Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa pagina descrive come usare Databricks Data Classification in Unity Catalog per classificare e contrassegnare automaticamente i dati sensibili nel catalogo.
I cataloghi di dati possono avere una grande quantità di dati, spesso contenenti dati sensibili noti e sconosciuti. È fondamentale che i team di dati comprendano il tipo di dati sensibili presenti in ogni tabella in modo che possano gestire e democratizzare l'accesso a questi dati.
Per risolvere questo problema, Databricks Data Classification usa un agente di intelligenza artificiale per classificare e contrassegnare automaticamente le tabelle nel catalogo. In questo modo è possibile individuare dati sensibili e applicare controlli di governance sui risultati, usando strumenti come il controllo degli accessi in base all'attributo di Unity Catalog. Per un elenco dei tag supportati, vedere Tag di classificazione supportati.
Usando questa funzionalità, è possibile:
- Classificare i dati: il motore usa un sistema di intelligenza artificiale agente per classificare e contrassegnare automaticamente le tabelle in Unity Catalog.
- Ottimizzare i costi tramite l'analisi intelligente: il sistema determina in modo intelligente quando analizzare i dati sfruttando Unity Catalog e il motore di business intelligence dei dati. Ciò significa che l'analisi è incrementale e ottimizzata per garantire che tutti i nuovi dati vengano classificati senza configurazione manuale.
- Esaminare e proteggere i dati sensibili: i risultati visualizzati consentono di visualizzare i risultati della classificazione e proteggere i dati sensibili contrassegnando e creando criteri di controllo di accesso per ogni classe.
Importante
Databricks Data Classification usa l'archiviazione predefinita per archiviare i risultati della classificazione. Non viene addebitato alcun costo per lo spazio di archiviazione.
Databricks Data Classification usa un modello di linguaggio di grandi dimensioni (LLM) per facilitare la classificazione.
Requisiti
Annotazioni
La classificazione dei dati è una funzionalità di anteprima a livello di area di lavoro e può essere gestita solo da un'area di lavoro o da un amministratore dell'account. Per istruzioni, vedere Manage Azure Databricks previews.
- L'area di lavoro deve disporre di risorse di calcolo serverless (abilitate per impostazione predefinita nelle aree di lavoro con il catalogo Unity).
- Per abilitare la classificazione dei dati, è necessario possedere il catalogo o avere i privilegi
USE CATALOGeMANAGEsu di esso. - Per abilitare l'assegnazione automatica di tag per un catalogo, è necessario avere
USE CATALOGsul catalogo,APPLY TAGsul catalogo eASSIGNsul tag applicato. - Per visualizzare i risultati della classificazione nell'interfaccia utente, è necessario avere
USE CATALOGeMANAGE(SELECT+USE SCHEMA) nel catalogo. Per visualizzare i valori di esempio associati ai rilevamenti, è necessario avereSELECTnella tabella Di sistema dei risultati.
Annotazioni
Per impostazione predefinita, solo gli amministratori dell'account dispongono delle autorizzazioni di MANAGE e ASSIGN per i tag regolati dal sistema di classificazione dei dati. Gli amministratori dell'account possono concedere MANAGE e ASSIGN per singoli tag regolamentati ad altri utenti, principali del servizio o gruppi. Vedere Gestire le autorizzazioni per i tag regolamentati.
Usare la classificazione dei dati
È possibile abilitare la classificazione dei dati per più cataloghi contemporaneamente dalla pagina dei risultati o configurare singoli cataloghi con un controllo a livello di schema più granulare.
Abilitare più cataloghi
- Nella pagina Risultati classificazione dati fare clic su Configura.
- Selezionare i cataloghi da abilitare oppure selezionare tutti i cataloghi disponibili nell'area di lavoro.
- Fare clic su Abilita.
L'abilitazione di tutti i cataloghi disponibili non abilita automaticamente i cataloghi futuri. Per classificare un nuovo catalogo, tornare alla finestra di dialogo Configura e abilitarla.
