Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Azure Data Factory è l'integrazione dei dati e il servizio ETL di Microsoft nel cloud. Questo documento fornisce linee guida per DataOps nella fabbrica di dati. Non è destinata a essere un'esercitazione completa su CI/CD, Git o DevOps. Si troveranno invece le linee guida del team di data factory per ottenere DataOps nel servizio con riferimenti ai collegamenti di implementazione dettagliati per le procedure consigliate per la distribuzione di data factory, la gestione delle factory e la governance. Alla fine di questo documento è disponibile una sezione relativa alle risorse con collegamenti alle esercitazioni.
Che cos'è DataOps?
DataOps è un processo che le organizzazioni dei dati praticano per la gestione collaborativa dei dati destinata a offrire valore più rapido ai decision maker.
Gartner fornisce questa chiara definizione di DataOps:
DataOps è una pratica collaborativa di gestione dei dati incentrata sul miglioramento della comunicazione, dell'integrazione e dell'automazione dei flussi di dati tra i responsabili dei dati e i consumer di dati in un'organizzazione. L'obiettivo di DataOps è offrire valore più velocemente creando un recapito prevedibile e la gestione delle modifiche dei dati, dei modelli di dati e degli artefatti correlati. DataOps usa la tecnologia per automatizzare la progettazione, la distribuzione e la gestione del recapito dei dati con livelli appropriati di governance e usa i metadati per migliorare l'usabilità e il valore dei dati in un ambiente dinamico.
Come si implementa DataOps con Azure Data Factory?
Azure Data Factory fornisce ai data engineer un paradigma della pipeline di dati basato su oggetti visivi per creare facilmente progetti ETL e integrazione dei dati su scala cloud. Data factory si basa su integrazioni native con strumenti di controllo della versione avanzati, ad esempio GitHub e Azure DevOps, nonché sull'ecosistema di Azure più ampio, per offrire molte funzionalità predefinite per facilitare DataOps che includono collaborazione, governance e relazioni di artefatti avanzate.
In particolare, dopo aver portato il proprio repository di GitHub o Azure DevOps nella data factory, il servizio offre opzioni intuitive dell'interfaccia utente predefinite per i comandi comuni, ad esempio commit, salvataggio di artefatti e controllo della versione. Il servizio offre anche la possibilità di fornire le procedure consigliate per CI/CD e il check-in del codice, per proteggere la sanità e l'integrità dell'ambiente di produzione.
"Codice" in Azure Data Factory
Tutti gli artefatti in Azure Data Factory, indipendentemente dal fatto che si tratti di pipeline, servizi collegati, trigger e così via, hanno rappresentazioni di "codice" corrispondenti in JSON dietro l'integrazione dell'interfaccia utente visiva. Questi artefatti agiscono in conformità agli standard Azure Resource Manager. È possibile trovare il codice facendo clic sull'icona tra parentesi quadre in alto a destra nell'area di disegno. Il codice JSON di esempio sarà simile al seguente:
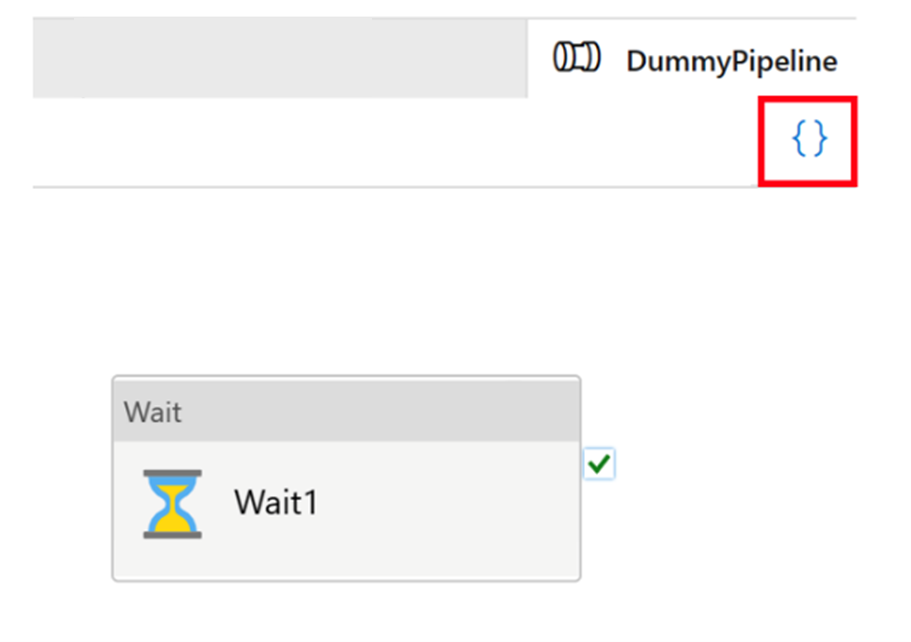

Modalità dinamica e controllo della versione Git
Ogni factory ha una fonte unica di verità: pipeline, servizi collegati e definizioni di trigger archiviate all'interno del servizio. Questa origine di verità è ciò su cui si basano le esecuzioni della pipeline e ciò che determina il comportamento dei trigger. Se si è in modalità dinamica, ogni volta che si pubblica, si modifica direttamente l'unica fonte di verità. L'immagine seguente mostra l'aspetto del pulsante Pubblica tutto in modalità dinamica.

