abilitato (runtime REST)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.rest |
enabled |
booleano | ❌ No | Nessuno |
Flag booleano che determina la disponibilità globale degli endpoint REST. Se disabilitata, le entità non possono essere accessibili tramite REST, indipendentemente dalle singole impostazioni dell'entità.
Formato
{
"runtime": {
"rest": {
"enabled": <true> (default) | <false>,
}
}
}
Esempi
In questo esempio l'endpoint DELL'API REST è disabilitato per tutte le entità.
{
"runtime": {
"rest": {
"enabled": false
}
}
}
Percorso (runtime REST)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.rest |
path |
corda | ❌ No | "/api" |
Imposta il percorso URL per l'accesso a tutti gli endpoint REST esposti. Ad esempio, l'impostazione di path su /api rende l'endpoint REST accessibile in /api/<entity>. Non sono consentiti percorsi secondari. Questo campo è facoltativo, con /api come impostazione predefinita.
Nota
Quando si distribuisce Generatore API dati usando App Web statiche (anteprima), il servizio di Azure inserisce automaticamente il sottopercorso aggiuntivo /data-api all'URL. Questo comportamento garantisce la compatibilità con le funzionalità di App Web statiche esistenti. L'endpoint risultante sarà /data-api/api/<entity>. Questo è rilevante solo per le app Web statiche.
Formato
{
"runtime": {
"rest": {
"path": <string> (default: /api)
}
}
}
Importante
I percorsi secondari forniti dall'utente non sono consentiti per questa proprietà.
Esempi
In questo esempio l'URI dell'API REST radice è /data.
{
"runtime": {
"rest": {
"path": "/data"
}
}
}
Mancia
Se si definisce un'entità Author, l'endpoint per questa entità sarà /data/Author.
Corpo della richiesta Strict (runtime REST)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.rest |
request-body-strict |
booleano | ❌ No | Vero |
Questa impostazione controlla quanto rigorosamente il corpo della richiesta per le operazioni di mutazione REST (ad esempio, POST, PUT, PATCH) viene convalidato.
-
true(impostazione predefinita): campi aggiuntivi nel corpo della richiesta che non eseguono il mapping alle colonne della tabella causano un'eccezioneBadRequest. -
false: i campi aggiuntivi vengono ignorati e vengono elaborate solo colonne valide.
Questa impostazione non si applica alle richieste di GET, perché il corpo della richiesta viene sempre ignorato.
Comportamento con configurazioni di colonna specifiche
- Le colonne con valore default() vengono ignorate durante
INSERTsolo quando il valore nel payload ènull. Le colonne con valore predefinito() non vengono ignorate duranteUPDATEindipendentemente dal valore del payload. - Le colonne calcolate vengono sempre ignorate.
- Le colonne generate automaticamente vengono sempre ignorate.
Formato
{
"runtime": {
"rest": {
"request-body-strict": <true> (default) | <false>
}
}
}
Esempi
CREATE TABLE Users (
Id INT PRIMARY KEY IDENTITY,
Name NVARCHAR(50) NOT NULL,
Age INT DEFAULT 18,
IsAdmin BIT DEFAULT 0,
IsMinor AS IIF(Age <= 18, 1, 0)
);
Configurazione di esempio
{
"runtime": {
"rest": {
"request-body-strict": false
}
}
}
Comportamento INSERT con request-body-strict: false
payload della richiesta:
{
"Id": 999,
"Name": "Alice",
"Age": null,
"IsAdmin": null,
"IsMinor": false,
"ExtraField": "ignored"
}
'istruzione Insert risultante:
INSERT INTO Users (Name) VALUES ('Alice');
-- Default values for Age (18) and IsAdmin (0) are applied by the database.
-- IsMinor is ignored because it’s a computed column.
-- ExtraField is ignored.
-- The database generates the Id value.
payload della risposta:
{
"Id": 1, // Auto-generated by the database
"Name": "Alice",
"Age": 18, // Default applied
"IsAdmin": false, // Default applied
"IsMinor": true // Computed
}
Comportamento UPDATE con request-body-strict: false
payload della richiesta:
{
"Id": 1,
"Name": "Alice Updated",
"Age": null, // explicitely set to 'null'
"IsMinor": true, // ignored because computed
"ExtraField": "ignored"
}
'istruzione di aggiornamento risultante:
UPDATE Users
SET Name = 'Alice Updated', Age = NULL
WHERE Id = 1;
-- IsMinor and ExtraField are ignored.
payload della risposta:
{
"Id": 1,
"Name": "Alice Updated",
"Age": null,
"IsAdmin": false,
"IsMinor": false // Recomputed by the database (false when age is `null`)
}
Host (runtime)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime |
host |
oggetto | ❌ No | Nessuno |
La sezione host all'interno della configurazione di runtime fornisce impostazioni fondamentali per l'ambiente operativo del generatore di API dati. Queste impostazioni includono modalità operative, configurazione CORS e dettagli di autenticazione.
Formato
{
"runtime": {
"host": {
"mode": "production" (default) | "development",
"max-response-size-mb": <integer; default: 158>,
"cors": {
"origins": ["<array-of-strings>"],
"allow-credentials": <true> | <false> (default)
},
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<client-id>",
"issuer": "<issuer-url>"
}
}
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
mode |
❌ No | stringa enumerazione | produzione |
cors |
❌ No | oggetto | Nessuno |
authentication |
❌ No | oggetto | Nessuno |
Esempi
Ecco un esempio di runtime configurato per l'hosting di sviluppo.
{
"runtime": {
"host": {
"mode": "development",
"cors": {
"allow-credentials": false,
"origins": ["*"]
},
"authentication": {
"provider": "Simulator"
}
}
}
}
Modalità (runtime host)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.host |
mode |
corda | ❌ No | "produzione" |
Definisce se il motore di Generatore API dati deve essere eseguito in modalità development o production. Il valore predefinito è production.
In genere, gli errori del database sottostanti vengono esposti in dettaglio impostando il livello predefinito di dettaglio per i log su Debug durante l'esecuzione nello sviluppo. Nell'ambiente di produzione, il livello di dettaglio per i log è impostato su Error.
Mancia
È possibile eseguire l'override del livello di log predefinito usando dab start --LogLevel <level-of-detail>. Per altre informazioni, vedere riferimento dell'interfaccia della riga di comando (CLI).
Formato
{
"runtime": {
"host": {
"mode": "production" (default) | "development"
}
}
}
Valori
Ecco un elenco di valori consentiti per questa proprietà:
| Descrizione | |
|---|---|
production |
Usare quando si ospita nell'ambiente di produzione in Azure |
development |
Uso nello sviluppo nel computer locale |
Comportamenti
- Solo in modalità
developmentè disponibile Swagger. - Solo in modalità
developmentè disponibile Banana Cake Pop.
Dimensioni massime della risposta (runtime)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.host |
max-response-size-mb |
numero intero | ❌ No | 158 |
Imposta le dimensioni massime (in megabyte) per qualsiasi risultato specificato. Questa impostazione consente agli utenti di configurare la quantità di dati che la memoria della piattaforma host può gestire durante lo streaming dei dati dalle origini dati sottostanti.
Quando gli utenti richiedono set di risultati di grandi dimensioni, possono filtrare il database e il generatore di API dati. Per risolvere questo problema, max-response-size-mb consente agli sviluppatori di limitare le dimensioni massime della risposta, misurate in megabyte, come flussi di dati dall'origine dati. Questo limite è basato sulle dimensioni complessive dei dati, non sul numero di righe. Poiché le colonne possono variare in base alle dimensioni, alcune colonne (ad esempio testo, binario, XML o JSON) possono contenere fino a 2 GB ciascuno, rendendo potenzialmente molto grandi le singole righe. Questa impostazione consente agli sviluppatori di proteggere gli endpoint riducendo le dimensioni delle risposte e impedendo gli overload di sistema mantenendo al contempo la flessibilità per i diversi tipi di dati.
Valori consentiti
| Valore | Risultato |
|---|---|
null |
Il valore predefinito è 158 megabyte se non è impostato o impostato in modo esplicito su null. |
integer |
È supportato qualsiasi numero intero positivo a 32 bit. |
< 0 |
Non supportato. Gli errori di convalida si verificano se impostato su meno di 1 MB. |
Formato
{
"runtime": {
"host": {
"max-response-size-mb": <integer; default: 158>
}
}
}
CORS (runtime host)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.host |
cors |
oggetto | ❌ No | Nessuno |
Impostazioni CORS (Cross-Origin Resource Sharing) per l'host del motore del generatore di API dati.
Formato
{
"runtime": {
"host": {
"cors": {
"origins": ["<array-of-strings>"],
"allow-credentials": <true> | <false> (default)
}
}
}
}
Proprietà
| Obbligatorio | Digitare | |
|---|---|---|
allow-credentials |
❌ No | booleano |
origins |
❌ No | matrice di stringhe |
Consenti credenziali (runtime host)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.host.cors |
allow-credentials |
booleano | ❌ No | Falso |
Se true, imposta l'intestazione CORS Access-Control-Allow-Credentials.
Nota
Per altre informazioni sull'intestazione CORS Access-Control-Allow-Credentials, vedere riferimento CORS della documentazione Web MDN.
Formato
{
"runtime": {
"host": {
"cors": {
"allow-credentials": <true> (default) | <false>
}
}
}
}
Origini (runtime host)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.host.cors |
origins |
matrice di stringhe | ❌ No | Nessuno |
Imposta una matrice con un elenco di origini consentite per CORS. Questa impostazione consente il carattere jolly * per tutte le origini.
Formato
{
"runtime": {
"host": {
"cors": {
"origins": ["<array-of-strings>"]
}
}
}
}
Esempi
Ecco un esempio di host che consente CORS senza credenziali da tutte le origini.
{
"runtime": {
"host": {
"cors": {
"allow-credentials": false,
"origins": ["*"]
}
}
}
}
Autenticazione (runtime host)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.host |
authentication |
oggetto | ❌ No | Nessuno |
Configura l'autenticazione per l'host del generatore di API dati.