Abilitare un singolo catalogo con la selezione dello schema
Per scegliere schemi specifici all'interno di un catalogo:
Passare al catalogo e fare clic sulla scheda Dettagli .
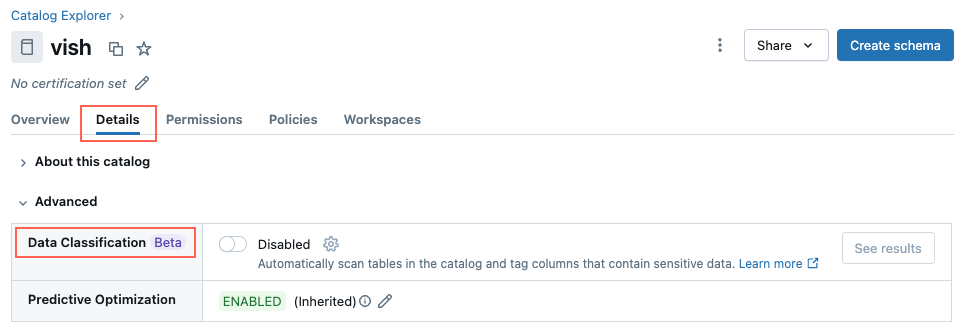
Accanto a Classificazione dati fare clic sul pulsante Abilita .
Verrà visualizzata la finestra di dialogo Classificazione dati . Per impostazione predefinita, sono inclusi tutti gli schemi. Per includere solo alcuni schemi, selezionarli nel menu a discesa Schemi da includere . È anche possibile selezionare un criterio di utilizzo
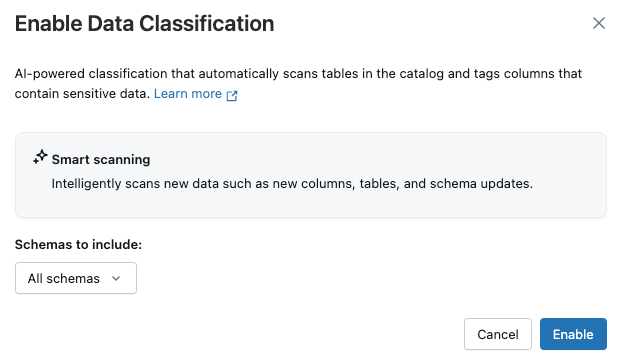
Fare clic su Salva.
Verrà creato un processo in background che analizza in modo incrementale tutte le tabelle nel catalogo o negli schemi selezionati.
Il motore di classificazione si basa sull'analisi intelligente per determinare quando analizzare una tabella. Le nuove tabelle e le colonne in un catalogo vengono in genere analizzate entro 24 ore dalla creazione.
Visualizzare i risultati della classificazione
Per visualizzare i risultati della classificazione, fare clic su Visualizza risultati accanto all'impostazione Classificazione dati .
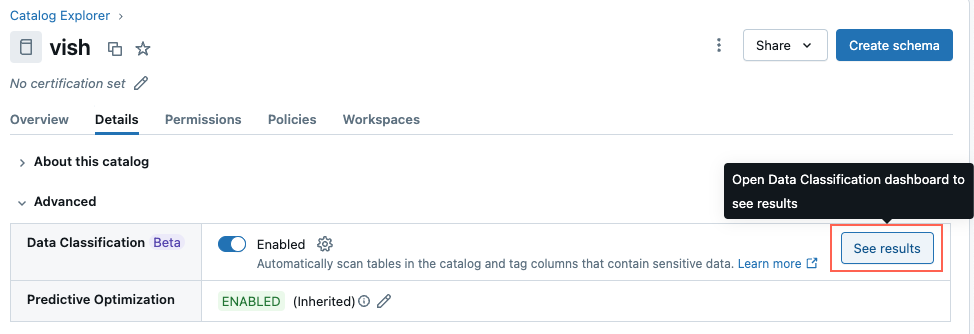
Verrà aperta l'interfaccia utente di classificazione dei dati per il catalogo. Per visualizzare i risultati della classificazione, è necessario un sql warehouse serverless.