La modalità dinamica può essere utile per la singola persona che lavora sui progetti side, in quanto consente agli sviluppatori di visualizzare effetti immediati delle modifiche al codice. Tuttavia, è sconsigliato per un team di sviluppatori che lavorano su progetti di lavoro a livello di produzione. I pericoli includono dita grasse, eliminazioni accidentali di risorse critiche, pubblicazione di codici non verificati, ecc., solo per citarne alcuni. Quando si lavora su progetti e piattaforme cruciali, è consigliabile introdurre un repository Git e usare la modalità Git in Data Factory per semplificare il processo di sviluppo. Il controllo della versione e le funzionalità di gated check-in della modalità Git consentono di evitare la maggior parte, se non tutti, degli incidenti associati al contatto diretto con la modalità live.
Nota
In modalità Git, il pulsante Pubblica o Pubblica tutto verrà sostituito da Salva o Salva tutto e le modifiche vengono sottoposte a commit nei propri rami (non modificando direttamente le codebase attive).
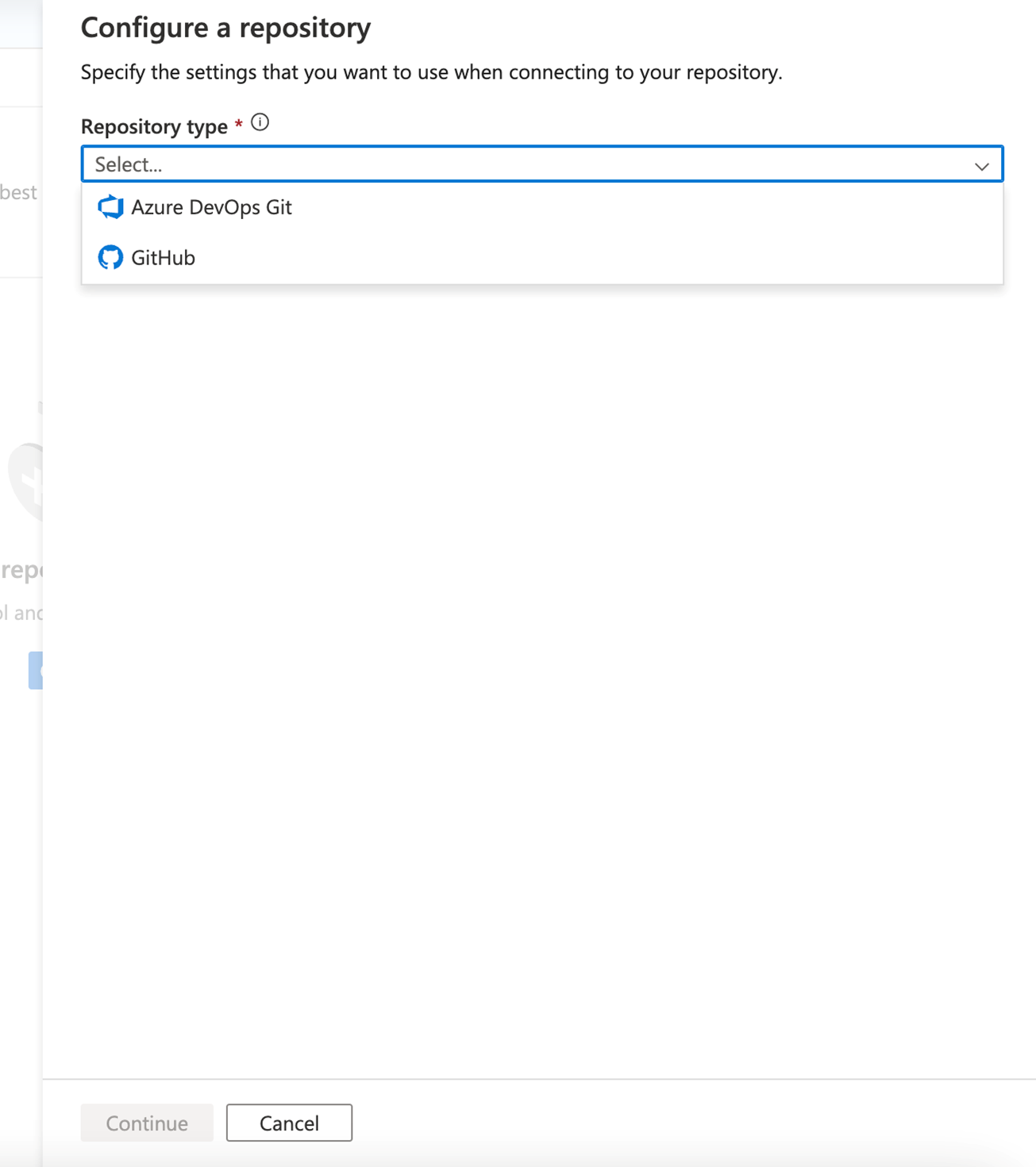
Configurazione dell'integrazione di GitHub e Azure DevOps
In Azure Data Factory è consigliabile archiviare il repository in GitHub o Azure DevOps. Il servizio supporta completamente entrambi i metodi e la scelta del repository da usare dipende dai singoli standard dell'organizzazione. Esistono due metodi per configurare un nuovo repository o per connettersi a un repository esistente: usando il portale di Azure o creando dall'interfaccia utente di Azure Data Factory Studio
Creazione della factory nel portale di Azure
Quando si crea una nuova data factory dal portale di Azure, il repository Git predefinito è Azure DevOps. È anche possibile selezionare GitHub come repository e configurare le impostazioni del repository.
Nel portale di Azure selezionare il tipo di repository e immettere i nomi dei repository e dei rami per creare una nuova factory integrata in modo nativo con Git.

Applicazione dell'uso di Git con Criteri di Azure nell'organizzazione
