Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Nota
Questa pagina usa esempi JSON di definizioni di criteri. È possibile definire un criterio usando JSON o usare l'interfaccia utente dei criteri di calcolo per configurare le definizioni dei criteri usando i menu a discesa e altri elementi dell'interfaccia utente.
Questa pagina è un riferimento per le definizioni dei criteri di calcolo, incluso un elenco di attributi dei criteri disponibili e tipi di limitazione. Esistono anche criteri di esempio a cui è possibile fare riferimento per i casi d'uso comuni.
Che cosa sono le definizioni dei criteri?
Le definizioni dei criteri sono singole regole dei criteri espresse in JSON.
Una definizione può aggiungere una regola a uno qualsiasi degli attributi controllati con l'API cluster . Ad esempio, queste definizioni impostano un tempo di autoterminazione predefinito, impediscono agli utenti di usare i pool e applicano l'uso di Photon:
{
"autotermination_minutes": {
"type": "unlimited",
"defaultValue": 4320,
"isOptional": true
},
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"runtime_engine": {
"type": "fixed",
"value": "PHOTON",
"hidden": true
}
}
Può esistere una sola limitazione per attributo. Il percorso di un attributo riflette il nome dell'attributo API. Per gli attributi annidati, il percorso concatena i nomi degli attributi annidati usando i punti. Gli attributi non definiti in una definizione di criteri non saranno limitati.
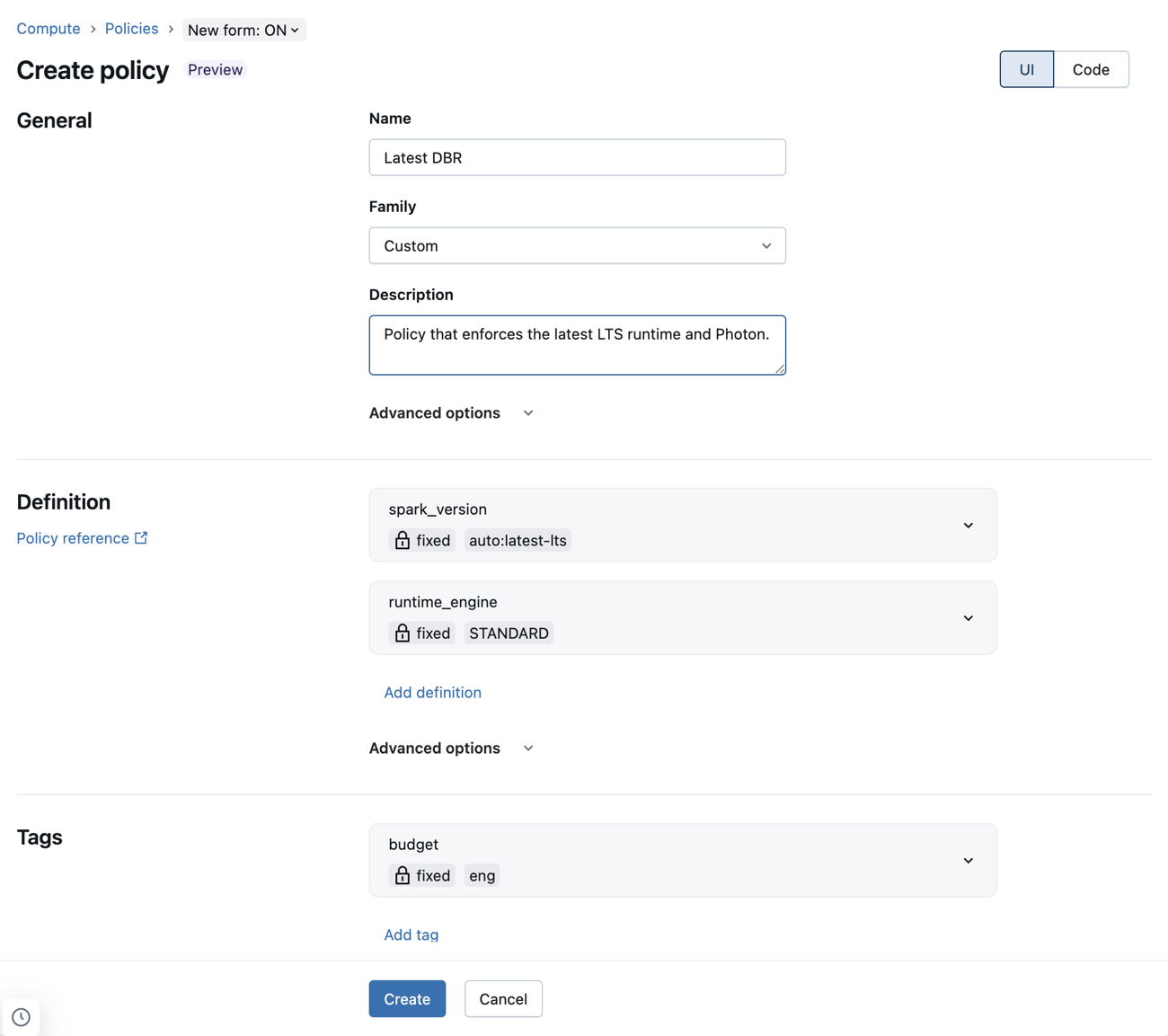
Configurare le definizioni dei criteri usando gli elementi dell'interfaccia utente
Il modulo dei criteri consente di configurare le definizioni dei criteri usando i menu a discesa e altri elementi dell'interfaccia utente. Ciò significa che gli amministratori possono scrivere criteri senza dover apprendere o fare riferimento alla sintassi dei criteri.
Il modulo supporta anche la modifica della definizione completa dei criteri direttamente come JSON. Per modificare il codice JSON:
