Principi guida per il lago
I principi guida sono regole di livello zero che definiscono e influenzano l'architettura. Per creare un data lakehouse che consenta al business di avere successo in futuro e in futuro, il consenso tra gli stakeholder dell'organizzazione è fondamentale.
Curare i dati e offrire dati attendibili come prodotti
La cura dei dati è essenziale per creare un data lake di alto valore per BI e ML/INTELLIGENZa artificiale. Gestire i dati come un prodotto con una definizione, uno schema e un ciclo di vita chiari. Garantire la coerenza semantica e che la qualità dei dati migliora da livello a livello in modo che gli utenti aziendali possano considerare completamente attendibili i dati.
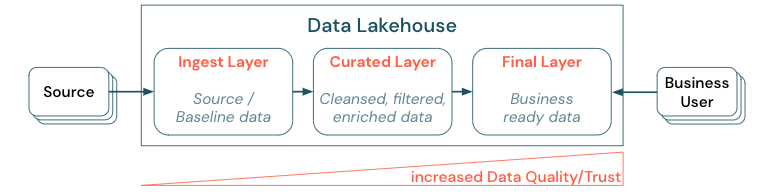
La cura dei dati stabilendo un'architettura a più livelli (o multi hop) è una procedura consigliata fondamentale per il lakehouse, in quanto consente ai team di dati di strutturare i dati in base ai livelli di qualità e definire ruoli e responsabilità per ogni livello. Un approccio di layering comune è:
- Livello inserimento: i dati di origine vengono inseriti nel lakehouse nel primo livello e devono essere mantenuti. Quando tutti i dati downstream vengono creati dal livello di inserimento, è possibile ricompilare i livelli successivi da questo livello, se necessario.
- Livello curato: lo scopo del secondo livello è mantenere i dati puliti, raffinati, filtrati e aggregati. L'obiettivo di questo livello è fornire una base solida e affidabile per le analisi e i report in tutti i ruoli e le funzioni.
- Livello finale: il terzo livello viene creato in base alle esigenze aziendali o di progetto; fornisce una visualizzazione diversa come prodotti dati ad altre business unit o progetti, preparando i dati in base alle esigenze di sicurezza (ad esempio, dati anonimi) o ottimizzando le prestazioni (con visualizzazioni preaggregate). I prodotti di dati in questo livello sono considerati la verità per l'azienda.
Le pipeline in tutti i livelli devono garantire che vengano soddisfatti vincoli di qualità dei dati, ovvero che i dati siano accurati, completi, accessibili e coerenti in qualsiasi momento, anche durante letture e scritture simultanee. La convalida dei nuovi dati avviene al momento dell'immissione dei dati nel livello curato e i passaggi ETL seguenti funzionano per migliorare la qualità di questi dati. La qualità dei dati deve migliorare man mano che i dati progredisce attraverso i livelli e, di conseguenza, la fiducia nei dati aumenta successivamente dal punto di vista aziendale.
Eliminare i silo di dati e ridurre al minimo lo spostamento dei dati
Non creare copie di un set di dati con processi aziendali basati su queste copie diverse. Le copie possono diventare silo di dati che non vengono sincronizzate, causando una qualità inferiore del data lake e infine informazioni obsolete o non corrette. Inoltre, per la condivisione dei dati con partner esterni, usare un meccanismo di condivisione aziendale che consente l'accesso diretto ai dati in modo sicuro.
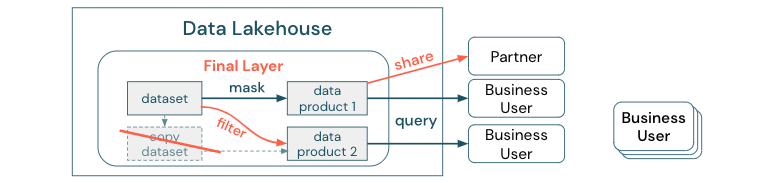
Per rendere chiara la distinzione tra una copia dei dati e un silo di dati: una copia autonoma o throwaway dei dati non è dannosa da sola. A volte è necessario aumentare l'agilità, la sperimentazione e l'innovazione. Tuttavia, se queste copie diventano operative con prodotti dati aziendali downstream dipendenti da essi, diventano silo di dati.
Per evitare i silo di dati, i team di dati in genere tentano di creare un meccanismo o una pipeline di dati per mantenere tutte le copie sincronizzate con l'originale. Poiché è improbabile che ciò accada in modo coerente, la qualità dei dati alla fine peggiora. Ciò può anche causare costi più elevati e una perdita significativa di fiducia da parte degli utenti. D'altra parte, diversi casi d'uso aziendali richiedono la condivisione dei dati con partner o fornitori.
Un aspetto importante consiste nel condividere in modo sicuro e affidabile la versione più recente del set di dati. Le copie del set di dati spesso non sono sufficienti perché possono uscire dalla sincronizzazione rapidamente. I dati devono invece essere condivisi tramite strumenti di condivisione dei dati aziendali.