L'uso di Git nei progetti Azure Data Factory è una procedura consigliata. Anche se non si implementa un processo CI/CD completo, l'integrazione git con Azure Data Factory consente di salvare gli artefatti delle risorse nell'ambiente sandbox (ramo Git) in cui è possibile testare le modifiche in modo indipendente dal resto dei rami factory. È possibile usare Criteri di Azure per applicare l'uso di Git nella factory dell'organizzazione.
Azure Data Factory Studio
Dopo aver creato la data factory, è anche possibile connettersi al repository tramite Azure Data Factory Studio. Nella scheda Gestisci vedrai l'opzione per configurare il repository e le sue impostazioni.

Tramite un processo guidato, viene illustrata una serie di passaggi che consentono di configurare e connettersi facilmente al repository preferito. Dopo aver configurato completamente, è possibile iniziare a lavorare in modo collaborativo e salvare le risorse nel repository.
Integrazione continua e recapito continuo (CI/CD)
CI/CD è un paradigma dello sviluppo di codice in cui le modifiche vengono esaminate e testate durante lo spostamento in varie fasi: sviluppo, test, staging e così via. Dopo essere stati esaminati e testati in ogni fase, questi vengono infine pubblicati in codebase in tempo reale in un ambiente di produzione.
L'integrazione continua (CI) è la pratica di testare e convalidare automaticamente ogni volta che uno sviluppatore apporta una modifica alla codebase. La consegna continua (CD) indica che, dopo che i test di integrazione continua hanno avuto successo, le modifiche passano alla fase successiva in modo continuo.
Come descritto brevemente in precedenza, "codice" in Azure Data Factory assume la forma di Azure Resource Manager modello JSON. Di conseguenza, le modifiche che passano attraverso il processo di integrazione e recapito continuo (CI/CD) includono aggiunte, eliminazioni e modifiche ai BLOB JSON.
Esecuzioni delle pipeline in Azure Data Factory
Prima di parlare di CI/CD in Azure Data Factory, è necessario prima parlare del modo in cui il servizio esegue una pipeline. Prima di eseguire una pipeline, data factory esegue le operazioni seguenti:
- Esegue il pull della definizione pubblicata più recente della pipeline e dei relativi asset associati, ad esempio set di dati, servizi collegati e così via.
