Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive come creare una pipeline di dati non strutturata per le applicazioni di intelligenza artificiale di generazione. Le pipeline non strutturate sono particolarmente utili per le applicazioni di Retrieval-Augmented Generation (RAG).
Informazioni su come convertire contenuti non strutturati come file di testo e PDF in un indice vettoriale su cui possono eseguire query gli agenti di intelligenza artificiale o altri retriever. Si apprenderà anche come sperimentare e ottimizzare la pipeline per ottimizzare la suddivisione in blocchi, l'indicizzazione e l'analisi dei dati, consentendo di risolvere i problemi e sperimentare con la pipeline per ottenere risultati migliori.
Notebook della pipeline di dati non strutturata
Il notebook seguente illustra come implementare le informazioni contenute in questo articolo per creare una pipeline di dati non strutturata.
Pipeline di dati non strutturati di Databricks
Componenti chiave della pipeline di dati
La base di qualsiasi applicazione RAG con dati non strutturati è la pipeline di dati. Questa pipeline è responsabile della cura e della preparazione dei dati non strutturati in un formato che l'applicazione RAG può usare in modo efficace.

Anche se questa pipeline di dati può diventare complessa a seconda del caso d'uso, di seguito sono riportati i componenti chiave da considerare per la prima compilazione dell'applicazione RAG:
- composizione e inserimento di corpus: selezionare le origini dati e il contenuto corretti in base al caso d'uso specifico.
-
La pre-elaborazione dei dati: trasformare i dati non elaborati in un formato pulito e coerente adatto per l'incorporamento e il recupero.
- Analisi: estrarre informazioni rilevanti dai dati non elaborati usando tecniche di analisi appropriate.
-
Arricchimento: Arricchire i dati con metadati aggiuntivi e rimuovere le interferenze.
- Metadata extraction: Estrarre metadati utili per implementare un reperimento dei dati più veloce ed efficiente.
- Deduplicazione: Analizzare i documenti per identificare ed eliminare i duplicati o i documenti simili ai duplicati.
- filtro: eliminare documenti irrilevanti o indesiderati dalla raccolta.
- Suddivisione in blocchi: suddividi i dati analizzati in blocchi più piccoli e gestibili per un recupero efficiente.
- Embedding: convertire i dati di testo suddivisi in blocchi in una rappresentazione vettoriale numerica che ne catturi il significato semantico.
- l'indicizzazione e l'archiviazione: creare indici vettoriali efficienti per ottimizzare le prestazioni di ricerca.
composizione e inserimento di corpus
L'applicazione RAG non riesce a recuperare le informazioni necessarie per rispondere a una query utente senza il corpus di dati corretto. I dati corretti dipendono interamente dai requisiti e dagli obiettivi specifici dell'applicazione, rendendo fondamentale dedicare tempo alla comprensione delle sfumature dei dati disponibili. Per altre informazioni, vedere flusso di lavoro per sviluppatori di app per intelligenza artificiale generativa .
Ad esempio, quando si crea un bot di supporto clienti, è possibile prendere in considerazione quanto segue:
- Documenti della knowledge base
- Domande frequenti (FAQ)
- Manuali e specifiche del prodotto
- Guide alla risoluzione dei problemi
Coinvolgere esperti di dominio e stakeholder dall'inizio di qualsiasi progetto per identificare e curare contenuti pertinenti che potrebbero migliorare la qualità e la copertura del corpus di dati. Possono fornire informazioni dettagliate sui tipi di query che è probabile che gli utenti inviino e consentano di classificare in ordine di priorità le informazioni più critiche da includere.
