Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L’inserimento in streaming è utile per il caricamento dei dati quando è necessaria una bassa latenza tra inserimento e query. Si consideri l'uso dell'ingestione in streaming nei seguenti scenari:
- È obbligatoria una latenza inferiore a un secondo.
- Per ottimizzare l'elaborazione operativa di molte tabelle in cui il flusso di dati in ogni tabella è relativamente piccolo (pochi record al secondo), ma il volume di inserimento dati complessivo è elevato (migliaia di record al secondo).
Se il flusso di dati in ogni tabella è elevato (oltre 4 GB all'ora), è consigliabile usare l'ingestione in coda.
Per altre informazioni sui diversi metodi di inserimento, vedere Panoramica dell'inserimento dati.
Per esempi di codice basati sulle versioni precedenti dell'SDK, vedere l'articolo archiviato.
Scegliere il tipo di inserimento in streaming appropriato
Sono supportati due tipi di inserimento in streaming:
| Tipo di acquisizione | Descrizione |
|---|---|
| Connessione dati | Event Hubs, IoT Hub e connessioni dati di Event Grid possono usare l'inserimento in streaming, purché sia abilitato a livello del cluster. La decisione di utilizzare l'inserimento in streaming viene presa in base ai criteri di inserimento in streaming configurati nella tabella di destinazione. Per informazioni sulla gestione delle connessioni dati, vedere Hub eventi, hub IoT e Griglia di eventi. |
| Ingestione personalizzata | Per l'inserimento personalizzato è necessario scrivere un'applicazione che usa una delle librerie client di Azure Data Explorer. Utilizzare le informazioni presenti in questo articolo per configurare l'inserimento personalizzato. Potresti trovare utile anche l'applicazione di esempio C?view=azure-data-explorer&preserve-view=true# streaming di inserimento. |
Usare la tabella seguente per scegliere il tipo di inserimento appropriato per l'ambiente di utilizzo:
| Criterio | Connessione dati | Inserimento personalizzato |
|---|---|---|
| Ritardo nella disponibilità dei dati tra l'avvio dell'inserimento e la disponibilità dei dati per la consultazione | Ritardo più lungo | Ritardo più breve |
| Sovraccarico di sviluppo | Configurazione rapida e semplice, senza sovraccarico di sviluppo | Sovraccarico elevato di sviluppo per creare un'applicazione per inserire i dati, gestire gli errori e garantire la coerenza dei dati |
Nota
È possibile gestire il processo per abilitare e disabilitare l'inserimento in streaming nel cluster usando il portale di Azure o a livello di codice in C#. Se si usa C# per l'applicazione personalizzata, è possibile che sia più conveniente usare l'approccio programmatico.
Prerequisiti
- Una sottoscrizione di Azure. Creare un account Azure gratuito.
Considerazioni sulle prestazioni e sulle operazioni
I fattori principali che possono influire sull'inserimento in streaming sono:
- Dimensioni della macchina virtuale e del cluster: le prestazioni e la capacità di inserzione in streaming aumentano con l'aumento delle dimensioni delle macchine virtuali e del cluster. Il numero di richieste di inserimento simultanee è limitato a sei per core. Ad esempio, per 16 SKU core, ad esempio D14 e L16, il carico massimo supportato è 96 richieste di inserimento simultanee. Per due SKU core, ad esempio D11, il carico massimo supportato è 12 richieste di inserimento simultanee.
- Limite di dimensioni dei dati: il limite di dimensioni dei dati per una richiesta di inserimento in streaming è di 4 MB. Sono inclusi tutti i dati creati per le politiche di aggiornamento durante l'ingestione.
- Aggiornamenti dello schema: gli aggiornamenti dello schema, ad esempio la creazione e la modifica di tabelle e mapping di inserimento, possono impiegare fino a cinque minuti per il servizio di inserimento in streaming. Per altre informazioni, vedere Inserimento in streaming e modifiche allo schema.