- Fare clic sul pulsante Modifica definizione come JSON nelle opzioni avanzate della sezione Definizione per aprire un editor JSON.
- Fare clic sulla scheda JSON per visualizzare il codice JSON di definizione. Da questa scheda è anche possibile fare clic su Modifica definizione come JSON per aprire l'editor.
È anche possibile aggiungere singole regole JSON al campo JSON personalizzato in Opzioni avanzate.
Limitazioni note del nuovo modulo di criteri
Se un criterio non è supportato dal nuovo modulo dei criteri di calcolo, eventuali definizioni incompatibili verranno visualizzate nel campo JSON personalizzato nella sezione Opzioni avanzate . Per i campi seguenti, sono supportati solo un subset di criteri validi:
-
workload_type: i criteri devono definire sia
workload_type.clients.notebookscheworkload_type.clients.jobs. Ognuna di queste regole deve essere impostata sutrueofalse. -
dbus_per_hour: sono supportati solo i criteri di intervallo che specificano
maxValuee non specificanominValue. -
ssh_public_keys: sono supportati solo i criteri fissi. I
ssh_public_keyscriteri non devono ignorare alcun indice. Ad esempio,ssh_public_keys.0,ssh_public_keys.1,ssh_public_keys.2è valido, massh_public_keys.0,ssh_public_keys.2,ssh_public_keys.3non è valido. -
cluster_log_conf:
cluster_log_conf.pathnon può essere una lista di permessi o lista di blocco. -
init_scripts: i criteri indicizzati (ovvero
init_scripts.0.volumes.destination) devono essere corretti. Le politiche con caratteri jolly (ovveroinit_scripts.*.volumes.destination) devono essere vietate. I criteri indicizzati non devono ignorare alcun indice.
Attributi supportati
Le politiche supportano tutti gli attributi controllati con l'API Cluster . Il tipo di restrizioni che è possibile applicare agli attributi può variare in base all'impostazione in base al tipo e alla relazione agli elementi dell'interfaccia utente. Non è possibile usare criteri per definire le autorizzazioni di calcolo.
Puoi anche utilizzare le politiche per impostare il numero massimo di DBUs all'ora e il tipo di cluster. Consultare i percorsi degli attributi virtuali .