Databricks consiglia di inserire dati in modo scalabile e incrementale. Azure Databricks offre vari metodi per l'inserimento dati, inclusi connettori completamente gestiti per applicazioni SaaS e integrazioni api. Come procedura consigliata, i dati di origine non elaborati devono essere inseriti e archiviati in una tabella di destinazione. Questo approccio garantisce la conservazione, la tracciabilità e il controllo dei dati. Consulta Connettori Standard in Lakeflow Connect.
preprocessamento dei dati
Dopo l'inserimento dei dati, è essenziale pulire e formattare i dati non elaborati in un formato coerente adatto per l'incorporamento e il recupero.
Analisi
Dopo aver identificato le origini dati appropriate per l'applicazione retriever, il passaggio successivo estrae le informazioni necessarie dai dati non elaborati. Questo processo, noto come analisi, comporta la trasformazione dei dati non strutturati in un formato che l'applicazione RAG può usare in modo efficace.
Le tecniche e gli strumenti di analisi specifici usati dipendono dal tipo di dati in uso. Ad esempio:
- Documenti di testo (PDF, documenti di Word): librerie pronte per l’uso come non strutturate e PyPDF2 possono gestire vari formati di file e offrire opzioni per personalizzare il processo di analisi.
- documenti HTML: librerie di analisi HTML come BeautifulSoup e lxml possono essere usate per estrarre contenuto pertinente dalle pagine Web. Queste librerie consentono di esplorare la struttura HTML, selezionare elementi specifici ed estrarre il testo o gli attributi desiderati.
- Immagini e documenti scansionati: le tecniche OCR (Optical Character Recognition) sono in genere necessarie per estrarre testo dalle immagini. Le librerie OCR più diffuse includono librerie open source come Tesseract o versioni SaaS come Amazon Textract, Azure AI Vision OCRe API Google Cloud Vision.
Procedure consigliate per l'analisi dei dati
L'analisi garantisce che i dati siano puliti, strutturati e pronti per l'incorporamento della generazione e della ricerca vettoriale. Quando si analizzano i dati, considerare le seguenti procedure consigliate:
- Pulizia dati: pre-elaborare il testo estratto per rimuovere informazioni irrilevanti o rumorose, ad esempio intestazioni, piè di pagina o caratteri speciali. Ridurre la quantità di informazioni non necessarie o in formato non valido che la catena RAG deve elaborare.
- Gestione di errori ed eccezioni: implementare meccanismi di gestione e registrazione degli errori per identificare e risolvere eventuali problemi riscontrati durante il processo di analisi. In questo modo è possibile identificare e risolvere rapidamente i problemi. In questo modo spesso si evidenziano problemi a monte con la qualità dei dati di origine.
- Personalizzazione della logica di analisi: a seconda della struttura e del formato dei dati, potrebbe essere necessario personalizzare la logica di analisi per estrarre le informazioni più pertinenti. Anche se può richiedere ulteriori sforzi iniziali, investire il tempo necessario per eseguire questa operazione, in quanto spesso impedisce molti problemi di qualità downstream.
- Valutazione della qualità dell'analisi: valutare regolarmente la qualità dei dati analizzati esaminando manualmente un campione dell'output. Ciò consente di identificare eventuali problemi o aree per migliorare il processo di analisi.
arricchimento
Arricchire i dati con metadati aggiuntivi e rimuovere il rumore. Anche se l'arricchimento è facoltativo, può migliorare drasticamente le prestazioni complessive dell'applicazione.
estrazione di metadati
La generazione e l'estrazione di metadati che acquisisce informazioni essenziali sul contenuto, il contesto e la struttura del documento possono migliorare significativamente la qualità e le prestazioni di recupero di un'applicazione RAG. I metadati forniscono segnali aggiuntivi che migliorano la pertinenza, abilitano il filtro avanzato e supportano i requisiti di ricerca specifici del dominio.
Sebbene le librerie come LangChain e LlamaIndex forniscano parser predefiniti in grado di estrarre automaticamente i metadati standard associati, è spesso utile integrare questa funzionalità con metadati personalizzati personalizzati in base al caso d'uso specifico. Questo approccio garantisce che vengano acquisite informazioni critiche specifiche del dominio, migliorando il recupero e la generazione downstream. È anche possibile usare modelli di linguaggio di grandi dimensioni per automatizzare il miglioramento dei metadati.
