Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Importante
- Questa documentazione è stata ritirata e potrebbe non essere aggiornata. Il prodotto, il servizio o la tecnologia citati in questo contenuto non sono più supportati.
- Le indicazioni contenute in questo articolo sono relative alla gestione del modello MLflow legacy. Databricks consiglia di eseguire la migrazione del modello che gestisce i flussi di lavoro a Model Serving per la distribuzione e la scalabilità avanzata degli endpoint del modello. Per altre informazioni, vedere Distribuire modelli con Mosaic AI Model Serving.
MLflow Model Serving legacy consente di ospitare modelli di Machine Learning dal Registro modelli come endpoint REST aggiornati automaticamente in base alla disponibilità delle versioni del modello e alle relative fasi. Usa un cluster a nodo singolo che viene eseguito con il proprio account all'interno di ciò che è ora denominato piano di calcolo classico. Questo piano di calcolo include la rete virtuale e le risorse di calcolo associate, ad esempio cluster per notebook e processi, data warehouse SQL classici e legacy che servono gli endpoint.
Quando si abilita la gestione del modello per un determinato modello registrato, Azure Databricks crea automaticamente un cluster univoco per il modello e distribuisce tutte le versioni non archiviate del modello in tale cluster. Azure Databricks riavvia il cluster se si verifica un errore e termina il cluster quando si disabilita la gestione del modello per il modello. Il modello viene sincronizzato automaticamente con il Registro modelli e distribuisce le nuove versioni del modello registrate. Le versioni del modello distribuite possono essere sottoposte a query con una richiesta API REST standard. Azure Databricks autentica le richieste al modello usando l'autenticazione standard.
Anche se questo servizio è in anteprima, Databricks consiglia di usarlo per applicazioni a bassa velocità effettiva e non critiche. La velocità effettiva di destinazione è di 200 qps e la disponibilità di destinazione è pari al 99,5%, anche se non viene garantita alcuna garanzia. Inoltre, esiste un limite di dimensioni del payload di 16 MB per ogni richiesta.
Ogni versione del modello viene distribuita usando la distribuzione del modello MLflow ed eseguita in un ambiente Conda specificato dalle relative dipendenze.
Nota
- Il cluster viene mantenuto finché la gestione è abilitata, anche se non esiste alcuna versione del modello attiva. Per terminare il cluster di gestione, disabilitare la gestione del modello per il modello registrato.
- Il cluster è considerato un cluster all-purpose, soggetto ai prezzi di tutti i carichi di lavoro.
- Gli script init globali non vengono eseguiti nei cluster di gestione dei modelli.
Importante
Anaconda Inc. ha aggiornato i termini di servizio per i canali di anaconda.org. In base alle nuove condizioni di servizio, potrebbe essere necessaria una licenza commerciale se ci si affida alla distribuzione di Anaconda e al suo packaging. Per altre informazioni, vedere Domande frequenti su Anaconda Commercial Edition . L'uso di qualsiasi canale Anaconda è disciplinato dalle condizioni del servizio.
I modelli MLflow registrati prima della versione 1.18 (Databricks Runtime 8.3 ML o versioni precedenti) sono stati registrati per impostazione predefinita con il canale conda defaults (https://repo.anaconda.com/pkgs/) come dipendenza. A causa di questa modifica della licenza, Databricks ha interrotto l'uso del canale per i modelli defaults registrati usando MLflow v1.18 e versioni successive. Il canale predefinito registrato è ora conda-forge, che punta alla community gestita https://conda-forge.org/.
Se è stato registrato un modello prima di MLflow v1.18 senza escludere il canale defaults dall'ambiente conda per il modello, tale modello potrebbe avere una dipendenza dal canale defaults che potrebbe non essere prevista.
Per verificare manualmente se un modello ha questa dipendenza, è possibile esaminare il valore channel nel file conda.yaml incluso nel pacchetto con il modello registrato. Ad esempio, un conda.yaml modello con una defaults dipendenza del canale può essere simile al seguente:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Poiché Databricks non è in grado di stabilire se l'uso del repository di Anaconda per interagire con i propri modelli sia consentito dal rapporto con Anaconda, Databricks non obbliga i propri clienti ad apportare alcuna modifica. Se l'uso del repository Anaconda.com tramite l'uso di Databricks è consentito in base ai termini di Anaconda, non è necessario eseguire alcuna azione.
