Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa pagina descrive come visualizzare la derivazione dei dati usando Esplora cataloghi e le tabelle di sistema di derivazione dei dati.
Panoramica della derivazione dei dati
Unity Catalog acquisisce la derivazione dei dati di runtime tra query eseguite in Azure Databricks. La lineage è supportata per tutte le lingue ed è registrata fino al livello di colonna. I dati di derivazione includono notebook, processi di lavoro e dashboard inerenti alla query. La derivazione può essere visualizzata in Esplora cataloghi quasi in tempo reale e recuperata a livello di codice usando le tabelle di sistema di derivazione.
La provenienza può includere anche asset esterni e flussi di lavoro eseguiti all'esterno di Azure Databricks. Questa funzionalità di metadati di derivazione esterna è disponibile in anteprima pubblica. Vedi Porta la tua propria lineage di dati.
La derivazione viene aggregata in tutte le aree di lavoro collegate a un metastore di Unity Catalog. Ciò significa che la derivazione acquisita in un'area di lavoro è visibile in qualsiasi altra area di lavoro che condivide tale metastore. In particolare, le tabelle e altri oggetti dati registrati nel metastore sono visibili agli utenti che hanno almeno BROWSE autorizzazioni per tali oggetti, in tutte le aree di lavoro collegate al metastore. Tuttavia, informazioni dettagliate sugli oggetti a livello di area di lavoro, ad esempio notebook e dashboard in altre aree di lavoro, sono mascherate (vedere Limitazioni della derivazione e autorizzazioni di derivazione).
I dati di derivazione vengono conservati a tempo indeterminato. Tutti i dati di derivazione acquisiti dopo il 1° settembre 2024 sono disponibili. Per i metastore creati dopo tale data, l'Esplora Cataloghi include un'opzione Tutti i tempi nell'elenco a discesa dell'intervallo di tempo della linea temporale. Per i metastore meno recenti, l'elenco a discesa include un'opzione Tutto disponibile che inizia dal 1° settembre 2024. La selezione predefinita è 1 anno.
La seguente immagine seguente è un grafico di derivazione di esempio.
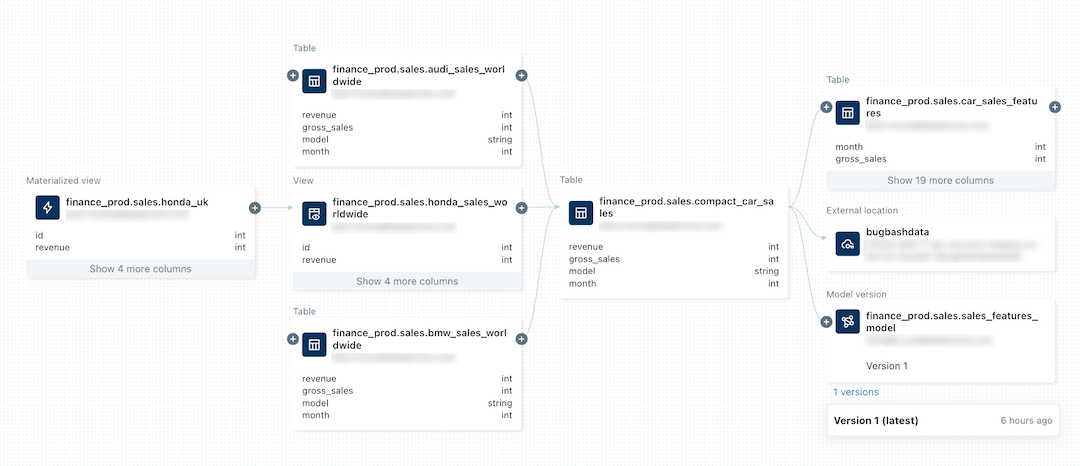
Per una demo di visualizzazione della derivazione dei dati, vedere Unity Catalog - Derivazione dei dati.
