Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Una tabella Streaming è una tabella Delta con supporto aggiuntivo per l'elaborazione di dati in streaming o incrementale. Una tabella di streaming può essere destinata a uno o più flussi in una pipeline.
Le tabelle di streaming sono una scelta ottimale per l'inserimento dei dati per i motivi seguenti:
- Ogni riga di input viene gestita una sola volta, un approccio che rispecchia la stragrande maggioranza dei carichi di lavoro di inserimento, ovvero l'aggiunta o l'aggiornamento delle righe in una tabella.
- Possono gestire grandi volumi di dati solo accodabili.
Le tabelle di streaming sono anche una buona scelta per le trasformazioni di streaming a bassa latenza, perché possono ragionare su righe e finestre di tempo, gestire volumi elevati di dati e offrire un'elaborazione a bassa latenza.
Il diagramma seguente mostra come i flussi leggono da origini di streaming e scrivono in modo incrementale in una tabella di streaming all'interno di una pipeline.
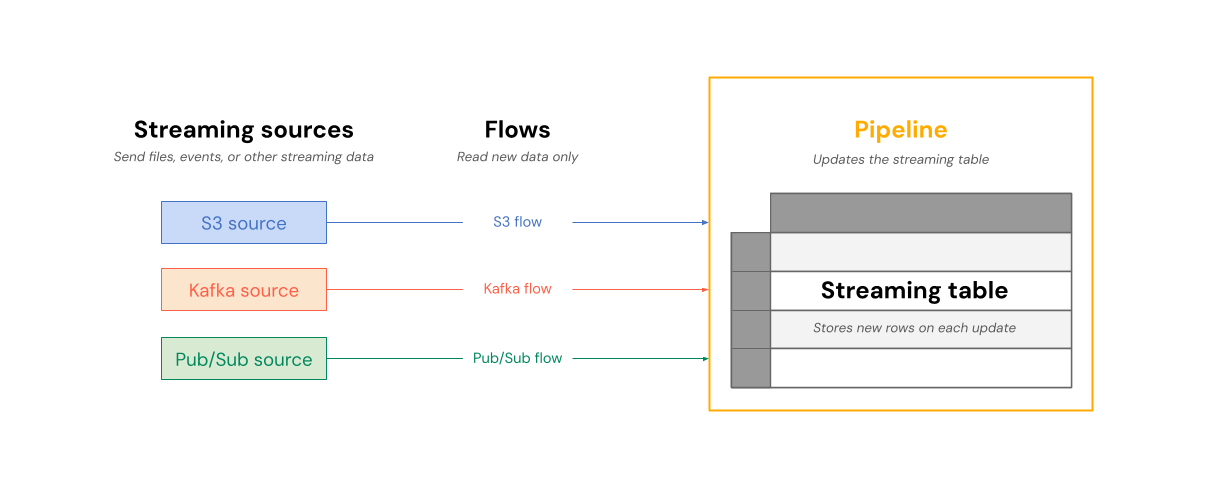
In ogni aggiornamento, i flussi associati a una tabella di streaming leggono le informazioni modificate in un'origine di streaming e aggiungono nuove informazioni a tale tabella.
Le tabelle di streaming sono di proprietà e aggiornate da una singola pipeline. Le tabelle di streaming vengono definite in modo esplicito nel codice sorgente della pipeline. Le tabelle definite da una pipeline non possono essere modificate o aggiornate da altre pipeline. È possibile definire più flussi da aggiungere a una singola tabella di streaming.
Azure Databricks crea tabelle interne per supportare l'elaborazione delle tabelle di streaming. Queste tabelle vengono visualizzate in system.information_schema.tables ma non sono visibili in Esplora cataloghi o in altre pagine dell'interfaccia utente dell'area di lavoro.
Annotazioni
Quando si crea una tabella di streaming all'esterno di una pipeline usando Databricks SQL, Azure Databricks crea una pipeline usata per aggiornare la tabella. È possibile visualizzare la pipeline selezionando ETL. Le tabelle di streaming create in Databricks SQL hanno un tipo di MV/ST.
Per altre informazioni sui flussi, vedere Caricare ed elaborare i dati in modo incrementale con i flussi dichiarativi di Lakeflow Spark.
Tabelle di streaming per l'inserimento
Le tabelle di streaming sono progettate per origini dati di sola aggiunta e processano gli input una sola volta. Ciò li rende particolarmente adatti per i carichi di lavoro di inserimento in cui i dati arrivano continuamente e devono essere acquisiti in modo affidabile senza rielaborare i record esistenti. Azure Databricks supporta l'inserimento di dati dall'archiviazione cloud e dai bus di messaggi in streaming.
Inserire file dall'archiviazione cloud
È possibile usare una tabella di streaming per inserire nuovi file dall'archiviazione cloud. Questi esempi usano il caricatore automatico per elaborare in modo incrementale i nuovi file non appena arrivano.
Pitone
from pyspark import pipelines as dp
# Create a streaming table
@dp.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
Per creare una tabella di streaming, la definizione del set di dati deve essere un tipo di flusso. Quando si usa la spark.readStream funzione in una definizione di set di dati, restituisce un set di dati di streaming.
SQL
-- Create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
Le tabelle di streaming richiedono set di dati di streaming. La STREAM parola chiave prima read_files indica alla query di considerare il set di dati come flusso.
Inserire messaggi in streaming
È anche possibile usare le tabelle di streaming per inserire dati dai bus di messaggi. Nell'esempio seguente viene illustrato come creare una tabella di streaming che legge da un argomento Pub/Sub.