Se si vuole modificare il canale usato nell'ambiente di un modello, è possibile registrare nuovamente il modello nel registro dei modelli con un nuovo conda.yamloggetto . A tale scopo, è possibile specificare il canale nel parametro conda_env di log_model().
Per altre informazioni sull'API log_model() , vedere la documentazione di MLflow relativa al tipo di modello in uso, ad esempio log_model per scikit-learn.
Per altre informazioni sui conda.yaml file, vedere la documentazione di MLflow.
Requisiti
- MLflow Model Serving legacy è disponibile per i modelli MLflow Python. È necessario dichiarare tutte le dipendenze del modello nell'ambiente conda. Vedere Dipendenze del modello di log.
- Per abilitare La gestione dei modelli, è necessario disporre dell'autorizzazione di creazione del cluster.
Modello usato dal Registro modelli
La gestione dei modelli è disponibile in Azure Databricks dal Registro modelli.
Abilitare e disabilitare la gestione del modello
Si abilita un modello per la gestione dalla pagina del modello registrato.
Fare clic sulla scheda Serve . Se il modello non è già abilitato per la gestione, viene visualizzato il pulsante Abilita servizio .
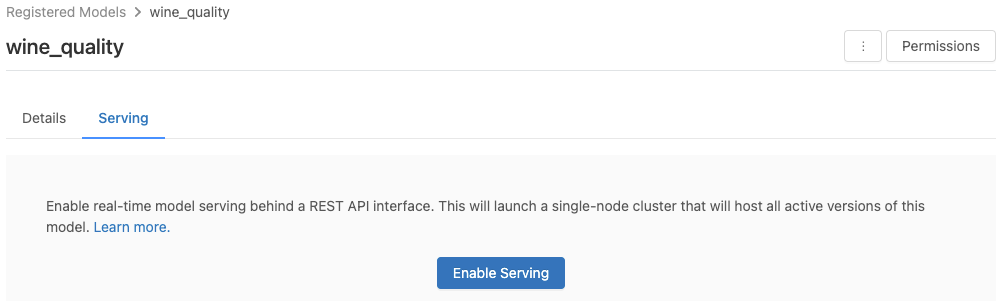
Fare clic su Abilita servizio. La scheda Serve viene visualizzata con Stato indicato come In sospeso. Dopo alcuni minuti, lo stato diventa Pronto.
Per disabilitare un modello per la gestione, fare clic su Arresta.
Convalidare la gestione del modello
Dalla scheda Serve è possibile inviare una richiesta al modello servito e visualizzare la risposta.
URI della versione del modello
A ogni versione del modello distribuito viene assegnato uno o più URI univoci. Come minimo, a ogni versione del modello viene assegnato un URI costruito come segue:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
Ad esempio, per chiamare la versione 1 di un modello registrato come iris-classifier, usare questo URI:
https://<databricks-instance>/model/iris-classifier/1/invocations
È anche possibile chiamare una versione del modello in base alla relativa fase. Ad esempio, se la versione 1 si trova nella fase Production, può anche essere valutata usando questo URI:
https://<databricks-instance>/model/iris-classifier/Production/invocations
L'elenco degli URI del modello disponibili viene visualizzato nella parte superiore della scheda Versioni del modello nella pagina di gestione.
Gestire le versioni gestite
Tutte le versioni del modello attive (non archiviate) vengono distribuite ed è possibile eseguire query usando gli URI. Azure Databricks distribuisce automaticamente nuove versioni del modello quando vengono registrate e rimuove automaticamente le versioni precedenti quando vengono archiviate.
Nota
Tutte le versioni distribuite di un modello registrato condividono lo stesso cluster.