Democratizzare la creazione di valore tramite self-service
Il data lake migliore non può fornire un valore sufficiente, se gli utenti non possono accedere facilmente alla piattaforma o ai dati per le attività BI e ML/AI. Ridurre le barriere all'accesso ai dati e alle piattaforme per tutte le business unit. Considerare i processi di gestione dei dati snella e fornire l'accesso self-service per la piattaforma e i dati sottostanti.
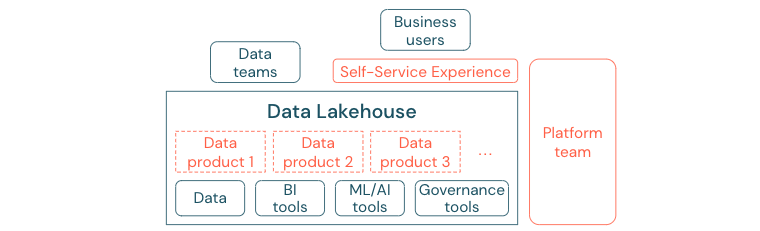
Le aziende che si sono trasferite correttamente in una cultura basata sui dati prospereranno. Ciò significa che ogni business unit deriva le proprie decisioni dai modelli analitici o dall'analisi dei propri dati forniti centralmente o . Per i consumer, i dati devono essere facilmente individuabili e accessibili in modo sicuro.
Un buon concetto per i produttori di dati è "dati come prodotto": i dati vengono offerti e gestiti da una business unit o da un partner commerciale come un prodotto e utilizzati da altre parti con un controllo delle autorizzazioni appropriato. Invece di affidarsi a un team centrale e a processi di richiesta potenzialmente lenti, questi prodotti dati devono essere creati, offerti, individuati e utilizzati in un'esperienza self-service.
Tuttavia, non sono solo i dati importanti. La democratizzazione dei dati richiede gli strumenti giusti per consentire a tutti di produrre o utilizzare e comprendere i dati. Per questo motivo, è necessario che data lakehouse sia una piattaforma di dati e intelligenza artificiale moderna che fornisce l'infrastruttura e gli strumenti per la creazione di prodotti dati senza duplicare lo sforzo di configurare un altro stack di strumenti.
Adottare una strategia di governance dei dati a livello di organizzazione
I dati sono un asset fondamentale di qualsiasi organizzazione, ma non è possibile concedere a tutti l'accesso a tutti i dati. L'accesso ai dati deve essere gestito attivamente. Il controllo di accesso, il controllo e il rilevamento della derivazione sono fondamentali per l'uso corretto e sicuro dei dati.
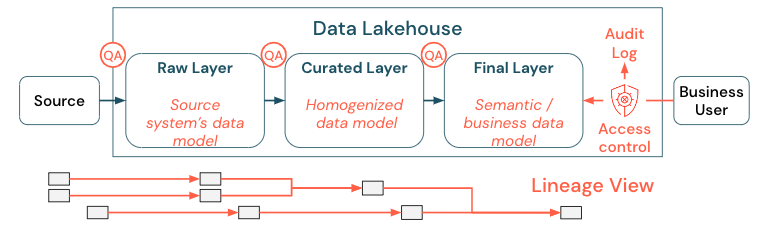
La governance dei dati è un argomento generale. Il lago copre le dimensioni seguenti:
Qualità dei dati
I prerequisiti più importanti per i report corretti e significativi, i risultati dell'analisi e i modelli sono dati di alta qualità. Il controllo di qualità (QA) deve esistere intorno a tutti i passaggi della pipeline. Esempi di come implementare questo tipo di implementazione includono contratti dati, contratti di servizio, mantenere stabili gli schemi e evolverli in modo controllato.
Catalogo dati
Un altro aspetto importante è l'individuazione dei dati: gli utenti di tutte le aree aziendali, in particolare in un modello self-service, devono essere in grado di individuare facilmente i dati pertinenti. Pertanto, un lakehouse necessita di un catalogo dati che copre tutti i dati rilevanti per l'azienda. Gli obiettivi principali di un catalogo dati sono i seguenti:
- Assicurarsi che lo stesso concetto aziendale venga chiamato in modo uniforme e dichiarato in tutta l'azienda. È possibile considerarlo come un modello semantico nel livello curato e finale.
- Tenere traccia della derivazione dei dati esattamente in modo che gli utenti possano spiegare come questi dati sono arrivati alla forma e al modulo correnti.
- Mantenere metadati di alta qualità, che è importante quanto i dati stessi per un uso appropriato dei dati.
