Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'architettura medallion descrive una serie di livelli di dati che indicano la qualità dei dati archiviati nella lakehouse. Azure Databricks consiglia di adottare un approccio a più livelli per creare un'unica origine di verità per i prodotti dati aziendali.
Questa architettura garantisce atomicità, coerenza, isolamento e durabilità quando i dati passano attraverso più livelli di convalida e trasformazioni prima di essere archiviati in un layout ottimizzato per l'analisi efficiente. I termini bronzo (crudo), argento (convalidato) e oro (arricchito) descrivono la qualità dei dati in ognuno di questi livelli.
Architettura medallion come modello di progettazione dei dati
Un'architettura medallion è un modello di progettazione dei dati usato per organizzare i dati in modo logico. L'obiettivo è quello di migliorare in modo incrementale e progressivo la struttura e la qualità dei dati man mano che fluiscono attraverso ogni livello dell'architettura (dallo strato Bronze ⇒ Silver ⇒ Gold). Le architetture medallion sono talvolta definite anche come architetture multi hop.
Grazie all'avanzamento dei dati attraverso questi livelli, le organizzazioni possono migliorare in modo incrementale la qualità e l'affidabilità dei dati, rendendoli più adatti alle applicazioni di Business Intelligence e Machine Learning.
Seguire l'architettura medallion è una procedura consigliata, ma non un requisito.
| Domanda | Bronzo | Argento | Oro |
|---|---|---|---|
| Cosa accade in questo livello? | Inserimento dati non elaborati | Pulizia e convalida dei dati | Modellazione dimensionale e aggregazione |
| Chi è l'utente desiderato? |
|
|
|
Architettura medaglione di esempio
Questo esempio di architettura a medaglione mostra i livelli di bronzo, argento e oro per l'uso da parte di un team delle operazioni aziendali. Ogni livello viene archiviato in uno schema diverso del catalogo delle operazioni.
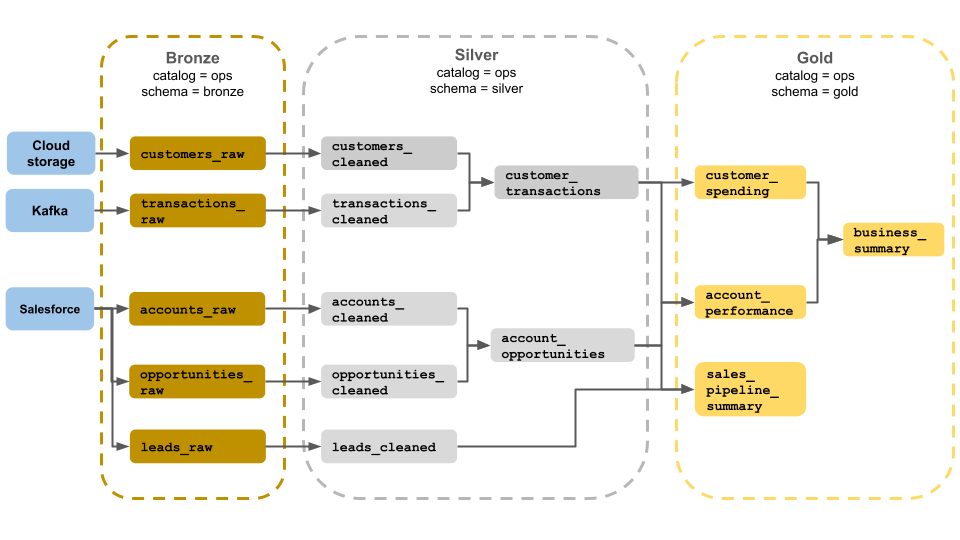
-
Livello bronzo (
ops.bronze): inserisce dati non elaborati dall'archiviazione cloud, Kafka e Salesforce. Non viene eseguita alcuna pulizia o convalida dei dati qui. -
Livello Silver (
ops.silver): la pulizia e la convalida dei dati vengono eseguite in questo livello.- I dati relativi a clienti e transazioni vengono puliti eliminando i valori Null e mettendo in quarantena record non validi. Questi set di dati vengono uniti in un nuovo set di dati denominato
customer_transactions. I data scientist possono usare questo set di dati per l'analisi predittiva. - Analogamente, gli account e i set di dati delle opportunità di Salesforce vengono uniti per creare
account_opportunities, che viene migliorato con le informazioni sull'account. - I
leads_rawdati vengono puliti in un set di dati denominatoleads_cleaned.
- I dati relativi a clienti e transazioni vengono puliti eliminando i valori Null e mettendo in quarantena record non validi. Questi set di dati vengono uniti in un nuovo set di dati denominato
-
Livello gold (
ops.gold): questo livello è progettato per gli utenti aziendali. Contiene meno set di dati rispetto all'argento e all'oro.-
customer_spending: media e spesa totale per ogni cliente. -
account_performance: Rendimento giornaliero per ogni account. -
sales_pipeline_summary: Informazioni sulla pipeline di vendita completa. -
business_summary: informazioni altamente aggregate per il personale esecutivo.
-
Inserire dati non elaborati nello strato di bronzo
Il livello bronzo contiene dati grezzi e non convalidati. I dati inseriti nello strato bronzo hanno in genere le caratteristiche seguenti:
- Contiene e mantiene lo stato non elaborato dell'origine dati nei formati originali.
- Viene accodato in modo incrementale e si sviluppa nel corso del tempo.
- È destinato all'utilizzo da parte di carichi di lavoro che arricchiscono i dati per le tabelle silver, non per l'accesso da parte di analisti e data scientist.
