Ottimizzare Azure Data Lake Storage Gen1 per le prestazioni
Data Lake Storage Gen1 supporta una velocità effettiva elevata per l'analisi e lo spostamento dei dati a elevato utilizzo di I/O. In Data Lake Storage Gen1 è importante poter usare tutta la velocità effettiva disponibile, ovvero la quantità di dati che possono essere letti o scritti al secondo, per ottenere prestazioni ottimali. Questo risultato viene ottenuto eseguendo il numero massimo possibile di operazioni di lettura e scrittura in parallelo.
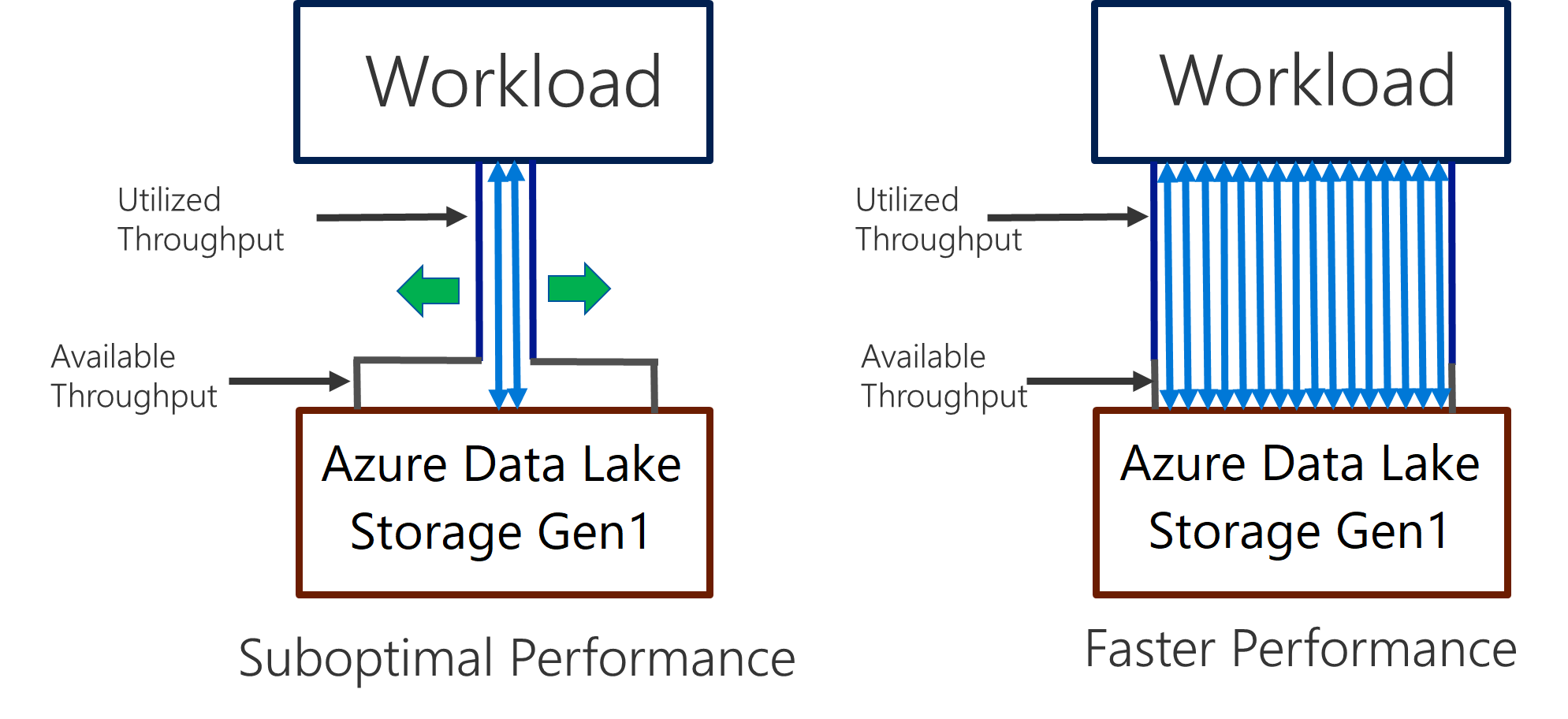
Data Lake Storage Gen1 può essere ridimensionato per offrire la velocità effettiva necessaria per qualsiasi scenario di analisi. Per impostazione predefinita, un account Data Lake Storage Gen1 offre automaticamente la velocità effettiva sufficiente per soddisfare le esigenze di un'ampia categoria di casi d'uso. Per i casi in cui i clienti raggiungono il limite predefinito, è possibile contattare il supporto tecnico Microsoft per configurare l'account Data Lake Storage Gen1 in modo da ottenere maggiore velocità effettiva.