I tipi di metadati includono:
- metadati a livello di documento: nome file, URL, informazioni sull'autore, timestamp di creazione e modifica, coordinate GPS e controllo delle versioni dei documenti.
- metadati basati sul contenuto: parole chiave estratte, riepiloghi, argomenti, entità denominate e tag specifici del dominio (nomi di prodotto e categorie come PII o HIPAA).
- Metadati strutturali: intestazioni di sezione, sommario, numeri di pagina e delimitazioni di contenuto semantico (capitoli o sottosezioni).
- metadati contestuali: sistema di origine, data di inserimento, livello di riservatezza dei dati, lingua originale o istruzioni transnazionali.
L'archiviazione di metadati insieme a documenti in blocchi o ai corrispondenti incorporamenti è essenziale per ottenere prestazioni ottimali. Consente inoltre di limitare le informazioni recuperate e migliorare l'accuratezza e la scalabilità dell'applicazione. Inoltre, l'integrazione dei metadati nelle pipeline di ricerca ibrida, il che significa combinare la ricerca di somiglianza dei vettori con il filtro basato su parole chiave, può migliorare la pertinenza, soprattutto in set di dati di grandi dimensioni o in scenari di criteri di ricerca specifici.
deduplicazione
A seconda delle origini, è possibile terminare con documenti duplicati o quasi duplicati. Ad esempio, se si scarica da una o più unità condivise, più copie dello stesso documento potrebbero esistere in diverse posizioni. Alcune di queste copie possono avere modifiche sottili. Analogamente, la base di conoscenza potrebbe avere copie della documentazione del prodotto o bozze di post del blog. Se questi duplicati rimangono nel corpus, è possibile ottenere blocchi con ridondanza elevata nell'indice finale in grado di ridurre le prestazioni dell'applicazione.
È possibile eliminare alcuni duplicati usando solo i metadati. Ad esempio, se un elemento ha lo stesso titolo e la stessa data di creazione, ma più voci di origini o posizioni diverse, è possibile filtrare tali voci in base ai metadati.
Tuttavia, questo potrebbe non essere sufficiente. Per identificare ed eliminare duplicati in base al contenuto dei documenti, è possibile usare una tecnica nota come hash sensibile alla località. In particolare, una tecnica denominata MinHash funziona correttamente qui e un'implementazione di Spark è già disponibile in Spark ML. Funziona creando un hash per il documento in base alle parole che contiene e poi può identificare efficacemente i duplicati o i duplicati vicini effettuando un confronto su tali hash. A un livello molto elevato, si tratta di un processo in quattro passaggi:
- Creare un vettore di funzionalità per ogni documento. Se necessario, valutare la possibilità di applicare tecniche come la rimozione di parole non significative, lo stemming e la lemmatizzazione per migliorare i risultati e quindi tokenizzare in n-grammi.
- Fittare un modello MinHash ed eseguire l'hashing dei vettori usando MinHash per la distanza Jaccard.
- Eseguire un'unione di somiglianza utilizzando tali hash per produrre un set di risultati per ogni documento duplicato o quasi duplicato.
- Filtra i duplicati che non vuoi mantenere.
Un passaggio di deduplicazione di base può selezionare i documenti da mantenere arbitrariamente (ad esempio il primo nei risultati di ogni duplicato o una scelta casuale tra i duplicati). Un potenziale miglioramento consiste nel selezionare la versione "migliore" del duplicato usando altre logiche ( ad esempio l'ultimo aggiornamento, lo stato della pubblicazione o l'origine più autorevole). Si noti anche che potrebbe essere necessario sperimentare il passaggio di definizione delle caratteristiche e il numero di tabelle hash usate nel modello MinHash per migliorare i risultati corrispondenti.