- Funge da singola fonte di verità, mantenendo la fedeltà dei dati.
- Consente di rielaborare e controllare conservando tutti i dati cronologici.
- Può essere qualsiasi combinazione di transazioni in streaming e batch provenienti da fonti, tra cui l'archiviazione di oggetti cloud (ad esempio, S3, GCS, ADLS), i bus di messaggi (ad esempio, Kafka, Kinesis, ecc.) e i sistemi federati (ad esempio, Lakehouse Federation).
Limitare la pulizia o la convalida dei dati
La convalida minima dei dati viene eseguita nel livello bronzo. Per garantire la protezione dai dati eliminati, Azure Databricks consiglia di archiviare la maggior parte dei campi come stringa, VARIANT o binaria per proteggersi da modifiche impreviste dello schema. È possibile aggiungere colonne di metadati, ad esempio la provenienza o l'origine dei dati , ad esempio _metadata.file_name .
Convalidare e deduplicare i dati nel livello Silver
La pulizia e la convalida dei dati vengono eseguite nel livello argento.
Creare tabelle d'argento dal livello bronzo
Per costruire il livello silver, leggere i dati da una o più tabelle bronze o silver e scrivere i dati nelle tabelle silver.
Azure Databricks non consiglia di scrivere in tabelle silver direttamente dalla fase di inserimento. Se si scrive direttamente dall'inserimento, si presenteranno errori a causa di modifiche dello schema o record danneggiati nelle origini dati. Supponendo che tutte le origini siano di sola accodamento, configurare la maggior parte delle letture dal bronzo come letture in streaming. Le letture batch devono essere riservate per set di dati di piccole dimensioni, ad esempio tabelle dimensionali di piccole dimensioni.
Il livello silver rappresenta versioni convalidate, pulite e arricchite dei dati. Livello argento:
- Deve includere sempre almeno una rappresentazione non aggregata convalidata di ogni record. Se le rappresentazioni aggregate determinano molti carichi di lavoro downstream, tali rappresentazioni potrebbero trovarsi nel livello silver, ma in genere si trovano nel livello oro.
- Dove si esegue la pulizia, la deduplicazione e la normalizzazione dei dati.
- Migliora la qualità dei dati correggendo errori e incoerenze.
- Struttura i dati in un formato più utilizzabile per l'elaborazione downstream.
Garantire la qualità dei dati
Le operazioni seguenti vengono eseguite in tabelle silver:
- Applicazione dello schema
- Gestione di valori nulli e mancanti
- Deduplicazione dati
- Risoluzione dei problemi di dati non in ordine e in ritardo
- Controlli e applicazione della qualità dei dati
- Evoluzione dello schema
- Conversione di tipi
- Giunzioni
Avviare la modellazione dei dati
È comune iniziare a eseguire la modellazione dei dati nel livello silver, inclusa la scelta di come rappresentare dati fortemente annidati o semistrutturati:
- Usare il
VARIANTtipo di dati. - Usare
JSONstringhe. - Creare struct, mappe e matrici.
- Rendere flat lo schema o normalizzare i dati in più tabelle.
Analisi di potenza con il livello oro
Il livello oro rappresenta visualizzazioni estremamente perfezionate dei dati che guidano analisi downstream, dashboard, apprendimento automatico e applicazioni. I dati del livello Gold sono spesso altamente aggregati e filtrati per periodi di tempo specifici o aree geografiche. Contiene set di dati semanticamente significativi che eseguono il mapping alle funzioni e alle esigenze aziendali.
Lo strato d'oro:
- È costituito da dati aggregati personalizzati per l'analisi e la creazione di report.
- Allinea alla logica aziendale e ai requisiti.
- È ottimizzato per le prestazioni nelle query e nei dashboard.
Allinearsi alla logica di business e ai requisiti
Il livello oro è il punto in cui si modellano i dati per la creazione di report e l'analisi usando un modello dimensionale stabilendo le relazioni e definendo le misure. Gli analisti con accesso ai dati in oro dovrebbero essere in grado di trovare dati specifici del dominio e rispondere a domande.
Poiché il livello gold modella un dominio aziendale, alcuni clienti creano più livelli gold per soddisfare esigenze aziendali diverse, ad esempio risorse umane, finanza e IT.
Creare aggregazioni personalizzate per l'analisi e la creazione di report
Spesso le organizzazioni devono creare funzioni di aggregazione per misure come medie, conteggi, valori massimi e minimi. Ad esempio, se l'azienda deve rispondere a domande sulle vendite settimanali totali, è possibile creare una vista materializzata denominata weekly_sales che preaggrega questi dati in modo che gli analisti e altri utenti non debbano ricreare visualizzazioni materializzate usate di frequente.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
Ottimizzare le prestazioni nelle query e nei dashboard
L'ottimizzazione delle tabelle gold-layer per le prestazioni è una procedura consigliata perché questi set di dati vengono spesso sottoposti a query. Grandi quantità di dati cronologici sono in genere accessibili nel livello sliver e non materializzati nello strato oro.
Controllare i costi modificando la frequenza di inserimento dei dati
Controllare i costi determinando la frequenza di inserimento dei dati.
| Frequenza di inserimento dati | Costo | Latenza | Esempi dichiarativi | Esempi procedurali |
|---|---|---|---|---|
| Inserimento incrementale continuo | Più alto | Inferiore |
|
|
| Inserimento incrementale attivato | Inferiore | Più alto |
|
|
| Inserimento in blocchi con incremento manuale | Inferiore | Massimo, per via di esecuzioni poco frequenti. |
|