- Lo compila fino alle azioni; se la data factory l'ha eseguita di recente, recupera le azioni dalle compilazioni memorizzate nella cache.
- Esegue la pipeline.
L'esecuzione della pipeline comporta i passaggi seguenti:
- Il servizio acquisisce uno snapshot della definizione della pipeline.
- Per tutta la durata della pipeline, le definizioni non cambiano.
- Anche se le pipeline vengono eseguite per un prolungato periodo, non sono influenzate dalle modifiche successive apportate dopo l'avvio. Se si pubblicano modifiche al servizio collegato, alle pipeline e così via, durante l'esecuzione, queste modifiche non influiscono sulle esecuzioni in corso.
- Quando si pubblicano le modifiche, le esecuzioni successive iniziano dopo la pubblicazione usano le definizioni aggiornate.
Pubblicazione in Azure Data Factory
Indipendentemente dal fatto che si distribuisca la pipeline con Azure Pipeline di versione per automatizzare la pubblicazione, o con distribuzione gestita di modelli di Resource Manager, nel back-end la pubblicazione è una serie di operazioni di creazione/aggiornamento su dataset, servizi collegati, pipelines e triggers, per ognuno degli artefatti. L'effetto equivale a effettuare direttamente le chiamate all'API REST sottostante.
Ecco alcuni risultati delle azioni qui:
- Tutte queste chiamate API sono sincrone, ovvero la chiamata restituisce solo quando la pubblicazione ha esito positivo o negativo. Non ci sarà uno stato di parziale distribuzione dell'artefatto.
- Le chiamate API sono in gran parte sequenziali. Si tenta di parallelizzare le chiamate, mantenendo al tempo stesso le dipendenze referenziale degli artefatti. L'ordine delle distribuzioni è servizio associato -> set di dati/runtime di integrazione -> pipeline -> trigger. Questo ordine garantisce che gli artefatti subordinati possano fare riferimento correttamente alle proprie dipendenze. Ad esempio, le pipeline dipendono dai set di dati e quindi la data factory le distribuisce dopo i set di dati.
- La distribuzione di servizi collegati, set di dati e così via è indipendente dalle pipeline. In alcune situazioni data factory aggiorna i servizi collegati prima degli aggiornamenti di una pipeline. Parleremo di questa situazione nella sezione Quando interrompere un trigger.
- La distribuzione non eliminerà gli artefatti dalle fabbriche. È necessario chiamare in modo esplicito le API di eliminazione per ogni tipo di artefatto (pipeline, set di dati, servizio collegato e così via) per pulire una factory. Vedere ad esempio lo script post-distribuzione di esempio da Azure Data Factory.
- Anche se non è stata toccata una pipeline, un set di dati o un servizio collegato, richiama comunque una chiamata API di aggiornamento rapido alla factory.
Attivatori di pubblicazione
- I "trigger" hanno stati: avviato o fermo.
- Non è possibile apportare modifiche a un trigger in modalità avviata . È necessario arrestare un trigger prima di pubblicare le modifiche.
- È possibile invocare l'API Crea o Aggiorna trigger su un trigger in modalità avviata.
- Se il payload cambia, l'API fallisce.
- Se il payload rimane invariato, l'API ha esito positivo.
- Questo comportamento ha un impatto profondo su quando arrestare un trigger.
Quando arrestare un trigger
Quando si tratta di eseguire la distribuzione in una data factory di produzione, con trigger attivi che avviano sempre le esecuzioni della pipeline, la domanda diventa "Dovremmo arrestarli?".
La risposta breve è che solo negli scenari seguenti è consigliabile arrestare il trigger:
- È necessario arrestare il trigger se si aggiornano le definizioni del trigger, inclusi campi quali data di fine, frequenza e associazione della pipeline.
- È consigliabile arrestare il trigger se si aggiornano i set di dati o i servizi collegati a cui si fa riferimento in una pipeline dinamica. Ad esempio, se si ruotano le credenziali per SQL Server.
- È possibile scegliere di arrestare il trigger se la pipeline associata genera errori e appesantisce i server.
Ecco alcuni punti da considerare per quanto riguarda l'arresto dei trigger:
- Come spiegato nella sezione Esecuzioni di pipeline in Azure Data Factory, quando un trigger avvia un'esecuzione della pipeline, crea un'istantanea delle definizioni della pipeline, del set di dati, del runtime di integrazione e del servizio collegato. Se la pipeline viene eseguita prima del popolamento delle modifiche nel back-end, il trigger avvia un'esecuzione con la versione precedente. Nella maggior parte dei casi, questo dovrebbe essere corretto.