Formato
{
"runtime": {
"host": {
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<string>",
"issuer": "<string>"
}
}
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
provider |
❌ No | stringa enumerazione | StaticWebApps |
jwt |
❌ No | oggetto | Nessuno |
l'autenticazione e le responsabilità dei clienti
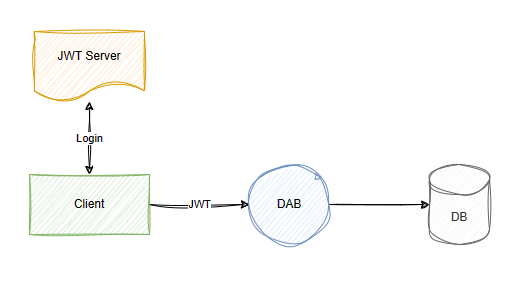
Il generatore di API dati è progettato per operare all'interno di una pipeline di sicurezza più ampia e sono necessari passaggi importanti da configurare prima di elaborare le richieste. È importante comprendere che Il generatore di API dati non autentica il chiamante diretto ,ad esempio l'applicazione Web, ma piuttosto l'utente finale, in base a un token JWT valido fornito da un provider di identità attendibile (ad esempio, Entra ID). Quando una richiesta raggiunge il generatore di API dati, presuppone che il token JWT sia valido e lo verifichi in base ai prerequisiti configurati, ad esempio attestazioni specifiche. Le regole di autorizzazione vengono quindi applicate per determinare cosa l'utente può accedere o modificare.
Dopo il passaggio dell'autorizzazione, il generatore di API dati esegue la richiesta usando l'account specificato nella stringa di connessione. Poiché questo account richiede spesso autorizzazioni elevate per gestire varie richieste utente, è essenziale ridurre al minimo i diritti di accesso per ridurre i rischi. È consigliabile proteggere l'architettura configurando un collegamento privato tra l'applicazione Web front-end e l'endpoint API e la protezione avanzata del computer che ospita il generatore di API dati. Queste misure consentono di garantire che l'ambiente rimanga sicuro, proteggendo i dati e riducendo al minimo le vulnerabilità che potrebbero essere sfruttate per accedere, modificare o esfiltrare informazioni riservate.
Provider (runtime host)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.host.authentication |
provider |
corda | ❌ No | "StaticWebApps" |
L'impostazione authentication.provider all'interno della configurazione host definisce il metodo di autenticazione usato dal generatore di API dati. Determina il modo in cui l'API convalida l'identità degli utenti o dei servizi che tenta di accedere alle risorse. Questa impostazione consente flessibilità nella distribuzione e nell'integrazione supportando vari meccanismi di autenticazione personalizzati in base a diversi ambienti e requisiti di sicurezza.
| Provider | Descrizione |
|---|---|
StaticWebApps |
Indica al generatore di API dati di cercare un set di intestazioni HTTP presenti solo durante l'esecuzione in un ambiente app Web statiche. |
AppService |
Quando il runtime è ospitato in Azure AppService con l'autenticazione appservice abilitata e configurata (EasyAuth). |
AzureAd |
Microsoft Entra Identity deve essere configurato in modo che possa autenticare una richiesta inviata a Generatore API dati (l'app server). Per altre informazioni, vedere autenticazione di Microsoft Entra ID. |
Simulator |
Provider di autenticazione configurabile che indica al motore di Generatore API dati di considerare tutte le richieste come autenticate. Per altre informazioni, vedere 'autenticazione locale. |
Formato
{
"runtime": {
"host": {
"authentication": {
"provider": "StaticWebApps" (default) | ...
}
}
}
}
Valori
Ecco un elenco di valori consentiti per questa proprietà:
| Descrizione | |
|---|---|
StaticWebApps |
App Web statiche di Azure |
AppService |
Servizio app di Azure |
AzureAD |
Microsoft Entra ID |
Simulator |
Simulatore |
Token Web JSON (runtime host)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.host.authentication |
jwt |
oggetto | ❌ No | Nessuno |
Se il provider di autenticazione è impostato su AzureAD (ID Microsoft Entra), questa sezione è necessaria per specificare il gruppo di destinatari e le autorità emittenti per il token JWT (JSOn Web Tokens). Questi dati vengono usati per convalidare i token rispetto al tenant di Microsoft Entra.
Obbligatorio se il provider di autenticazione è AzureAD per Microsoft Entra ID. Questa sezione deve specificare il audience e issuer per convalidare il token JWT ricevuto rispetto al tenant AzureAD previsto per l'autenticazione.
| Impostazione | Descrizione |
|---|---|
| pubblico | Identifica il destinatario previsto del token; in genere l'identificatore dell'applicazione registrato in Microsoft Entra Identity (o nel provider di identità), assicurandosi che il token sia stato effettivamente emesso per l'applicazione. |
| Emittente | Specifica l'URL dell'autorità emittente, ovvero il servizio token che ha emesso il token JWT. Questo URL deve corrispondere all'URL dell'autorità di certificazione del provider di identità da cui è stato ottenuto il token JWT, convalidando l'origine del token. |
Formato
{
"runtime": {
"host": {
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<client-id>",
"issuer": "<issuer-url>"
}
}
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
audience |
❌ No | corda | Nessuno |
issuer |
❌ No | corda | Nessuno |
Esempi
Data API Builder (DAB) offre supporto flessibile per l'autenticazione, integrazione con Microsoft Entra Identity e server JWT (JSON Web Token) personalizzati. In questa immagine, il server JWT rappresenta il servizio di autenticazione che rilascia i token JWT ai client al termine dell'accesso. Il client passa quindi il token a DAB, che può interrogare le attestazioni e le proprietà.
Di seguito sono riportati esempi della proprietà host in base alle varie opzioni di architettura che è possibile effettuare nella soluzione.
App Web statiche di Azure
{
"host": {
"mode": "development",
"cors": {
"origins": ["https://dev.example.com"],
"credentials": true
},
"authentication": {
"provider": "StaticWebApps"
}
}
}
Con StaticWebApps, Il generatore di API dati prevede che App Web statiche di Azure eseguano l'autenticazione della richiesta e che sia presente l'intestazione HTTP X-MS-CLIENT-PRINCIPAL.
Servizio app di Azure
{
"host": {
"mode": "production",
"cors": {
"origins": [ "https://api.example.com" ],
"credentials": false
},
"authentication": {
"provider": "AppService",
"jwt": {
"audience": "9e7d452b-7e23-4300-8053-55fbf243b673",
"issuer": "https://example-appservice-auth.com"
}
}
}
}
L'autenticazione viene delegata a un provider di identità supportato in cui è possibile emettere il token di accesso. Un token di accesso acquisito deve essere incluso con le richieste in ingresso a Generatore API dati. Il generatore di API dati convalida quindi tutti i token di accesso presentati, assicurandosi che il generatore di API dati fosse il pubblico previsto del token.
Microsoft Entra ID
{
"host": {
"mode": "production",
"cors": {
"origins": [ "https://api.example.com" ],
"credentials": true
},
"authentication": {
"provider": "AzureAD",
"jwt": {
"audience": "c123d456-a789-0abc-a12b-3c4d56e78f90",
"issuer": "https://login.microsoftonline.com/98765f43-21ba-400c-a5de-1f2a3d4e5f6a/v2.0"
}
}
}
}
Simulatore (solo sviluppo)
{
"host": {
"mode": "development",
"authentication": {
"provider": "Simulator"
}
}
}
Destinatari (runtime host)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.host.authentication.jwt |
audience |
corda | ❌ No | Nessuno |
Destinatari per il token JWT.
Formato
{
"runtime": {
"host": {
"authentication": {
"jwt": {
"audience": "<client-id>"
}
}
}
}
}
Autorità di certificazione (runtime host)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.host.authentication.jwt |
issuer |
corda | ❌ No | Nessuno |
Autorità di certificazione per il token JWT.
Formato
{
"runtime": {
"host": {
"authentication": {
"jwt": {
"issuer": "<issuer-url>"
}
}
}
}
}
Paginazione (runtime)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime |
pagination |
oggetto | ❌ No | Nessuno |
Configura i limiti di impaginazione per gli endpoint REST e GraphQL.
Formato
{
"runtime": {
"pagination": {
"max-page-size": <integer; default: 100000>,
"default-page-size": <integer; default: 100>
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
max-page-size |
❌ No | numero intero | 100,000 |
default-page-size |
❌ No | numero intero | 100 |
Configurazione di esempio
{
"runtime": {
"pagination": {
"max-page-size": 1000,
"default-page-size": 2
}
},
"entities": {
"Users": {
"source": "dbo.Users",
"permissions": [
{
"actions": ["read"],
"role": "anonymous"
}
]
}
}
}
Esempio di paginazione REST
In questo esempio, l'emissione della richiesta REST GET https://localhost:5001/api/users restituirà due record nella matrice value perché il default-page-size è impostato su 2. Se esistono più risultati, il generatore di API dati include un nextLink nella risposta. Il nextLink contiene un parametro $after per il recupero della pagina successiva dei dati.
Richiesta:
GET https://localhost:5001/api/users
Risposta:
{
"value": [
{
"Id": 1,
"Name": "Alice",
"Age": 30,
"IsAdmin": true,
"IsMinor": false
},
{
"Id": 2,
"Name": "Bob",
"Age": 17,
"IsAdmin": false,
"IsMinor": true
}
],
"nextLink": "https://localhost:5001/api/users?$after=W3siRW50aXR5TmFtZSI6InVzZXJzIiwiRmllbGROYW1lI=="
}
Usando il nextLink, il client può recuperare il set di risultati successivo.
Esempio di paginazione graphQL
Per GraphQL, usare i campi hasNextPage e endCursor per la paginazione. Questi campi indicano se sono disponibili più risultati e fornire un cursore per il recupero della pagina successiva.
Quesito:
query {
users {
items {
Id
Name
Age
IsAdmin
IsMinor
}
hasNextPage
endCursor
}
}
Risposta:
{
"data": {
"users": {
"items": [
{
"Id": 1,
"Name": "Alice",
"Age": 30,
"IsAdmin": true,
"IsMinor": false
},
{
"Id": 2,
"Name": "Bob",
"Age": 17,
"IsAdmin": false,
"IsMinor": true
}
],
"hasNextPage": true,
"endCursor": "W3siRW50aXR5TmFtZSI6InVzZXJzIiwiRmllbGROYW1lI=="
}
}
}
Per recuperare la pagina successiva, includere il valore endCursor nella query successiva:
Query con cursore:
query {
users(after: "W3siRW50aXR5TmFtZSI6InVzZXJzIiwiRmllbGROYW1lI==") {
items {
Id
Name
Age
IsAdmin
IsMinor
}
hasNextPage
endCursor
}
}
Modifica delle dimensioni della pagina
REST e GraphQL consentono entrambi di modificare il numero di risultati per ogni query usando $limit (REST) o first (GraphQL).
valore $limit/first |
Comportamento |
|---|---|
-1 |
Il valore predefinito è max-page-size. |
< max-page-size |
Limita i risultati al valore specificato. |
0 o < -1 |
Non supportato. |
> max-page-size |
È stato limitato a max-page-size. |
Esempio di query REST:
GET https://localhost:5001/api/users?$limit=5
Esempio di query GraphQL:
query {
users(first: 5) {
items {
Id
Name
Age
IsAdmin
IsMinor
}
}
}
Dimensioni massime della pagina (runtime di paginazione)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.pagination |
max-page-size |
Int | ❌ No | 100,000 |
Imposta il numero massimo di record di primo livello restituiti da REST o GraphQL. Se un utente richiede più di max-page-size, i risultati vengono limitati a max-page-size.