- Capacità SSD: abilitare l'ingestione in streaming su un cluster, anche quando i dati non vengono ingeriti tramite streaming, utilizza parte del disco SSD locale delle macchine del cluster per i dati di ingestione in streaming e riduce lo spazio di archiviazione disponibile per la cache ad accesso frequente.
- Cursori di database: quando si usa l'inserimento in streaming, gli aggiornamenti del cursore del database potrebbero essere in ritardo rispetto alla disponibilità dei dati fino a 60 secondi. Questo ritardo si verifica dai processi asincroni di chiusura in background che passano i dati dal buffer di streaming agli extent permanenti dell'archivio di colonne, durante i quali viene aggiornato il cursore (usato per l'elaborazione incrementale, le esportazioni continue o le viste materializzate). Se il carico di lavoro richiede la coerenza immediata del cursore per la semantica di tipo exactly-once, è consigliabile usare l'inserimento in coda o tenere conto di questo potenziale ritardo nella logica dell'applicazione.
Abilitare l'inserimento in streaming sul tuo cluster
Prima di poter usare l'inserimento in streaming, è necessario abilitare la funzionalità nel cluster e definire un criterio di inserimento di streaming. È possibile abilitare la funzionalità durante la creazione del cluster o aggiungerla a un cluster esistente.
Avviso
Esaminare le limitazioni prima di abilitare l'inserimento in streaming.
Abilita l'ingestione in streaming durante la configurazione di un nuovo cluster
È possibile abilitare l'inserimento in streaming durante la creazione di un nuovo cluster usando il portale di Azure o a livello di codice in C#.
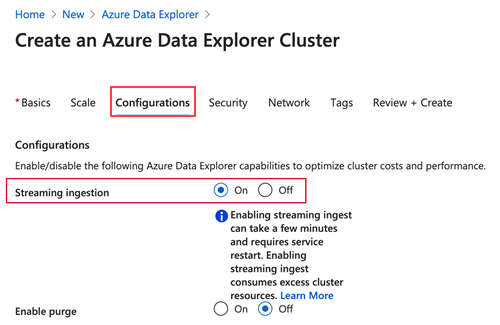
Durante la creazione di un cluster usando la procedura descritta in Creare un cluster e un database Azure Data Explorer, nella scheda Configurazioni, selezionare Streaming ingestion>On.