Per informazioni sul rilevamento della derivazione di un modello di Machine Learning, vedere Tenere traccia della derivazione dei dati di un modello in Unity Catalog.
Requisiti
Per acquisire la derivazione dei dati usando Unity Catalog:
- Le tabelle devono essere registrate in un metastore del catalogo Unity.
- Gli asset esterni (quelli non registrati nel metastore del Catalogo Unity) devono essere aggiunti come oggetti di metadati esterni nel Catalogo Unity, configurati per avere relazioni con altri oggetti sicurizzabili registrati nel metastore del Catalogo Unity. Vedi Porta la tua propria lineage di dati.
- Le query devono usare il dataframe Spark (ad esempio, funzioni SPARK SQL che restituiscono un dataframe) o interfacce SQL di Databricks, ad esempio notebook o editor di query SQL.
Per visualizzare la derivazione dei dati:
- È necessario disporre almeno del privilegio
BROWSEsul catalogo padre della tabella o della vista. Il catalogo principale deve essere anch'esso accessibile dall'area di lavoro. Vedere associazione del catalogo dell'area di lavoro. - Per notebook, processi o dashboard, è necessario disporre delle autorizzazioni per questi oggetti, come definito dalle impostazioni di controllo di accesso nell'area di lavoro. Per informazioni dettagliate, vedere Autorizzazioni di derivazione.
- Per una pipeline abilitata per Unity Catalog, è necessario disporre dell'autorizzazione CAN VIEW per la pipeline.
Requisiti di calcolo:
- Il monitoraggio della tracciabilità dello streaming tra tabelle Delta richiede Databricks Runtime 11.3 LTS o una versione successiva.
- Il rilevamento della derivazione delle colonne per i carichi di lavoro delle pipeline dichiarative di Lakeflow Spark richiede Databricks Runtime 13.3 LTS o versione successiva.
Requisiti di rete:
- Potrebbe essere necessario aggiornare le regole del firewall in uscita per consentire la connettività all'endpoint di Hub eventi nel piano di controllo Azure Databricks. Questo vale in genere se l'area di lavoro Azure Databricks è distribuita nella propria VNet (nota anche come inserimento VNet). Per ottenere l'endpoint di Hub eventi per l'area di lavoro, vedere Metastore, archiviazione BLOB degli artefatti, archiviazione delle tabelle di sistema, archiviazione BLOB dei log e indirizzi IP degli endpoint di Hub eventi. Per informazioni sulla configurazione di route definite dall'utente per Azure Databricks, vedere Impostazioni di route definite dall'utente per Azure Databricks.
Visualizzare la derivazione dei dati con Esplora cataloghi
Per usare Esplora cataloghi per visualizzare la derivazione della tabella:
Nell'area di lavoro Azure Databricks fare clic su
 Catalog.
Catalog.Cerca o sfoglia la tua tabella.
Selezionare la scheda Derivazione . Viene visualizzato il pannello di derivazione e vengono visualizzate le tabelle correlate.
Per visualizzare un grafico interattivo della derivazione dei dati, fare clic su Visualizza grafico di derivazione.
Per impostazione predefinita, nel grafico viene visualizzato un livello. Fare clic sull'icona
 su un nodo per visualizzare altre connessioni, se disponibili.
su un nodo per visualizzare altre connessioni, se disponibili.Fare clic su una freccia che connette i nodi nel grafico di derivazione per aprire il pannello Connessione derivazione.
Il pannello connessione Lineage mostra i dettagli sulla connessione, incluse le tabelle di origine e di destinazione, i notebook e i processi.