Per ulteriori informazioni, consultare la documentazione di Spark per hash sensibile alla località.
Filtraggio
Alcuni dei documenti inseriti nel corpus potrebbero non essere utili per l'agente, sia perché sono irrilevanti per il suo scopo, troppo vecchio o inaffidabile, o perché contengono contenuti problematici come la lingua dannosa. Tuttavia, altri documenti possono contenere informazioni riservate che non si desidera esporre tramite l'agente.
Prendere quindi in considerazione l'inclusione di un passaggio nella pipeline per filtrare questi documenti usando tutti i metadati, ad esempio l'applicazione di un classificatore di tossicità al documento per produrre una stima che è possibile usare come filtro. Un altro esempio è l'applicazione di un algoritmo di rilevamento delle informazioni personali ai documenti per filtrare i documenti.
Infine, tutte le origini di documenti immesse nell'agente rappresentano potenziali vettori di attacco per malintenzionati che vogliono avviare attacchi di avvelenamento dei dati. È anche possibile prendere in considerazione l'aggiunta di meccanismi di rilevamento e filtro per identificare ed eliminare tali meccanismi.
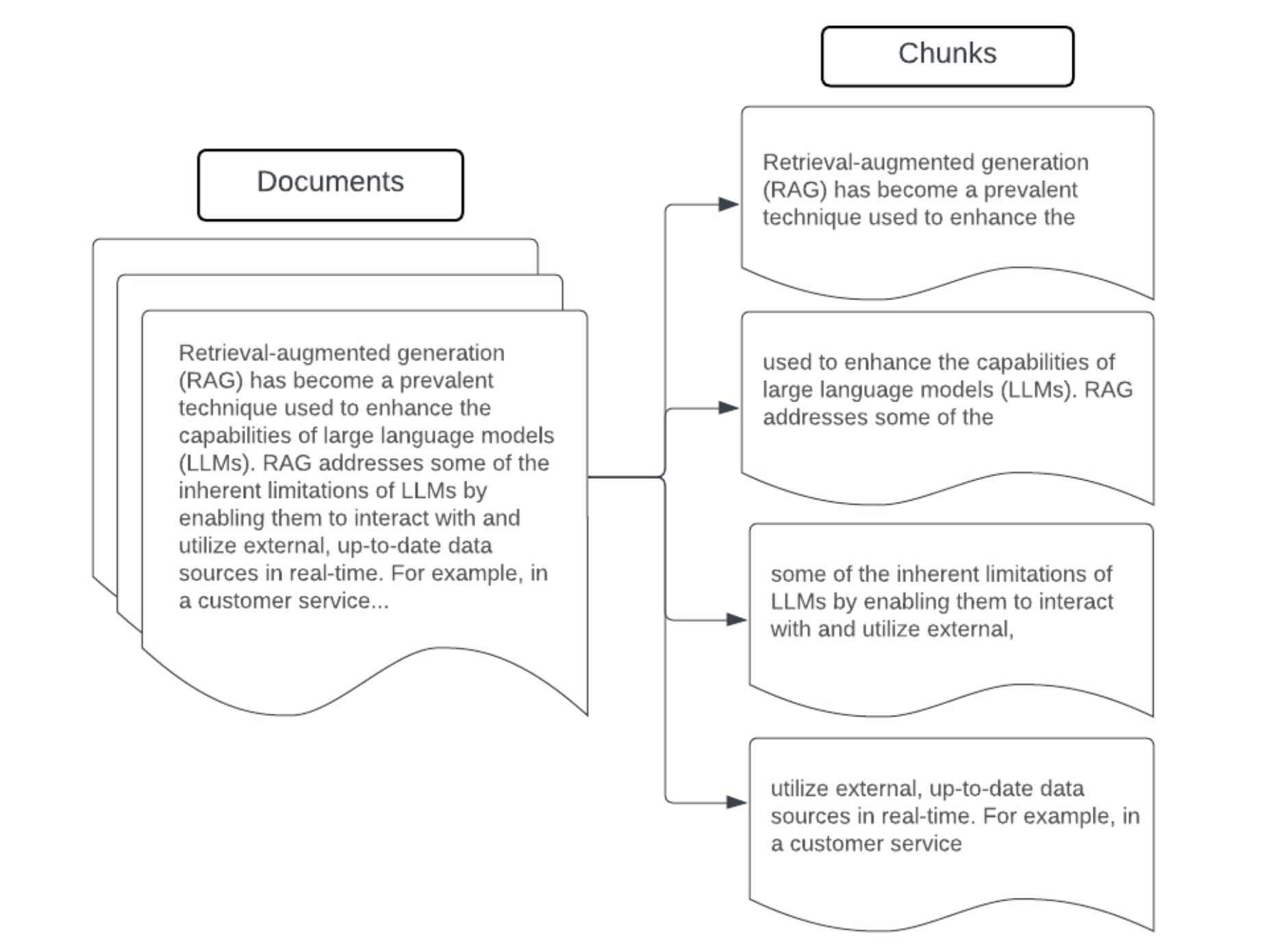
suddivisione in blocchi
Dopo aver analizzato i dati non elaborati in un formato più strutturato, rimuovendo i duplicati e filtrando le informazioni indesiderate, il passaggio successivo consiste nell'suddividerli in unità più piccole e gestibili denominate blocchi. La segmentazione di documenti di grandi dimensioni in blocchi più piccoli e concentrati semanticamente garantisce che i dati recuperati si adattino al contesto LLM riducendo al minimo l'inclusione di informazioni distrazioni o irrilevanti. Le scelte effettuate sulla suddivisione in blocchi influiscono direttamente sui dati recuperati forniti dall'LLM, rendendoli uno dei primi livelli di ottimizzazione in un'applicazione RAG.
