Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come creare una risorsa di calcolo assegnata a un gruppo usando la modalità di accesso dedicato .
La modalità di accesso ai gruppi dedicati consente agli utenti di ottenere l'efficienza operativa di un cluster in modalità di accesso standard, supportando in modo sicuro anche linguaggi e carichi di lavoro non supportati dalla modalità di accesso standard, ad esempio Databricks Runtime per ML, API RDD e R.
I cluster di gruppo sono un modo per assumere un ruolo in Azure Databricks. Quando un utente si connette a un cluster di gruppo, le autorizzazioni di identità utente vengono sostituite dalle autorizzazioni del gruppo per tutte le operazioni in tale cluster. Ciò equivale ad assumere che il gruppo assuma un ruolo per la durata della sessione del cluster. Per altri metodi di assunzione di un ruolo, tra cui il cambio di ruolo, l'interfaccia della riga di comando e l'API, vedere Cambiare i ruoli.
Requisiti
Per usare la modalità di accesso al gruppo dedicato:
- L'area di lavoro deve essere abilitata per Unity Catalog.
- È necessario usare Databricks Runtime 15.4 o versione successiva.
- Il gruppo assegnato deve disporre di autorizzazioni
CAN MANAGEper una cartella dell'area di lavoro in cui è possibile conservare notebook, esperimenti di Machine Learning e altri artefatti dell'area di lavoro usati dal cluster di gruppo.
Che cos'è la modalità di accesso dedicato?
La modalità di accesso dedicato è la versione più recente della modalità di accesso utente singolo. Con l'accesso dedicato, una risorsa di calcolo può essere assegnata a un singolo utente o gruppo, consentendo solo agli utenti assegnati di accedere all'uso della risorsa di calcolo.
Quando un utente è connesso a una risorsa di calcolo dedicata a un gruppo (un cluster di gruppo), le autorizzazioni dell'utente si sottoscrivono automaticamente alle autorizzazioni del gruppo, consentendo all'utente di condividere in modo sicuro la risorsa con gli altri membri del gruppo.
Creare una risorsa di calcolo dedicata a un gruppo
- Nell'area di lavoro Azure Databricks passare a Compute e fare clic su Crea calcolo.
- Espandi la sezione avanzata .
- In Modalità di accesso fare clic su Manuale e quindi selezionare Dedicato (in precedenza: Utente singolo) dal menu a discesa.
- Nel campo
utente singolo o gruppo selezionare il gruppo che si vuole assegnare a questa risorsa. - Configurare le altre impostazioni di calcolo desiderate, quindi fare clic su Crea.
Procedure consigliate per la gestione dei cluster di gruppo
Poiché le autorizzazioni utente sono limitate al gruppo quando si usano cluster di gruppo, Databricks consiglia di creare una cartella /Workspace/Groups/<groupName> per ogni gruppo che si intende utilizzare con un cluster di gruppo. Assegnare quindi al gruppo le autorizzazioni CAN MANAGE sulla cartella. Ciò consente ai gruppi di evitare errori di autorizzazione. Tutti i notebook e gli asset dell'area di lavoro del gruppo devono essere gestiti nella cartella del gruppo.
È anche necessario modificare i carichi di lavoro seguenti per l'esecuzione nei cluster di gruppo:
- MLflow: Assicurati di eseguire il notebook dalla cartella del gruppo o di eseguire
mlflow.set_tracking_uri("/Workspace/Groups/<groupName>"). - AutoML: impostare il parametro
experiment_dirfacoltativo su“/Workspace/Groups/<groupName>”per le esecuzioni autoML. -
dbutils.notebook.run: verificare che il gruppo disponga dell'autorizzazioneREADper il notebook in esecuzione.
Comportamento di autorizzazione nei cluster di gruppo
Tutti i comandi, le query e altre azioni eseguite in un cluster di gruppo usano le autorizzazioni assegnate al gruppo, non l'utente singolo.
Non è possibile applicare autorizzazioni utente individuali perché tutti i membri del gruppo hanno accesso completo alle API Spark e all'ambiente di calcolo condiviso. Se sono state applicate autorizzazioni basate sull'utente, un membro potrebbe eseguire query sui dati con restrizioni e un altro membro senza accesso potrebbe comunque recuperare i risultati tramite l'ambiente condiviso. Pertanto, il gruppo stesso, non l'utente membro del gruppo, deve disporre delle autorizzazioni necessarie per eseguire correttamente l'azione.
Ad esempio, il gruppo necessita di autorizzazioni esplicite per eseguire query su una tabella, accedere a un ambito segreto o segreto, usare credenziali di connessione del catalogo Unity, accedere a una cartella Git o creare un oggetto area di lavoro.
Autorizzazioni di gruppo di esempio
Quando si crea un oggetto dati usando il cluster di gruppo, il gruppo viene assegnato come proprietario dell'oggetto.