Abilitare l'inserimento in streaming in un cluster esistente
Se si dispone di un cluster esistente, è possibile abilitare l'inserimento in streaming usando il portale di Azure o a livello di codice in C#.
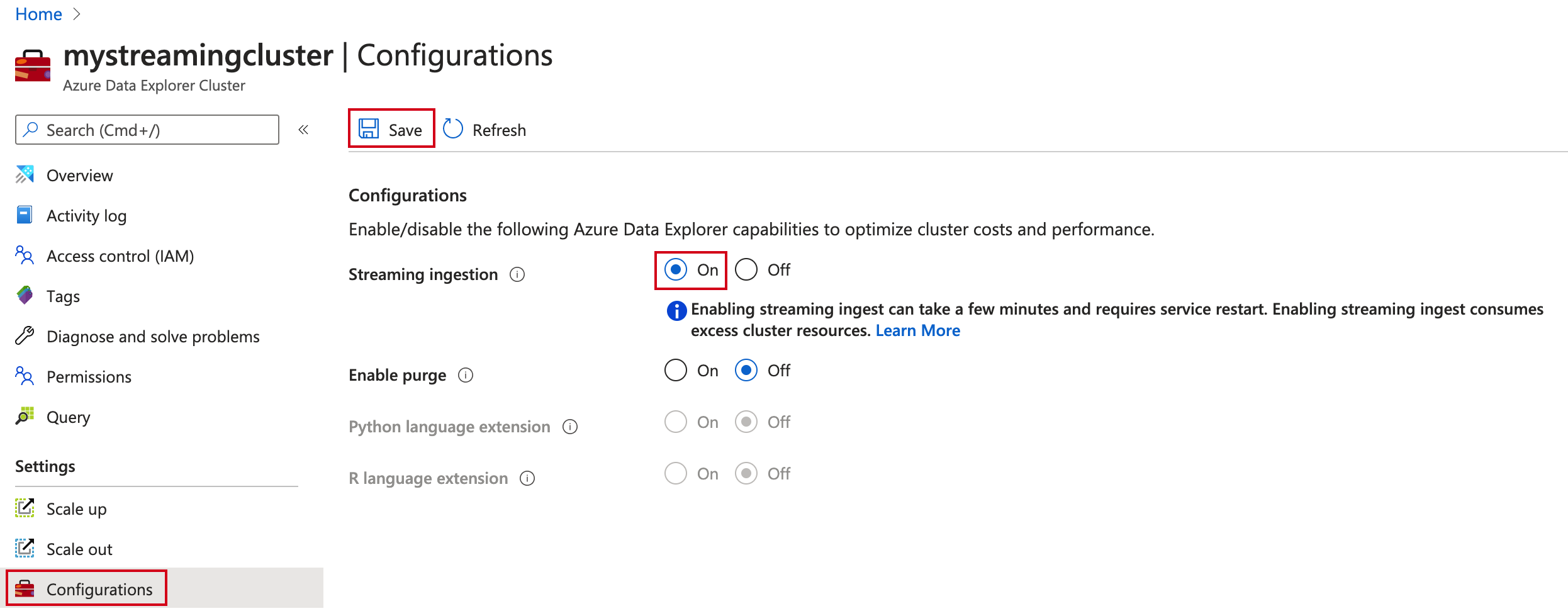
Nel portale di Azure, vai al cluster di Azure Data Explorer.
In Impostazioniselezionare Configurazioni.
Nel riquadro Configurazioni selezionare On per abilitare l'inserimento in streaming.
Seleziona Salva.
Creare una tabella di destinazione e definire i criteri
Creare una tabella per ricevere i dati di inserimento in streaming e definirne i criteri correlati usando il portale di Azure o a livello di codice in C#.
Nel portale di Azure, vai al tuo cluster.
Seleziona Query.
Per creare la tabella che riceverà i dati tramite l'inserimento in streaming, copiare il comando seguente nel riquadro Query e selezionare Esegui.
.create table TestTable (TimeStamp: datetime, Name: string, Metric: int, Source:string)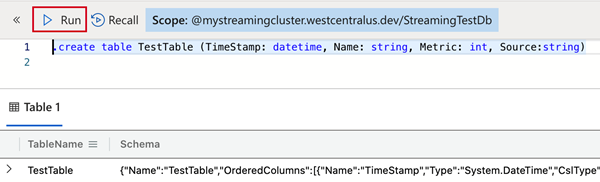
Copiare uno dei comandi seguenti nel riquadro Query e selezionare Esegui. In questo modo vengono definiti i criteri di inserimento in streaming nella tabella creata o nel database che contiene la tabella.
Suggerimento
Un criterio definito a livello di database si applica a tutte le tabelle esistenti e future presenti nel database. Quando si abilitano i criteri a livello di database, non è necessario abilitarlo per ogni tabella.
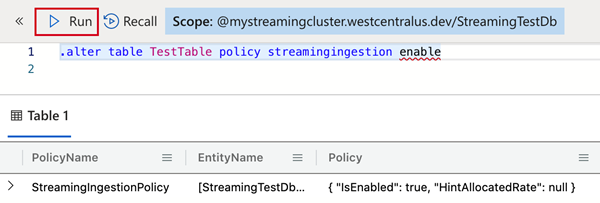
Per definire i criteri nella tabella creata, usare:
.alter table TestTable policy streamingingestion enablePer definire i criteri nel database contenente la tabella creata, usare:
.alter database StreamingTestDb policy streamingingestion enable
Creare un'applicazione di ingestione in streaming per l'inserimento dei dati nel cluster
Creare l'applicazione per l'inserimento di dati nel cluster usando la lingua preferita.