Nella tabella seguente sono elencati i percorsi degli attributi dei criteri supportati:
| Percorso dell'attributo | Tipo | Descrizione |
|---|---|---|
autoscale.max_workers |
numero facoltativo | Se nascosto, rimuove il campo numero di lavoro massimo dall'interfaccia utente. |
autoscale.min_workers |
numero facoltativo | Se nascosto, rimuove il campo numero di lavoro minimo dall'interfaccia utente. |
autotermination_minutes |
numero | Il valore 0 non rappresenta alcuna terminazione automatica. Se nascosta, rimuove dall'interfaccia utente la casella di controllo per la terminazione automatica e il campo di inserimento del valore. |
azure_attributes.availability |
corda | Controlla se l'utilizzo delle risorse di calcolo usa istanze su richiesta o spot (SPOT_AZURE, ON_DEMAND_AZUREo SPOT_WITH_FALLBACK_AZURE). |
azure_attributes.first_on_demand |
numero | Controlla il numero di nodi del cluster che usano istanze su richiesta, a partire dal nodo driver. Ad esempio, un valore di 1 imposta il nodo driver su richiesta. Un valore di 2 imposta il nodo driver e un nodo worker su richiesta. |
azure_attributes.spot_bid_max_price |
numero | Controlla il prezzo massimo per le istanze spot di Azure. |
cluster_log_conf.path |
corda | URL di destinazione dei file di log. |
cluster_log_conf.type |
corda | Tipo di destinazione del log.
DBFS e VOLUMES sono gli unici valori accettabili. |
cluster_name |
corda | Nome del cluster. |
custom_tags.* |
corda | Controllare i valori di tag specifici aggiungendo il nome del tag, ad esempio custom_tags.<mytag>. |
data_security_mode |
corda | Imposta la modalità di accesso del cluster. Il catalogo unity richiede SINGLE_USER o USER_ISOLATION (modalità di accesso standard nell'interfaccia utente). Un valore di NONE indica che non sono abilitate funzionalità di sicurezza. |
docker_image.basic_auth.password |
corda | Password per l'autenticazione di base dell'immagine nei servizi container di Databricks. |
docker_image.basic_auth.username |
corda | Nome utente per l'autenticazione di base dell'immagine del servizio container di Databricks. |
docker_image.url |
corda | Controlla l'URL dell'immagine nei servizi container di Databricks. Se nascosto, rimuove la sezione Databricks Container Services dall'interfaccia utente. |
driver_node_type_id |
stringa facoltativa | Se nascosta, rimuove la selezione del tipo di nodo driver dall'interfaccia utente. |
driver_node_type_flexibility.alternate_node_type_ids |
corda | Specifica i tipi di nodo alternativi per il nodo driver. Sono supportati solo i criteri fissi. Vedere Tipi di nodo flessibili. |
enable_local_disk_encryption |
booleano | Impostare su true per abilitare o false per disabilitare la crittografia dei dischi collegati localmente al cluster (come specificato tramite l'API). |
init_scripts.*.workspace.destination
init_scripts.*.volumes.destination
init_scripts.*.abfss.destination
init_scripts.*.file.destination
|
corda |
* fa riferimento all'indice dello script init nella matrice di attributi. Vedere Scrittura di criteri per gli attributi di matrice. |
instance_pool_id |
corda | Controlla il pool utilizzato dai nodi di lavoro se driver_instance_pool_id è anch'esso definito, o per tutti i nodi del cluster altrimenti. Se si usano pool per i nodi di lavoro, è necessario usare anche i pool per il nodo driver. Se nascosto, rimuove la selezione del pool dall'interfaccia utente. |
driver_instance_pool_id |
corda | Se specificato, configura un pool diverso per il nodo driver rispetto ai nodi di lavoro. Se non specificato, eredita instance_pool_id. Se si usano pool per i nodi di lavoro, è necessario usare anche i pool per il nodo driver. Se nascosto, rimuove la selezione del pool di driver dall'interfaccia utente. |
is_single_node |
booleano | Se impostato su true, il calcolo deve essere a nodo singolo. Questo attributo è supportato solo quando l'utente usa il modulo semplice. |
node_type_id |
corda | Se nascosto, rimuove la selezione del tipo di nodo di lavoro dall'interfaccia utente. |
worker_node_type_flexibility.alternate_node_type_ids |
corda | Specifica i tipi di nodo alternativi per i nodi di lavoro. Sono supportati solo i criteri fissi. Vedere Tipi di nodo flessibili. |
num_workers |
numero facoltativo | Quando è nascosta, rimuove la specifica del numero del lavoratore dall'interfaccia utente. |
runtime_engine |