Valori consentiti
| Valore | Risultato |
|---|---|
-1 |
Il valore predefinito è il valore massimo supportato. |
integer |
È supportato qualsiasi numero intero positivo a 32 bit. |
< -1 |
Non supportato. |
0 |
Non supportato. |
Formato
{
"runtime": {
"pagination": {
"max-page-size": <integer; default: 100000>
}
}
}
Dimensioni di pagina predefinite (runtime di paginazione)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.pagination |
default-page-size |
Int | ❌ No | 100 |
Imposta il numero predefinito di record di primo livello restituiti quando è abilitata l'impaginazione, ma non viene fornita alcuna dimensione di pagina esplicita.
Valori consentiti
| Valore | Risultato |
|---|---|
-1 |
Il valore predefinito è l'impostazione max-page-size corrente. |
integer |
Qualsiasi numero intero positivo minore del max-page-sizecorrente. |
< -1 |
Non supportato. |
0 |
Non supportato. |
Cache (runtime)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime |
cache |
oggetto | ❌ No | Nessuno |
Abilita e configura la memorizzazione nella cache per l'intero runtime.
Formato
{
"runtime": {
"cache": <object>
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
enabled |
❌ No | booleano | Nessuno |
ttl-seconds |
❌ No | numero intero | 5 |
Esempi
In questo esempio la cache è abilitata e gli elementi scadono dopo 30 secondi.
{
"runtime": {
"cache": {
"enabled": true,
"ttl-seconds": 30
}
}
}
Abilitato (runtime della cache)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.cache |
enabled |
booleano | ❌ No | Falso |
Abilita la memorizzazione nella cache a livello globale per tutte le entità. Il valore predefinito è false.
Formato
{
"runtime": {
"cache": {
"enabled": <boolean>
}
}
}
Esempi
In questo esempio la cache è disabilitata.
{
"runtime": {
"cache": {
"enabled": false
}
}
}
TTL in secondi (runtime della cache)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.cache |
ttl-seconds |
numero intero | ❌ No | 5 |
Configura il valore TTL (Time-to-Live) in secondi per gli elementi memorizzati nella cache. Dopo questo intervallo di tempo, gli elementi vengono eliminati automaticamente dalla cache. Il valore predefinito è 5 secondi.
Formato
{
"runtime": {
"cache": {
"ttl-seconds": <integer>
}
}
}
Esempi
In questo esempio la cache è abilitata a livello globale e tutti gli elementi scadono dopo 15 secondi.
{
"runtime": {
"cache": {
"enabled": true,
"ttl-seconds": 15
}
}
}
Telemetria (runtime)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime |
telemetry |
oggetto | ❌ No | Nessuno |
Questa proprietà configura Application Insights per centralizzare i log API. Altre .
Formato
{
"runtime": {
"telemetry": {
"application-insights": {
"enabled": <true; default: true> | <false>,
"connection-string": <string>
}
}
}
}
Application Insights (runtime di telemetria)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.telemetry |
application-insights |
oggetto | ✔️ Sì | Nessuno |
Abilitato (telemetria di Application Insights)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.telemetry.application-insights |
enabled |
booleano | ❌ No | Vero |
Stringa di connessione (dati di telemetria di Application Insights)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
runtime.telemetry.application-insights |
connection-string |
corda | ✔️ Sì | Nessuno |
Entità
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
$root |
entities |
oggetto | ✔️ Sì | Nessuno |
La sezione entities funge da base del file di configurazione, stabilendo un bridge tra gli oggetti di database e gli endpoint API corrispondenti. Questa sezione esegue il mapping degli oggetti di database agli endpoint esposti. Questa sezione include anche il mapping delle proprietà e la definizione delle autorizzazioni. Ogni entità esposta viene definita in un oggetto dedicato. Il nome della proprietà dell'oggetto viene usato come nome dell'entità da esporre.
Questa sezione definisce il modo in cui ogni entità nel database viene rappresentata nell'API, inclusi mapping delle proprietà e autorizzazioni. Ogni entità viene incapsulata all'interno della propria sottosezione, con il nome dell'entità che funge da chiave per riferimento in tutta la configurazione.
Formato
{
"entities": {
"<entity-name>": {
"rest": {
"enabled": <true; default: true> | <false>,
"path": <string; default: "<entity-name>">,
"methods": <array of strings; default: ["GET", "POST"]>
},
"graphql": {
"enabled": <true; default: true> | <false>,
"type": {
"singular": <string>,
"plural": <string>
},
"operation": <"query" | "mutation"; default: "query">
},
"source": {
"object": <string>,
"type": <"view" | "stored-procedure" | "table">,
"key-fields": <array of strings>,
"parameters": {
"<parameter-name>": <string | number | boolean>
}
},
"mappings": {
"<database-field-name>": <string>
},
"relationships": {
"<relationship-name>": {
"cardinality": <"one" | "many">,
"target.entity": <string>,
"source.fields": <array of strings>,
"target.fields": <array of strings>,
"linking.object": <string>,
"linking.source.fields": <array of strings>,
"linking.target.fields": <array of strings>
}
},
"permissions": [
{
"role": <"anonymous" | "authenticated" | "custom-role-name">,
"actions": <array of strings>,
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
},
"policy": {
"database": <string>
}
}
]
}
}
}
Proprietà
| Obbligatorio | Digitare | |
|---|---|---|
source |
✔️ Sì | oggetto |
permissions |
✔️ Sì | array |
rest |
❌ No | oggetto |
graphql |
❌ No | oggetto |
mappings |
❌ No | oggetto |
relationships |
❌ No | oggetto |
cache |
❌ No | oggetto |
Esempi
Questo oggetto JSON, ad esempio, indica al generatore di API dati di esporre un'entità GraphQL denominata User e un endpoint REST raggiungibile tramite il percorso /User. La tabella di database dbo.User supporta l'entità e la configurazione consente a chiunque di accedere all'endpoint in modo anonimo.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
]
}
}
}
In questo esempio viene dichiarata l'entità User. Questo nome User viene usato in qualsiasi punto del file di configurazione a cui fanno riferimento le entità. In caso contrario, il nome dell'entità non è rilevante per gli endpoint.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table",
"key-fields": ["Id"],
"parameters": {} // only when source.type = stored-procedure
},
"rest": {
"enabled": true,
"path": "/users",
"methods": [] // only when source.type = stored-procedure
},
"graphql": {
"enabled": true,
"type": {
"singular": "User",
"plural": "Users"
},
"operation": "query"
},
"mappings": {
"id": "Id",
"name": "Name",
"age": "Age",
"isAdmin": "IsAdmin"
},
"permissions": [
{
"role": "authenticated",
"actions": ["read"], // "execute" only when source.type = stored-procedure
"fields": {
"include": ["id", "name", "age", "isAdmin"],
"exclude": []
},
"policy": {
"database": "@claims.userId eq @item.id"
}
},
{
"role": "admin",
"actions": ["create", "read", "update", "delete"],
"fields": {
"include": ["*"],
"exclude": []
},
"policy": {
"database": "@claims.userRole eq 'UserAdmin'"
}
}
]
}
}
}
Fonte
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity} |
source |
oggetto | ✔️ Sì | Nessuno |
La configurazione {entity}.source connette l'entità esposta all'API e il relativo oggetto di database sottostante. Questa proprietà specifica la tabella di database, la vista o la stored procedure rappresentata dall'entità, stabilendo un collegamento diretto per il recupero e la manipolazione dei dati.
Per scenari semplici in cui l'entità esegue il mapping diretto a una singola tabella di database, la proprietà di origine richiede solo il nome dell'oggetto di database. Questa semplicità semplifica la configurazione rapida per i casi d'uso comuni: "source": "dbo.User".
Formato
{
"entities": {
"<entity-name>": {
"source": {
"object": <string>,
"type": <"view" | "stored-procedure" | "table">,
"key-fields": <array of strings>,
"parameters": { // only when source.type = stored-procedure
"<name>": <string | number | boolean>
}
}
}
}
}
Proprietà
| Obbligatorio | Digitare | |
|---|---|---|
object |
✔️ Sì | corda |
type |
✔️ Sì | stringa enumerazione |
parameters |
❌ No | oggetto |
key-fields |
❌ No | matrice di stringhe |
Esempi
1. Mapping tabella semplice:
In questo esempio viene illustrato come associare un'entità User a una tabella di origine dbo.Users.
sql
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
configurazione
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
}
}
}
}
2. Esempio di stored procedure:
In questo esempio viene illustrato come associare un'entità User a un processo di origine dbo.GetUsers.
sql
CREATE PROCEDURE GetUsers
@IsAdmin BIT
AS
SELECT Id, Name, Age, IsAdmin
FROM dbo.Users
WHERE IsAdmin = @IsAdmin;
configurazione
{
"entities": {
"User": {
"source": {
"type": "stored-procedure",
"object": "GetUsers",
"parameters": {
"IsAdmin": "boolean"
}
},
"mappings": {
"Id": "id",
"Name": "name",
"Age": "age",
"IsAdmin": "isAdmin"
}
}
}
}
La proprietà mappings è facoltativa per le stored procedure.
Oggetto
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.source |
object |
corda | ✔️ Sì | Nessuno |
Nome dell'oggetto di database da utilizzare. Se l'oggetto appartiene allo schema dbo, specificare lo schema è facoltativo. Inoltre, è possibile usare o omettere parentesi quadre intorno ai nomi degli oggetti ( ad esempio, [dbo].[Users] e dbo.Users).