È anche possibile visualizzare i risultati aggregati in tutti i cataloghi classificati nel metastore usando il selettore del catalogo in alto a sinistra. Scegliere Tutti i cataloghi dal menu a discesa.
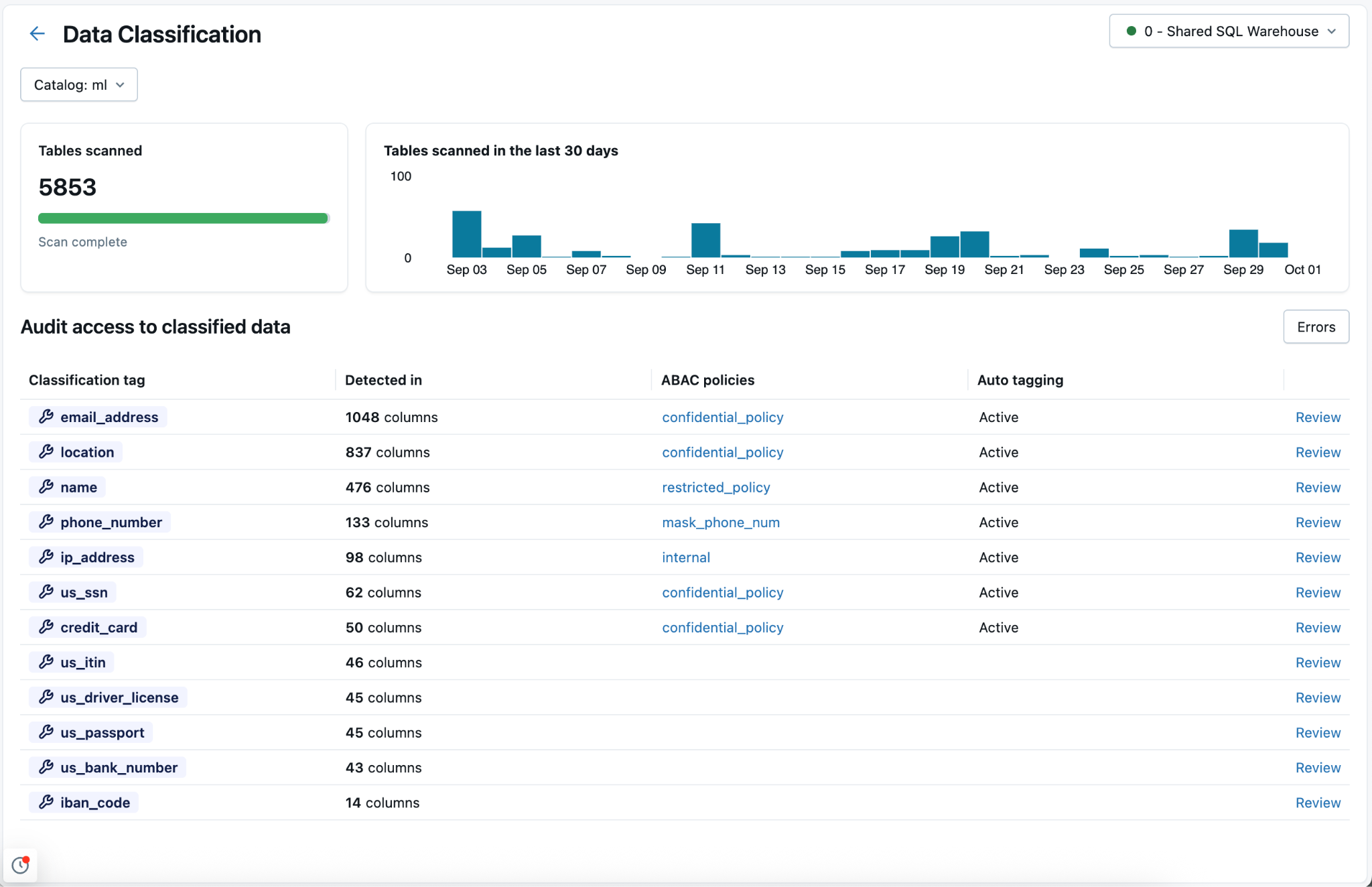
Per ogni tipo di classificazione, la tabella mostra:
- Colonne rilevate: numero di colonne in cui è stata rilevata la classificazione.