Gestire i diritti di accesso ai modelli
I diritti di accesso ai modelli vengono ereditati dal Registro modelli. Per abilitare o disabilitare la funzionalità di gestione è necessaria l'autorizzazione "manage" per il modello registrato. Chiunque abbia diritti di lettura può assegnare un punteggio a una qualsiasi delle versioni distribuite.
Assegnare un punteggio alle versioni del modello distribuite
Per assegnare un punteggio a un modello distribuito, è possibile usare l'interfaccia utente o inviare una richiesta API REST all'URI del modello.
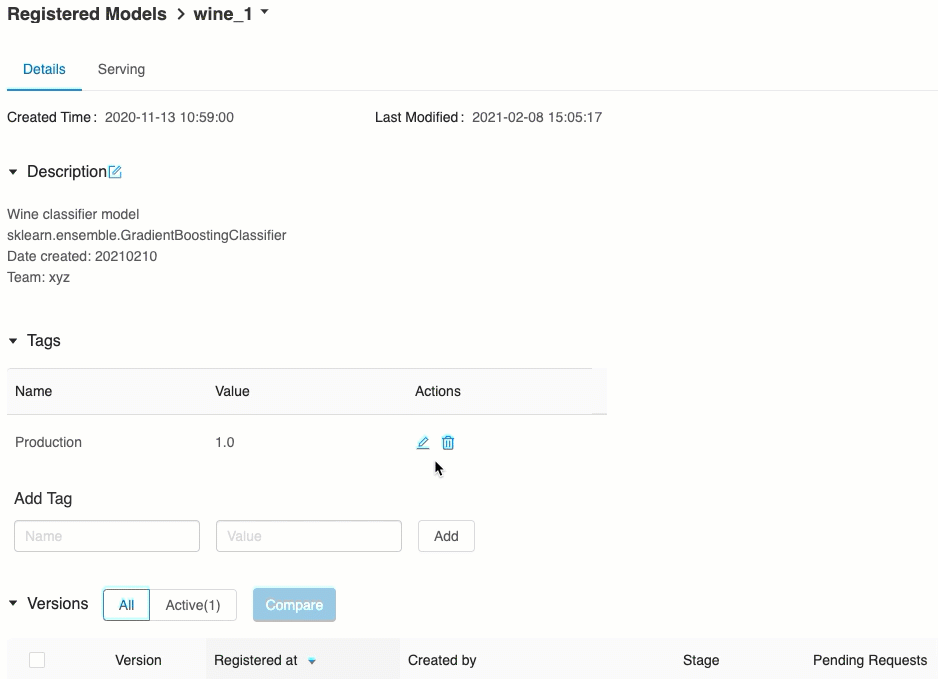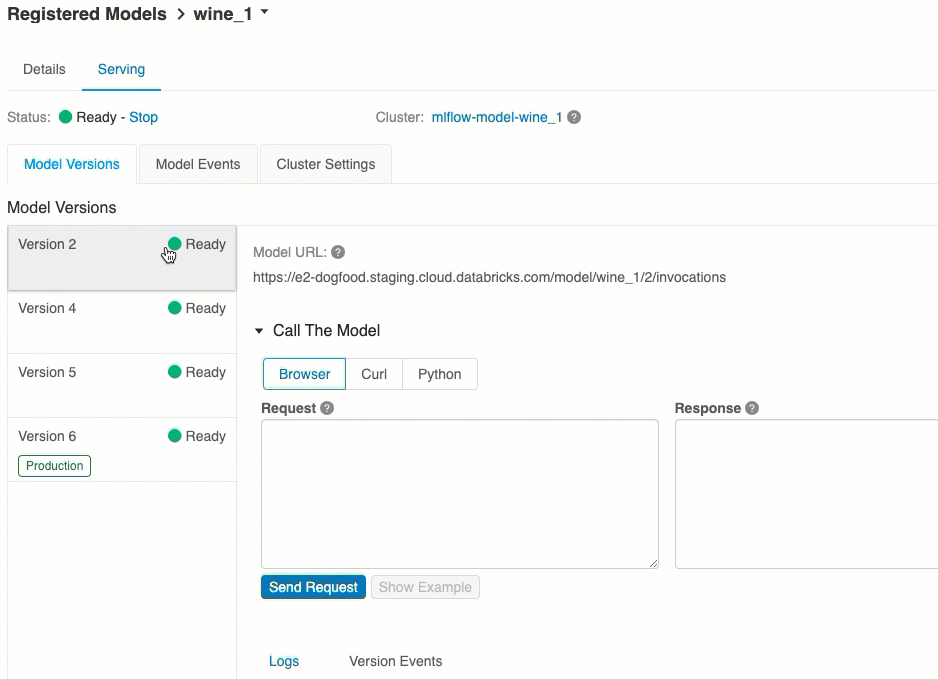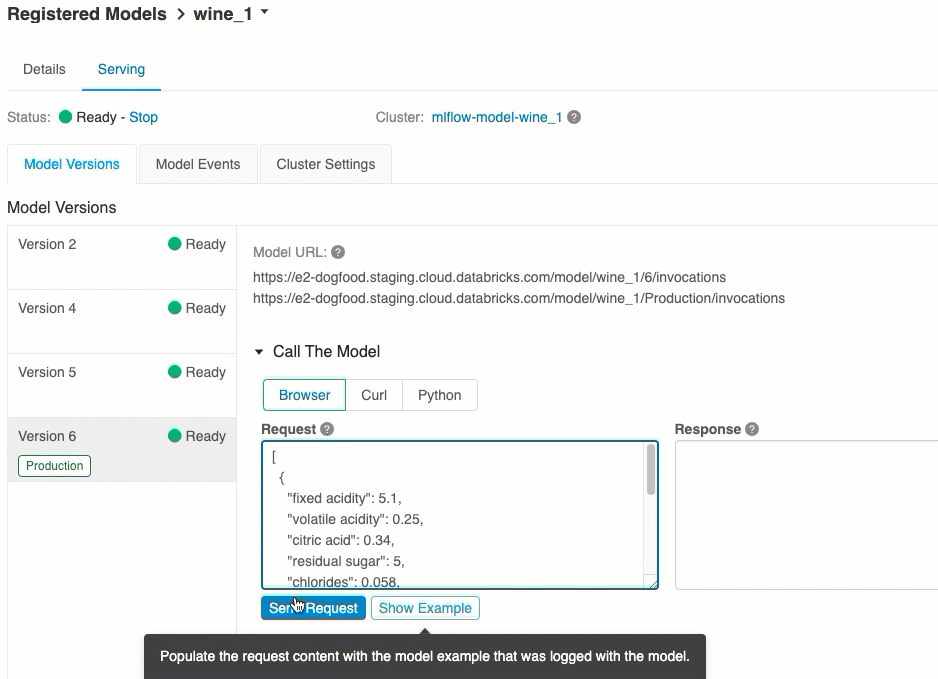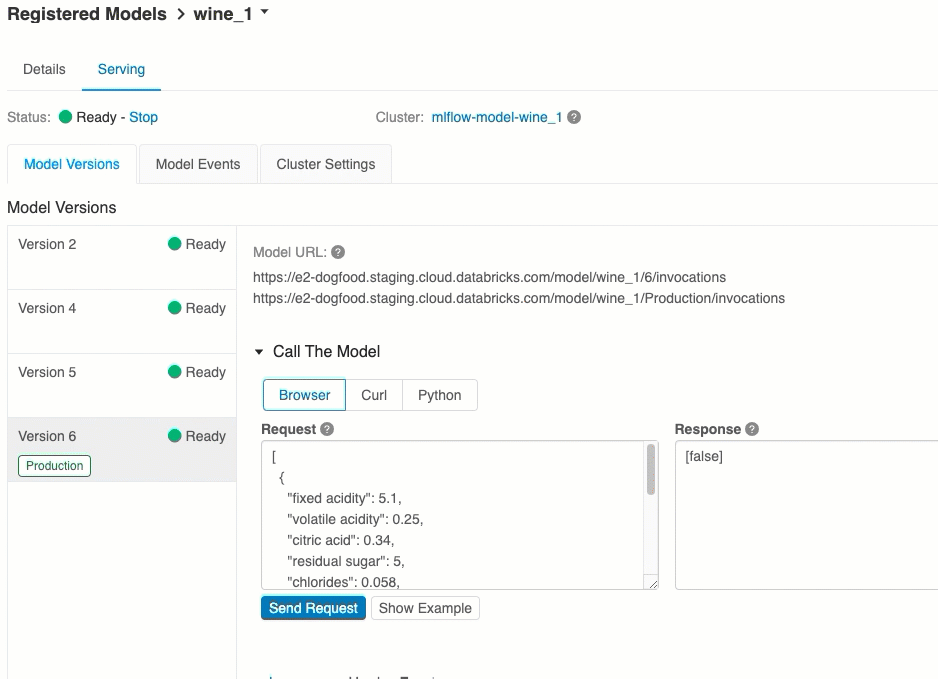
Punteggio tramite l'interfaccia utente
Questo è il modo più semplice e rapido per testare il modello. È possibile inserire i dati di input del modello in formato JSON e fare clic su Invia richiesta. Se il modello è stato registrato con un esempio di input (come illustrato nell'immagine precedente), fare clic su Carica esempio per caricare l'esempio di input.