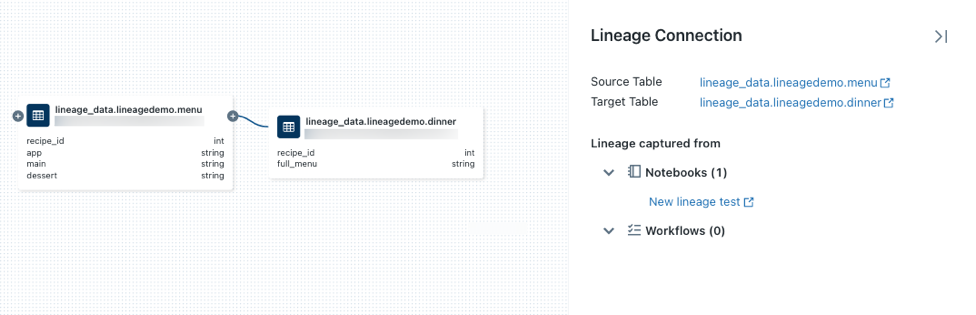
Per visualizzare un notebook associato a una tabella, selezionare il notebook nel pannello Connessione derivazione oppure chiudere il grafico di derivazione e fare clic su Notebook.
Per aprire il notebook in una nuova scheda, fare clic sul nome del notebook.
Per visualizzare la derivazione a livello di colonna, fare clic su una colonna nel grafico per visualizzare i collegamenti alle colonne correlate. Ad esempio, facendo clic sulla
full_menucolonna in questo grafico di esempio vengono visualizzate le colonne upstream da cui è stata derivata la colonna: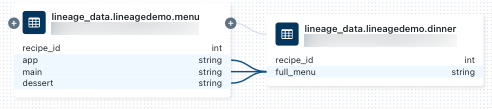
Visualizzare la tracciabilità dell'attività
Per visualizzare la derivazione del processo, passare alla scheda Derivazione di una tabella, selezionare Processi e selezionare Downstream. Il nome del processo viene visualizzato sotto Nome processo come utente della tabella.
Visualizzare la derivazione del dashboard
Per visualizzare la derivazione del dashboard, passare alla scheda Derivazione di una tabella e fare clic su Dashboard. Il dashboard appare sotto Nome del dashboard come utente della tabella.
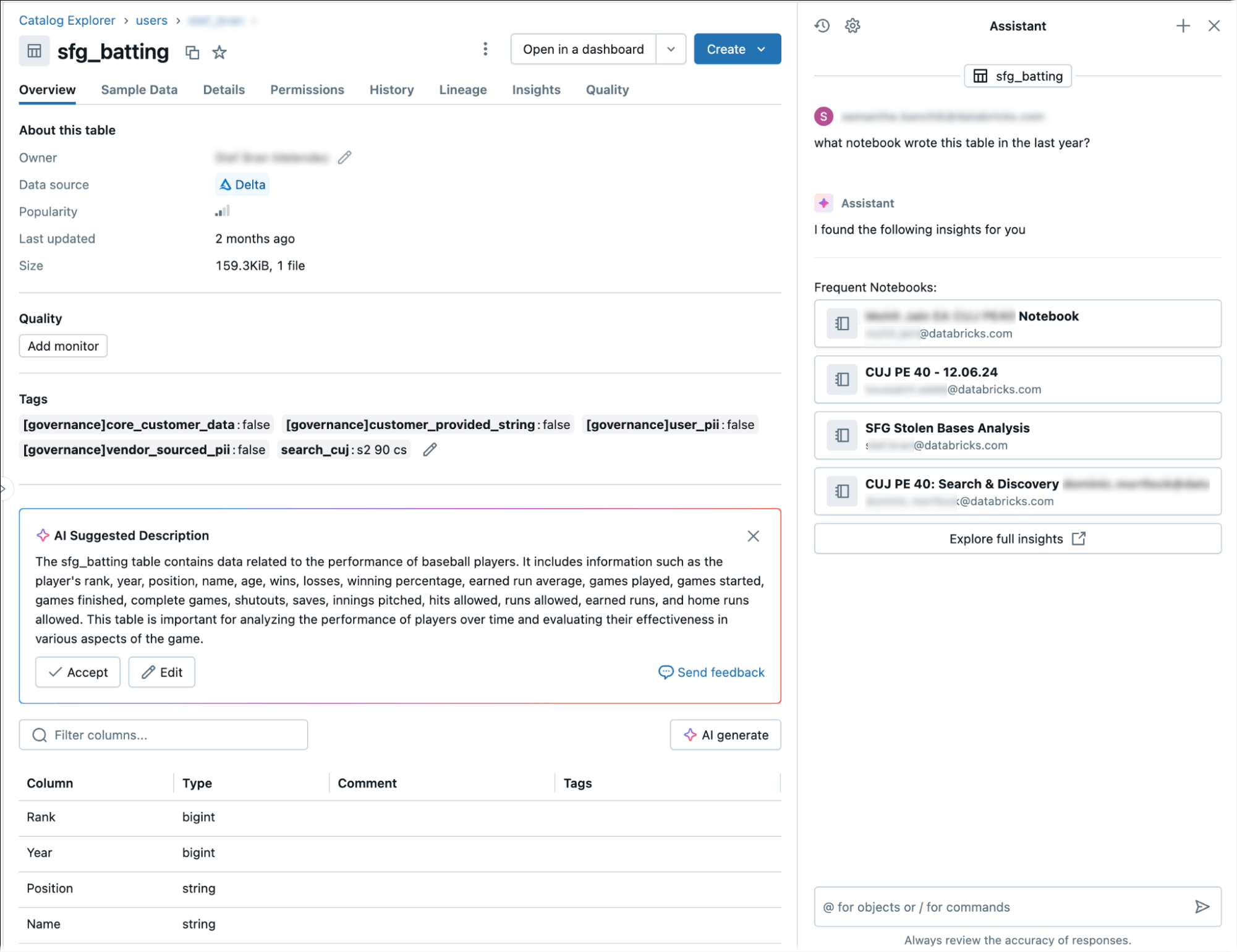
Ottenere il lineage della tabella con Genie Code
Genie Code fornisce informazioni dettagliate sulle derivazioni delle tabelle e sugli approfondimenti.
Per ottenere informazioni sulla derivazione tramite Genie Code:
- Nella barra laterale dell'area di lavoro fare clic Catalogo.