corda | Determina se il cluster usa o meno Photon. I valori possibili sono PHOTON o STANDARD. |
single_user_name |
corda | Controlla quali utenti o gruppi possono essere assegnati alla risorsa di calcolo. |
spark_conf.* |
stringa facoltativa | Controlla valori di configurazione specifici aggiungendo il nome della chiave di configurazione, ad esempio: spark_conf.spark.executor.memory. |
spark_env_vars.* |
stringa facoltativa | Controlla valori specifici delle variabili di ambiente Spark aggiungendo la variabile di ambiente, ad esempio: spark_env_vars.<environment variable name>. |
spark_version |
corda | Nome della versione dell'immagine Spark, come specificato tramite l'API (ovvero il Databricks Runtime). È anche possibile usare valori di criteri speciali che selezionano dinamicamente Databricks Runtime. Vedere Valori dei criteri speciali per la selezione di Databricks Runtime. |
use_ml_runtime |
booleano | Controlla se è necessario usare una versione ml di Databricks Runtime. Questo attributo è supportato solo quando l'utente usa il modulo semplice. |
workload_type.clients.jobs |
booleano | Definisce se la risorsa di calcolo può essere usata per le attività. Vedi Impedire l'uso del calcolo con le attività. |
workload_type.clients.notebooks |
booleano | Definisce se la risorsa di calcolo può essere usata con i notebook. Vedi Impedire l'uso del calcolo con le attività. |
Percorsi degli attributi virtuali
Questa tabella include due attributi sintetici aggiuntivi supportati dai criteri. Se si usa il nuovo modulo dei criteri, questi attributi possono essere impostati nella sezione Opzioni avanzate .
| Percorso dell'attributo | Tipo | Descrizione |
|---|---|---|
dbus_per_hour |
numero | Attributo calcolato che rappresenta il numero massimo di DBU che una risorsa può usare su base oraria, incluso il nodo driver. Questa metrica è un modo diretto per controllare i costi a livello di calcolo individuale. Usare con limitazione dell'intervallo. |
cluster_type |
corda | Rappresenta il tipo di cluster che è possibile creare:
Consenti o blocca la creazione di tipi di calcolo specificati dalla policy. Se il valore all-purpose non è consentito, il criterio non viene visualizzato nell'interfaccia utente generale per la creazione di risorse di calcolo. Se il valore job non è consentito, il criterio non viene visualizzato nell'interfaccia utente di creazione del processo di calcolo. |
Tipi di nodo flessibili
Gli attributi dei tipi di nodo flessibili consentono di specificare tipi di nodo alternativi che la risorsa di calcolo può usare se il tipo di nodo primario non è disponibile. Questi attributi hanno requisiti specifici per i criteri:
- Sono supportati solo i criteri fissi. Tutti gli altri tipi di criteri non sono consentiti e verranno rifiutati in fase di creazione dei criteri.
- Una stringa vuota nella policy viene associata a un elenco vuoto di tipi di nodo alternativi, disabilitando effettivamente i tipi di nodo flessibili.
Correzione per un elenco specifico di tipi di nodo
A differenza dei campi API Clusters corrispondenti che usano una matrice di stringhe, gli attributi dei criteri di calcolo usano un singolo valore stringa che codifica la matrice di tipi di nodo come elenco delimitato da virgole. Per esempio:
{
"worker_node_type_flexibility.alternate_node_type_ids": {
"type": "fixed",
"value": "nodeA,nodeB"
}
}
Se si usa l'API Clusters per creare una risorsa di calcolo con un criterio assegnato, Databricks consiglia di non impostare i worker_node_type_flexibility campi o driver_node_type_flexibility . Se si impostano questi campi, i tipi di nodo e l'ordine della matrice devono corrispondere esattamente all'elenco delimitato da virgole del criterio oppure non è possibile creare il calcolo. Ad esempio, la definizione dei criteri precedente verrebbe impostata come segue:
"worker_node_type_flexibility": {
"alternate_node_type_ids": ["nodeA", "nodeB"]
}
Disabilitare i tipi di nodo flessibili
Per disabilitare i tipi di nodo flessibili, impostare il valore su una stringa vuota. Per esempio:
{
"worker_node_type_flexibility.alternate_node_type_ids": {
"type": "fixed",
"value": ""
}
}
Valori delle politiche speciali per la selezione di Databricks Runtime
L'attributo spark_version supporta valori speciali che mappano dinamicamente a una versione di Databricks Runtime basata sull'attuale set di versioni di Databricks Runtime supportate.