Controllo di accesso
Poiché il valore creato dai dati nella lakehouse avviene in tutte le aree aziendali, la lakehouse deve essere costruita con sicurezza come cittadino di prima classe. Le aziende potrebbero avere criteri di accesso ai dati più aperti o rispettare rigorosamente il principio dei privilegi minimi. Indipendentemente da questo, i controlli di accesso ai dati devono essere applicati in ogni livello. È importante implementare schemi di autorizzazione di livello fine fin dall'inizio (controllo di accesso a livello di riga e colonna, controllo degli accessi in base al ruolo o basato su attributi). Le aziende possono iniziare con regole meno rigide. Tuttavia, man mano che la piattaforma lakehouse cresce, tutti i meccanismi e i processi per un regime di sicurezza più sofisticato dovrebbero essere già presenti. Inoltre, tutti gli accessi ai dati nel lakehouse devono essere regolati dai log di controllo dal get-go.
Incoraggiare interfacce aperte e formati aperti
Le interfacce aperte e i formati di dati sono fondamentali per l'interoperabilità tra lakehouse e altri strumenti. Semplifica l'integrazione con i sistemi esistenti e apre anche un ecosistema di partner che hanno integrato i propri strumenti con la piattaforma.
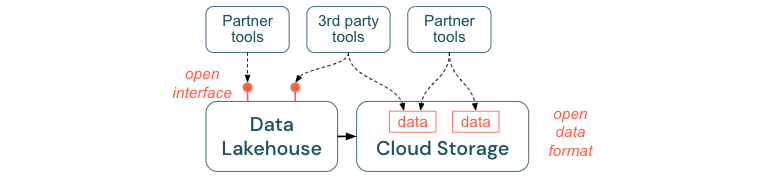
Le interfacce aperte sono fondamentali per abilitare l'interoperabilità e impedire la dipendenza da qualsiasi singolo fornitore. Tradizionalmente, i fornitori hanno creato tecnologie proprietarie e interfacce chiuse che limitano le aziende nel modo in cui possono archiviare, elaborare e condividere i dati.
La creazione di interfacce aperte consente di creare per il futuro:
- Aumenta la longevità e la portabilità dei dati in modo da poterli usare con più applicazioni e per altri casi d'uso.
- Apre un ecosistema di partner che possono sfruttare rapidamente le interfacce aperte per integrare i propri strumenti nella piattaforma lakehouse.
Infine, standardizzando i formati aperti per i dati, i costi totali saranno significativamente inferiori; è possibile accedere ai dati direttamente nell'archiviazione cloud senza la necessità di inviarli tramite una piattaforma proprietaria che può comportare costi elevati di uscita e calcolo.
Compilazione per ridimensionare e ottimizzare le prestazioni e i costi
I dati continuano inevitabilmente a crescere e diventano più complessi. Per equipaggiare l'organizzazione per esigenze future, il lakehouse dovrebbe essere in grado di ridimensionare. Ad esempio, dovrebbe essere possibile aggiungere facilmente nuove risorse su richiesta. I costi devono essere limitati al consumo effettivo.
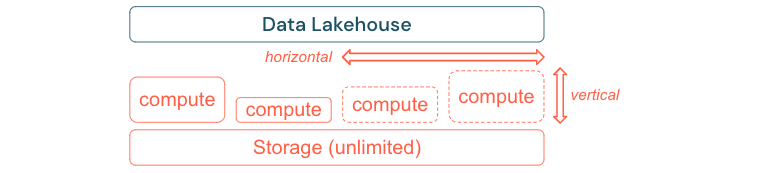
I processi ETL standard, i report aziendali e i dashboard hanno spesso una necessità di risorse prevedibili dal punto di vista della memoria e del calcolo. Tuttavia, nuovi progetti, attività stagionali o approcci moderni, ad esempio il training del modello (varianza, previsione, manutenzione) generano picchi di necessità di risorse. Per consentire a un'azienda di eseguire tutti questi carichi di lavoro, è necessaria una piattaforma scalabile per la memoria e il calcolo. Le nuove risorse devono essere aggiunte facilmente su richiesta e solo il consumo effettivo deve generare costi. Non appena il picco è finito, le risorse possono essere liberate di nuovo e i costi sono ridotti di conseguenza. Spesso, questo viene definito ridimensionamento orizzontale (meno o più nodi) e ridimensionamento verticale (nodi più grandi o più piccoli).
Il ridimensionamento consente anche alle aziende di migliorare le prestazioni delle query selezionando nodi con più risorse o cluster con più nodi. Tuttavia, invece di fornire in modo permanente computer e cluster di grandi dimensioni, è possibile eseguirne il provisioning su richiesta solo per il tempo necessario per ottimizzare il rapporto tra prestazioni complessive e costi. Un altro aspetto dell'ottimizzazione è l'archiviazione rispetto alle risorse di calcolo. Poiché non esiste una chiara relazione tra il volume dei dati e i carichi di lavoro che usano questi dati (ad esempio, usando solo parti dei dati o eseguendo calcoli intensivi su dati di piccole dimensioni), è consigliabile stabilire una piattaforma dell'infrastruttura che disaccoppi l'archiviazione e le risorse di calcolo.