Inserimento dati
Quando si inseriscono dati da un sistema di origine a Data Lake Storage Gen1, è importante considerare che l'hardware di origine, l'hardware di rete di origine e la connettività di rete a Data Lake Storage Gen1 possono essere il collo di bottiglia.
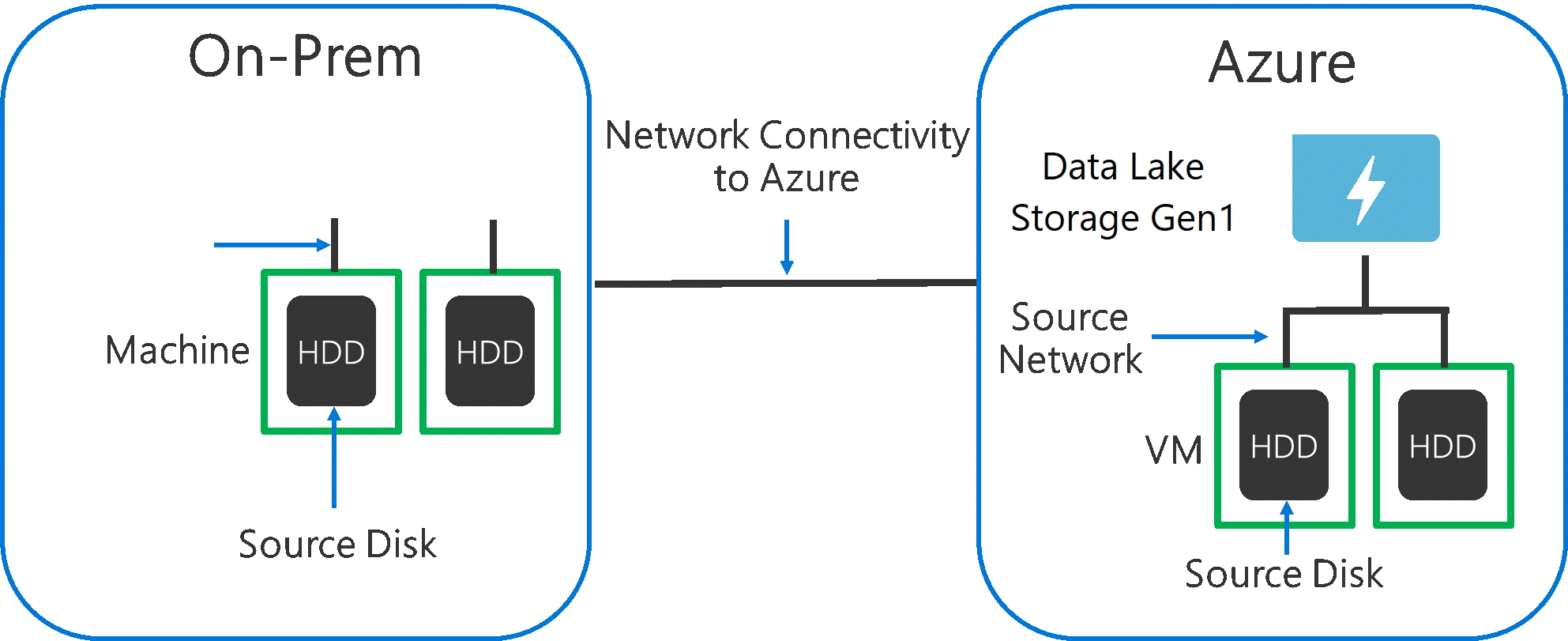
È importante assicurarsi che lo spostamento dei dati non sia influenzato da questi fattori.