Quando si crea una suddivisione in blocchi dei dati, considerare i fattori seguenti:
- Strategia di suddivisione in blocchi: il metodo usato per dividere il testo originale in blocchi. Ciò può comportare tecniche di base, ad esempio la suddivisione per frasi, paragrafi, conteggi di caratteri/token specifici e strategie di suddivisione più avanzate specifiche del documento.
- dimensioni blocco: blocchi più piccoli possono concentrarsi su dettagli specifici, ma perdere alcune informazioni contestuali circostanti. I blocchi più grandi possono acquisire più contesto, ma possono includere informazioni irrilevanti o richiedere costi di calcolo.
- Sovrapposizione tra blocchi: per assicurarsi che le informazioni importanti non vengano perse durante la suddivisione dei dati in blocchi, considerare la possibilità di includere alcune sovrapposizioni tra blocchi adiacenti. La sovrapposizione può garantire la continuità e la conservazione del contesto tra blocchi e migliorare i risultati del recupero.
- coerenza semantica: Quando possibile, mirare a creare blocchi semanticamente coerenti che contengono informazioni correlate, ma possono essere indipendenti come un'unità significativa di testo. A tale scopo, è possibile considerare la struttura dei dati originali, ad esempio paragrafi, sezioni o limiti dell'argomento.
- metadati:metadati rilevanti, ad esempio il nome del documento di origine, l'intestazione di sezione o i nomi dei prodotti, possono migliorare il recupero. Queste informazioni aggiuntive consentono di associare le query di recupero ai blocchi.