Esempi
sql
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
configurazione
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
}
}
}
}
notazione alternativa senza schema e parentesi quadre:
Se la tabella si trova nello schema dbo, è possibile omettere lo schema o le parentesi quadre:
{
"entities": {
"User": {
"source": {
"object": "Users",
"type": "table"
}
}
}
}
Tipo (entità)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.source |
type |
corda | ✔️ Sì | Nessuno |
La proprietà type identifica il tipo di oggetto di database sottostante l'entità, tra cui view, tablee stored-procedure. Questa proprietà è obbligatoria e non ha alcun valore predefinito.
Formato
{
"entities": {
"<entity-name>": {
"type": <"view" | "stored-procedure" | "table">
}
}
}
Valori
| Valore | Descrizione |
|---|---|
table |
Rappresenta una tabella. |
stored-procedure |
Rappresenta una stored procedure. |
view |
Rappresenta una visualizzazione. |
Esempi
1. Esempio di tabella:
sql
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
configurazione
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
}
}
}
}
2. Esempio di visualizzazione:
sql
CREATE VIEW dbo.AdminUsers AS
SELECT Id, Name, Age
FROM dbo.Users
WHERE IsAdmin = 1;
configurazione
{
"entities": {
"AdminUsers": {
"source": {
"object": "dbo.AdminUsers",
"type": "view",
"key-fields": ["Id"]
},
"mappings": {
"Id": "id",
"Name": "name",
"Age": "age"
}
}
}
}
Nota: Specificare key-fields è importante per le visualizzazioni perché non dispongono di chiavi primarie intrinseche.
3. Esempio di stored procedure:
sql
CREATE PROCEDURE dbo.GetUsers (@IsAdmin BIT)
AS
SELECT Id, Name, Age, IsAdmin
FROM dbo.Users
WHERE IsAdmin = @IsAdmin;
configurazione
{
"entities": {
"User": {
"source": {
"type": "stored-procedure",
"object": "GetUsers",
"parameters": {
"IsAdmin": "boolean"
}
}
}
}
}
Campi chiave
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.source |
key-fields |
matrice di stringhe | ❌ No | Nessuno |
La proprietà {entity}.key-fields è particolarmente necessaria per le entità supportate dalle viste, quindi Generatore API dati sa come identificare e restituire un singolo elemento. Se type è impostato su view senza specificare key-fields, il motore rifiuta l'avvio. Questa proprietà è consentita con tabelle e stored procedure, ma non viene usata in tali casi.
Importante
Questa proprietà è obbligatoria se il tipo di oggetto è un view.
Formato
{
"entities": {
"<entity-name>": {
"source": {
"type": <"view" | "stored-procedure" | "table">,
"key-fields": <array of strings>
}
}
}
}
Esempio: Visualizzazione con campi chiave
In questo esempio viene utilizzata la visualizzazione dbo.AdminUsers con Id indicato come campo chiave.
sql
CREATE VIEW dbo.AdminUsers AS
SELECT Id, Name, Age
FROM dbo.Users
WHERE IsAdmin = 1;
configurazione
{
"entities": {
"AdminUsers": {
"source": {
"object": "dbo.AdminUsers",
"type": "view",
"key-fields": ["Id"]
}
}
}
}
Parametri
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.source |
parameters |
oggetto | ❌ No | Nessuno |
La proprietà parameters all'interno di entities.{entity}.source viene usata per le entità supportate dalle stored procedure. Garantisce il mapping corretto dei nomi dei parametri e dei tipi di dati richiesti dalla stored procedure.
Importante
La proprietà parameters è obbligatoria se il type dell'oggetto è stored-procedure e il parametro è obbligatorio.
Formato
{
"entities": {
"<entity-name>": {
"source": {
"type": "stored-procedure",
"parameters": {
"<parameter-name-1>": <string | number | boolean>,
"<parameter-name-2>": <string | number | boolean>
}
}
}
}
}
Esempio 1: Stored procedure senza parametri
sql
CREATE PROCEDURE dbo.GetUsers AS
SELECT Id, Name, Age, IsAdmin FROM dbo.Users;
configurazione
{
"entities": {
"Users": {
"source": {
"object": "dbo.GetUsers",
"type": "stored-procedure"
}
}
}
}
Esempio 2: Stored procedure con parametri
sql
CREATE PROCEDURE dbo.GetUser (@userId INT) AS
SELECT Id, Name, Age, IsAdmin FROM dbo.Users
WHERE Id = @userId;
configurazione
{
"entities": {
"User": {
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
}
}
}
}
Autorizzazioni
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity} |
permissions |
oggetto | ✔️ Sì | Nessuno |
Questa sezione definisce chi può accedere all'entità correlata e quali azioni sono consentite. Le autorizzazioni sono definite in termini di ruoli e operazioni CRUD: create, read, updatee delete. La sezione permissions specifica quali ruoli possono accedere all'entità correlata e usando le azioni.
Formato
{
"entities": {
"<entity-name>": {
"permissions": [
{
"actions": ["create", "read", "update", "delete", "execute", "*"]
}
]
}
}
}
| Azione | Descrizione |
|---|---|
create |
Consente di creare un nuovo record nell'entità. |
read |
Consente la lettura o il recupero di record dall'entità. |
update |
Consente di aggiornare i record esistenti nell'entità. |
delete |
Consente di eliminare record dall'entità. |
execute |
Consente l'esecuzione di una stored procedure o di un'operazione. |
* |
Concede tutte le operazioni CRUD applicabili. |
Esempi
esempio 1: Ruolo anonimo nell'entità utente
In questo esempio, il ruolo anonymous viene definito con accesso a tutte le azioni possibili nell'entità User.
{
"entities": {
"User": {
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
]
}
}
}
esempio 2: Azioni miste per ruolo anonimo
Questo esempio illustra come combinare azioni stringa e matrice di oggetti per l'entità User.
{
"entities": {
"User": {
"permissions": [
{
"role": "anonymous",
"actions": [
{ "action": "read" },
"create"
]
}
]
}
}
}
ruolo anonimo: consente agli utenti anonimi di leggere tutti i campi ad eccezione di un campo sensibile ipotetico (ad esempio, secret-field). L'uso di "include": ["*"] con "exclude": ["secret-field"] nasconde secret-field consentendo l'accesso a tutti gli altri campi.
ruolo autenticato: consente agli utenti autenticati di leggere e aggiornare campi specifici. Ad esempio, includendo in modo esplicito id, namee age, ma escludendo isAdmin può illustrare come le esclusioni eseguono l'override delle inclusioni.
ruolo di amministratore: gli amministratori possono eseguire tutte le operazioni (*) in tutti i campi senza esclusioni. Se si specifica "include": ["*"] con una matrice "exclude": [] vuota, viene concesso l'accesso a tutti i campi.
Questa configurazione:
"fields": {
"include": [],
"exclude": []
}
è in effetti identico a:
"fields": {
"include": ["*"],
"exclude": []
}
Considerare anche questa configurazione:
"fields": {
"include": [],
"exclude": ["*"]
}
In questo modo non vengono inclusi campi in modo esplicito e tutti i campi vengono esclusi, che in genere limitano completamente l'accesso.
uso pratico: una configurazione di questo tipo potrebbe sembrare controintuitiva poiché limita l'accesso a tutti i campi. Tuttavia, può essere usato negli scenari in cui un ruolo esegue determinate azioni (ad esempio la creazione di un'entità) senza accedere ad alcun dato.
Lo stesso comportamento, ma con sintassi diversa, sarebbe:
"fields": {
"include": ["Id", "Name"],
"exclude": ["*"]
}
Questa configurazione tenta di includere solo campi Id e Name, ma esclude tutti i campi a causa del carattere jolly in exclude.
Un altro modo per esprimere la stessa logica sarebbe:
"fields": {
"include": ["Id", "Name"],
"exclude": ["Id", "Name"]
}
Dato che exclude ha la precedenza su include, specificando exclude: ["*"] significa che tutti i campi vengono esclusi, anche quelli in include. Pertanto, a prima vista, questa configurazione potrebbe sembrare impedire l'accessibilità di tutti i campi.
Ilinverso: se lo scopo è concedere l'accesso solo ai campi Id e Name, è più chiaro e affidabile specificare solo tali campi nella sezione include senza usare un carattere jolly di esclusione:
"fields": {
"include": ["Id", "Name"],
"exclude": []
}
Proprietà
| Obbligatorio | Digitare | |
|---|---|---|
role |
✔️ Sì | corda |
| o actions (matrice di oggetti) |
✔️ Sì | matrice di oggetti o stringhe |
Ruolo
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.permissions |
role |
corda | ✔️ Sì | Nessuno |
Stringa contenente il nome del ruolo a cui si applica l'autorizzazione definita. I ruoli impostano il contesto delle autorizzazioni in cui deve essere eseguita una richiesta. Per ogni entità definita nella configurazione di runtime, è possibile definire un set di ruoli e autorizzazioni associate che determinano come è possibile accedere all'entità tramite endpoint REST e GraphQL. I ruoli non sono additivi.
Generatore API dati valuta le richieste nel contesto di un singolo ruolo:
| Ruolo | Descrizione |
|---|---|
anonymous |
Non viene presentato alcun token di accesso |
authenticated |
Viene presentato un token di accesso valido |
<custom-role> |
Viene presentato un token di accesso valido e l'intestazione HTTP X-MS-API-ROLE specifica un ruolo presente nel token |
Formato
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <"anonymous" | "authenticated" | "custom-role">,
"actions": ["create", "read", "update", "delete", "execute", "*"],
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
}
}
]
}
}
}
Esempi
Questo esempio definisce un ruolo denominato reader con solo autorizzazioni di read per l'entità User.
{
"entities": {
"User": {
"permissions": [
{
"role": "reader",
"actions": ["read"]
}
]
}
}
}
È possibile usare <custom-role> quando viene presentato un token di accesso valido e è inclusa l'intestazione HTTP X-MS-API-ROLE, specificando un ruolo utente incluso anche nell'attestazione dei ruoli del token di accesso. Di seguito sono riportati esempi di richieste GET all'entità User, inclusi sia il token di connessione dell'autorizzazione che l'intestazione X-MS-API-ROLE, nella base dell'endpoint REST /api in localhost usando lingue diverse.