I valori seguenti possono essere usati nell'attributo spark_version:
-
auto:latest: Corrisponde alla versione GA più recente di Databricks Runtime. -
auto:latest-ml: Fa riferimento alla versione più recente di Databricks Runtime ML. -
auto:latest-lts: Mappa alla versione più recente di Databricks Runtime con supporto a lungo termine (Long Term Support - LTS). -
auto:latest-lts-ml: Corrisponde alla versione più recente di LTS Databricks Runtime ML. -
auto:prev-major: Mappa alla seconda più recente versione GA di Databricks Runtime. Ad esempio, seauto:latestè 14.2,auto:prev-majorè 13.3. -
auto:prev-major-ml: corrisponde alla penultima versione disponibile in disponibilità generale di Databricks Runtime ML. Ad esempio, seauto:latestè 14.2,auto:prev-majorè 13.3. -
auto:prev-lts: corrisponde alla seconda versione più recente di Databricks Runtime LTS. Ad esempio, seauto:latest-ltsè 13.3,auto:prev-ltsè 12.2. -
auto:prev-lts-ml: mappa alla seconda versione più recente di LTS del Databricks Runtime ML. Ad esempio, seauto:latest-ltsè 13.3,auto:prev-ltsè 12.2.
Nota
L'uso di questi valori non esegue l'aggiornamento automatico delle risorse di calcolo quando viene rilasciata una nuova versione di runtime. Un utente deve modificare esplicitamente la configurazione di calcolo per cambiare la versione di Databricks Runtime.
Tipi di criteri supportati
Questa sezione include un riferimento per ognuno dei tipi di criteri disponibili. Esistono due categorie di tipi di criteri: criteri fissi e criteri di limitazione.
Le politiche fisse impediscono la configurazione utente su un attributo. I due tipi di criteri fissi sono:
La limitazione dei criteri limita le opzioni di un utente per la configurazione di un attributo. I criteri di limitazione consentono anche di impostare i valori predefiniti e rendere facoltativi gli attributi. Vedere Campi dei criteri di limitazione aggiuntivi.
Le opzioni per limitare i criteri sono:
- Politica di lista di autorizzazione
- politica della lista di blocco
- politica Regex
- Politica di intervallo
- Politica illimitata
politica fissa
I criteri fissi limitano l'attributo al valore specificato. Per i valori di attributo diversi da numerico e booleano, il valore deve essere rappresentato da o convertibile in una stringa.
Con i criteri fissi, è anche possibile nascondere l'attributo dall'interfaccia utente impostando il campo hidden su true.
interface FixedPolicy {
type: "fixed";
value: string | number | boolean;
hidden?: boolean;
}
Questo criterio di esempio definisce la versione di Databricks Runtime e nasconde il campo dall'interfaccia utente:
{
"spark_version": { "type": "fixed", "value": "auto:latest-lts", "hidden": true }
}
Politica vietata
Un criterio non consentito impedisce agli utenti di configurare un attributo. I criteri non consentiti sono compatibili solo con gli attributi facoltativi.
interface ForbiddenPolicy {
type: "forbidden";
}
Questo criterio impedisce il collegamento di pool al calcolo per i nodi di lavoro. I pool non sono consentiti neanche per il nodo driver, perché driver_instance_pool_id eredita la politica.
{
"instance_pool_id": { "type": "forbidden" }
}
politica di lista di autorizzazioni
Un criterio allowlist specifica un elenco di valori tra cui l'utente può scegliere durante la configurazione di un attributo.
interface AllowlistPolicy {
type: "allowlist";
values: (string | number | boolean)[];
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
Questo esempio allowlist consente all'utente di selezionare tra due versioni di Databricks Runtime:
{
"spark_version": { "type": "allowlist", "values": ["13.3.x-scala2.12", "12.2.x-scala2.12"] }
}
Forzare gli utenti a selezionare un valore dall'elenco consenti
Se non imposti un valore predefinito per la politica dell'allowlist, l'interfaccia utente viene impostata sul primo valore dell'elenco consenti. Per forzare l'utente a selezionare manualmente un valore, impostare il valore predefinito su un valore non valido. Ad esempio: defaultValue?: "SELECT A VALUE";.