Hardware di origine
Indipendentemente dal fatto che si usino macchine virtuali o computer locali in Azure, è consigliabile selezionare attentamente l'hardware appropriato. Per l'hardware del disco di origine, preferire le unità SSD alle HDD e scegliere hardware con spindle più veloci. Per l'hardware di rete di origine, usare le schede di interfaccia di rete più veloci possibili. In Azure è consigliabile usare macchine virtuali di Azure D14 che dispongono dell'hardware di rete e del disco appropriato.
Connettività di rete a Data Lake Storage Gen1
La connettività di rete tra i dati di origine e Data Lake Storage Gen1 può talvolta costituire il collo di bottiglia. Quando i dati di origine sono in locale, valutare l'opportunità di usare un collegamento dedicato con Azure ExpressRoute . Se i dati di origine sono in Azure, si ottengono prestazioni ottimali quando i dati si trovano nella stessa area di Azure dell'account Data Lake Storage Gen1.
Configurare gli strumenti di inserimento dei dati per la massima parallelizzazione
Dopo aver risolto i colli di bottiglia di connettività di rete e hardware di origine, è possibile configurare gli strumenti di inserimento. La tabella seguente presenta un riepilogo delle impostazioni delle chiavi per diversi strumenti di inserimento comuni e include collegamenti ad articoli di approfondimento sull'ottimizzazione delle prestazioni. Per altre informazioni sullo strumento da usare per uno scenario specifico, vedere questo articolo.
| Strumento | Impostazioni | Altre informazioni |
|---|---|---|
| PowerShell | PerFileThreadCount, ConcurrentFileCount | Collegamento |
| AdlCopy | Unità Azure Data Lake Analytics | Collegamento |
| DistCp | -m (mapper) | Collegamento |
| Azure Data Factory | parallelCopies | Collegamento |
| Sqoop | fs.azure.block.size, -m (mapper) | Collegamento |
Strutturare il set di dati
Quando i dati vengono archiviati in Data Lake Storage Gen1, le dimensioni del file, il numero di file e la struttura delle cartelle influiscono sulle prestazioni. La sezione seguente descrive le procedure consigliate in queste aree.
Dimensione del file
I motori di analisi come HDInsight e Azure Data Lake Analytics in genere gestiscono il sovraccarico a livello di singolo file. Se quindi si archiviano i dati in molti file di piccole dimensioni, questo può influire negativamente sulle prestazioni.
Per ottenere prestazioni migliori, è in genere opportuno organizzare i dati in file di dimensioni più grandi. Come regola generale, organizzare i set di dati in file di 256 MB o superiori. In alcuni casi, ad esempio per le immagini e i dati binari, non è possibile eseguire l'elaborazione in parallelo In questi casi, è consigliabile mantenere singoli file con meno di 2 GB.
In alcuni casi, le pipeline di dati hanno un controllo limitato sui dati non elaborati con un numero elevato di file di piccole dimensioni. È pertanto consigliabile prevedere l'esecuzione di un processo che genera file di maggiori dimensioni destinati all'uso da parte delle applicazioni downstream.
Organizzare i dati delle serie temporali nelle cartelle
Per i carichi di lavoro Hive e ADLA, l'eliminazione della partizione dei dati delle serie temporali può aiutare alcune query a leggere solo un subset dei dati, migliorando così le prestazioni.
Le pipeline che inseriscono dati di serie temporali, spesso inseriscono i file con una denominazione strutturata per file e cartelle. Di seguito è riportato un esempio comune per i dati strutturati per data: \DataSet\AAAA\MM\DD\datafile_YYYY_MM_DD.tsv.
Si noti che le informazioni di data/ora vengono visualizzate sia come cartelle sia nel nome del file.
Per data e ora, di seguito è riportato un modello comune: \DataSet\AAAA\MM\DD\HH\mm\datafile_YYYY_MM_DD_HH_mm.tsv.
Anche in questo caso, la scelta relativa all'organizzazione di file e cartelle deve prevedere una gestione ottimizzata dei file di maggiori dimensioni e l'inclusione di un numero ragionevole di file in ogni cartella.
Ottimizzare i processi a elevato utilizzo di I/O nei carichi di lavoro Hadoop e Spark in HDInsight
I processi sono classificabili in una delle tre categorie seguenti:
- Uso intensivo della CPU. Questi processi hanno tempi di elaborazione lunghi e tempi di I/O minimi, come i processi di machine learning e quelli di elaborazione del linguaggio naturale.