- Assegnazione automatica di tag: stato di assegnazione di tag per tale classificazione: attivo o inattivo. Nella visualizzazione metastore lo stato Parzialmente attivo indica che l'assegnazione di tag è abilitata in alcuni ma non in tutti i cataloghi.
- Accesso utente (ultimo 7d): numero di utenti distinti che hanno acceduto a dati non mascherati o mascherati di tale classificazione negli ultimi 7 giorni. Usare questa opzione per valutare l'esposizione dei dati sensibili all'interno dell'organizzazione.
Esaminare i rilevamenti
Per esaminare i risultati per un tipo di classificazione specifico, fare clic su Rivedi nella colonna più a destra. Viene visualizzato un pannello con due schede:
- Colonne rilevate: visualizza le colonne in cui il tag di classificazione è stato rilevato con attendibilità elevata, ordinato per primo dal rilevamento più recente. Include anche un grafico Rilevamenti nel tempo e un elenco di colonne rilevate con valori di esempio. Fare clic su una barra qualsiasi nel grafico per visualizzare i rilevamenti specifici per tale data. I valori di esempio vengono visualizzati solo se si dispone delle autorizzazioni necessarie per visualizzare i risultati della classificazione.
- Accesso utente: elenca tutti gli utenti che hanno eseguito l'accesso alle colonne con questo tag di classificazione, visualizzando la posta elettronica e il nome utente insieme al fatto che abbiano accesso mascherato o non mascherato. Mostra anche tutti i criteri di controllo degli accessi in base all'attributo assegnati a questo tag di classificazione. Quando si visualizzano i risultati per un singolo catalogo, è possibile creare un nuovo criterio di controllo degli accessi basato sugli attributi direttamente dal pannello.
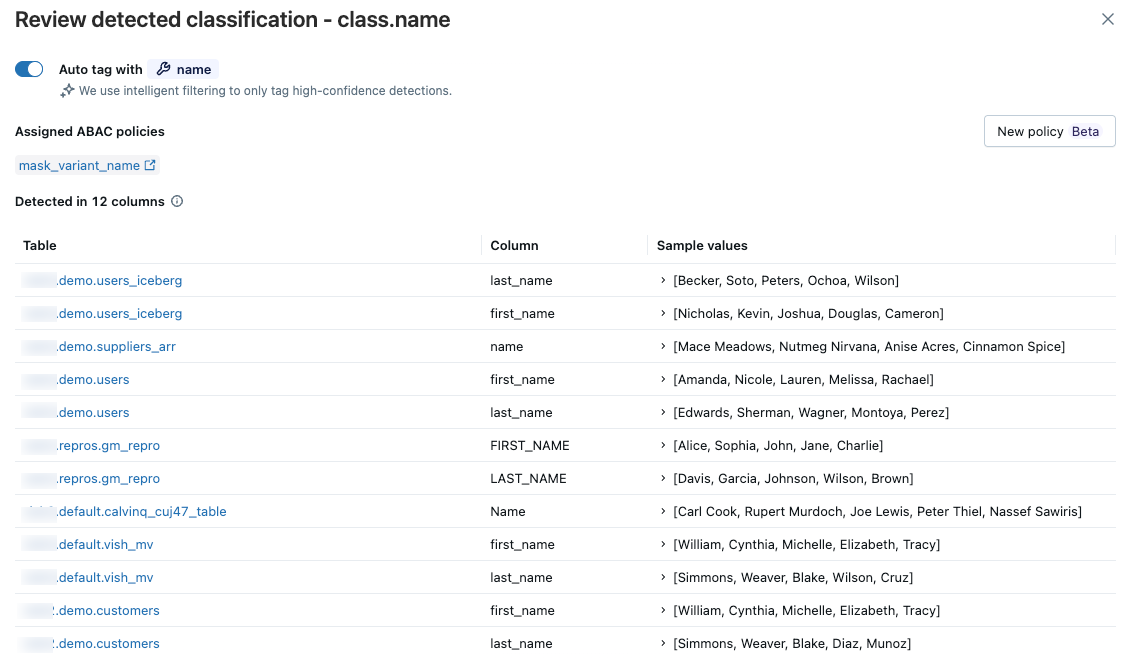
Se le colonne rilevate non sono corrette, è possibile fare clic sull'icona Escludi a destra della voce. Vedere Escludere i rilevamenti.
Abilitare l'assegnazione automatica di tag
Se le colonne identificate corrispondono alle aspettative, è possibile abilitare l'assegnazione automatica di tag per il tag di classificazione. Quando l'assegnazione automatica di tag è abilitata, vengono contrassegnati tutti i rilevamenti esistenti e futuri di questa classificazione.