Politica della lista dei blocchi
I criteri dell'elenco di elementi bloccati elencano i valori non consentiti. Poiché i valori devono corrispondere esattamente, questo criterio potrebbe non funzionare come previsto quando l'attributo è leniente nel modo in cui viene rappresentato il valore ( ad esempio, consentendo spazi iniziali e finali).
interface BlocklistPolicy {
type: "blocklist";
values: (string | number | boolean)[];
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
Questo esempio impedisce all'utente di selezionare 7.3.x-scala2.12 come Databricks Runtime.
{
"spark_version": { "type": "blocklist", "values": ["7.3.x-scala2.12"] }
}
politica Regex
Una politica regex limita i valori disponibili a quelli che corrispondono al regex. Per motivi di sicurezza, assicurati che la tua espressione regolare sia ancorata all'inizio e alla fine del valore della stringa.
interface RegexPolicy {
type: "regex";
pattern: string;
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
Questo esempio limita le versioni di Databricks Runtime tra cui un utente può selezionare:
{
"spark_version": { "type": "regex", "pattern": "13\\.[3456].*" }
}
Politica di intervallo
Un criterio di intervallo limita il valore a un intervallo specificato usando i campi minValue e maxValue. Il valore deve essere un numero decimale.
I limiti numerici devono essere rappresentabili come valore a virgola mobile doppia. Per indicare la mancanza di un limite specifico, è possibile omettere minValue o maxValue.
interface RangePolicy {
type: "range";
minValue?: number;
maxValue?: number;
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
Questo esempio limita il numero massimo di lavoratori a 10.
{
"num_workers": { "type": "range", "maxValue": 10 }
}
politica illimitata
Il criterio illimitato viene usato per rendere obbligatori gli attributi o per impostare il valore predefinito nell'interfaccia utente.
interface UnlimitedPolicy {
type: "unlimited";
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
Questo esempio aggiunge il tag COST_BUCKET al calcolo:
{
"custom_tags.COST_BUCKET": { "type": "unlimited" }
}
Per impostare un valore predefinito per una variabile di configurazione Spark, ma anche consentire l'omissione (rimozione) di questa variabile:
{
"spark_conf.spark.my.conf": { "type": "unlimited", "isOptional": true, "defaultValue": "my_value" }
}
Campi dei criteri di limitazione aggiuntivi
Per limitare i tipi di criteri, è possibile specificare due campi aggiuntivi:
-
defaultValue- Il valore che si inserisce automaticamente nell'interfaccia utente per la creazione di risorse di calcolo. -
isOptional: un criterio di limitazione per un attributo lo rende necessario automaticamente. Per rendere facoltativo l'attributo, impostare il campoisOptionalsutrue.
Nota
I valori predefiniti non vengono applicati automaticamente al calcolo creato con l'API Clusters. Per applicare i valori predefiniti usando l'API, aggiungere il parametro apply_policy_default_values alla definizione di calcolo e impostarlo su true.
Questo esempio di politica specifica il valore predefinito id1 per il pool per i nodi di lavoro, ma lo rende facoltativo. Quando si crea il calcolo, è possibile selezionare un pool diverso o scegliere di non usarlo. Se driver_instance_pool_id non è definito nei criteri o quando si crea il calcolo, viene usato lo stesso pool per i nodi di lavoro e il nodo driver.
{
"instance_pool_id": { "type": "unlimited", "isOptional": true, "defaultValue": "id1" }
}
Scrittura di criteri per gli attributi di matrice
È possibile specificare i criteri per gli attributi di matrice in due modi:
- Limitazioni generiche per tutti gli elementi della matrice. Queste limitazioni usano il simbolo jolly
*nel percorso dei criteri. - Limitazioni specifiche per un elemento di matrice in corrispondenza di un indice specifico. Queste limitazioni usano un numero nel percorso.
Nota
Gli attributi dei tipi di nodo flessibili (worker_node_type_flexibility.alternate_node_type_ids e driver_node_type_flexibility.alternate_node_type_ids) sono campi di tipo matrice nell'API Clusters, ma non seguono il modello di percorso con caratteri jolly/indicizzati documentato qui. Questi attributi richiedono una singola regola dei criteri che specifica l'elenco completo come stringa delimitata da virgole. Per informazioni dettagliate, vedere Tipi di nodo flessibili .