- Utilizzo intensivo della memoria. Questi processi usano grandi quantità di memoria, come i processi di PageRank e quelli di analisi in tempo reale.
- Uso intensivo dell'I/O. Questi processi impiegano la maggior parte del tempo a eseguire operazioni di I/O. Un esempio comune è un processo di copia che esegue solo operazioni di lettura e scrittura. Altri esempi includono processi di preparazione dei dati che leggono numerosi dati, eseguono una trasformazione dei dati e quindi scrivono nuovamente i dati nell'archivio.
Le linee guida seguenti sono applicabili solo ai processi con uso intensivo dell'I/O.
Considerazioni generali per un cluster HDInsight
- Versioni di HDInsight. Per prestazioni ottimali, usare la versione più recente di HDInsight.
- Aree. Inserire l'account Data Lake Storage Gen1 nella stessa area del cluster HDInsight.
Un cluster HDInsight è composto da due nodi head e da alcuni nodi di ruolo di lavoro. Ogni nodo di ruolo di lavoro fornisce un numero specifico di core e memoria, in base al tipo di macchina virtuale. Quando si esegue un processo, YARN è il negoziatore di risorse che alloca la memoria e i core disponibili per creare contenitori. Ogni contenitore esegue le attività necessarie per completare il processo. I contenitori vengono eseguiti in parallelo per l'elaborazione rapida delle attività. È quindi possibile ottenere un miglioramento delle prestazioni eseguendo la quantità massima possibile di contenitori paralleli.
All'interno di un cluster HDInsight sono presenti tre livelli che possono essere ottimizzati per aumentare il numero di contenitori e sfruttare tutta la velocità effettiva disponibile.
- Livello fisico
- Livello YARN
- Livello carico di lavoro
Livello fisico
Eseguire il cluster con più nodi e/o macchine virtuali di dimensioni maggiori. Un cluster di dimensioni maggiori consentirà di eseguire più contenitori YARN, come illustrato nell'immagine seguente.

Usare macchine virtuali con maggiore larghezza di banda di rete. La larghezza di banda di rete può costituire un collo di bottiglia se la larghezza di banda di rete disponibile è inferiore alla velocità effettiva di Data Lake Storage Gen1. Macchine virtuali differenti avranno dimensioni variabili della larghezza di banda di rete. Scegliere un tipo di macchina virtuale con la massima larghezza di banda di rete possibile.
Livello YARN
Usare contenitori YARN di dimensioni inferiori. Ridurre le dimensioni di ogni contenitore YARN per creare altri contenitori con la stessa quantità di risorse.
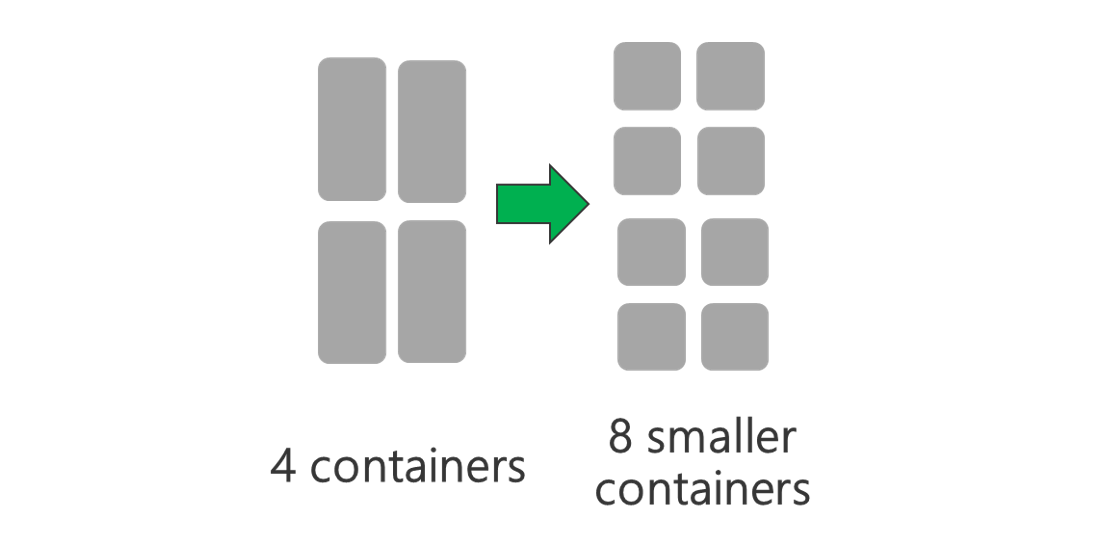
A seconda del carico di lavoro, sarà sempre necessaria una dimensione minima per i contenitori YARN. Se si sceglie un contenitore troppo piccolo, si verificheranno problemi di memoria insufficiente per i processi. In genere, i contenitori YARN non devono essere inferiori a 1 GB. È comune vedere 3 GB di contenitori YARN. Per alcuni carichi di lavoro, possono essere necessari contenitori YARN più grandi.