È possibile configurare l'assegnazione automatica di tag a due livelli:
-
Livello metastore: Abilitare o disabilitare tutti i cataloghi contemporaneamente. È necessario essere un amministratore del metastore e avere
ASSIGNsul tag da applicare. -
Livello catalogo: abilitare o disabilitare solo per il catalogo corrente. Le impostazioni a livello di catalogo hanno la precedenza sull'impostazione a livello di metastore. È necessario avere
USE CATALOGeAPPLY TAGnel catalogo eASSIGNsul tag applicato.
A livello di catalogo, l'assegnazione automatica di tag ha tre stati:
- Valore predefinito (ereditato): il catalogo eredita l'impostazione di assegnazione di tag dal livello del metastore.
- Attivo: l'assegnazione di tag è abilitata in modo esplicito per questo catalogo, indipendentemente dall'impostazione a livello di metastore.
- Inattivo: l'assegnazione di tag è disabilitata in modo esplicito per questo catalogo, indipendentemente dall'impostazione a livello di metastore.
Quando si disabilita l'assegnazione di tag, non vengono applicati tag futuri, ma i tag esistenti non vengono rimossi.
Annotazioni
Quando si abilita l'assegnazione automatica di tag, i tag non vengono riempiti immediatamente. Verranno popolati nella scansione successiva, che diventerà effettiva entro 24 ore. Le classificazioni successive verranno contrassegnate immediatamente.
Escludere i rilevamenti
Importante
Le esclusioni di rilevamento e il loro uso per migliorare l'accuratezza della classificazione futura sono disponibili nella versione beta.
Nel pannello di revisione è possibile escludere i rilevamenti di singole colonne. Esclusione di un rilevamento:
- Rimuove qualsiasi tag di classificazione esistente da tale colonna.
- Impedisce alle analisi future di riapplicare il tag a tale colonna.
- Fornisce commenti e suggerimenti che migliorano l'accuratezza dei risultati della classificazione futuri.
Per escludere un rilevamento, fare clic sull'icona Escludi per la colonna corrispondente nel pannello di revisione. Per includere nuovamente il rilevamento, fare di nuovo clic sull'icona.
