Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il controllo di accesso con granularità fine consente di limitare l'accesso a dati specifici usando visualizzazioni, filtri di riga e maschere di colonna. Questa pagina illustra come viene usato il calcolo serverless per applicare controlli di accesso con granularità fine alle risorse di calcolo dedicate.
Annotazioni
Il calcolo dedicato è un calcolo di tutti gli scopi o processi configurato con la modalità di accesso dedicato (in precedenza modalità di accesso utente singolo). Vedere Modalità di accesso usata.
Requisiti
Per utilizzare il calcolo dedicato per interrogare una vista o una tabella con controlli di accesso a grana fine:
- La risorsa di calcolo dedicata deve trovarsi in Databricks Runtime 15.4 LTS o versione successiva.
- L'area di lavoro deve essere abilitata per il calcolo serverless.
Se la risorsa di calcolo dedicata e l'area di lavoro soddisfano questi requisiti, il filtro dei dati viene eseguito automaticamente.
Funzionamento del filtro dei dati nell'ambiente di calcolo dedicato
Ogni volta che una query accede a un oggetto di database con controlli di accesso con granularità fine, la risorsa di calcolo dedicata passa la query al calcolo serverless dell'area di lavoro per eseguire il filtro dei dati. I dati filtrati vengono quindi trasferiti tra il calcolo serverless e dedicato usando i file temporanei nell'archiviazione cloud interna dell'area di lavoro.
Azure Databricks trasferisce i dati filtrati usando Cloud Fetch, una funzionalità che scrive i set di risultati temporanei nell'archiviazione interna dell'area di lavoro ( radice DBFS dell'area di lavoro). Azure Databricks raccoglie automaticamente questi file, contrassegnandoli per l'eliminazione dopo 24 ore e eliminandoli definitivamente dopo altre 24 ore.
Questa funzionalità si applica agli oggetti di database seguenti:
- viste dinamiche
- Tabelle con filtri di riga o maschere di colonna
-
Viste compilate su tabelle su cui l'utente non ha il
SELECTprivilegio - viste materializzate
- tabelle di streaming
Nel diagramma seguente, un utente ha il SELECT privilegio su table_1, view_2, e table_w_rls, a cui sono stati applicati filtri di riga. L'utente non dispone del privilegio SELECT su table_2, che è referenziato da view_2.

La query su table_1 viene gestita interamente dalla risorsa di calcolo dedicata, perché non è necessario alcun filtro. Le query su view_2 e table_w_rls richiedono il filtro dei dati per restituire i dati a cui l'utente ha accesso. Queste query vengono gestite dalla funzionalità di filtro dei dati nell'ambiente di calcolo serverless.
Supporto per le operazioni di scrittura
In Databricks Runtime 16.3 e versioni successive è possibile scrivere nelle tabelle con filtri di riga o maschere di colonna applicate usando queste opzioni:
- Il comando SQL MERGE INTO, che puoi utilizzare per ottenere le funzionalità
INSERT,UPDATEeDELETE. - Operazione di unione delta.
- L'
DataFrame.write.mode("append")API.
Per ottenere INSERT, UPDATE e DELETE le funzionalità, è possibile usare una tabella di staging e l'istruzione MERGE INTO con le clausole WHEN MATCHED e WHEN NOT MATCHED.
Di seguito è riportato un esempio di UPDATE che utilizza MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET
t.column1 = s.column1,
t.column2 = s.column2;
Di seguito è riportato un esempio di INSERT che utilizza MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN NOT MATCHED THEN
INSERT (id, column1, column2) VALUES (s.id, s.column1, s.column2);
Di seguito è riportato un esempio di delete usando MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s ON t.id = s.id
WHEN MATCHED AND s.some_column = TRUE THEN DELETE;
Supporto per DDL, SHOW, DESCRIBE e altri comandi
In Databricks Runtime 17.1 e versioni successive è possibile usare i comandi seguenti in combinazione con oggetti con controllo di accesso con granularità fine in calcolo dedicato:
- Istruzioni DDL
- Istruzioni SHOW
- Istruzioni DESCRIBE
- OPTIMIZE
- DESCRIBE HISTORY
- FSCK REPAIR TABLE (Databricks Runtime 17.2 e versioni successive)
Se necessario, questi comandi vengono eseguiti automaticamente nell'ambiente di calcolo serverless.
Alcuni comandi non sono supportati, tra cui VACCUM, RESTOREe REORG TABLE.
Costi di calcolo serverless
I clienti vengono addebitati per le risorse di calcolo serverless che eseguono operazioni di filtro dei dati. Per informazioni sui prezzi, vedere Livelli di piattaforma e componenti aggiuntivi.
Gli utenti con accesso possono eseguire query sulla system.billing.usage tabella per verificare quanto sono stati addebitati. Ad esempio, la query seguente suddivide i costi di calcolo per utente:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Visualizzare le prestazioni delle query quando viene attivato il filtro dei dati
L'interfaccia utente di Spark per il calcolo dedicato visualizza le metriche che è possibile usare per comprendere le prestazioni delle query. Per ogni query eseguita nella risorsa di calcolo, nella scheda SQL/Dataframe viene visualizzata la rappresentazione del grafo della query. Se una query è stata coinvolta nel filtro dei dati, l'interfaccia utente visualizza un nodo dell'operatore RemoteSparkConnectScan nella parte inferiore del grafico. Tale nodo visualizza le metriche che è possibile usare per analizzare le prestazioni delle query. Vedere Visualizzare le informazioni di calcolo nell'interfaccia utente di Spark.