Ad esempio, per l'attributo di matrice init_scripts, i percorsi generici iniziano con init_scripts.* e i percorsi specifici con init_scripts.<n>, dove <n> è un indice intero nella matrice (a partire da 0).
È possibile combinare limitazioni generiche e specifiche, nel qual caso la limitazione generica si applica a ogni elemento di matrice che non presenta una limitazione specifica. In ogni caso verrà applicata una sola limitazione dei criteri.
Nelle sezioni seguenti vengono illustrati esempi di esempi comuni che usano attributi di matrice.
Richiedi voci specifiche per l'inclusione
Non è possibile richiedere valori specifici senza specificare l'ordine. Per esempio:
{
"init_scripts.0.volumes.destination": {
"type": "fixed",
"value": "<required-script-1>"
},
"init_scripts.1.volumes.destination": {
"type": "fixed",
"value": "<required-script-2>"
}
}
Richiedi un valore fisso dell'intero elenco
{
"init_scripts.0.volumes.destination": {
"type": "fixed",
"value": "<required-script-1>"
},
"init_scripts.*.volumes.destination": {
"type": "forbidden"
}
}
Non consentire l'uso completamente
{
"init_scripts.*.volumes.destination": {
"type": "forbidden"
}
}
Consenti elementi che seguono restrizioni specifiche
{
"init_scripts.*.volumes.destination": {
"type": "regex",
"pattern": ".*<required-content>.*"
}
}
Correggere un set specifico di script init
In caso di percorsi di init_scripts, la matrice può contenere una delle molte strutture per cui tutte le possibili varianti devono essere gestite a seconda del caso d'uso. Ad esempio, per richiedere un set specifico di script init e non consentire qualsiasi variante dell'altra versione, è possibile usare il modello seguente:
{
"init_scripts.0.volumes.destination": {
"type": "fixed",
"value": "<volume-paths>"
},
"init_scripts.1.volumes.destination": {
"type": "fixed",
"value": "<volume-paths>"
},
"init_scripts.*.workspace.destination": {
"type": "forbidden"
},
"init_scripts.*.abfss.destination": {
"type": "forbidden"
},
"init_scripts.*.file.destination": {
"type": "forbidden"
}
}
Esempi di politiche
Questa sezione include esempi di criteri che è possibile usare come riferimenti per la creazione di criteri personalizzati. È anche possibile usare le famiglie di criteri di fornite da Azure Databricks come modelli per i casi d'uso comuni dei criteri.
- criteri di calcolo generali
- Definire i limiti per il calcolo delle pipeline Lakeflow
- Semplice polizza di medie dimensioni
- Politica esclusivamente lavorativa
- Politica del Metastore Esterno
- Impedire l'uso del calcolo con i lavori
- Rimuovere i criteri di scalabilità automatica
- applicazione e controllo dei tag personalizzati
Criteri di calcolo generali
Un criterio di calcolo per utilizzo generico destinato a guidare gli utenti e limitare alcune funzionalità, richiedendo tag, limitando il numero massimo di istanze e applicando il timeout.
{
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"spark_version": {
"type": "regex",
"pattern": "12\\.[0-9]+\\.x-scala.*"
},
"node_type_id": {
"type": "allowlist",
"values": ["Standard_L4s", "Standard_L8s", "Standard_L16s"],
"defaultValue": "Standard_L16s_v2"
},
"driver_node_type_id": {
"type": "fixed",
"value": "Standard_L16s_v2",
"hidden": true
},
"autoscale.min_workers": {
"type": "fixed",
"value": 1,
"hidden": true
},
"autoscale.max_workers": {
"type": "range",
"maxValue": 25,
"defaultValue": 5
},
"autotermination_minutes": {
"type": "fixed",
"value": 30,
"hidden": true
},
"custom_tags.team": {
"type": "fixed",
"value": "product"
}
}
Definire i limiti per il calcolo delle pipeline Lakeflow
Nota
Quando si usano criteri per configurare il calcolo delle pipeline di Lakeflow, Databricks consiglia di applicare un singolo criterio sia al calcolo che a default .maintenance
Per configurare un criterio per un calcolo della pipeline, creare un criterio con il campo cluster_type impostato su dlt. L'esempio seguente crea un criterio minimo per il calcolo di una pipeline Lakeflow:
{
"cluster_type": {
"type": "fixed",
"value": "dlt"
},
"num_workers": {
"type": "unlimited",
"defaultValue": 3,
"isOptional": true
},
"node_type_id": {
"type": "unlimited",
"isOptional": true
},
"spark_version": {
"type": "unlimited",
"hidden": true
}
}
Polizza semplice e di medie dimensioni
Consente agli utenti di creare un calcolo di medie dimensioni con una configurazione minima. L'unico campo obbligatorio in fase di creazione è il nome del calcolo; il resto è fisso e nascosto.
