Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive come compilare, distribuire ed eseguire un file JAR Scala con bundle di automazione dichiarativi. Per informazioni sui bundle, vedere Che cosa sono i bundle di automazione dichiarativa?.
Ad esempio, la configurazione che compila un file JAR Java e la carica nel catalogo Unity, vedere Bundle che carica un file JAR in Unity Catalog.
Requisiti
Questa esercitazione richiede che l'area di lavoro di Databricks soddisfi i requisiti seguenti:
- Il catalogo unity è abilitato. Vedere Abilitare un'area di lavoro per il Catalogo Unity.
- È necessario disporre di un volume di Unity Catalog in Databricks in cui archiviare gli artefatti di compilazione e le autorizzazioni per caricare il file JAR in un percorso di volume specificato. Vedere Creare e gestire volumi del catalogo Unity.
- Il calcolo serverless è abilitato. Assicurarsi di esaminare le limitazioni delle funzionalità di calcolo serverless.
- L'area di lavoro si trova in un'area supportata.
Inoltre, l'ambiente di sviluppo locale deve avere installato quanto segue:
- Java Development Kit (JDK) 17
- IntelliJ IDEA
- sbt
- CLI di Databricks versione 0.218.0 o successiva. Per controllare la versione installata dell'interfaccia della riga di comando di Databricks, eseguire il comando
databricks -v. Per installare o aggiornare Databricks CLI, consultare Installare o aggiornare il Databricks CLI. - L'autenticazione CLI di Databricks è configurata con un profilo
DEFAULT. Per configurare l'autenticazione, vedere Configurare l'accesso all'area di lavoro.
Passaggio 1: Creare il bundle
Creare prima di tutto il bundle usando il comando bundle init e il modello di bundle di progetto Scala.
Il modello di bundle JAR Scala crea un bundle che crea un file JAR, lo carica nel volume specificato e definisce un processo con un'attività Spark del file JAR eseguita nel calcolo serverless. Nel progetto modello Scala definisce una funzione definita dall'utente che applica una semplice trasformazione a un DataFrame di esempio e produce i risultati. L'origine del modello si trova nel repository bundle-examples.
Eseguire il comando seguente in una finestra del terminale nel computer di sviluppo locale. Richiede il valore di alcuni campi obbligatori.
databricks bundle init default-scalaPer un nome per il progetto, immettere
my_scala_project. Questo determina il nome della cartella principale per questo bundle. Questa directory principale viene creata all’interno della directory di lavoro corrente.Per il percorso di destinazione dei volumi, specificare il percorso dei volumi di Unity Catalog in Databricks in cui si vuole creare la directory bundle che conterrà il file JAR e altri artefatti, ad esempio
/Volumes/my-catalog/my-schema/bundle-volumes.Annotazioni
Il progetto modello configura l'ambiente di calcolo serverless, ma se lo si modifica per usare il calcolo classico, l'amministratore potrebbe dover aggiungere alla lista consentita il percorso del file JAR di Volumes che specificate. Vedere librerie lista consentita e script di inizializzazione sulle risorse di calcolo con modalità di accesso standard (in precedenza modalità di accesso condiviso).
Passaggio 2: Configurare le opzioni della macchina virtuale
Importa la directory corrente in IntelliJ dove si trova
build.sbt.Scegliere Java 17 in IntelliJ. Passare a File>Struttura del progetto>SDK.