- Come illustrato nella sezione Trigger di pubblicazione. Quando un trigger è in stato avviato , non può essere aggiornato. Pertanto, se è necessario modificare i dettagli sulla definizione del trigger, interrompere il trigger prima di pubblicare le modifiche.
- Come illustrato nella sezione Publishing in Azure Data Factory, le modifiche ai set di dati o ai servizi collegati vengono pubblicate prima delle modifiche della pipeline. Per garantire che le esecuzioni della pipeline usino le credenziali corrette e comunichino con i server corretti, è consigliabile arrestare anche il trigger associato.
Preparazione delle modifiche al "codice"
Consigliamo di seguire queste procedure ottimali per le pull request.
- Ogni sviluppatore deve lavorare su singoli rami e, alla fine del giorno, creare richieste pull al ramo principale del repository. Consulta i tutorial sulle richieste pull in GitHub e DevOps.
- Quando i responsabili di controllo approvano le richieste pull e uniscono le modifiche nel ramo principale, il processo CI/CD può essere avviato. Esistono due metodi consigliati per promuovere le modifiche in tutti gli ambienti: automatizzato e manuale.
- Quando si è pronti per avviare le pipeline CI/CD, è possibile farlo in genere usando Azure Pipeline Release o creare distribuzioni di singole pipeline specifiche usando questa utilità open source da Azure Player.
Distribuzione automatica delle modifiche
Per semplificare le distribuzioni automatizzate, è consigliabile usare il pacchetto npm delle utilità Azure Data Factory. L'uso del pacchetto npm consente di convalidare tutte le risorse in una pipeline e generare i modelli di Resource Manager per l'utente.
Per iniziare a usare il pacchetto npm utilità di Azure Data Factory, consultare Pubblicazione automatica per l'integrazione continua e la distribuzione.
Distribuzione manuale delle modifiche
Dopo aver unito il ramo al ramo di collaborazione principale nel repository Git, è possibile pubblicare manualmente le modifiche nel servizio live Azure Data Factory. Il servizio fornisce il controllo tramite l'interfaccia utente sulla pubblicazione da factory non di sviluppo con l'opzione Disabilita pubblicazione (da ADF Studio).
Distribuzione selettiva
La distribuzione selettiva si basa su una funzionalità di GitHub e Azure DevOps, nota come cherry pick. Questa funzionalità consente di distribuire solo determinate modifiche, ma non altre. Ad esempio, uno sviluppatore ha apportato modifiche a più pipeline, ma per la distribuzione odierna potremmo voler distribuire solo le modifiche a una.
Seguire le esercitazioni di Azure DevOps e GitHub per selezionare i commit rilevanti per la pipeline necessaria. Assicurarsi che siano state selezionate tutte le modifiche, incluse le modifiche rilevanti apportate ai trigger, ai servizi collegati e alle dipendenze associate alla pipeline.
Dopo aver selezionato le modifiche e unito alla pipeline di collaborazione principale, è possibile avviare il processo CI/CD per le modifiche proposte. Altre informazioni su come eseguire correzioni rapide, scegliere elementi specifici o utilizzare framework esterni per la distribuzione selettiva, come descritto nella sezione Test automatizzati di questo articolo.
Test unitario
Gli unit test sono una parte importante del processo di sviluppo di nuove pipeline o di modifica degli artefatti di data factory esistenti, incentrati sui componenti di test del codice. Data Factory consente di eseguire singoli unit test a livello di artefatto della pipeline e del flusso di dati usando la funzionalità di debug della pipeline.

Quando si sviluppano flussi di dati, sarà possibile ottenere informazioni dettagliate su ogni singola trasformazione e modifica del codice usando la funzionalità di anteprima dei dati per ottenere unit test prima di distribuire le modifiche nell'ambiente di produzione.

Il servizio fornisce feedback live e interattivo sulle attività della pipeline nell'interfaccia utente durante il debug e gli unit test in Azure Data Factory.
Test automatizzati
Sono disponibili diversi strumenti per i test automatizzati che è possibile usare con Azure Data Factory. Poiché il servizio archivia gli oggetti nel servizio come entità JSON, può essere utile usare il framework open source .NET unit testing NUnit con Visual Studio. Fare riferimento a questo post Setup automated testing for Azure Data Factory che fornisce una spiegazione approfondita di come configurare un ambiente di unit test automatizzato per la factory. (Grazie speciale a Richard Swinbank per l'autorizzazione a usare questo blog.
