Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
I bundle dichiarativi di automazione (in precedenza noti come aggregazioni di asset di Databricks) descrivono le risorse di Databricks, ad esempio processi, pipeline e notebook come file di origine, consentono di includere metadati insieme a questi file di origine per effettuare il provisioning dell'infrastruttura e di altre risorse e fornire una definizione end-to-end di un progetto, tutto incluso come singolo progetto distribuibile. Vedere Che cosa sono i bundle di automazione dichiarativa?.
I modelli di aggregazione consentono agli utenti di creare bundle in modo coerente e ripetibile, stabilendo strutture di cartelle, passaggi di compilazione e attività, test e altri attributi dell'infrastruttura distribuita come codice (IaC) devOps comuni in una pipeline di distribuzione.
Ad esempio, se si eseguono regolarmente processi che richiedono pacchetti personalizzati con un passaggio di compilazione dispendioso in termini di tempo durante l'installazione, è possibile velocizzare il ciclo di sviluppo creando un modello di bundle che specifica un ambiente contenitore personalizzato.
Databricks fornisce un set di modelli di bundle predefiniti , ma è anche possibile creare modelli di bundle personalizzati. Gli utenti possono quindi inizializzare i bundle usando il comando init bundle, specificando un modello predefinito o il modello personalizzato.
Creare un bundle usando un modello
Per usare un modello di bundle Azure Databricks per creare il bundle, usare il comando Databricksbundle init, specificando il nome del modello da usare o selezionare un modello disponibile durante la creazione di un bundle nell'area di lavoro. Vedere Creare un bundle.
Ad esempio, il comando seguente crea un bundle usando il modello di bundle Python predefinito:
databricks bundle init default-python
Per usare un modello di bundle personalizzato, passare il percorso locale o l'URL remoto del modello al comando della CLI di Databricksbundle init.
Ad esempio, il comando seguente usa il modello dab-container-template creato nell'Esercitazione sul modello di bundle personalizzato:
databricks bundle init /projects/my-custom-bundle-templates/dab-container-template
Se non si specifica un template, il comando bundle init visualizza il set di template predefiniti disponibili da cui scegliere.
modelli di pacchetti predefiniti
Azure Databricks offre i modelli di bundle predefiniti seguenti:
| Modello | Descrizione |
|---|---|
default-minimal |
Modello per la creazione di un bundle vuoto. Questo modello contiene solo i file necessari e nessun codice di esempio e configura anche le variabili di catalogo essenziali. In questo modo è possibile creare rapidamente nuovi progetti bundle. Vedere default-minimal. |
default-python |
Modello per l'uso di Python con Databricks. Questo modello crea un bundle con un processo e una pipeline ETL e richiede uv. Vedere default-python. |
default-scala |
Modello per l'uso di Scala con Databricks. Questo modello crea un bundle che compila un file JAR Scala configurato per la distribuzione in un ambiente di calcolo serverless. Vedere default-scala. |
default-sql |
Modello per l'uso di SQL con Databricks. Questo modello contiene un file di configurazione che definisce un processo che esegue query SQL in un'istanza di SQL Warehouse. Vedere default-sql. |
dbt-sql |
Modello che sfrutta dbt-core per lo sviluppo locale e i bundle per la distribuzione. Questo modello contiene la configurazione che definisce un processo con un'attività dbt, nonché un file di configurazione che definisce i profili dbt per i processi dbt distribuiti. Vedere dbt-sql. |
mlops-stacks |
Modello avanzato di stack completo per l'avvio di nuovi progetti stack MLOps. Vedere mlops-stacks e Bundle di Automazione Dichiarativi per Stack MLOps. |
pydabs |
Versione modificata del default-python modello che usa Python per la configurazione del bundle anziché YAML. Vedere pydabs. |
Modelli di bundle personalizzati
I modelli di bundle usano la sintassi di creazione di modelli di pacchetto Go, che offrono flessibilità nei modelli di bundle personalizzati che è possibile creare. Vedere la documentazione sul modello di pacchetto Go.
struttura del progetto modello
Come minimo, un progetto di modello di bundle deve avere:
- Un file
databricks_template_schema.jsonalla radice del progetto che definisce una proprietà di richiesta utente per il nome del progetto del pacchetto. Consultare il Template schema. - Un file
databricks.yml.tmplche si trova in una cartellatemplateche definisce la configurazione per tutti i bundle creati con il modello. Se il filedatabricks.yml.tmplfa riferimento a modelli di configurazione aggiuntivi*.yml.tmpl, specificare il percorso di questi nel mappinginclude. Consultare Modelli di configurazione.