Apri
src/main/scala/com/examples/Main.scala.Passare alla configurazione per Main per aggiungere le opzioni della macchina virtuale:
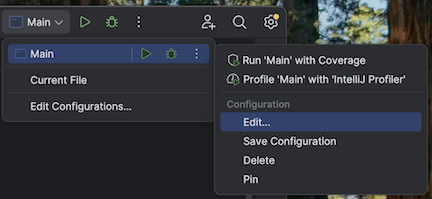
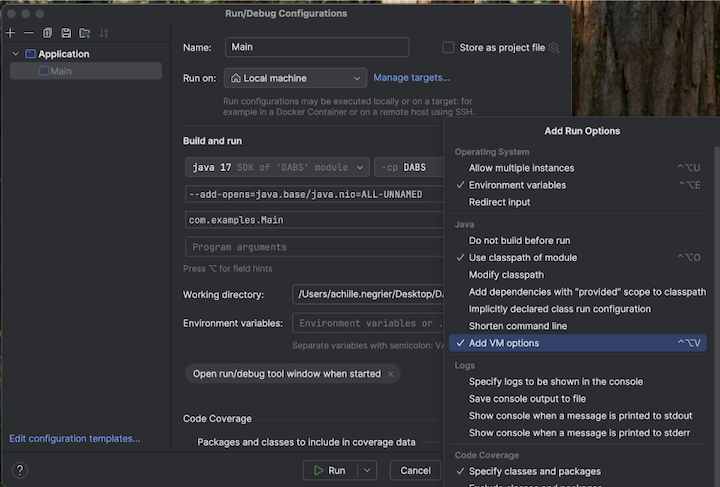
Aggiungere quanto segue alle opzioni della macchina virtuale:
--add-opens=java.base/java.nio=ALL-UNNAMED
Suggerimento
In alternativa, o se si usa Visual Studio Code, aggiungere quanto segue al file di compilazione sbt:
fork := true
javaOptions += "--add-opens=java.base/java.nio=ALL-UNNAMED"
Eseguire quindi l'applicazione dal terminale:
sbt run
Passaggio 3: Esplorare il bundle
Per visualizzare i file generati dal modello, vai alla directory principale del nuovo bundle e apri questa directory nel tuo IDE. Il modello usa sbt per compilare e creare un pacchetto di file Scala e usare Databricks Connect per lo sviluppo locale. Per informazioni dettagliate, vedere l'README.md del progetto generato.
I file seguenti sono di particolare interesse:
-
databricks.yml: questo file specifica il nome programmatico del bundle, include un riferimento alla definizione del processo e specifica le impostazioni relative all'area di lavoro di destinazione. -
resources/my_scala_project.job.yml: questo file specifica le impostazioni dell'attività JAR e del cluster del processo. -
src/: questa directory include i file di origine per il progetto Scala. -
build.sbt: questo file contiene importanti impostazioni di compilazione e libreria dipendente. -
README.md: questo file contiene questi passaggi introduttivi e le istruzioni e le impostazioni di compilazione locali.
Passaggio 4: Convalidare il file di configurazione del bundle del progetto
Verificare quindi se la configurazione del bundle è valida usando il comando di convalida del bundle.
Dal directory radice eseguire il comando CLI di Databricks
bundle validate. Tra gli altri controlli, questo verifica che il volume specificato nel file di configurazione esista nell'area di lavoro.databricks bundle validateSe viene restituito un riepilogo della configurazione del bundle, la convalida ha avuto esito positivo. Se vengono restituiti errori, correggere gli errori, ripetere questo passaggio.
Se si apportano modifiche al bundle dopo questo passaggio, ripetere questo passaggio per verificare se la configurazione del bundle è ancora valida.
Passaggio 5: Distribuire il progetto locale nell'area di lavoro remota
Distribuire ora il bundle nell'area di lavoro remota di Azure Databricks usando il comando di distribuzione del bundle. Questo passaggio compila il file JAR e lo carica nel volume specificato.
Eseguire il comando Databricks CLI
bundle deploy.databricks bundle deploy -t devPer verificare se il file JAR compilato in locale è stato distribuito:
- Nella barra laterale dell'area di lavoro di Azure Databricks fare clic su Esplora cataloghi.
- Vai al percorso di destinazione del volume che hai specificato quando hai inizializzato il pacchetto. Il file JAR deve trovarsi nella cartella seguente all'interno di tale percorso:
/my_scala_project/dev/<user-name>/.internal/.
Per verificare se l'attività è stata creata:
- Nella barra laterale dell'area di lavoro di Azure Databricks fare clic su Processi e pipeline.
- Opzionalmente, selezionare i filtri Attività e Di mia proprietà.
- Fare clic su [dev
<your-username>]my_scala_project. - Fare clic sulla scheda Attività.
Deve essere presente un'attività: main_task.
Se si apportano modifiche al bundle dopo questo passaggio, ripetere i passaggi di convalida e distribuzione.
Passaggio 6: eseguire il progetto distribuito
Eseguire infine il processo di Azure Databricks usando il comando di esecuzione del bundle.
Dalla directory radice, eseguire il comando CLI di Databricks
bundle run, specificando il nome del job nel file di definizionemy_scala_project.job.yml:databricks bundle run -t dev my_scala_projectCopiare il valore di
Run URLvisualizzato nel terminale e incollare questo valore nel Web browser per aprire l'area di lavoro di Azure Databricks.Nell'area di lavoro di Azure Databricks, una volta che il compito si completa con successo e viene visualizzata una barra verde nel titolo, fare clic sul compito main_task per visualizzare i risultati.