Aumentare il numero di core per contenitore YARN. Aumentare il numero di core allocati a ogni contenitore per aumentare il numero di attività parallele eseguite in ogni contenitore. Questo funziona per applicazioni come Spark, che eseguono più attività per ogni contenitore. Per applicazioni come Hive che eseguono un singolo thread in ogni contenitore, è preferibile avere più contenitori anziché più core per ogni contenitore.
Livello carico di lavoro
Usare tutti i contenitori disponibili. Impostare il numero di attività su uguale o maggiore del numero di contenitori disponibili in modo che vengano usate tutte le risorse.
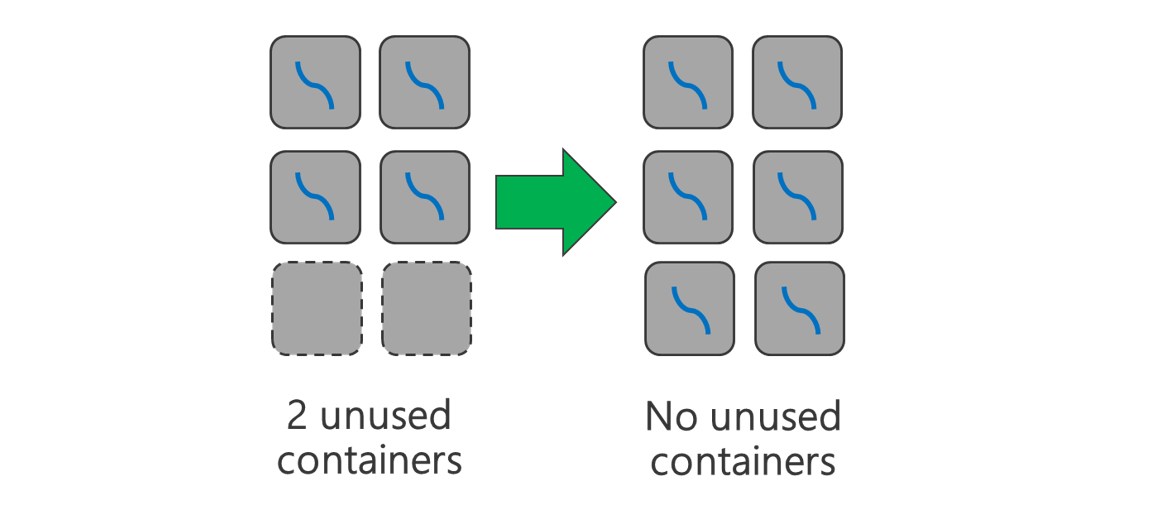
Le attività che non vengono eseguite correttamente sono dispendiose. Se ogni attività deve elaborare una grande quantità di dati, l'esito negativo di un'attività ha come risultato l'esecuzione di un nuovo tentativo impegnativo in termini di risorse. È quindi preferibile creare più attività, ognuna delle quali elabora una piccola quantità di dati.
Oltre alle linee guida generali sopra illustrate, ogni applicazione dispone di diversi parametri che è possibile ottimizzare. La tabella seguente elenca alcuni parametri e collegamenti per ottimizzare con facilità le prestazioni di ogni applicazione.
| Carico di lavoro | Parametro per impostare le attività |
|---|---|
| Spark in HDInsight |
|
| Hive in HDInsight |
|
| MapReduce in HDInsight |
|
| Storm in HDInsight |
|