GET https://localhost:5001/api/User
Authorization: Bearer <your_access_token>
X-MS-API-ROLE: custom-role
Azioni (matrice di stringhe)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.permissions |
actions |
oneOf [string, array] | ✔️ Sì | Nessuno |
Matrice di valori stringa che illustra in dettaglio le operazioni consentite per il ruolo associato. Per gli oggetti di database table e view, i ruoli possono usare qualsiasi combinazione di azioni create, read, updateo delete. Per le stored procedure, i ruoli possono avere solo l'azione execute.
| Azione | Operazione SQL |
|---|---|
* |
Carattere jolly, inclusa l'esecuzione |
create |
Inserire una o più righe |
read |
Selezionare una o più righe |
update |
Modificare una o più righe |
delete |
Eliminare una o più righe |
execute |
Esegue una stored procedure |
Nota
Per le stored procedure, l'azione con caratteri jolly (*) si espande solo all'azione execute. Per tabelle e viste, si espande fino a create, read, updatee delete.
Esempi
In questo esempio vengono concesse autorizzazioni create e read a un ruolo denominato contributor e delete autorizzazioni per un ruolo denominato auditor nell'entità User.
{
"entities": {
"User": {
"permissions": [
{
"role": "auditor",
"actions": ["delete"]
},
{
"role": "contributor",
"actions": ["read", "create"]
}
]
}
}
}
Un altro esempio:
{
"entities": {
"User": {
"permissions": [
{
"role": "contributor",
"actions": ["read", "create"]
}
]
}
}
}
Azioni (matrice di oggetti)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.permissions |
actions |
matrice di stringhe | ✔️ Sì | Nessuno |
Matrice di oggetti azione che illustra in dettaglio le operazioni consentite per il ruolo associato. Per gli oggetti table e view, i ruoli possono usare qualsiasi combinazione di create, read, updateo delete. Per le stored procedure, è consentito solo execute.
Nota
Per le stored procedure, l'azione con caratteri jolly (*) si espande solo execute. Per tabelle/viste, si espande fino a create, read, updatee delete.
Formato
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": <array of strings>,
"policy": <object>
}
]
}
]
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
action |
✔️ Sì | corda | Nessuno |
fields |
❌ No | matrice di stringhe | Nessuno |
policy |
❌ No | oggetto | Nessuno |
Esempio
Questo esempio concede solo read autorizzazione al ruolo auditor per l'entità User, con restrizioni di campo e criteri.
{
"entities": {
"User": {
"permissions": [
{
"role": "auditor",
"actions": [
{
"action": "read",
"fields": {
"include": ["*"],
"exclude": ["last_login"]
},
"policy": {
"database": "@item.IsAdmin eq false"
}
}
]
}
]
}
}
}
Azione
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.permissions.actions[] |
action |
corda | ✔️ Sì | Nessuno |
Specifica l'operazione specifica consentita nell'oggetto di database.
Valori
| Tabelle | Visualizzazioni | Stored procedure | Descrizione | |
|---|---|---|---|---|
create |
✔️ Sì | ✔️ Sì | ❌ No | Creare nuovi elementi |
read |
✔️ Sì | ✔️ Sì | ❌ No | Leggere gli elementi esistenti |
update |
✔️ Sì | ✔️ Sì | ❌ No | Aggiornare o sostituire elementi |
delete |
✔️ Sì | ✔️ Sì | ❌ No | Elimina elementi |
execute |
❌ No | ❌ No | ✔️ Sì | Eseguire operazioni a livello di codice |
Formato
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": "<role>",
"actions": [
{
"action": "<string>",
"fields": {
"include": [/* fields */],
"exclude": [/* fields */]
},
"policy": {
"database": "<predicate>"
}
}
]
}
]
}
}
}
Esempio
Di seguito è riportato un esempio in cui anonymous gli utenti possono execute una stored procedure e read dalla tabella User.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read"
}
]
}
]
},
"GetUser": {
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
},
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "execute"
}
]
}
]
}
}
}
Campi
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.permissions.actions[] |
fields |
oggetto | ❌ No | Nessuno |
Specifiche granulari per i campi specifici a cui è consentito l'accesso per l'oggetto di database. La configurazione del ruolo è un tipo di oggetto con due proprietà interne, include e exclude. Questi valori supportano la definizione granulare delle colonne di database (campi) a cui è consentito l'accesso nella sezione fields.
Formato
{
"entities": {
<string>: {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
},
"policy": <object>
}
]
}
]
}
}
}
Esempi
In questo esempio, il ruolo anonymous può leggere da tutti i campi tranne id, ma può usare tutti i campi durante la creazione di un elemento.
{
"entities": {
"Author": {
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read",
"fields": {
"include": [ "*" ],
"exclude": [ "id" ]
}
},
{ "action": "create" }
]
}
]
}
}
}
Includere ed escludere il lavoro insieme. Il carattere jolly * nella sezione include indica tutti i campi. I campi indicati nella sezione exclude hanno la precedenza sui campi indicati nella sezione include. La definizione viene convertita in includere tutti i campi ad eccezione del campo 'last_updated'.
"Book": {
"source": "books",
"permissions": [
{
"role": "anonymous",
"actions": [ "read" ],
// Include All Except Specific Fields
"fields": {
"include": [ "*" ],
"exclude": [ "secret-field" ]
}
},
{
"role": "authenticated",
"actions": [ "read", "update" ],
// Explicit Include and Exclude
"fields": {
"include": [ "id", "title", "secret-field" ],
"exclude": [ "secret-field" ]
}
},
{
"role": "author",
"actions": [ "*" ],
// Include All With No Exclusions (default)
"fields": {
"include": ["*"],
"exclude": []
}
}
]
}
Politica
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.permissions.actions[] |
policy |
oggetto | ❌ No | Nessuno |
La sezione policy, definita per action, definisce le regole di sicurezza a livello di elemento (criteri di database) che limitano i risultati restituiti da una richiesta. La sottosezione database indica l'espressione dei criteri di database valutata durante l'esecuzione della richiesta.
Formato
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": <object>,
"policy": {
"database": <string>
}
}
]
}
]
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
database |
✔️ Sì | corda | Nessuno |
Descrizione
Criterio di database: un'espressione simile a OData che viene convertita in un predicato di query valuta il database, inclusi operatori come eq, lte gt. Affinché i risultati vengano restituiti per una richiesta, il predicato di query della richiesta risolto da un criterio di database deve restituire true durante l'esecuzione nel database.
| Criteri elemento di esempio | Predicato |
|---|---|
@item.OwnerId eq 2000 |
WHERE Table.OwnerId = 2000 |
@item.OwnerId gt 2000 |
WHERE Table.OwnerId > 2000 |
@item.OwnerId lt 2000 |
WHERE Table.OwnerId < 2000 |
Un
predicateè un'espressione che restituisce TRUE o FALSE. I predicati vengono usati nella condizione di ricerca di clausole WHERE e clausole HAVING, le condizioni di join di clausole FROM e altri costrutti in cui è necessario un valore booleano. (Microsoft Learn Docs)
Criteri di database
È possibile usare due tipi di direttive per gestire i criteri di database durante la creazione di un'espressione di criteri di database:
| Direttiva | Descrizione |
|---|---|
@claims |
Accedere a un'attestazione all'interno del token di accesso convalidato fornito nella richiesta |
@item |
Rappresenta un campo dell'entità per la quale sono definiti i criteri del database |
Nota
Quando è configurata l'autenticazione app Web statiche di Azure (EasyAuth), sono disponibili un numero limitato di tipi di attestazioni da usare nei criteri di database: identityProvider, userId, userDetailse userRoles. Per altre informazioni, vedere la documentazione
Ecco alcuni criteri di database di esempio:
@claims.userId eq @item.OwnerId@claims.userId gt @item.OwnerId@claims.userId lt @item.OwnerId
Generatore API dati confronta il valore dell'attestazione UserId con il valore del campo del database OwnerId. Il payload del risultato include solo i record che soddisfano sia i metadati della richiesta sia l'espressione dei criteri di database.
Limitazioni
I criteri di database sono supportati per tabelle e viste. Le stored procedure non possono essere configurate con i criteri.
I criteri di database non impediscono l'esecuzione delle richieste all'interno del database. Questo comportamento è dovuto al fatto che vengono risolti come predicati nelle query generate passate al motore di database.
I criteri di database sono supportati solo per la creazione di actions, lettura, aggiornamentoe eliminare. Poiché non è presente alcun predicato in una chiamata a una stored procedure, non possono essere accodati.
Operatori simili a OData supportati
| Operatore | Descrizione | Sintassi di esempio |
|---|---|---|
and |
AND logico | "@item.status eq 'active' and @item.age gt 18" |
or |
OR logico | "@item.region eq 'US' or @item.region eq 'EU'" |
eq |
Uguale | "@item.type eq 'employee'" |
gt |
Maggiore | "@item.salary gt 50000" |
lt |
Meno di | "@item.experience lt 5" |
Per altre informazioni, vedere operatori binari.
| Operatore | Descrizione | Sintassi di esempio |
|---|---|---|
- |
Nega (numerico) | "@item.balance lt -100" |
not |
Negazione logica (NOT) | "not @item.status eq 'inactive'" |
Per altre informazioni, vedere operatori unari.
Restrizioni relative al nome del campo dell'entità
-
Rules: deve iniziare con una lettera o un carattere di sottolineatura (
_), seguito da un massimo di 127 lettere, caratteri di sottolineatura (_) o cifre (0-9). - Impatto: i campi che non sono aderendo a queste regole non possono essere usati direttamente nei criteri di database.
-
Soluzione: usare la sezione
mappingsper creare alias per i campi che non soddisfano queste convenzioni di denominazione; i mapping assicurano che tutti i campi possano essere inclusi nelle espressioni dei criteri.
Utilizzo di mappings per i campi non conformi
Se i nomi dei campi dell'entità non soddisfano le regole di sintassi OData o si vuole semplicemente eseguirne l'alias per altri motivi, è possibile definire alias nella sezione mappings della configurazione.
{
"entities": {
"<entity-name>": {
"mappings": {
"<field-1-name>": <string>,
"<field-2-name>": <string>,
"<field-3-name>": <string>
}
}
}
}
In questo esempio, field-1-name è il nome del campo del database originale che non soddisfa le convenzioni di denominazione OData. La creazione di una mappa a field-1-name e field-1-alias consente di fare riferimento a questo campo nelle espressioni dei criteri di database senza problemi. Questo approccio non solo consente di aderire alle convenzioni di denominazione OData, ma migliora anche la chiarezza e l'accessibilità del modello di dati all'interno degli endpoint GraphQL e RESTful.