Nota
Per l'inserimento in coda, consultare le istruzioni per creare un'app per recuperare dati utilizzando l'inserimento in coda
using System.IO;
using System.Threading.Tasks;
using Kusto.Data; // Requires Package Microsoft.Azure.Kusto.Data
using Kusto.Data.Common;
using Kusto.Ingest; // Requires Package Microsoft.Azure.Kusto.Ingest
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var clusterPath = "https://<clusterName>.<region>.kusto.windows.net";
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
// Create Kusto connection string with App Authentication
var connectionStringBuilder = new KustoConnectionStringBuilder(clusterPath)
.WithAadApplicationKeyAuthentication(
applicationClientId: appId,
applicationKey: appKey,
authority: appTenant
);
// Create a disposable client that will execute the ingestion
using var client = KustoIngestFactory.CreateStreamingIngestClient(connectionStringBuilder);
// Ingest from a compressed file
var fileStream = File.Open("MyFile.gz", FileMode.Open);
// Initialize client properties
var ingestionProperties = new KustoIngestionProperties(databaseName: "<databaseName>", tableName: "<tableName>");
// Create source options
var sourceOptions = new StreamSourceOptions { CompressionType = DataSourceCompressionType.gzip, };
// Ingest from stream
await client.IngestFromStreamAsync(fileStream, ingestionProperties, sourceOptions);
}
}
Disabilita l'inserimento in streaming sul tuo cluster
Avviso
La disabilitazione dell'inserimento in streaming può richiedere alcune ore.
Prima di disabilitare l'inserimento in streaming nel cluster di Azure Esplora dati, eliminare la politica di inserimento in streaming da tutte le tabelle e i database pertinenti. La rimozione del criterio di inserimento del flusso attiva la ridistribuzione dei dati all'interno del cluster di Azure Data Explorer. I dati di inserimento in streaming vengono trasferiti dalla memoria di archiviazione iniziale a quella permanente nello store a colonne (extents o shards). Questo processo può richiedere da alcuni secondi a poche ore, a seconda della quantità di dati presenti nella risorsa di archiviazione iniziale.