Ad esempio, se si dispone di un notebook collegato a un cluster del gruppo ed esegui il comando seguente:
use catalog main;
create schema group_cluster_group_schema;
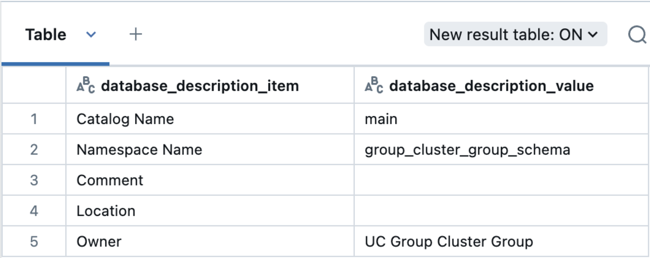
Eseguire quindi questa query per controllare il proprietario dello schema:
describe schema group_cluster_group_schema;
Attività di calcolo dedicata del gruppo di controllo
Esistono due identità chiave coinvolte quando un cluster di gruppo esegue un carico di lavoro:
- Utente che esegue il carico di lavoro nel cluster di gruppo
- Gruppo le cui autorizzazioni vengono usate per eseguire le azioni effettive del carico di lavoro
La tabella di sistema del registro di controllo registra queste identità sotto i seguenti parametri:
-
identity_metadata.run_by: L'utente autenticato che esegue l'azione -
identity_metadata.run_as: Il gruppo autorizzativo i cui permessi vengono utilizzati nell'azione.
La seguente query di esempio recupera i metadati di identità per un'azione eseguita con il cluster di gruppo.
select action_name, event_time, user_identity.email, identity_metadata
from system.access.audit
where user_identity.email = "uc-group-cluster-group" AND service_name = "unityCatalog"
order by event_time desc limit 100;
Consulta la tabella di riferimento del sistema di log di controllo per altre query di esempio. Consultare la tabella di sistema del registro di controllo .
Limitazioni note
L'accesso al gruppo dedicato presenta le limitazioni seguenti:
- I task creati utilizzando l'API e l'SDK non possono ottenere accesso ai gruppi. Questo perché il parametro del
run_asprocesso di lavoro supporta solo un singolo utente o un principale di servizio. - I processi che usano Git avranno esito negativo perché la directory temporanea usata dal processo per controllare il repository Git non è scrivibile. Usare invece cartelle Git .
- Le tabelle di sistema di lineage non registrano
identity_metadata.run_as(il gruppo autorizzante) oidentity_metadata.run_by(l'utente autenticante) per i carichi di lavoro che vengono eseguiti su un cluster di gruppo. - I log di controllo recapitati all'archiviazione dei clienti non registrano
identity_metadata.run_as(il gruppo di autorizzazione) oidentity_metadata.run_by(l'utente che esegue l'autenticazione) per i carichi di lavoro eseguiti in un cluster di gruppo. È necessario usare la tabellasystem.access.auditper visualizzare i metadati di identità. - Se collegato a un cluster di gruppo, Esplora cataloghi non filtra in base agli asset accessibili solo al gruppo.
- I responsabili dei gruppi che non sono membri del gruppo non possono creare, modificare o eliminare cluster di gruppo. Solo gli amministratori dell'area di lavoro e i membri del gruppo possono farlo.
- Se un gruppo viene rinominato, è necessario aggiornare manualmente tutti i criteri di calcolo che fanno riferimento al nome del gruppo.
- I cluster di gruppo non sono supportati per le aree di lavoro con ACL disabilitati (isWorkspaceAclsEnabled == false) a causa della mancanza intrinseca di controlli di sicurezza e accesso ai dati quando gli ACL dell'area di lavoro sono disabilitati.
- Il
%runcomando e altre azioni eseguite nel contesto del notebook usano sempre le autorizzazioni dell'utente anziché le autorizzazioni del gruppo. Ciò è dovuto al fatto che queste azioni vengono gestite dall'ambiente notebook, non dall'ambiente del cluster. I comandi alternativi,dbutils.notebook.run()ad esempio, vengono eseguiti nel cluster e quindi usano le autorizzazioni del gruppo. - La
is_member(<group>)funzione restituiscefalsequando viene richiamata in un cluster di gruppo perché il gruppo non è membro di se stesso. Per controllare correttamente l'appartenenza tra cluster di gruppo e altre modalità di accesso, usareis_member(<group>) OR current_user() == <group>. - La creazione e l'accesso agli endpoint di gestione del modello non sono supportati.
- La creazione e l'accesso agli endpoint o agli indici di ricerca di intelligenza artificiale non sono supportati.
- L'eliminazione di file e cartelle non è supportata nei cluster di gruppo.
- L'interfaccia utente di caricamento file non supporta i cluster di gruppo.