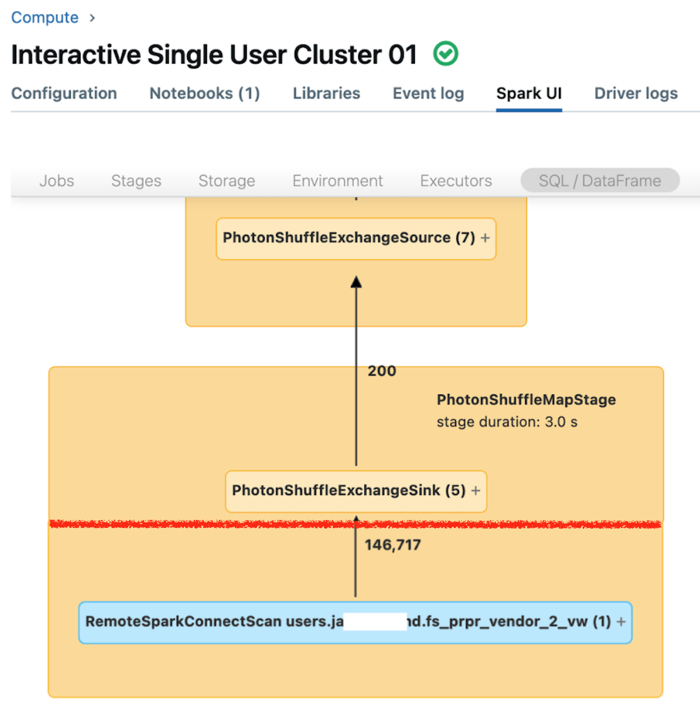
Espandere il nodo dell'operatore RemoteSparkConnectScan per visualizzare le metriche che rispondono a queste domande:
- Quanto tempo è stato necessario per il filtro dei dati? Visualizzare il "tempo totale di esecuzione remota".
- Quante righe sono rimaste dopo il filtro dei dati? Vedi "output righe".
- Quanti dati (in byte) sono stati restituiti dopo il filtro dei dati? Visualizzare le "dimensioni di uscita delle righe".
- Quanti file di dati sono stati esclusi dalla partizione e non hanno dovuto essere letti dalla memoria di archiviazione? Visualizzare "File eliminati" e "Dimensioni dei file eliminati".
- Quanti file di dati non potevano essere eliminati e dovevano essere letti dalla risorsa di archiviazione? Visualizzare "File letti" e "Dimensioni dei file letti".
- Dei file da leggere, quanti erano già presenti nella cache? Visualizzare "Dimensioni dei cache hit" e "Dimensioni dei mancati nella cache".
Limiti
Nelle tabelle di streaming sono supportate solo le letture batch. Le tabelle con filtri di riga o maschere di colonna non supportano processi di streaming sui calcoli dedicati.
Impossibile modificare il catalogo predefinito (
spark.sql.catalog.spark_catalog).spark.catalog.listColumns()non è supportato. È invece possibile usareSHOW COLUMNS INper elencare i nomi delle colonne,SHOW PARTITIONSelencare le colonne di partizione oDESCRIBE TABLE [EXTENDED [AS JSON]]ottenere una descrizione dettagliata della tabella.In Databricks Runtime 16.2 e versioni successive non è disponibile alcun supporto per le operazioni di scrittura o aggiornamento delle tabelle nelle tabelle con filtri di riga o maschere di colonna applicati.
In particolare, le operazioni DML, ad esempio
INSERT,DELETEUPDATEREFRESH TABLEeMERGE, non sono supportate. È possibile leggere (SELECT) solo da queste tabelle.In Databricks Runtime 16.3 e versioni successive, scrivere operazioni di tabella come
INSERT,DELETEeUPDATEnon sono supportate, ma possono essere eseguite usandoMERGE, supportato.Quando si utilizzano
DeltaTable.forName()oDeltaTable.forPath()su un ambiente di calcolo dedicato con tabelle abilitate al FGAC, sono supportate solo le operazionimerge()etoDF(). Per altre operazioni DeltaTable, usare invece i comandi SQL corrispondenti. Ad esempio, anzichéhistory(), usareDESCRIBE HISTORYe invece diclone(), usareSHALLOW CLONEoDEEP CLONE.In Databricks Runtime 16.2 e versioni successive, i self-join vengono bloccati per impostazione predefinita quando viene chiamato il filtro dei dati perché queste query potrebbero restituire snapshot diversi della stessa tabella remota. È tuttavia possibile abilitare queste query impostando
spark.databricks.remoteFiltering.blockSelfJoinssufalsenel calcolo in cui si eseguono questi comandi.In Databricks Runtime 16.3 e versioni successive gli snapshot vengono sincronizzati automaticamente tra risorse di calcolo dedicate e serverless. A causa di questa sincronizzazione, le query self-join che usano la funzionalità di filtro dei dati restituiscono snapshot identici e sono abilitate per impostazione predefinita. Le eccezioni sono le viste materializzate e tutte le viste, le viste materializzate e le tabelle di streaming condivise tramite Delta Sharing. Per questi oggetti, i self-join vengono bloccati per impostazione predefinita, ma è possibile abilitare queste query impostando
spark.databricks.remoteFiltering.blockSelfJoinssu false nel calcolo in cui si eseguono questi comandi.Se si abilitano le query self-join per le viste materializzate e qualsiasi vista o tabella di streaming, è necessario assicurarsi che non siano presenti scritture simultanee sugli oggetti uniti.
- Nessun supporto nelle immagini Docker.
- Nessun supporto quando si usa Databricks Container Services.
- È necessario aprire le porte 8443 e 8444 per abilitare il controllo di accesso con granularità fine in un ambiente di calcolo dedicato. Vedere Implementare Azure Databricks nella rete virtuale di Azure (VNet Injection).