Assegnare un punteggio tramite la richiesta dell'API REST
È possibile inviare una richiesta di assegnazione dei punteggi tramite l'API REST usando l'autenticazione standard di Databricks. Gli esempi seguenti illustrano l'autenticazione usando un token di accesso personale con MLflow 1.x.
Nota
Come procedura consigliata per la sicurezza, quando si esegue l'autenticazione con strumenti automatizzati, sistemi, script e app, Databricks consiglia di usare token di accesso personali appartenenti alle entità servizio anziché agli utenti dell'area di lavoro. Per creare token per le entità servizio, vedere Gestire i token per un'entità servizio.
Dato un MODEL_VERSION_URI like https://<databricks-instance>/model/iris-classifier/Production/invocations (dove <databricks-instance> è il nome dell'istanza di Databricks) e un token dell'API REST di Databricks denominato DATABRICKS_API_TOKEN, gli esempi seguenti illustrano come eseguire query su un modello servito:
Gli esempi seguenti riflettono il formato di assegnazione dei punteggi per i modelli creati con MLflow 1.x. Se si preferisce usare MLflow 2.0, è necessario aggiornare il formato di payload della richiesta.
Bash
Frammento di codice per eseguire query su un modello che accetta gli input del dataframe.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
Frammento di codice per eseguire query su un modello che accetta input tensor. Gli input tensor devono essere formattati come descritto nella documentazione api di TensorFlow Serving.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Pitone
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
Power BI
È possibile assegnare un punteggio a un set di dati in Power BI Desktop seguendo questa procedura:
Aprire il set di dati per assegnare un punteggio.
Vai a Trasformazione Dati.
Fare clic con il pulsante destro del mouse nel pannello sinistro e selezionare Crea nuova query.
Passare a Visualizza > editor avanzato.
Sostituire il corpo della query con il frammento di codice seguente, dopo aver compilato un oggetto appropriato
DATABRICKS_API_TOKENeMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionAssegnare alla query il nome del modello desiderato.
Aprire l'editor di query avanzato per il set di dati e applicare la funzione del modello.