{
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"spark_conf.spark.databricks.cluster.profile": {
"type": "forbidden",
"hidden": true
},
"autoscale.min_workers": {
"type": "fixed",
"value": 1,
"hidden": true
},
"autoscale.max_workers": {
"type": "fixed",
"value": 10,
"hidden": true
},
"autotermination_minutes": {
"type": "fixed",
"value": 60,
"hidden": true
},
"node_type_id": {
"type": "fixed",
"value": "Standard_L8s_v2",
"hidden": true
},
"driver_node_type_id": {
"type": "fixed",
"value": "Standard_L8s_v2",
"hidden": true
},
"spark_version": {
"type": "fixed",
"value": "auto:latest-ml",
"hidden": true
},
"custom_tags.team": {
"type": "fixed",
"value": "product"
}
}
Politica solo lavoro
Consente agli utenti di creare processi di calcolo per eseguire attività. Gli utenti non possono creare risorse di calcolo per tutti gli scopi usando questo criterio.
{
"cluster_type": {
"type": "fixed",
"value": "job"
},
"dbus_per_hour": {
"type": "range",
"maxValue": 100
},
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"num_workers": {
"type": "range",
"minValue": 1
},
"node_type_id": {
"type": "regex",
"pattern": "Standard_[DLS]*[1-6]{1,2}_v[2,3]"
},
"driver_node_type_id": {
"type": "regex",
"pattern": "Standard_[DLS]*[1-6]{1,2}_v[2,3]"
},
"spark_version": {
"type": "unlimited",
"defaultValue": "auto:latest-lts"
},
"custom_tags.team": {
"type": "fixed",
"value": "product"
}
}
Politica del metastore esterno
Consente agli utenti di creare un ambiente di calcolo con un metastore definito dall'amministratore già collegato. Ciò è utile per consentire agli utenti di creare il proprio ambiente di calcolo senza richiedere una configurazione aggiuntiva.
{
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionURL": {
"type": "fixed",
"value": "jdbc:sqlserver://<jdbc-url>"
},
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionDriverName": {
"type": "fixed",
"value": "com.microsoft.sqlserver.jdbc.SQLServerDriver"
},
"spark_conf.spark.databricks.delta.preview.enabled": {
"type": "fixed",
"value": "true"
},
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionUserName": {
"type": "fixed",
"value": "<metastore-user>"
},
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionPassword": {
"type": "fixed",
"value": "<metastore-password>"
}
}
Impedire l'uso delle risorse di calcolo nei lavori
Questo criterio impedisce agli utenti di usare il calcolo per eseguire i processi. Gli utenti potranno usare solo il calcolo con i notebook.
{
"workload_type.clients.notebooks": {
"type": "fixed",
"value": true
},
"workload_type.clients.jobs": {
"type": "fixed",
"value": false
}
}
Rimuovere i criteri di scalabilità automatica
Questo criterio disabilita la scalabilità automatica e consente all'utente di impostare il numero di ruoli di lavoro all'interno di un determinato intervallo.
{
"num_workers": {
"type": "range",
"maxValue": 25,
"minValue": 1,
"defaultValue": 5
}
}
Imposizione dei tag personalizzati
Per aggiungere una regola di tag di calcolo a una politica, usare l'attributo custom_tags.<tag-name>.
Ad esempio, qualsiasi utente che usa questo criterio deve compilare un tag COST_CENTER con 9999, 9921 o 9531 per il calcolo da avviare:
{ "custom_tags.COST_CENTER": { "type": "allowlist", "values": ["9999", "9921", "9531"] } }