Eliminare il criterio di inserimento in streaming
È possibile eliminare i criteri di inserimento di streaming usando il portale di Azure o a livello di codice in C#.
Nel portale di Azure, passa al cluster Azure Data Explorer e seleziona Query.
Per eliminare i criteri di inserimento in streaming dalla tabella, copiare il comando seguente nel riquadro Query e selezionare Esegui.
.delete table TestTable policy streamingingestion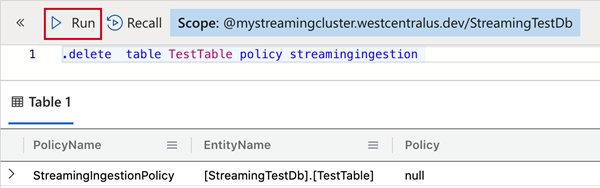
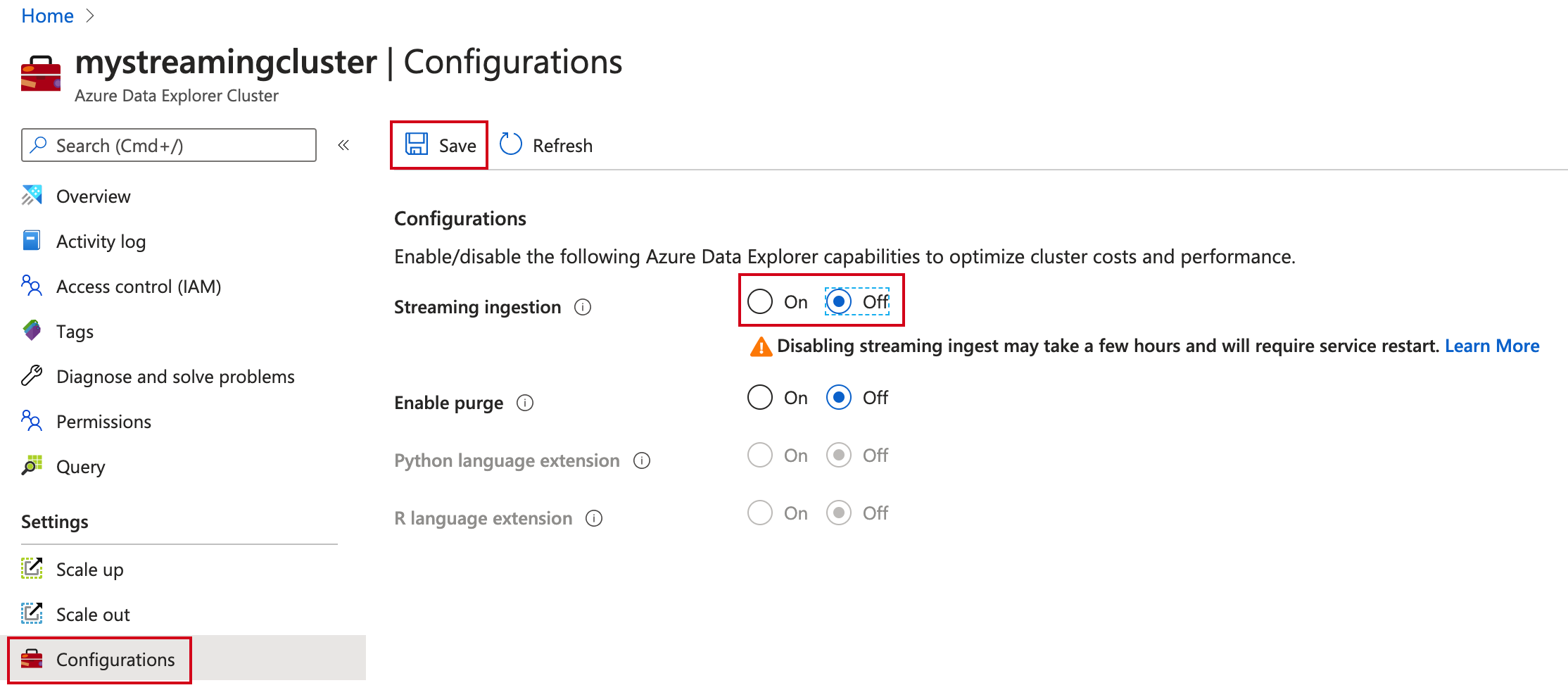
In Impostazioniselezionare Configurazioni.
Nel riquadro Configurazioni selezionare Off per disabilitare l'inserimento in streaming.
Seleziona Salva.
Limiti
- I mapping dei dati devono essere pre-creati per l'uso nell'inserimento in streaming. Le singole richieste di inserimento in streaming non supportano i mapping dei dati inline.
- Non è possibile impostare i tag extent nei dati di inserimento in streaming.
-
Aggiornare i criteri
- I criteri di aggiornamento possono fare riferimento solo ai dati appena inseriti nella tabella di origine e non ad altri dati o tabelle nel database
- Il plug-in Python non è supportato
- Quando un criterio di aggiornamento con un criterio transazionale fallisce, i tentativi passano all'inserimento batch.
- Per le politiche di aggiornamento a cascata che includono un
joinoperatore, è necessario disabilitare l'inserimento in streaming in tutte le tabelle a monte. Si considerino ad esempio i criteri di aggiornamento a catena in cui Table1 aggiorna Table2, Table2 aggiorna Table3 e Table3 aggiorna Table4. Se il criterio di aggiornamento di Table4 include un join, è necessario disabilitare l'ingestione in streaming in Table1, Table2 e Table3.
- Se l'inserimento in streaming è abilitato in un cluster usato come leader per i database follower, l'inserimento in streaming deve essere abilitato anche nei cluster follower per poter seguire i dati di inserimento in streaming. Lo stesso vale se i dati del cluster vengono condivisi tramite Condivisione dati.