Monitorare i modelli serviti
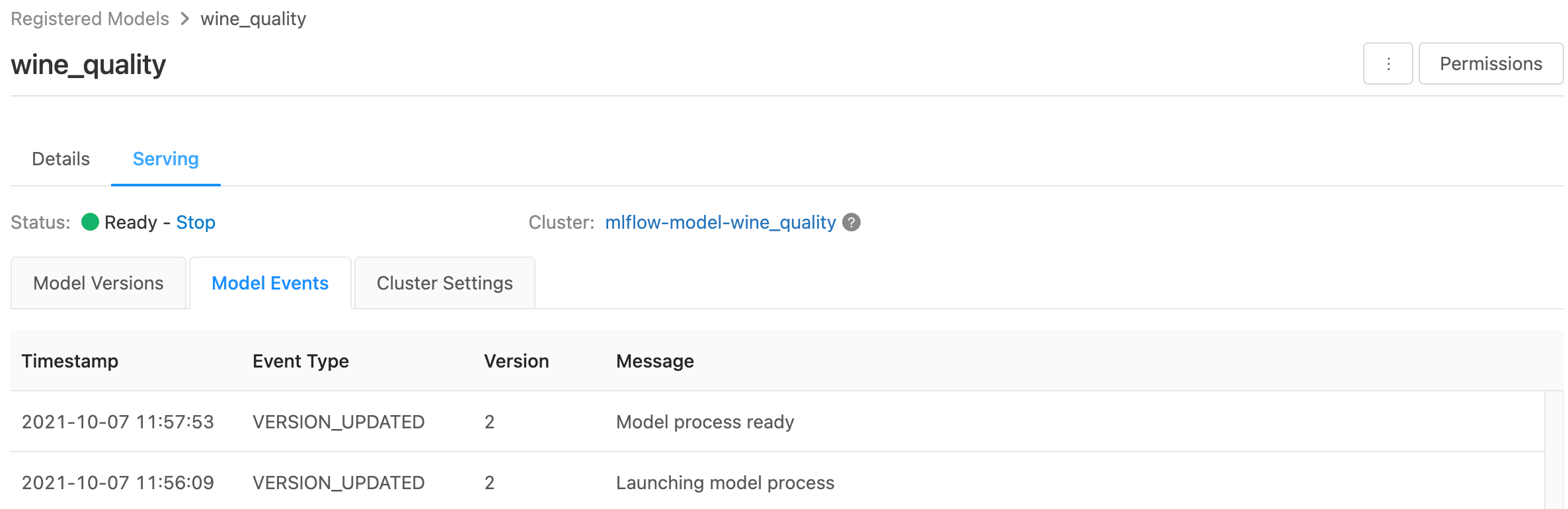
Nella pagina di gestione vengono visualizzati gli indicatori di stato per il cluster di gestione e le singole versioni del modello.
- Per esaminare lo stato del cluster di gestione, usare la scheda Eventi modello , che visualizza un elenco di tutti gli eventi che servono per questo modello.
- Per esaminare lo stato di una singola versione del modello, fare clic sulla scheda Versioni modello e scorrere per visualizzare le schede Log o Eventi versione .
Personalizzare il cluster di gestione
Per personalizzare il cluster di gestione, usare la scheda Impostazioni cluster nella scheda Serve .
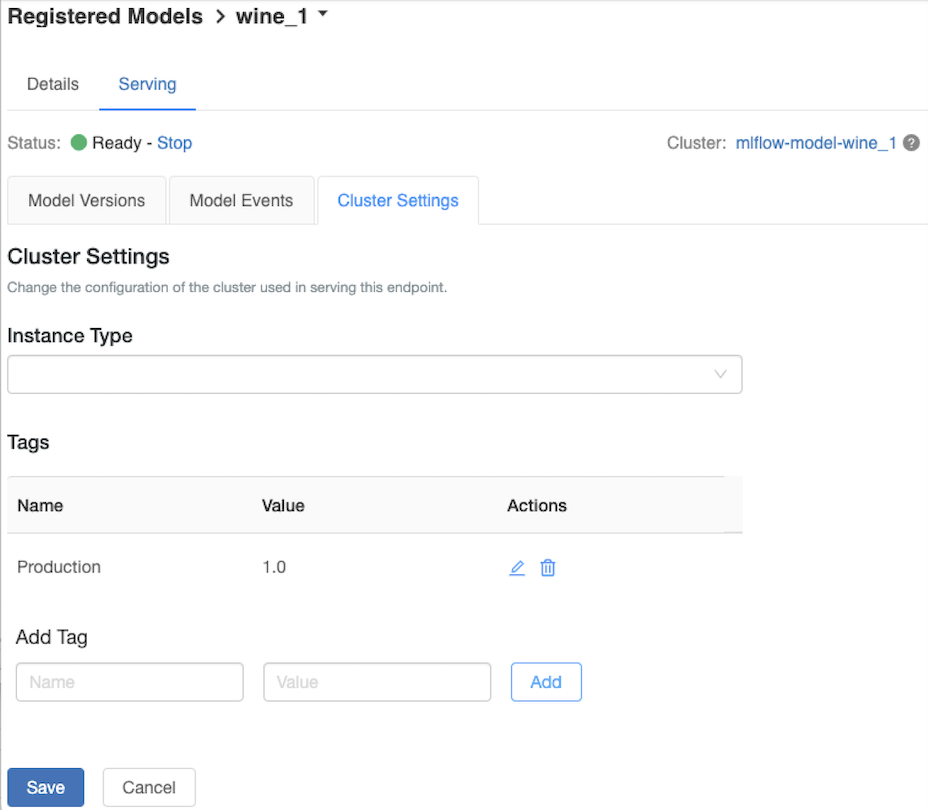
- Per modificare le dimensioni della memoria e il numero di core di un cluster di gestione, usare il menu a discesa Tipo di istanza per selezionare la configurazione del cluster desiderata. Quando si fa clic su Salva, il cluster esistente viene terminato e viene creato un nuovo cluster con le impostazioni specificate.