Strategie di suddivisione in blocchi dei dati
Trovare il metodo di suddivisione in blocchi appropriato è sia iterativo che dipendente dal contesto. Non esiste un approccio valido per tutti. La dimensione e il metodo ottimali del blocco dipendono dal caso d'uso specifico e dalla natura dei dati elaborati. In generale, le strategie di suddivisione in blocchi possono essere considerate come le seguenti:
- Suddivisione in blocchi a dimensione fissa: suddividere il testo in blocchi di dimensioni predeterminate, ad esempio un numero fisso di caratteri o token, (ad esempio LangChain CharacterTextSplitter). Anche se la suddivisione per un numero arbitrario di caratteri/token è rapida e facile da configurare, in genere non comporta blocchi semanticamente coerenti. Questo approccio funziona raramente per le applicazioni di livello di produzione.
- Suddivisione in blocchi basata su paragrafo: usare i limiti naturali del paragrafo nel testo per definire i blocchi. Questo metodo può contribuire a mantenere la coerenza semantica dei blocchi, poiché i paragrafi contengono spesso informazioni correlate (ad esempio , LangChain RecursiveCharacterTextSplitter).
- La suddivisione in blocchi specifica del formato: Formati come Markdown o HTML hanno una struttura intrinseca che può definire limiti dei blocchi (ad esempio, intestazioni Markdown). A questo scopo, è possibile usare strumenti come MarkdownHeaderTextSplitter o splitter basati su intestazioni e / HTML di LangChain.
- suddivisione in blocchi semantici: Tecniche come la modellazione di argomenti possono essere applicate per identificare sezioni semanticamente coerenti nel testo. Questi approcci analizzano il contenuto o la struttura di ogni documento per determinare i limiti di blocchi più appropriati in base agli spostamenti degli argomenti. Sebbene siano più coinvolti rispetto agli approcci di base, la suddivisione in blocchi semantici può aiutare a creare blocchi più allineati alle divisioni semantiche naturali nel testo (vedere LangChain SemanticChunker, ad esempio).