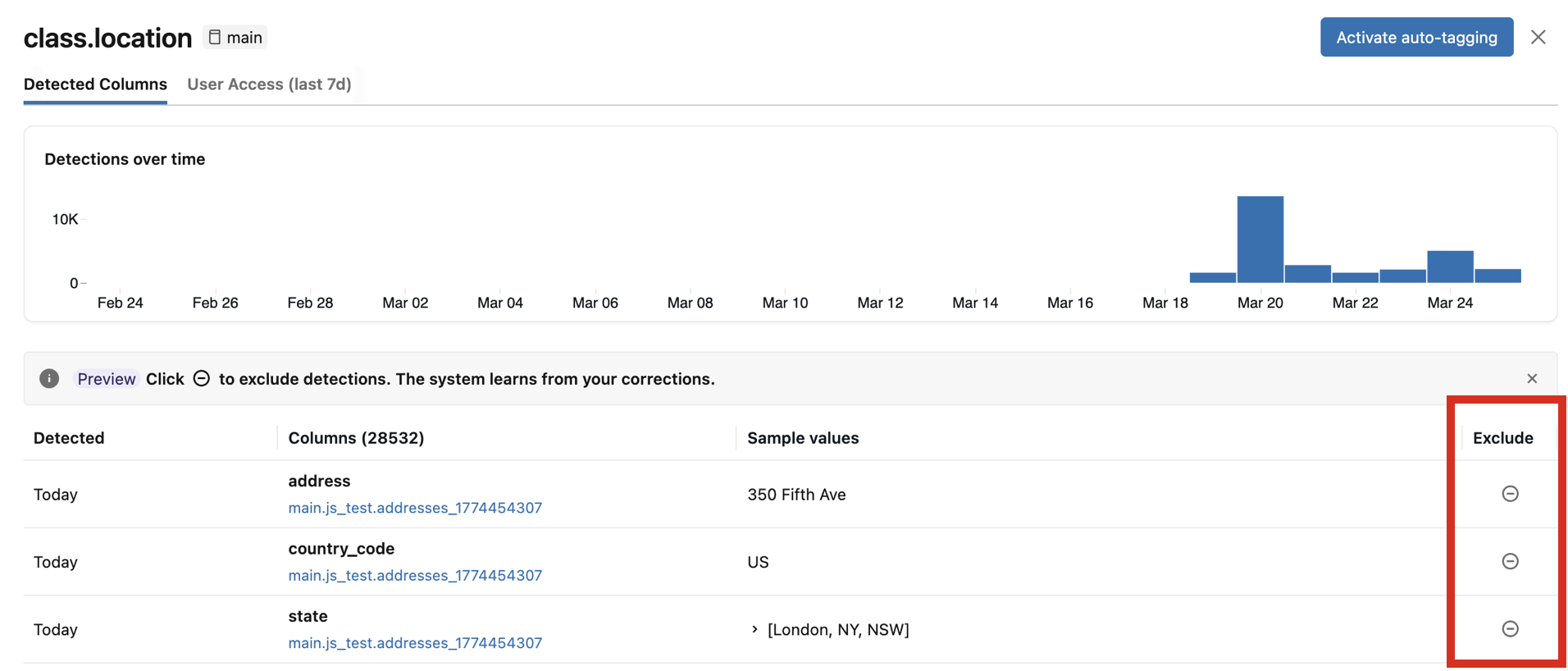
Tabella di sistema dei risultati
La classificazione dei dati crea una tabella di sistema denominata system.data_classification.results per archiviare i risultati che per impostazione predefinita sono accessibili solo all'amministratore dell'account. L'amministratore dell'account può condividere questa tabella. La tabella è accessibile solo quando si usa il calcolo serverless. Per informazioni dettagliate su questa tabella, vedere Informazioni di riferimento sulla tabella di sistema di classificazione dei dati.
Importante
La tabella system.data_classification.results dei risultati contiene tutti i risultati della classificazione nell'intero metastore e include i valori di esempio delle tabelle in ogni catalogo. È consigliabile condividere questa tabella solo con gli utenti con privilegi per visualizzare i risultati della classificazione a livello di metastore, inclusi i valori di esempio.