Inoltre, la struttura delle cartelle e i file inclusi del progetto modello di bundle nella cartella template vengono riflessi dai bundle creati con il modello. Ad esempio, se si vuole che il modello generi un bundle con un notebook semplice nella cartella src e una definizione di processo che esegue il notebook nella cartella resources, è necessario organizzare il progetto modello come segue:
basic-bundle-template
├── databricks_template_schema.json
└── template
└── {{.project_name}}
├── databricks.yml.tmpl
├── resources
│ └── {{.project_name}}_job.yml.tmpl
└── src
└── simple_notebook.ipynb
Suggerimento
Il nome della cartella del progetto e il nome del file di definizione del processo in questo modello di bundle usano una variabile modello. Per informazioni sugli assistenti e sulle variabili dei modelli, consultare Assistenti e variabili del modello.
Schema del modello
Un progetto modello di bundle personalizzato deve contenere un file JSON databricks_template_schema.json nella radice del progetto. Questo file definisce i campi usati dall'interfaccia della riga di comando di Databricks quando viene eseguito il comando bundle init, ad esempio il testo del prompt.
Il file di base databricks_template_schema.json seguente definisce una variabile di input project_name per il progetto bundle, che include il messaggio di richiesta e un valore predefinito. Definisce quindi un messaggio di esito positivo per l'inizializzazione del progetto bundle che usa il valore della variabile di input all'interno del messaggio.
{
"properties": {
"project_name": {
"type": "string",
"default": "basic_bundle",
"description": "What is the name of the bundle you want to create?",
"order": 1
}
},
"success_message": "\nYour bundle '{{.project_name}}' has been created."
}
Campi dello schema del modello
Il file databricks_template_schema.json supporta la definizione di variabili di input per la raccolta di informazioni durante l'inizializzazione del bundle dall'utente all'interno del campo properties, nonché campi aggiuntivi per personalizzare l'inizializzazione.
Le variabili di input vengono definite nel campo properties dello schema del modello. Ogni variabile di input definisce i metadati necessari per presentare un prompt all'utente durante l'initalizzazione del bundle. Il valore della variabile è quindi accessibile usando la sintassi delle variabili di modello, ad esempio {{.project_name}}.
È anche possibile impostare i valori di alcuni campi per personalizzare il processo di inizializzazione del bundle.
I campi dello schema supportati sono elencati nella tabella seguente.
| Campo dello Schema | Descrizione |
|---|---|
properties |
Definizioni delle variabili di input del modello di pacchetto. Databricks consiglia di definire almeno una variabile di input che corrisponde al nome del progetto di bundle. |
properties.<variable_name> |
Nome della variabile di input. |
properties.<variable_name>.default |
Valore predefinito da usare se un valore non viene fornito dall'utente con --config-file come parte del comando bundle init o alla riga di comando quando viene richiesto. |
properties.<variable_name>.description |
Messaggio di richiesta dell'utente associato alla variabile di input. |
properties.<variable_name>.enum |
Elenco di valori possibili per la proprietà, ad esempio "enum": ["azure", "aws", "gcp"]. Se questo campo è definito, l'interfaccia della riga di comando di Databricks presenta i valori in un elenco nella riga di comando per richiedere all'utente di selezionare un valore. |
properties.<variable_name>.order |
Intero che definisce l'ordine relativo per le proprietà di input. Questo controlla l'ordine in cui vengono visualizzati i prompt per queste variabili di input nella riga di comando. |
properties.<variable_name>.pattern |
Modello regexp da usare per convalidare l'input dell'utente, ad esempio "pattern": "^[^ .\\\\/]{3,}$". Per la sintassi regexp supportata, vedere https://github.com/google/re2/wiki/Syntax. |
properties.<variable_name>.pattern_match_failure_message |
Messaggio visualizzato all'utente se il valore immesso dall'utente non corrisponde al modello specificato, ad esempio Project name must be at least 3 characters long and cannot contain the following characters: \"\\\", \"/\", \" \" and \".\".". |
properties.<variable_name>.skip_prompt_if |
Ignorare la richiesta della variabile di input se lo schema è soddisfatto dalla configurazione già presente. In tal caso viene invece utilizzato il valore predefinito della proprietà . Per un esempio, vedere il modello mlops-stacks. Solo i confronti const sono supportati. |
properties.<variable_name>.skip_prompt_if.properties.<previous_variable_name>.const |
Se il valore di <previous_variable_name> corrisponde alla costante configurata in skip_prompt_if, la richiesta di <variable_name> verrà ignorata. |
template_dir |
Percorso della directory del modello, ad esempio ../default. In questo modo, i modelli generici consentono a più databricks_template_schema.json file di fare riferimento alla stessa directory. |
welcome_message |
Primo messaggio da restituire prima di richiedere l'input all'utente. |
success_message |
Messaggio da stampare dopo l'inizializzazione del modello. |
min_databricks_cli_version |
La versione minima semver di questa CLI di Databricks richiesta dal modello.