Esempi
Si consideri un'entità denominata Employee all'interno di una configurazione dell'API dati che usa sia le attestazioni che le direttive dell'elemento. Garantisce che l'accesso ai dati venga gestito in modo sicuro in base ai ruoli utente e alla proprietà dell'entità:
{
"entities": {
"Employee": {
"source": {
"object": "HRUNITS",
"type": "table",
"key-fields": ["employee NUM"],
"parameters": {}
},
"mappings": {
"employee NUM": "EmployeeId",
"employee Name": "EmployeeName",
"department COID": "DepartmentId"
},
"policy": {
"database": "@claims.role eq 'HR' or @claims.userId eq @item.EmployeeId"
}
}
}
}
definizione di entità: l'entità Employee è configurata per le interfacce REST e GraphQL, a indicare che i dati possono essere sottoposti a query o manipolati tramite questi endpoint.
Configurazione origine: identifica il HRUNITS nel database, con employee NUM come campo chiave.
Mapping: gli alias vengono usati rispettivamente per eseguire il mapping di employee NUM, employee Namee department COID a EmployeeId, EmployeeNamee DepartmentId, semplificando rispettivamente i nomi dei campi e nascondendo potenzialmente i dettagli dello schema del database sensibili.
'applicazione criteri: la sezione policy applica criteri di database usando un'espressione simile a OData. Questo criterio limita l'accesso ai dati agli utenti con il ruolo HR (@claims.role eq 'HR') o agli utenti la cui attestazione UserId corrisponde EmployeeId, ovvero l'alias del campo , nel database (@claims.userId eq @item.EmployeeId). Garantisce che i dipendenti possano accedere ai propri record solo a meno che non appartengano al reparto risorse umane. I criteri possono applicare la sicurezza a livello di riga in base alle condizioni dinamiche.
Banca dati
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.permissions.actions.policy |
database |
oggetto | ✔️ Sì | Nessuno |
La sezione policy, definita per action, definisce le regole di sicurezza a livello di elemento (criteri di database) che limitano i risultati restituiti da una richiesta. La sottosezione database indica l'espressione dei criteri di database valutata durante l'esecuzione della richiesta.
Formato
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
},
"policy": {
"database": <string>
}
}
]
}
]
}
}
}
Questa proprietà indica l'espressione dei criteri di database valutata durante l'esecuzione della richiesta. La stringa di criteri è un'espressione OData che viene convertita in un predicato di query valutato dal database. Ad esempio, l'espressione di criteri @item.OwnerId eq 2000 viene convertita nel predicato della query WHERE <schema>.<object-name>.OwnerId = 2000.
Nota
Un predicato è un'espressione che evalute per TRUE, FALSEo UNKNOWN. I predicati vengono usati in:
- Condizione di ricerca delle clausole di
WHERE - Condizione di ricerca delle clausole di
FROM - Condizioni di join delle clausole di
FROM - Altri costrutti in cui è necessario un valore booleano.
Per altre informazioni, vedere predicati.
Affinché i risultati vengano restituiti per una richiesta, il predicato di query della richiesta risolto da un criterio di database deve restituire true durante l'esecuzione nel database.
È possibile usare due tipi di direttive per gestire i criteri di database durante la creazione di un'espressione di criteri di database:
| Descrizione | |
|---|---|
@claims |
Accede a un'attestazione all'interno del token di accesso convalidato fornito nella richiesta |
@item |
Rappresenta un campo dell'entità per la quale sono definiti i criteri del database |
Nota
Un numero limitato di tipi di attestazione è disponibile per l'uso nei criteri di database quando è configurata l'autenticazione di App Web statiche di Azure (EasyAuth). Questi tipi di attestazione includono: identityProvider, userId, userDetailse userRoles. Per altre informazioni, vedere dati dell'entità client di App Web statiche di Azure.
Esempi
Ad esempio, un'espressione di criteri di base può valutare se un campo specifico è true all'interno della tabella. In questo esempio viene valutato se il campo soft_delete è false.
{
"entities": {
"Manuscripts": {
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read",
"policy": {
"database": "@item.soft_delete eq false"
}
}
]
}
]
}
}
}
I predicati possono anche valutare i tipi di direttiva claims e item. Questo esempio esegue il pull del campo UserId dal token di accesso e lo confronta con il campo owner_id nella tabella di database di destinazione.
{
"entities": {
"Manuscript": {
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read",
"policy": {
"database": "@claims.userId eq @item.owner_id"
}
}
]
}
]
}
}
}
Limitazioni
- I criteri di database sono supportati per tabelle e viste. Le stored procedure non possono essere configurate con i criteri.
- I criteri di database non possono essere usati per impedire l'esecuzione di una richiesta all'interno di un database. Questa limitazione è dovuta al fatto che i criteri di database vengono risolti come predicati di query nelle query di database generate. Il motore di database valuta infine queste query.
- I criteri di database sono supportati solo per
actionscreate,read,updateedelete. - La sintassi delle espressioni OData dei criteri di database supporta solo questi scenari.
- Operatori binari inclusi, ma non limitati a;
and,or,eq,gtelt. Per ulteriori informazioni, vedereBinaryOperatorKind. - Operatori unari, ad esempio gli operatori
-(negate) enot. Per ulteriori informazioni, vedereUnaryOperatorKind.
- Operatori binari inclusi, ma non limitati a;
- I criteri di database hanno anche restrizioni correlate ai nomi dei campi.
- Nomi di campo entità che iniziano con una lettera o un carattere di sottolineatura, seguiti al massimo da 127 lettere, caratteri di sottolineatura o cifre.
- Questo requisito è in base alla specifica OData. Per altre informazioni, vedere OData Common Schema Definition Language.
Mancia
Non è possibile fare riferimento ai campi che non sono conformi alle restrizioni menzionate nei criteri di database. Come soluzione alternativa, configurare l'entità con una sezione mapping per assegnare alias conformi ai campi.
GraphQL (entità)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity} |
graphql |
oggetto | ❌ No | Nessuno |
Questo oggetto definisce se GraphQL è abilitato e il nome[s] usato per esporre l'entità come tipo GraphQL. Questo oggetto è facoltativo e viene usato solo se il nome o le impostazioni predefinite non sono sufficienti.
Questo segmento fornisce l'integrazione di un'entità nello schema GraphQL. Consente agli sviluppatori di specificare o modificare i valori predefiniti per l'entità in GraphQL. Questa configurazione garantisce che lo schema rifletta in modo accurato la struttura e le convenzioni di denominazione previste.
Formato
{
"entities": {
"<entity-name>": {
"graphql": {
"enabled": <true> (default) | <false>,
"type": {
"singular": <string>,
"plural": <string>
},
"operation": "query" (default) | "mutation"
}
}
}
}
{
"entities": {
"<entity-name>": {
"graphql": {
"enabled": <boolean>,
"type": <string-or-object>,
"operation": "query" (default) | "mutation"
}
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
enabled |
❌ No | booleano | Nessuno |
type |
❌ No | stringa o oggetto | Nessuno |
operation |
❌ No | stringa enumerazione | Nessuno |
Esempi
Questi due esempi sono equivalenti a livello funzionale.
{
"entities": {
"Author": {
"graphql": true
}
}
}
{
"entities": {
"Author": {
"graphql": {
"enabled": true
}
}
}
}
In questo esempio l'entità definita è Book, che indica che si sta gestendo un set di dati correlati ai libri nel database. La configurazione per l'entità Book all'interno del segmento GraphQL offre una struttura chiara su come deve essere rappresentata e interagita con in uno schema GraphQL.
proprietà Enabled: l'entità Book viene resa disponibile tramite GraphQL ("enabled": true), ovvero gli sviluppatori e gli utenti possono eseguire query o modificare i dati dei libri tramite operazioni GraphQL.
proprietà Type: l'entità viene rappresentata con il nome singolare "Book" e il nome plurale "Books" nello schema GraphQL. Questa distinzione garantisce che quando si eseguono query su un singolo libro o più libri, lo schema offre tipi denominati in modo intuitivo (Book per una singola voce, Books per un elenco), migliorando l'usabilità dell'API.
proprietà Operation: l'operazione è impostata su "query", a indicare che l'interazione primaria con l'entità Book tramite GraphQL deve eseguire query sui dati (recuperando) anziché modificarli (creazione, aggiornamento o eliminazione). Questa configurazione è allineata ai modelli di utilizzo tipici in cui i dati dei libri vengono letti più frequentemente rispetto alla modifica.
{
"entities": {
"Book": {
...
"graphql": {
"enabled": true,
"type": {
"singular": "Book",
"plural": "Books"
},
"operation": "query"
},
...
}
}
}
Tipo (entità GraphQL)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.graphql |
type |
oneOf [string, object] | ❌ No | {entity-name} |
Questa proprietà determina la convenzione di denominazione per un'entità all'interno dello schema GraphQL. Supporta sia i valori stringa scalari che i tipi di oggetto. Il valore dell'oggetto specifica le forme singolari e plurali. Questa proprietà fornisce un controllo granulare sulla leggibilità e sull'esperienza utente dello schema.
Formato
{
"entities": {
<entity-name>: {
"graphql": {
"type": <string>
}
}
}
}
{
"entities": {
<entity-name>: {
"graphql": {
"type": {
"singular": <string>,
"plural": <string>
}
}
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
singular |
❌ No | corda | Nessuno |
plural |
❌ No | corda | N/D (impostazione predefinita: singolare) |
Esempi
Per un maggiore controllo sul tipo GraphQL, è possibile configurare il modo in cui il nome singolare e plurale viene rappresentato in modo indipendente.
Se plural manca o omesso (ad esempio, valore scalare) Il generatore di API dati tenta di pluralizzare automaticamente il nome, seguendo le regole in inglese per la pluralizzazione (ad esempio: https://engdic.org/singular-and-plural-noun-rules-definitions-examples)
{
"entities" {
"<entity-name>": {
...
"graphql": {
...
"type": {
"singular": "User",
"plural": "Users"
}
}
}
}
}
È possibile specificare un nome di entità personalizzato usando il parametro type con un valore stringa. In questo esempio, il motore distingue automaticamente tra le varianti singolari e plurali di questo nome usando regole in inglese comuni per la pluralizzazione.