Gli utenti con SELECT accesso a questa tabella possono anche visualizzare i valori di esempio associati ai rilevamenti nella pagina Risultati classificazione dati.
Configurare i controlli di governance in base ai risultati della classificazione dei dati
Mascherare i dati sensibili usando un criterio di controllo degli accessi basato sugli attributi.
Databricks consiglia di usare il controllo degli accessi in base all'attributo di Unity Catalog per creare controlli di governance in base ai risultati della classificazione dei dati.
Per creare un criterio dalla pagina Risultati classificazione dati, fare clic su Verifica per un tag di classificazione, aprire la scheda Accesso utenti e fare clic su Nuovo criterio. Il modulo dei criteri viene precompilato per mascherare le colonne con il tag di classificazione da esaminare. Per mascherare i dati, specificare qualsiasi funzione di maschera registrata nel catalogo unity e fare clic su Salva.
È anche possibile creare criteri che coprono più tag di classificazione, modificando Quando la colonnasoddisfa la condizione e fornendo più tag.
Ad esempio, per creare un criterio denominato "Riservato" che maschera qualsiasi nome, indirizzo di posta elettronica o numero di telefono, impostare la condizione soddisfa su has_tag("class.name") OR has_tag("class.email_address") OR has_tag("class.phone_number").
Individuazione ed eliminazione dei dati secondo il GDPR
Questo notebook di esempio illustra come usare la classificazione dei dati per facilitare l'individuazione e l'eliminazione dei dati per la conformità al GDPR.
Individuazione ed eliminazione dei dati ai sensi del GDPR utilizzando un notebook per la classificazione dei dati
Come gestire tag non corretti
Se una classificazione non è corretta, escludere il rilevamento dal pannello di revisione. L'esclusione di un rilevamento rimuove il tag, impedisce la riapplicazione e migliora l'accuratezza delle analisi future. Vedere Escludere i rilevamenti.
Errori di scansione
Se si verificano errori durante l'analisi, viene visualizzato un pulsante Errori in alto a destra nella tabella dei risultati.
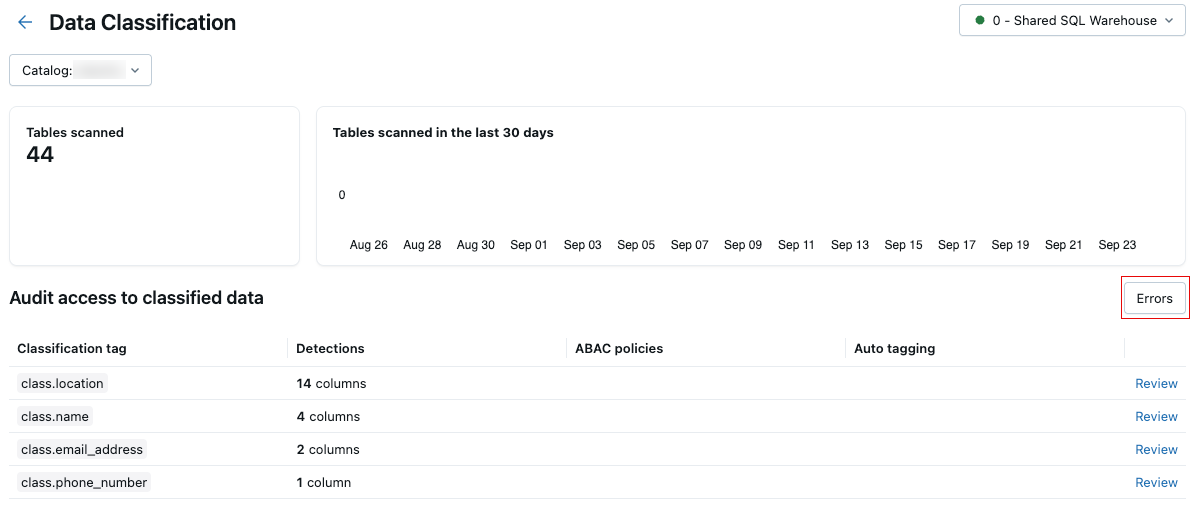
Fare clic sul pulsante per visualizzare le tabelle che non hanno superato l'analisi e i messaggi di errore associati.