databricks bundle init ha esito negativo se la versione dell'interfaccia della riga di comando è minore di questa versione. |
version |
Riservato a un uso futuro. La versione dello schema. Viene usato per determinare se lo schema è compatibile con la versione corrente dell'interfaccia della riga di comando. |
modelli di configurazione
Un modello di bundle personalizzato deve contenere un file databricks.yml.tmpl in una cartella template nel progetto modello di bundle usato per creare il progetto bundle databricks.yml file di configurazione. I modelli per i file di configurazione per le risorse possono essere creati nella cartella resources. Popolare questi file modello con il modello di configurazione YAML.
I modelli di configurazione di esempio seguenti per databricks.yml e *_job.yml associati stabiliscono il nome del bundle e due ambienti di destinazione e definiscono un processo che esegue il notebook nel bundle, per i bundle creati usando questo modello. Questi modelli di configurazione sfruttano le sostituzioni di bundle e gli assistenti dei modelli di bundle .
template/{{.project_name}}/databricks.yml.tmpl:
# databricks.yml
# This is the configuration for the bundle {{.project_name}}.
bundle:
name: {{.project_name}}
include:
- resources/*.yml
targets:
# The deployment targets. See https://docs.databricks.com/en/dev-tools/bundles/deployment-modes.html
dev:
mode: development
default: true
workspace:
host: {{workspace_host}}
prod:
mode: production
workspace:
host: {{workspace_host}}
root_path: /Shared/.bundle/prod/${bundle.name}
{{- if not is_service_principal}}
run_as:
# This runs as {{user_name}} in production. Alternatively,
# a service principal could be used here using service_principal_name
user_name: {{user_name}}
{{end -}}
template/{{.project_name}}/resources/{{.project_name}}_job.yml.tmpl:
# {{.project_name}}_job.yml
# The main job for {{.project_name}}
resources:
jobs:
{{.project_name}}_job:
name: {{.project_name}}_job
tasks:
- task_key: notebook_task
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/simple_notebook.ipynb
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
node_type_id: i3.xlarge
spark_version: 13.3.x-scala2.12
Aiuti e variabili del modello
Gli helper modello sono funzioni fornite da Databricks che è possibile usare all'interno dei file modello per ottenere informazioni specifiche dell'utente in fase di esecuzione o interagire con il motore di modelli. È anche possibile definire variabili di modello personalizzate.
Per i progetti modello di bundle di Databricks sono disponibili gli helper modello seguenti. Per informazioni sull'uso di modelli e variabili Go, vedere Modelli Go.
| Assistente | Descrizione |
|---|---|
{{url}} |
Alias di https://pkg.go.dev/net/url#Parse. In questo modo è possibile l'utilizzo di tutti i metodi di url.URL. |
{{regexp}} |
Alias di https://pkg.go.dev/regexp#Compile. In questo modo è possibile l'utilizzo di tutti i metodi di regexp.Regexp. |
{{random_int}} |
Restituisce, come int, un numero pseudo-casuale non negativo nell'intervallo semi-aperto (0,n). |
{{uuid}} |
Restituisce, come stringa, un UUID che è un IDentifier univoco universale a 128 bit (16 byte) come definito in RFC 4122.Questo ID è stabile per la durata dell'esecuzione del modello e può essere usato per popolare il campo bundle.uuid in databricks.yml dagli autori di modelli. |
{{bundle_uuid}} |
ID univoco per il bundle. Più chiamate di questa funzione restituiranno lo stesso UUID. |
{{pair}} |
Coppia chiave-valore. Viene usato con l'helper map per generare mappe da usare all'interno di un modello. |
{{map}} |
Converte un elenco di coppie in un oggetto mappa. Ciò è utile per passare più oggetti ai modelli definiti nella directory della libreria. Poiché la sintassi del modello di testo Go per richiamare un modello consente solo di specificare un singolo argomento, questa funzione può essere usata per risolvere tale limitazione. Nella riga seguente, ad esempio, {{template "my_template" (map (pair "foo" $arg1) (pair "bar" $arg2))}}, $arg1 e $arg2 possono essere indicati dall'interno di my_template come .foo e .bar. |
{{smallest_node_type}} |
Restituisce il tipo di nodo più piccolo. |
{{path_separator}} |
Carattere separatore di percorso per il sistema operativo. Si tratta di / per sistemi basati su Unix e \ per Windows. |
{{workspace_host}} |