- Sfogliare o cercare il catalogo, fare clic sul nome del catalogo e quindi fare clic
 Icona Genie Code nell'angolo superiore destro.
Icona Genie Code nell'angolo superiore destro. - Al prompt del codice Genie digitare:
- /getTableLineages per visualizzare le dipendenze upstream e downstream.
- /getTableInsights per accedere a informazioni dettagliate basate sui metadati, ad esempio attività utente e modelli di query.
Queste query consentono a Genie Code di rispondere a domande come "mostra le derivazioni downstream" o "chi esegue più spesso query su questa tabella".
Eseguire query sui dati di derivazione usando le tabelle di sistema
È possibile usare le tabelle di sistema di derivazione per eseguire query sui dati di derivazione a livello di codice. Per istruzioni dettagliate, vedere il riferimento alle tabelle di sistema e il riferimento alle tabelle del sistema lineage.
Autorizzazioni di derivazione.
I grafici di lineage condividono lo stesso modello di autorizzazione di Unity Catalog. Le tabelle e altri oggetti dati registrati nel metastore del catalogo Unity sono visibili solo agli utenti che dispongono almeno di autorizzazioni BROWSE per tali oggetti. Se un utente non dispone del privilegio BROWSE o SELECT per una tabella, non può esplorarne la derivazione. I grafici di derivazione mostrano gli oggetti del Catalogo Unity in tutte le aree di lavoro collegate al metastore, a condizione che l'utente disponga di adeguate autorizzazioni sugli oggetti.
