Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa pagina illustra in che modo Azure Databricks usa Lakeguard per applicare l'isolamento degli utenti negli ambienti di calcolo condivisi e il controllo di accesso con granularità fine in calcolo dedicato.
Che cos'è Lakeguard?
Lakeguard è un set di tecnologie in Databricks che applicano l'isolamento del codice e il filtro dei dati in modo che più utenti possano condividere la stessa risorsa di calcolo in modo sicuro e conveniente e accedere ai dati con controlli di accesso con granularità fine sul posto sul calcolo che offre l'accesso con privilegi ai computer.
Come funziona Lakeguard?
Negli ambienti di calcolo condivisi, ad esempio calcolo classico standard, calcolo serverless e sql warehouse, Lakeguard isola il codice utente dal motore Spark e da altri utenti. Questa progettazione consente a molti utenti di condividere le stesse risorse di calcolo mantenendo limiti rigorosi tra utenti, driver Spark ed executor.
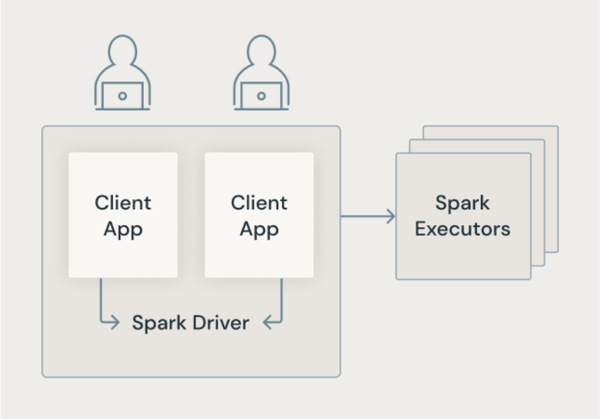
Architettura spark classica
L'immagine seguente mostra come nell'architettura Spark tradizionale, le applicazioni utente condividono una JVM con accesso con privilegi al computer sottostante.
Architettura di Lakeguard
Lakeguard isola tutto il codice utente usando contenitori sicuri. Ciò consente l'esecuzione di più carichi di lavoro nella stessa risorsa di calcolo mantenendo al tempo stesso un isolamento rigoroso tra gli utenti.
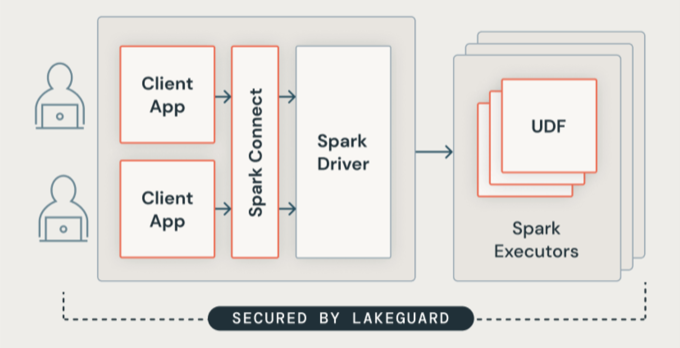
Isolamento del client Spark
Lakeguard isola le applicazioni client dal driver Spark e l'una dall'altra usando due componenti chiave:
Spark Connect: Lakeguard usa Spark Connect (introdotto con Apache Spark 3.4) per separare le applicazioni client dal driver. Le applicazioni client e i driver non condividono più la stessa JVM o classpath. Questa separazione impedisce l'accesso non autorizzato ai dati. Questa progettazione impedisce inoltre agli utenti di accedere ai dati risultanti dall'overfetching quando le query includono filtri a livello di riga o di colonna.
Annotazioni
Spark Connect rinvia l'analisi e la risoluzione dei nomi al tempo di esecuzione, che può modificare il comportamento del codice. Vedi Confronta Spark Connect con Spark Classic.
Sandboxing dei contenitori: ogni applicazione client viene eseguita nel proprio ambiente contenitore isolato. Ciò impedisce al codice utente di accedere ai dati di altri utenti o al computer sottostante. Il sandboxing usa tecniche di isolamento basate su contenitori per creare limiti sicuri tra gli utenti.
Isolamento della funzione definita dall'utente
Per impostazione predefinita, gli executor Spark non isolano le funzioni definite dall'utente. Tale mancanza di isolamento può consentire alle funzioni definite dall'utente di scrivere file o accedere al computer sottostante.
Lakeguard isola il codice definito dall'utente, incluse le funzioni definite dall'utente, in executor Spark da:
- Sandbox dell'ambiente di esecuzione in executor Spark.
- Isolare il traffico di rete in uscita dalle funzioni definite dall'utente per impedire l'accesso esterno non autorizzato.
- Replica dell'ambiente client nella sandbox UDF in modo che gli utenti possano accedere alle librerie necessarie.
Questo isolamento si applica alle funzioni definite dall'utente nel calcolo standard e alle funzioni definite dall'utente Python nelle risorse di calcolo serverless e nei warehouse SQL.