URL host dell'area di lavoro a cui l'utente è attualmente autenticato. |
{{user_name}} |
Nome completo dell'utente che inizializza il modello. |
{{short_name}} |
Nome breve dell'utente che inizializza il modello. |
{{default_catalog}} |
Restituisce il catalogo dell'area di lavoro predefinito. Se non è presente alcun valore predefinito o se Il catalogo di Unity non è abilitato, verrà restituita una stringa vuota. |
{{is_service_principal}} |
Indica se l'utente corrente è un principale di servizio. |
{{ skip <glob-pattern-relative-to-current-directory> }} |
Fa sì che il motore di template ignori la generazione di tutti i file e le directory che corrispondono allo schema glob di input. Per un esempio, vedere il modello mlops-stacks. |
Helper di modelli personalizzati
Per definire gli helper di template personalizzati, creare un file template nella cartella library del progetto template e usare la sintassi di templating Go per definire gli helper. Ad esempio, il contenuto seguente di un file di library/variables.tmpl definisce le variabili cli_version e model_name. Quando questo modello viene usato per inizializzare un bundle, il valore della variabile model_name viene costruito usando il campo input_project_name definito nel file dello schema del modello. Il valore di questo campo è l'input dell'utente dopo una richiesta.
{{ define `cli_version` -}}
v0.240.0
{{- end }}
{{ define `model_name` -}}
{{ .input_project_name }}-model
{{- end }}
Per un esempio completo, vedere il file delle variabili del modello mlops-stacks .
Testare il modello di bundle
Infine, assicurarsi di testare il modello. Ad esempio, usare l'interfaccia della riga di comando di Databricks per inizializzare un nuovo bundle usando il modello definito nelle sezioni precedenti:
databricks bundle init basic-bundle-template
Per il prompt, What is your bundle project name?, digitare my_test_bundle.
Dopo aver creato il bundle di test, viene restituito il messaggio di esito positivo del file di schema. Se si esamina il contenuto della cartella my_test_bundle, verrà visualizzato quanto segue:
my_test_bundle
├── databricks.yml
├── resources
│ └── my_test_bundle_job.yml
└── src
└── simple_notebook.ipynb
E il file e il processo databricks.yml sono ora personalizzati:
# databricks.yml
# This is the configuration for the bundle my-test-bundle.
bundle:
name: my_test_bundle
include:
- resources/*.yml
targets:
# The 'dev' target, used for development purposes. See [_](https://docs.databricks.com/en/dev-tools/bundles/deployment-modes.html#development-mode)
dev:
mode: development
default: true
workspace:
host: https://my-host.cloud.databricks.com
# The 'prod' target, used for production deployment. See [_](https://docs.databricks.com/en/dev-tools/bundles/deployment-modes.html#production-mode)
prod:
mode: production
workspace:
host: https://my-host.cloud.databricks.com
root_path: /Shared/.bundle/prod/${bundle.name}
run_as:
# This runs as someone@example.com in production. Alternatively,
# a service principal could be used here using service_principal_name
user_name: someone@example.com
# my_test_bundle_job.yml
# The main job for my_test_bundle
resources:
jobs:
my_test_bundle_job:
name: my_test_bundle_job
tasks:
- task_key: notebook_task
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/simple_notebook.ipynb
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
node_type_id: i3.xlarge
spark_version: 13.3.x-scala2.12
Condividere un modello personalizzato
Se si vuole condividere un modello di bundle con altri utenti, è possibile archiviarlo nel controllo della versione con qualsiasi provider supportato da Git e a cui gli utenti hanno accesso. Per eseguire il comando bundle init con un URL Git, assicurarsi che il file databricks_template_schema.json si trovi nel percorso radice relativo a tale URL Git.
Suggerimento
È possibile inserire il databricks_template_schema.json file in una cartella diversa rispetto alla radice del bundle. È quindi possibile usare l'opzione bundle init del --template-dir comando per fare riferimento a tale cartella, che contiene il databricks_template_schema.json file.
Configurare una cartella modello personalizzata nell'area di lavoro
Importante
Questa funzionalità è in versione beta.
I modelli di bundle personalizzati possono essere resi disponibili per la creazione di bundle nell'area di lavoro.