I clienti possono anche eseguire pipeline di test con PowerShell o AZ CLI come parte del processo CI/CD per i passaggi di pre e post-distribuzione.
Un punto di forza chiave della data factory è la parametrizzazione dei set di dati. Questa funzionalità consente ai clienti di eseguire le stesse pipeline con set di dati diversi per assicurarsi che il nuovo sviluppo soddisfi tutti i requisiti di origine e di destinazione.
Altri framework di Integrazione Continua/Consegna Continua per Azure Data Factory
Come descritto in precedenza, l'integrazione git predefinita è disponibile in modo nativo tramite l'interfaccia utente Azure Data Factory, tra cui unione, diramazione, confronto e pubblicazione. Esistono tuttavia altri framework CI/CD utili diffusi nella community di Azure, che forniscono meccanismi alternativi per offrire funzionalità simili. La metodologia Git Azure Data Factory si basa sui modelli arm, mentre i framework come ADFTools di Kamil Nowinski adottare un approccio diverso basandosi invece sui singoli artefatti JSON della factory. Gli ingegneri dei dati che sono esperti in Azure DevOps e preferiscono lavorare in tale ambiente (anziché con l'interfaccia utente basata su ARM offerta dal servizio) possono ritenere che questo framework funzioni bene per loro e anche per scenari comuni come le distribuzioni parziali. Questo framework può anche semplificare la gestione dei trigger durante la distribuzione in ambienti con stati di trigger in esecuzione.
Governance dei dati in Azure Data Factory
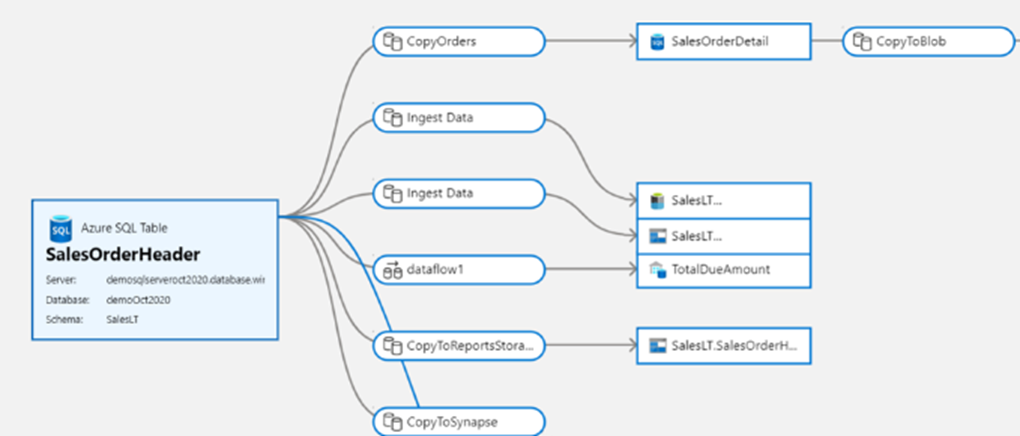
Un aspetto importante di DataOps efficace è la governance dei dati. Per gli strumenti ETL di integrazione dei dati, fornire relazioni tra elementi e derivazione dei dati può fornire informazioni importanti per un data engineer per comprendere l'impatto delle modifiche downstream. Data Factory offre viste correlate degli artefatti predefiniti che costituiscono l'implementazione della factory.
L'integrazione nativa con Microsoft Purview offre inoltre derivazione, analisi dell'impatto e catalogo dati.
Microsoft Purview offre una soluzione unificata di governance dei dati per gestire e gestire i dati SaaS (Software as a Service) locali, multicloud e software come servizio. Consente di creare facilmente una mappa olistica e aggiornata del panorama dei dati con l'individuazione automatica dei dati, la classificazione dei dati sensibili e la derivazione dei dati end-to-end. Queste funzionalità consentono ai consumer di dati di accedere a una gestione dei dati preziosa e affidabile.
Grazie all'integrazione nativa nel Data Catalog Purview, la data factory consente di eseguire facilmente ricerche e individuare gli asset di dati da usare nelle pipeline di integrazione dei dati in tutta l'ampiezza completa del patrimonio di dati dell'organizzazione.

È possibile usare la barra di ricerca principale di Azure Data Factory Studio per trovare gli asset di dati nel catalogo purview.