{
"entities": {
"Author": {
"graphql": {
"type": "bookauthor"
}
}
}
}
Se si sceglie di specificare i nomi in modo esplicito, utilizzare le proprietà type.singular e type.plural. In questo esempio vengono impostati in modo esplicito entrambi i nomi.
{
"entities": {
"Author": {
"graphql": {
"type": {
"singular": "bookauthor",
"plural": "bookauthors"
}
}
}
}
}
Entrambi gli esempi sono equivalenti a livello funzionale. Entrambi restituiscono lo stesso output JSON per una query GraphQL che usa il nome dell'entità bookauthors.
{
bookauthors {
items {
first_name
last_name
}
}
}
{
"data": {
"bookauthors": {
"items": [
{
"first_name": "Henry",
"last_name": "Ross"
},
{
"first_name": "Jacob",
"last_name": "Hancock"
},
...
]
}
}
}
Operazione (entità GraphQL)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.graphql |
operation |
stringa enumerazione | ❌ No | Nessuno |
Per le entità mappate alle stored procedure, la proprietà operation definisce il tipo di operazione GraphQL (query o mutazione) in cui la stored procedure è accessibile. Questa impostazione consente l'organizzazione logica dello schema e la conformità alle procedure consigliate di GraphQL, senza alcun impatto sulle funzionalità.
Nota
Un'entità viene specificata come stored procedure impostando il valore della proprietà {entity}.type su stored-procedure. Nel caso di una stored procedure, viene creato automaticamente un nuovo tipo GraphQL executeXXX. Tuttavia, la proprietà operation consente allo sviluppatore di coerare la posizione di tale tipo nelle parti mutation o query dello schema. Questa proprietà consente l'hygene dello schema e non vi è alcun impatto funzionale indipendentemente dal valore operation.
Se mancante, il valore predefinito operation è mutation.
Formato
{
"entities": {
"<entity-name>": {
"graphql": {
"operation": "query" (default) | "mutation"
}
}
}
}
Valori
Ecco un elenco di valori consentiti per questa proprietà:
| Descrizione | |
|---|---|
query |
La stored procedure sottostante viene esposta come query |
mutation |
La stored procedure sottostante viene esposta come mutazione |
Esempi
Quando operation è mutation, lo schema GraphQL sarà simile al seguente:
type Mutation {
executeGetCowrittenBooksByAuthor(
searchType: String = "S"
): [GetCowrittenBooksByAuthor!]!
}
Quando operation è query, lo schema GraphQL sarà simile al seguente:
Lo schema GraphQL sarà simile al seguente:
type Query {
executeGetCowrittenBooksByAuthor(
searchType: String = "S"
): [GetCowrittenBooksByAuthor!]!
}
Nota
La proprietà operation riguarda solo la posizione dell'operazione nello schema GraphQL, non modifica il comportamento dell'operazione.
Abilitato (entità GraphQL)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.graphql |
enabled |
booleano | ❌ No | Vero |
Abilita o disabilita l'endpoint GraphQL. Controlla se un'entità è disponibile tramite endpoint GraphQL. Attivando o disattivando la proprietà enabled, gli sviluppatori espongono in modo selettivo le entità dallo schema GraphQL.
Formato
{
"entities": {
"<entity-name>": {
"graphql": {
"enabled": <true> (default) | <false>
}
}
}
}
REST (entità)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity} |
rest |
oggetto | ❌ No | Nessuno |
La sezione rest del file di configurazione è dedicata all'ottimizzazione degli endpoint RESTful per ogni entità di database. Questa funzionalità di personalizzazione garantisce che l'API REST esposta soddisfi requisiti specifici, migliorando sia l'utilità che le funzionalità di integrazione. Risolve potenziali mancate corrispondenze tra le impostazioni derivate predefinite e i comportamenti degli endpoint desiderati.
Formato
{
"entities": {
"<entity-name>": {
"rest": {
"enabled": <true> (default) | <false>,
"path": <string; default: "<entity-name>">,
"methods": <array of strings; default: ["GET", "POST"]>
}
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
enabled |
✔️ Sì | booleano | Vero |
path |
❌ No | corda | /<entity-name> |
methods |
❌ No | matrice di stringhe | OTTIENI |
Esempi
Questi due esempi sono equivalenti a livello funzionale.
{
"entities": {
"Author": {
"source": {
"object": "dbo.authors",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
],
"rest": true
}
}
}
{
"entities": {
"Author": {
...
"rest": {
"enabled": true
}
}
}
}
Ecco un altro esempio di configurazione REST per un'entità.
{
"entities" {
"User": {
"rest": {
"enabled": true,
"path": "/User"
},
...
}
}
}
Abilitato (entità REST)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.rest |
enabled |
booleano | ❌ No | Vero |
Questa proprietà funge da interruttore per la visibilità delle entità all'interno dell'API REST. Impostando la proprietà enabled su true o false, gli sviluppatori possono controllare l'accesso a entità specifiche, abilitando una superficie API personalizzata in linea con i requisiti di sicurezza e funzionalità delle applicazioni.
Formato
{
"entities": {
"<entity-name>": {
"rest": {
"enabled": <true> (default) | <false>
}
}
}
}
Percorso (entità REST)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.rest |
path |
corda | ❌ No | Nessuno |
La proprietà path specifica il segmento URI usato per accedere a un'entità tramite l'API REST. Questa personalizzazione consente percorsi di endpoint più descrittivi o semplificati oltre il nome dell'entità predefinito, migliorando la navigazione api e l'integrazione lato client. Per impostazione predefinita, il percorso è /<entity-name>.
Formato
{
"entities": {
"<entity-name>": {
"rest": {
"path": <string; default: "<entity-name>">
}
}
}
}
Esempi
In questo esempio viene esposta l'entità Author usando l'endpoint /auth.
{
"entities": {
"Author": {
"rest": {
"path": "/auth"
}
}
}
}
Metodi (entità REST)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.rest |
methods |
matrice di stringhe | ❌ No | Nessuno |
Applicabile in modo specifico alle stored procedure, la proprietà methods definisce i verbi HTTP (ad esempio, GET, POST) a cui la routine può rispondere. I metodi consentono un controllo preciso sul modo in cui le stored procedure vengono esposte tramite l'API REST, garantendo la compatibilità con gli standard RESTful e le aspettative dei client. Questa sezione sottolinea l'impegno della piattaforma per la flessibilità e il controllo dello sviluppatore, consentendo una progettazione api precisa e intuitiva su misura per le esigenze specifiche di ogni applicazione.
Se omesso o mancante, il valore predefinito methods è POST.
Formato
{
"entities": {
"<entity-name>": {
"rest": {
"methods": ["GET" (default), "POST"]
}
}
}
}
Valori
Ecco un elenco di valori consentiti per questa proprietà:
| Descrizione | |
|---|---|
get |
Espone le richieste HTTP GET |
post |
Espone le richieste HTTP POST |
Esempi
In questo esempio viene indicato al motore che la stored procedure stp_get_bestselling_authors supporta solo le azioni HTTP GET.
{
"entities": {
"BestSellingAuthor": {
"source": {
"object": "dbo.stp_get_bestselling_authors",
"type": "stored-procedure",
"parameters": {
"depth": "number"
}
},
"rest": {
"path": "/best-selling-authors",
"methods": [ "get" ]
}
}
}
}
Mapping (entità)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity} |
mappings |
oggetto | ❌ No | Nessuno |
Sezione mappings consente di configurare alias o nomi esposti per i campi oggetto di database. I nomi esposti configurati si applicano sia agli endpoint GraphQL che REST.
Importante
Per le entità con GraphQL abilitato, il nome esposto configurato deve soddisfare i requisiti di denominazione graphQL. Per altre informazioni, vedere specifica dei nomi GraphQL.
Formato
{
"entities": {
"<entity-name>": {
"mappings": {
"<field-1-name>": "<field-1-alias>",
"<field-2-name>": "<field-2-alias>",
"<field-3-name>": "<field-3-alias>"
}
}
}
}
Esempi
In questo esempio, il campo sku_title dell'oggetto di database dbo.magazines viene esposto usando il nome title. Analogamente, il campo sku_status viene esposto come status negli endpoint REST e GraphQL.
{
"entities": {
"Magazine": {
...
"mappings": {
"sku_title": "title",
"sku_status": "status"
}
}
}
}
Ecco un altro esempio di mapping.
{
"entities": {
"Book": {
...
"mappings": {
"id": "BookID",
"title": "BookTitle",
"author": "AuthorName"
}
}
}
}
Mapping: l'oggetto mappings collega i campi del database (BookID, BookTitle, AuthorName) a nomi più intuitivi o standardizzati (id, title, author) utilizzati esternamente. Questo aliasing serve a diversi scopi:
chiarezza e coerenza: consente l'uso di nomi chiari e coerenti nell'API, indipendentemente dallo schema del database sottostante. Ad esempio,
BookIDnel database viene rappresentato comeidnell'API, rendendolo più intuitivo per gli sviluppatori che interagiscono con l'endpoint.GraphQL Compliance: fornendo un meccanismo ai nomi dei campi alias, garantisce che i nomi esposti tramite l'interfaccia GraphQL siano conformi ai requisiti di denominazione di GraphQL. L'attenzione ai nomi è importante perché GraphQL ha regole rigorose sui nomi (ad esempio, senza spazi, deve iniziare con una lettera o un carattere di sottolineatura e così via). Ad esempio, se un nome di campo del database non soddisfa questi criteri, può essere aliasato a un nome conforme tramite mapping.
flessibilità: questo aliasing aggiunge un livello di astrazione tra lo schema del database e l'API, consentendo le modifiche in una senza richiedere modifiche nell'altra. Ad esempio, una modifica del nome di campo nel database non richiede un aggiornamento alla documentazione dell'API o al codice lato client se il mapping rimane coerente.
nome campo offuscamento: il mapping consente l'offuscamento dei nomi di campo, che consente agli utenti non autorizzati di dedurre informazioni riservate sullo schema del database o sulla natura dei dati archiviati.
Protezione delle informazioni proprietarie: rinominando i campi, è anche possibile proteggere i nomi proprietari o la logica di business che potrebbero essere specificati tramite i nomi dei campi originali del database.