Archiviare il modello di bundle in un repository GitHub e configurare una cartella Git per la connessione. Per informazioni sulla configurazione di una cartella Git, vedere Clonare un repository.
In qualità di amministratore dell'account o dell'area di lavoro, passare a Impostazioni nell'area di lavoro. Vedi Gestisci l'area di lavoro.
Fare clic su Sviluppo.
In Bundle di automazione dichiarativa selezionare una cartella per i modelli personalizzati. Tutti i modelli di bundle personalizzati devono essere disponibili a livello radice della cartella.
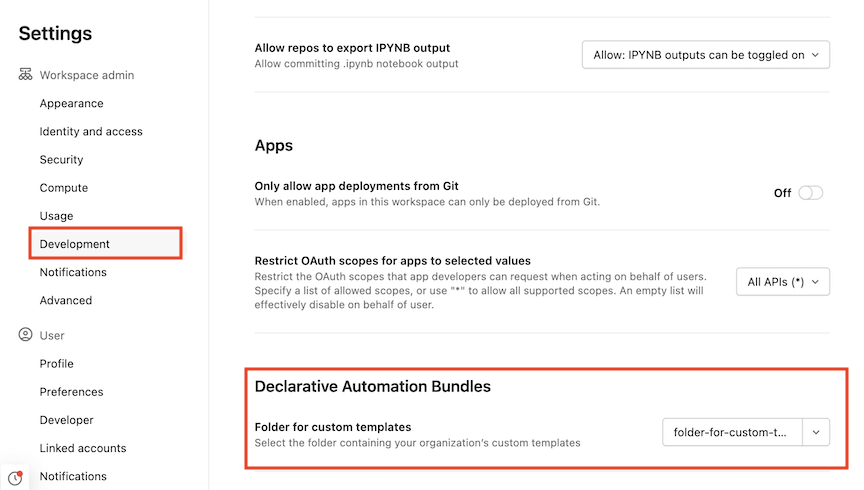
Quando viene visualizzata la finestra di dialogo delle autorizzazioni, concedere a tutti gli utenti l'accesso alla cartella per i modelli personalizzati o selezionare Non concedere l'accesso per impostare autorizzazioni più granulari.
Per impostare autorizzazioni più granulari, selezionare i tre puntini all'interno di qualsiasi cartella e fare clic su Visualizza dettagli.
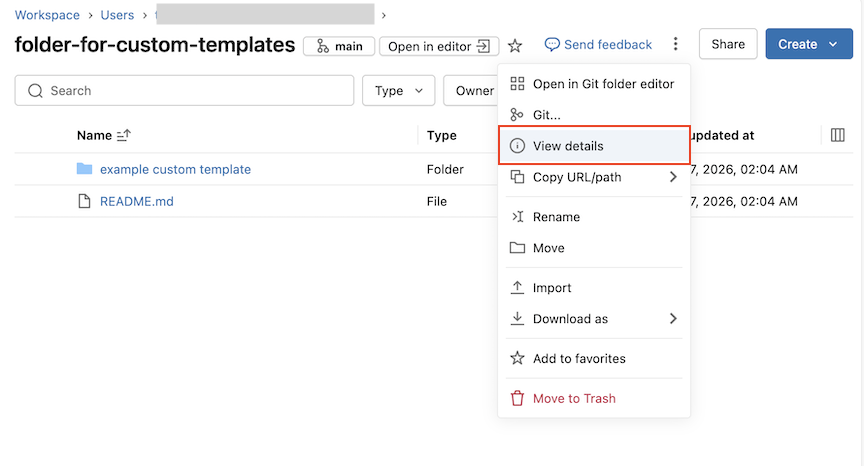
Fare clic su Condividi nel pannello dei dettagli della cartella Git .
Scegliere chi può modificare i modelli (CAN MANAGE) e chi può creare bundle usando i modelli (CAN VIEW).
Per altre informazioni sulle autorizzazioni, vedere Elenchi di controllo di accesso alle cartelle e ACLdelle cartelle Git.
I modelli in questa cartella sono ora disponibili per gli utenti quando creano bundle nell'area di lavoro. Vedere Creare un bundle.
Passaggi successivi
- Esplorare modelli aggiuntivi creati e gestiti da Databricks. Vedi gli esempi di bundle nel repository di GitHub.
- Per usare stack MLOps con i modelli di bundle di automazione dichiarativa, vedere Bundle di automazione dichiarativa per stack MLOps.
- Scopri di più sulla gestione dei template dei pacchetti Go. Vedere la documentazione sul modello di pacchetto Go.