- Per aggiungere un tag, digitare il nome e il valore nei campi Aggiungi tag e fare clic su Aggiungi.
- Per modificare o eliminare un tag esistente, fare clic su una delle icone nella colonna Azioni della tabella Tag .
Integrazione dell'archivio funzionalità
La gestione dei modelli legacy può cercare automaticamente i valori delle funzionalità dagli archivi online pubblicati.
Databricks Legacy MLflow Model Serving supporta la ricerca automatica delle caratteristiche da questi archivi dati online.
- Azure Cosmos DB (versione v0.5.0 e successive)
- Database di Azure per MySQL
Errori noti
ResolvePackageNotFound: pyspark=3.1.0
Questo errore può verificarsi se un modello dipende da pyspark e viene registrato usando Databricks Runtime 8.x.
Se viene visualizzato questo errore, specificare la pyspark versione in modo esplicito durante la registrazione del modello usando il conda_env parametro .
Unrecognized content type parameters: format
Questo errore può verificarsi in seguito al nuovo formato del protocollo di punteggio MLflow 2.0. Se viene visualizzato questo errore, è probabile che si usi un formato di richiesta di assegnazione dei punteggi obsoleto. Per risolvere l'errore, è possibile:
Aggiornare il formato della richiesta di assegnazione dei punteggi al protocollo più recente.
Nota
Gli esempi seguenti riflettono il formato di punteggio introdotto in MLflow 2.0. Se si preferisce usare MLflow 1.x, è possibile modificare le
log_model()chiamate API per includere la dipendenza della versione di MLflow desiderata nelextra_pip_requirementsparametro . In questo modo si garantisce che venga usato il formato di punteggio appropriato.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
Eseguire query su un modello che accetta input del dataframe pandas.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'Eseguire una query su un modello che accetta input tensor. Gli input tensor devono essere formattati come descritto nella documentazione api di TensorFlow Serving.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Pitone
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)Power BI
È possibile assegnare un punteggio a un set di dati in Power BI Desktop seguendo questa procedura:
Aprire il set di dati per assegnare un punteggio.
Vai a Trasformazione Dati.
Fare clic con il pulsante destro del mouse nel pannello sinistro e selezionare Crea nuova query.
Passare a Visualizza > editor avanzato.
Sostituire il corpo della query con il frammento di codice seguente, dopo aver compilato un oggetto appropriato
DATABRICKS_API_TOKENeMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionAssegnare alla query il nome del modello desiderato.
Aprire l'editor di query avanzato per il set di dati e applicare la funzione del modello.
Se la richiesta di assegnazione dei punteggi usa il client MLflow, ad esempio
mlflow.pyfunc.spark_udf(), aggiornare il client MLflow alla versione 2.0 o successiva per usare il formato più recente. Altre informazioni sul protocollo di punteggio del modello MLflow aggiornato in MLflow 2.0.
Per altre informazioni sui formati di dati di input accettati dal server (ad esempio, il formato diviso pandas), vedere la documentazione di MLflow.