Pitone
@dp.table
def pubsub_raw():
auth_options = {
"clientId": client_id,
"clientEmail": client_email,
"privateKey": private_key,
"privateKeyId": private_key_id
}
return (
spark.readStream
.format("pubsub")
.option("subscriptionId", "my-subscription")
.option("topicId", "my-topic")
.option("projectId", "my-project")
.options(auth_options)
.load()
)
SQL
CREATE OR REFRESH STREAMING TABLE pubsub_raw
AS SELECT * FROM STREAM read_pubsub(
subscriptionId => 'my-subscription',
projectId => 'my-project',
topicId => 'my-topic',
clientEmail => secret('pubsub-scope', 'clientEmail'),
clientId => secret('pubsub-scope', 'clientId'),
privateKeyId => secret('pubsub-scope', 'privateKeyId'),
privateKey => secret('pubsub-scope', 'privateKey')
);
Databricks consiglia di usare i segreti quando si forniscono opzioni di autorizzazione. Per tutte le opzioni di autenticazione, vedere Configurare l'accesso a Pub/Sub .
Per altre informazioni sul caricamento dei dati nella tabella di streaming, vedere Caricare i dati nelle pipeline.
Il diagramma seguente illustra il funzionamento delle tabelle di streaming solo append.

Una riga che è già stata aggiunta a una tabella di streaming non verrà consultata nuovamente con gli aggiornamenti successivi nella pipeline. Se si modifica la query , ad esempio da SELECT LOWER (name) a SELECT UPPER (name), le righe esistenti non verranno aggiornate in lettere maiuscole, ma le nuove righe saranno maiuscole. È possibile attivare un aggiornamento completo per rieseguire una query su tutti i dati precedenti della tabella di origine per aggiornare tutte le righe nella tabella Streaming.
Tabelle in streaming e streaming a bassa latenza
Le tabelle di streaming sono progettate per lo streaming a bassa latenza con uno stato delimitato. Le tabelle di streaming usano la gestione dei checkpoint, che li rende particolarmente adatti per lo streaming a bassa latenza. Tuttavia, si aspettano flussi che sono naturalmente delimitati o delimitati con una filigrana.
Un flusso naturalmente delimitato viene prodotto da una sorgente di dati di streaming che ha un inizio e una fine ben definiti. Un esempio di flusso delimitato naturalmente è la lettura dei dati da una directory di file in cui non vengono aggiunti nuovi file dopo l'inserimento di un batch iniziale di file. Il flusso viene considerato delimitato perché il numero di file è finito e il flusso termina dopo l'elaborazione di tutti i file.
È anche possibile usare una filigrana per delimitare un flusso. Una filigrana in Structured Streaming è un meccanismo che consente di gestire i dati in ritardo specificando per quanto tempo il sistema deve attendere gli eventi ritardati prima di considerare l'intervallo di tempo come completato. Un flusso illimitato che non dispone di una filigrana può causare un fallimento della pipeline a causa della pressione della memoria.
Per altre informazioni sull'elaborazione del flusso con stato, vedere Ottimizzare l'elaborazione con stato con filigrane.
Join tra flusso e snapshot
I join di snapshot di flusso connettono un set di dati di streaming a una tabella delle dimensioni snapshotta all'avvio del flusso. Poiché la tabella delle dimensioni viene considerata fissa in quel momento, tutte le modifiche apportate dopo l'avvio del flusso non vengono riflesse nel join. Ciò è accettabile quando piccole discrepanze non sono importanti, ad esempio quando il numero di transazioni è molti ordini di grandezza superiore al numero di clienti.
L'esempio di codice seguente unisce una tabella delle dimensioni con due righe chiamate customers con un set di dati in continua crescita, transactions. Materializza un join tra questi due set di dati in una tabella denominata sales_report. Se un processo esterno aggiorna la tabella customers aggiungendo una nuova riga (customer_id=3, name=Zoya), questa nuova riga non sarà presente nel join perché la tabella delle dimensioni statiche è stata snapshotata all'avvio dei flussi.
from pyspark import pipelines as dp
@dp.temporary_view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dp.temporary_view
def v_customers():
return spark.read.table("customers")
@dp.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return facts.join(dims, on="customer_id", how="inner")
Limitazioni delle tabelle di streaming
Le tabelle di streaming presentano le limitazioni seguenti:
-
Evoluzione limitata: È possibile modificare la query senza ricompilare l'intero set di dati. Senza un aggiornamento completo, una tabella di streaming vede ogni riga una sola volta, quindi query diverse avranno elaborato righe diverse. Ad esempio, se si aggiunge
UPPER()a un campo nella query, solo le righe elaborate dopo la modifica saranno maiuscole. Ciò significa che è necessario essere consapevoli di tutte le versioni precedenti della query in esecuzione nel set di dati. Per rielaborare le righe esistenti elaborate prima della modifica, è necessario un aggiornamento completo. - Gestione dello stato: Le tabelle di streaming sono a bassa latenza e richiedono flussi naturalmente delimitati o delimitati da una filigrana. Per altre informazioni, vedere Ottimizzare l'elaborazione con stato con filigrane.
- I join non vengono ricalcolati: I join nelle tabelle di streaming non vengono ricalcolati quando le dimensioni cambiano. Questa caratteristica può essere utile per scenari "veloci ma non corretti". Se si desidera che la visualizzazione sia sempre corretta, è possibile usare una visualizzazione materializzata. Le viste materializzate sono sempre corrette perché ricompilano automaticamente i join quando le dimensioni cambiano. Per ulteriori informazioni, vedere le viste materializzate .