hll() (funzione di aggregazione)
La hll() funzione è un modo per stimare il numero di valori univoci in un set di valori. A tale scopo, calcolare i risultati intermedi per l'aggregazione all'interno dell'operatore summarize per un gruppo di dati tramite la dcount funzione .
Informazioni sull'algoritmo sottostante (HyperLogLog) e sull'accuratezza della stima.
Nota
Questa funzione viene usata insieme all'operatore summarize.
Suggerimento
- Usare la funzione hll_merge per unire i risultati di più
hll()funzioni. - Usare la funzione dcount_hll per calcolare il numero di valori distinti dall'output delle
hll()funzioni ohll_merge.
Importante
I risultati di hll(), hll_if() e hll_merge() possono essere archiviati e recuperati in seguito. Ad esempio, è possibile creare un riepilogo utenti univoci giornaliero, che può quindi essere usato per calcolare i conteggi settimanali. Tuttavia, la rappresentazione binaria precisa di questi risultati può cambiare nel tempo. Non esiste alcuna garanzia che queste funzioni produrranno risultati identici per gli input identici e pertanto non è consigliabile affidarsi a tali input.
Sintassi
hll(expr [,accuratezza])
Altre informazioni sulle convenzioni di sintassi.
Parametri
| Nome | Tipo | Obbligatoria | Descrizione |
|---|---|---|---|
| Expr | string |
✔️ | Espressione utilizzata per il calcolo dell'aggregazione. |
| Precisione | int |
Valore che controlla l'equilibrio tra velocità e accuratezza. Se non specificato, il valore predefinito è 1. Per i valori supportati, vedere Accuratezza della stima. |
Restituisce
Restituisce i risultati intermedi del conteggio distinto dell'expr nel gruppo.
Esempio
Nell'esempio seguente la hll() funzione viene usata per stimare il numero di valori univoci della DamageProperty colonna all'interno di ogni contenitore di tempo di 10 minuti della StartTime colonna.
StormEvents
| summarize hll(DamageProperty) by bin(StartTime,10m)
La tabella dei risultati mostrata include solo le prime 10 righe.
| StartTime | hll_DamageProperty |
|---|---|
| 2007-01-01T00:20:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T01:00:00Z | [[1024,14],["7755241107725382121","-5665157283053373866","3803688792395291579","-1003235211361077779"],[]] |
| 2007-01-01T02:00:00Z | [[1024,14],["-1003235211361077779","-5665157283053373866","7755241107725382121"],[]] |
| 2007-01-01T02:20:00Z | [[1024,14],["7755241107725382121"],[]] |
| 2007-01-01T03:30:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T03:40:00Z | [[1024,14],["-5665157283053373866"],[]] |
| 2007-01-01T04:30:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T05:30:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T06:30:00Z | [[1024,14],["1589522558235929902"],[]] |
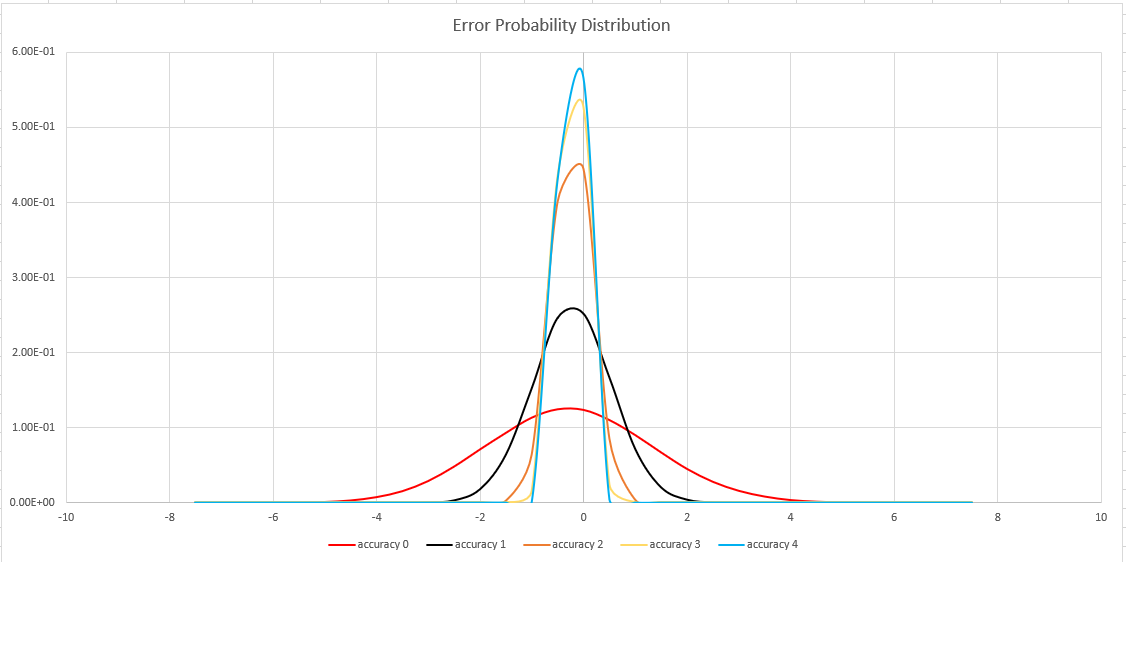
Accuratezza della stima
Questa funzione usa una variante dell'algoritmo HyperLogLog (HLL), che esegue una stima stocastica della cardinalità set. L'algoritmo fornisce una "manopola" che può essere usata per bilanciare l'accuratezza e il tempo di esecuzione in base alle dimensioni della memoria:
| Accuratezza | Errori (%) | Numero di voci |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0,8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0,28 | 217 |
| 4 | 0,2 | 218 |
Nota
La colonna "Numero di voci" corrisponde al numero di contatori di 1 byte nell'implementazione di HLL.
L'algoritmo include alcune clausole per eseguire un conteggio perfetto (zero errori) se la cardinalità del set è sufficientemente piccola:
- Se il livello di accuratezza è
1, vengono restituiti 1000 valori - Se il livello di accuratezza è
2, vengono restituiti 8000 valori
Il limite di errore è probabilistico, non teorico. Il valore è la deviazione standard della distribuzione degli errori (sigma) e il 99,7% delle stime avrà un errore relativo inferiore a 3 x sigma.
L'immagine seguente mostra la funzione di distribuzione delle probabilità di errore relativo nella stima, in percentuali, per tutte le impostazioni di accuratezza supportate:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per