Esempio: Suddivisione in blocchi a dimensione fissa
Esempio di suddivisione in blocchi a dimensione fissa usando RecursiveCharacterTextSplitter di LangChain con chunk_size=100 e chunk_overlap=20. ChunkViz offre un modo interattivo per visualizzare le diverse dimensioni dei blocchi e i valori di sovrapposizione dei blocchi con i separatori di caratteri di Langchain influiscono sui blocchi risultanti.
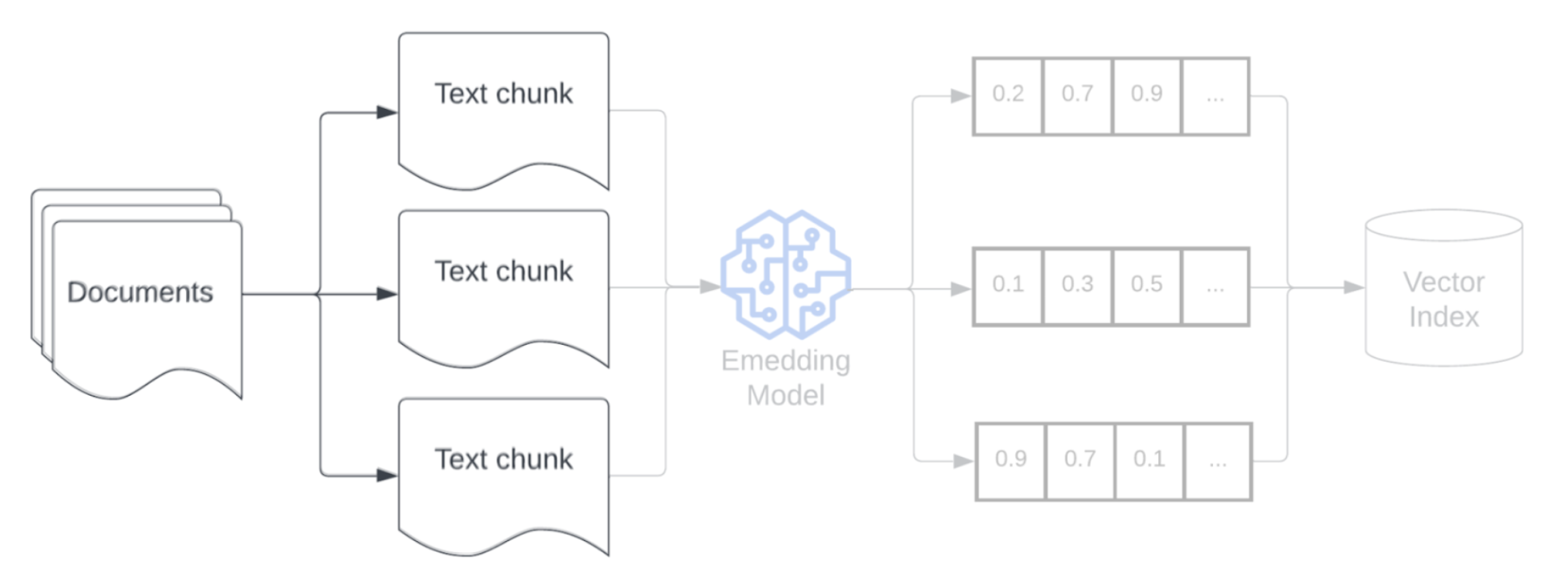
Incorporazione
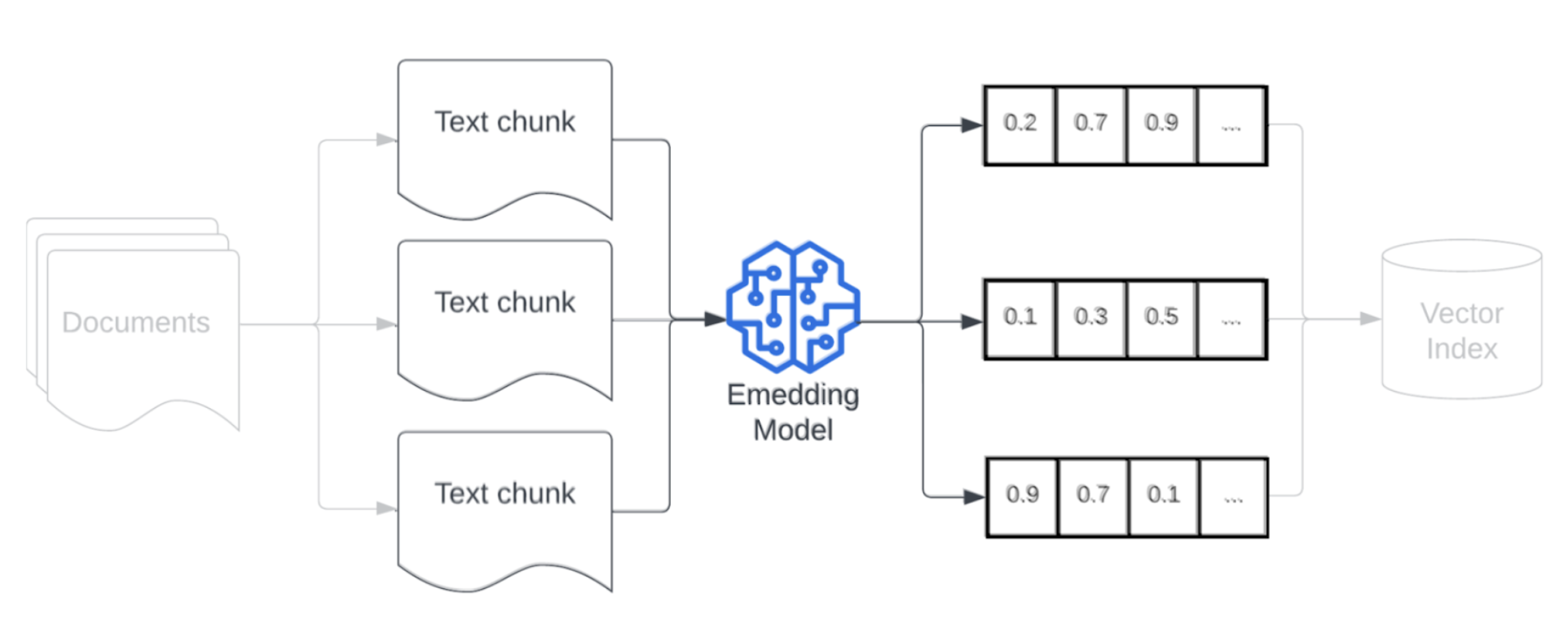
Dopo la suddivisione in blocchi dei dati, il passaggio successivo consiste nel convertire i blocchi di testo in una rappresentazione vettoriale usando un modello di incorporamento. Un modello di incorporamento converte ogni blocco di testo in una rappresentazione vettoriale che ne acquisisce il significato semantico. Rappresentando blocchi come vettori densi, gli incorporamenti consentono il recupero rapido e accurato dei blocchi più rilevanti in base alla loro somiglianza semantica a una query di recupero. La query di estrazione verrà trasformata al momento dell'interrogazione usando lo stesso modello di embedding usato per incorporare blocchi nella pipeline dei dati.
Quando si seleziona un modello di incorporamento, considerare i seguenti fattori:
- scelta del modello: Ogni modello di incorporamento presenta sfumature e i benchmark disponibili potrebbero non acquisire le caratteristiche specifiche dei dati. È fondamentale selezionare un modello sottoposto a training su dati simili. Può anche essere utile esplorare tutti i modelli di incorporamento disponibili progettati per attività specifiche. Sperimentare diversi modelli di incorporamento pronti all’uso, anche quelli che possono avere una posizione bassa in classifiche standard come MTEB. Alcuni esempi da considerare:
- Token massimi: Conoscere il limite massimo di token per il modello di incorporamento scelto. Se si passano blocchi che superano questo limite, essi verranno troncati, perdendo potenzialmente informazioni importanti. Ad esempio, bge-large-en-v1.5 ha un limite massimo di token pari a 512.
- Dimensioni del modello: modelli di incorporamento di dimensioni maggiori in genere offrono prestazioni migliori, ma richiedono più risorse di calcolo. In base al caso d'uso specifico e alle risorse disponibili, sarà necessario bilanciare le prestazioni e l'efficienza.
- Ottimizzazione fine: Se l'applicazione RAG si occupa di linguaggio specifico del dominio (ad esempio acronimi o terminologia della società interna), è consigliabile ottimizzare il modello di incorporamento su dati specifici del dominio. Questo può aiutare il modello a acquisire meglio le sfumature e la terminologia del dominio specifico e spesso può portare a migliorare le prestazioni di recupero.
l'indicizzazione e l'archiviazione
Il passaggio successivo della pipeline consiste nel creare indici sugli incorporamenti e sui metadati generati nei passaggi precedenti. Questa fase prevede l'organizzazione di incorporamenti di vettori altamente dimensionali in strutture di dati efficienti che consentono ricerche di somiglianza veloci e accurate.
Mosaic AI Vector Search usa le tecniche di indicizzazione più recenti quando si distribuisce un endpoint di ricerca vettoriale e un indice per garantire ricerche rapide ed efficienti per le query di ricerca vettoriale. Non è necessario preoccuparsi di testare e scegliere le tecniche di indicizzazione migliori.
Dopo aver compilato e distribuito l'indice, è pronto per l'archiviazione in un sistema che supporta query scalabili e a bassa latenza. Per le pipeline RAG di produzione con set di dati di grandi dimensioni, usare un database vettoriale o un servizio di ricerca scalabile per garantire bassa latenza e velocità effettiva elevata. Archiviare metadati aggiuntivi insieme agli incorporamenti per consentire un filtro efficiente durante il recupero.