Per impostazione predefinita, gli errori che si sono verificati per le singole tabelle vengono ignorati e ritentati il giorno successivo.
Visualizzare le spese di classificazione dei dati
Per informazioni sulla fatturazione della classificazione dei dati, vedere la pagina dei prezzi. È possibile visualizzare le spese correlate alla classificazione dei dati eseguendo una query o visualizzando il dashboard di utilizzo.
Annotazioni
L'analisi iniziale è più costosa rispetto alle analisi successive sullo stesso catalogo, poiché tali analisi sono incrementali e in genere comportano costi inferiori.
Visualizzare l'utilizzo dalla tabella di sistema system.billing.usage
È possibile eseguire query sulle spese di classificazione dei dati da system.billing.usage. I campi created_by e catalog_id possono essere usati facoltativamente per suddividere i costi:
-
created_by: Includere per visualizzare i costi per l'utente che ha attivato l'utilizzo. -
catalog_id: includere per visualizzare i costi in base al catalogo. L'ID catalogo viene visualizzato nellasystem.data_classification.resultstabella .
Query di esempio per gli ultimi 30 giorni:
SELECT
usage_date,
identity_metadata.created_by,
usage_metadata.catalog_id,
SUM(usage_quantity) AS dbus
FROM
system.billing.usage
WHERE
usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
created_by,
catalog_id
ORDER BY
usage_date DESC,
created_by;
Per calcolare il costo totale in dollari, connettersi con system.billing.list_prices. La query di esempio seguente usa un parametro :add_on_rate denominato come moltiplicatore per il prezzo di listino. Impostarlo su 1 per utilizzare direttamente il prezzo di listino o su un valore minore di 1 per riflettere uno sconto concordato (ad esempio, 0.9 per uno sconto del 10%).
Query di esempio per il costo totale del dollaro negli ultimi 30 giorni:
SELECT
u.usage_date,
SUM(u.usage_quantity * lp.pricing.effective_list.default) * :add_on_rate
AS `Data Classification Dollar Cost`
FROM system.billing.usage AS u
JOIN system.billing.list_prices AS lp
ON lp.sku_name = u.sku_name
WHERE
u.billing_origin_product = 'DATA_CLASSIFICATION'
AND u.usage_end_time >= lp.price_start_time
AND (lp.price_end_time IS NULL OR u.usage_end_time < lp.price_end_time)
AND u.usage_date >= DATE_ADD(CURRENT_DATE(), -30)
GROUP BY
u.usage_date
ORDER BY
u.usage_date DESC;
Visualizzare l'utilizzo dal dashboard di utilizzo
Se hai già un dashboard di utilizzo configurato nell'area di lavoro, puoi usarlo per filtrare l'utilizzo selezionando il progetto di origine della fatturazione etichettato "Classificazione Dati". Se non è configurato un dashboard di utilizzo, è possibile importarne uno e applicare lo stesso filtro. Per informazioni dettagliate, vedere Dashboard di utilizzo.
Tag di classificazione supportati
Per un elenco completo dei tag supportati organizzati da tag globali, tag regionali e framework di conformità (PII, GDPR, HIPAA, DPDPA), vedere Tag di classificazione supportati.
Limitazioni
- Le visualizzazioni e le visualizzazioni delle metriche non sono supportate. Se la vista si basa su tabelle esistenti, Databricks consiglia di classificare le tabelle sottostanti per verificare se contengono dati sensibili.