Relazioni (entità)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity} |
relationships |
oggetto | ❌ No | Nessuno |
Questo mapping di sezioni include un set di definizioni di relazione che eseguono il mapping del modo in cui le entità sono correlate ad altre entità esposte. Queste definizioni di relazione possono anche includere facoltativamente dettagli sugli oggetti di database sottostanti usati per supportare e applicare le relazioni. Gli oggetti definiti in questa sezione vengono esposti come campi GraphQL nell'entità correlata. Per altre informazioni, vedere suddivisione delle relazioni del generatore di API dati.
Nota
Le relazioni sono rilevanti solo per le query GraphQL. Gli endpoint REST accedono a una sola entità alla volta e non possono restituire tipi annidati.
La sezione relationships descrive come le entità interagiscono all'interno del generatore di API dati, illustrano in dettaglio le associazioni e il potenziale supporto del database per queste relazioni. La proprietà relationship-name per ogni relazione è obbligatoria e deve essere univoca in tutte le relazioni per una determinata entità. I nomi personalizzati garantiscono connessioni chiare e identificabili e mantengono l'integrità dello schema GraphQL generato da queste configurazioni.
| Relazione | Cardinalità | Esempio |
|---|---|---|
| uno-a-molti | many |
Un'entità categoria può essere correlata a molte entità todo |
| molti-a-uno | one |
Molte entità todo possono essere correlate a un'entità di categoria |
| molti-a-molti | many |
Un'entità todo può essere correlata a molte entità utente e un'entità utente può essere correlata a molte entità todo |
Formato
{
"entities": {
"<entity-name>": {
"relationships": {
"<relationship-name>": {
"cardinality": "one" | "many",
"target.entity": "<string>",
"source.fields": ["<string>"],
"target.fields": ["<string>"],
"linking.object": "<string>",
"linking.source.fields": ["<string>"],
"linking.target.fields": ["<string>"]
}
}
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
cardinality |
✔️ Sì | stringa enumerazione | Nessuno |
target.entity |
✔️ Sì | corda | Nessuno |
source.fields |
❌ No | matrice di stringhe | Nessuno |
target.fields |
❌ No | matrice di stringhe | Nessuno |
linking.<object-or-entity> |
❌ No | corda | Nessuno |
linking.source.fields |
❌ No | matrice di stringhe | Nessuno |
linking.target.fields |
❌ No | matrice di stringhe | Nessuno |
Esempi
Quando si considerano le relazioni, è consigliabile confrontare le differenze tra uno-a-molti, molti-a-uno e relazioni molti-a-molti.
Uno-a-molti
Si consideri innanzitutto un esempio di relazione con l'entità Category esposta con una relazione uno-a-molti con l'entità Book. In questo caso, la cardinalità è impostata su many. Ogni Category può avere più entità Book correlate, mentre ogni entità Book è associata solo a una singola entità Category.
{
"entities": {
"Book": {
...
},
"Category": {
"relationships": {
"category_books": {
"cardinality": "many",
"target.entity": "Book",
"source.fields": [ "id" ],
"target.fields": [ "category_id" ]
}
}
}
}
}
In questo esempio, l'elenco source.fields specifica il campo id dell'entità di origine (Category). Questo campo viene usato per connettersi all'elemento correlato nell'entità target. Viceversa, l'elenco target.fields specifica il campo category_id dell'entità di destinazione (Book). Questo campo viene usato per connettersi all'elemento correlato nell'entità source.
Con questa relazione definita, lo schema GraphQL esposto risultante dovrebbe essere simile a questo esempio.
type Category
{
id: Int!
...
books: [BookConnection]!
}
Molti-a-uno
Si consideri quindi molti-a-uno che imposta la cardinalità su one. L'entità Book esposta può avere una singola entità Category correlata. L'entità Category può avere più entità correlate Book.
{
"entities": {
"Book": {
"relationships": {
"books_category": {
"cardinality": "one",
"target.entity": "Category",
"source.fields": [ "category_id" ],
"target.fields": [ "id" ]
}
},
"Category": {
...
}
}
}
}
In questo caso, l'elenco source.fields specifica che il campo category_id dell'entità di origine (Book) fa riferimento al campo id dell'entità di destinazione correlata (Category). Inversamente, l'elenco target.fields specifica la relazione inversa. Con questa relazione, lo schema GraphQL risultante include ora un mapping da Libri a Categorie.
type Book
{
id: Int!
...
category: Category
}
Molti-a-molti
Infine, viene definita una relazione molti-a-molti con una cardinalità di many e più metadati per definire quali oggetti di database vengono usati per creare la relazione nel database di supporto. In questo caso, l'entità Book può avere più entità Author e viceversa l'entità Author può avere più entità Book.
{
"entities": {
"Book": {
"relationships": {
...,
"books_authors": {
"cardinality": "many",
"target.entity": "Author",
"source.fields": [ "id" ],
"target.fields": [ "id" ],
"linking.object": "dbo.books_authors",
"linking.source.fields": [ "book_id" ],
"linking.target.fields": [ "author_id" ]
}
},
"Category": {
...
},
"Author": {
...
}
}
}
}
In questo esempio, il source.fields e target.fields indicano entrambi che la tabella delle relazioni usa l'identificatore primario (id) delle entità di origine (Book) e di destinazione (Author). Il campo linking.object specifica che la relazione è definita nell'oggetto di database dbo.books_authors. Inoltre, linking.source.fields specifica che il campo book_id dell'oggetto di collegamento fa riferimento al campo id dell'entità Book e linking.target.fields specifica che il campo author_id dell'oggetto di collegamento fa riferimento al campo id dell'entità Author.
Questo esempio può essere descritto usando uno schema GraphQL simile a questo esempio.
type Book
{
id: Int!
...
authors: [AuthorConnection]!
}
type Author
{
id: Int!
...
books: [BookConnection]!
}
Cardinalità
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.relationships |
cardinality |
corda | ✔️ Sì | Nessuno |
Specifica se l'entità di origine corrente è correlata solo a una singola istanza dell'entità di destinazione o a più.
Valori
Ecco un elenco di valori consentiti per questa proprietà:
| Descrizione | |
|---|---|
one |
L'origine si riferisce solo a un record dalla destinazione |
many |
L'origine può essere correlata a record zero-a-molti dalla destinazione |
Entità di destinazione
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.relationships |
target.entity |
corda | ✔️ Sì | Nessuno |
Nome dell'entità definita altrove nella configurazione che rappresenta la destinazione della relazione.
Campi di origine
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.relationships |
source.fields |
array | ❌ No | Nessuno |
Parametro facoltativo per definire il campo usato per il mapping nell'entità di origine usata per connettersi all'elemento correlato nell'entità di destinazione.
Mancia
Questo campo non è obbligatorio se è presente una chiave esterna restrizione sul database tra i due oggetti di database che possono essere usati per dedurre automaticamente la relazione.
Campi di destinazione
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.relationships |
target.fields |
array | ❌ No | Nessuno |
Parametro facoltativo per definire il campo usato per il mapping nell'entità di destinazione usata per connettersi all'elemento correlato nell'entità di origine.
Mancia
Questo campo non è obbligatorio se è presente una chiave esterna restrizione sul database tra i due oggetti di database che possono essere usati per dedurre automaticamente la relazione.
Collegamento di oggetti o entità
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.relationships |
linking.object |
corda | ❌ No | Nessuno |
Per le relazioni molti-a-molti, il nome dell'oggetto di database o dell'entità che contiene i dati necessari per definire una relazione tra due altre entità.
Collegamento dei campi di origine
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.relationships |
linking.source.fields |
array | ❌ No | Nessuno |
Nome dell'oggetto di database o del campo dell'entità correlato all'entità di origine.
Collegamento dei campi di destinazione
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.relationships |
linking.target.fields |
array | ❌ No | Nessuno |
Nome dell'oggetto di database o del campo dell'entità correlato all'entità di destinazione.
Cache (entità)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.cache |
enabled |
booleano | ❌ No | Falso |
Abilita e configura la memorizzazione nella cache per l'entità.
Formato
You're right; the formatting doesn't match your style. Here’s the corrected version following your preferred documentation format:
```json
{
"entities": {
"<entity-name>": {
"cache": {
"enabled": <true> (default) | <false>,
"ttl-seconds": <integer; default: 5>
}
}
}
}
Proprietà
| Proprietà | Obbligatorio | Digitare | Default |
|---|---|---|---|
enabled |
❌ No | booleano | Falso |
ttl-seconds |
❌ No | numero intero | 5 |
Esempi
In questo esempio la cache è abilitata e gli elementi scadono dopo 30 secondi.
{
"entities": {
"Author": {
"cache": {
"enabled": true,
"ttl-seconds": 30
}
}
}
}
Abilitato (entità cache)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.{entity}.cache |
enabled |
booleano | ❌ No | Falso |
Abilita la memorizzazione nella cache per l'entità.
Supporto degli oggetti di database
| Tipo di oggetto | Supporto della cache |
|---|---|
| Tavolo | ✅ Sì |
| Vista | ✅ Sì |
| Stored Procedure | ✖️ No |
| Contenitore | ✖️ No |
Supporto intestazione HTTP
| Intestazione richiesta | Supporto della cache |
|---|---|
no-cache |
✖️ No |
no-store |
✖️ No |
max-age |
✖️ No |
public |
✖️ No |
private |
✖️ No |
etag |
✖️ No |
Formato
{
"entities": {
"<entity-name>": {
"cache": {
"enabled": <boolean> (default: false)
}
}
}
}
Esempi
In questo esempio la cache è disabilitata.
{
"entities": {
"Author": {
"cache": {
"enabled": false
}
}
}
}
TTL in secondi (entità cache)
| Genitore | Proprietà | Digitare | Obbligatorio | Default |
|---|---|---|---|---|
entities.cache |
ttl-seconds |
numero intero | ❌ No | 5 |
Configura il valore TTL (Time-to-Live) in secondi per gli elementi memorizzati nella cache. Dopo questo intervallo di tempo, gli elementi vengono eliminati automaticamente dalla cache. Il valore predefinito è 5 secondi.
Formato
{
"entities": {
"<entity-name>": {
"cache": {
"ttl-seconds": <integer; inherited>
}
}
}
}
Esempi
In questo esempio la cache è abilitata e gli elementi scadono dopo 15 secondi. Se omesso, questa impostazione eredita l'impostazione globale o l'impostazione predefinita.
{
"entities": {
"Author": {
"cache": {
"enabled": true,
"ttl-seconds": 15
}
}
}
}
Contenuto correlato
- funzioni di riferimento
- di riferimento dell'interfaccia della riga di comando