Ad esempio, eseguire i comandi seguenti per userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
Quando userA visualizza il grafico di derivazione per la tabella lineage_data.lineagedemo.menu, verrà visualizzata la tabella menu. Non saranno in grado di visualizzare informazioni sulle tabelle associate, ad esempio la tabella downstream lineage_data.lineagedemo.dinner. La tabella dinner viene visualizzata come nodo masked nella visualizzazione per userAe userA non è in grado di espandere il grafico per visualizzare le tabelle downstream dalle tabelle a cui non dispone dell'autorizzazione per accedere.
Se si esegue il comando seguente per concedere l'autorizzazione BROWSE a userB, tale utente può visualizzare il grafico di derivazione per qualsiasi tabella nello lineage_data schema:
GRANT BROWSE on lineage_data to `userB@company.com`;
Analogamente, gli utenti di derivazione devono disporre di autorizzazioni specifiche per visualizzare oggetti dell'area di lavoro come notebook, processi e dashboard. Inoltre, possono visualizzare solo informazioni dettagliate sugli oggetti dell'area di lavoro quando vengono connessi all'area di lavoro in cui sono stati creati tali oggetti. Le informazioni dettagliate sugli oggetti a livello di area di lavoro in altre aree di lavoro sono mascherate nel grafico di derivazione.
Per altre informazioni sulla gestione dell'accesso a oggetti a protezione diretta in Unity Catalog, vedere Gestire i privilegi in Unity Catalog. Per altre informazioni sulla gestione dell'accesso agli oggetti dell'area di lavoro, ad esempio notebook, processi e dashboard, si veda Elenchi di controllo di accesso.
Limitazioni di derivazione
La derivazione dei dati presenta le limitazioni seguenti. Queste limitazioni si applicano anche alle tabelle di sistema di derivazione:
- Sebbene la derivazione sia aggregata per tutte le aree di lavoro collegate allo stesso metastore del catalogo Unity, i dettagli degli oggetti dell'area di lavoro come notebook e dashboard sono visibili solo nell'area di lavoro in cui sono stati creati.
- I dati di derivazione acquisiti prima del 1° settembre 2024 non sono disponibili.
- I lavori che utilizzano la richiesta dell'API
runs submito il tipo di attivitàspark submitnon sono disponibili nelle viste di origine. La derivazione a livello di tabella e colonna viene ancora registrata per questi flussi di lavoro, ma il collegamento all'esecuzione del job non viene registrato. - Il lineage non viene mantenuto per gli oggetti rinominati. Questo vale per cataloghi, schemi, tabelle, viste e colonne.
- Se si usa il checkpoint del set di dati Spark SQL, la derivazione non viene acquisita.
- Unity Catalog acquisisce il lineage dalle pipeline dichiarative di Lakeflow Spark nella maggior parte dei casi. In alcuni casi, tuttavia, non è possibile garantire una copertura di derivazione completa, ad esempio quando le pipeline usano tabelle PRIVATE.
- I set di dati distribuiti resilienti (RDD) non vengono acquisiti in derivazione.
- Le visualizzazioni temporanee globali non vengono acquisite in derivazione.
- Le transazioni generano una derivazione durante ogni lettura e scrittura. Gli eventi di derivazione vengono mantenuti anche se viene eseguito il rollback della transazione.
- Le tabelle sotto
system.information_schemanon vengono acquisite nel lineage. - Il Catalogo Unity acquisisce il tracciamento al livello di colonna il più possibile. Tuttavia, esistono alcuni casi in cui non è possibile acquisire la derivazione a livello di colonna. Questi includono:
Impossibile acquisire la derivazione delle colonne se l'origine o la destinazione viene fatto riferimento come percorso (esempio:
select * from delta."s3://<bucket>/<path>"). La derivazione delle colonne è supportata solo quando si fa riferimento sia all'origine che alla destinazione in base al nome della tabella (ad esempio:select * from <catalog>.<schema>.<table>).Uso di funzioni definite dall'utente che possono nascondere il mapping tra le colonne di origine e di destinazione.