Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive come MLOps Stacks consente di implementare il processo di sviluppo e distribuzione come codice in un repository controllato dal codice sorgente. Descrive anche i vantaggi dello sviluppo di modelli nella piattaforma Databricks Data Intelligence, una singola piattaforma che unifica ogni passaggio del processo di sviluppo e distribuzione del modello.
Che cos'è MLOps Stacks?
Con gli stack MLOps, l'intero processo di sviluppo del modello viene implementato, salvato e monitorato come codice in un repository controllato dal codice sorgente. L'automazione del processo in questo modo facilita distribuzioni ripetibili, prevedibili e sistematiche e consente l'integrazione con il processo CI/CD. Rappresentare il processo di sviluppo del modello come codice permette di distribuire il codice anziché distribuire il modello. La distribuzione del codice automatizza la possibilità di compilare il modello, semplificando notevolmente il training del modello quando necessario.
Quando si crea un progetto usando MLOps Stacks, si definiscono i componenti del processo di sviluppo e distribuzione di ML, ad esempio i notebook da usare per progettazione di funzionalità, training, test e distribuzione, pipeline per training e test, aree di lavoro da usare per ogni fase e flussi di lavoro CI/CD usando GitHub Actions o Azure DevOps per il test e la distribuzione automatizzati del codice.
L'ambiente creato da MLOps Stacks implementa il flusso di lavoro MLOps consigliato da Databricks. È possibile personalizzare il codice per creare stack in base ai processi o ai requisiti dell'organizzazione.
Come funziona MLOps Stacks?
Si utilizza il CLI di Databricks per creare uno stack MLOps. Per istruzioni passo-passo, vedere Pacchetti di automazione dichiarativa per stack MLOps.
Quando si avvia un progetto MLOps Stacks, il software esegue la procedura per immettere i dettagli di configurazione e quindi crea una directory contenente i file che compongono il progetto. Questa directory, o stack, implementa il flusso di lavoro MLOps di produzione consigliato da Databricks. I componenti visualizzati nel diagramma vengono creati automaticamente ed è necessario modificare solo i file per aggiungere il codice personalizzato.
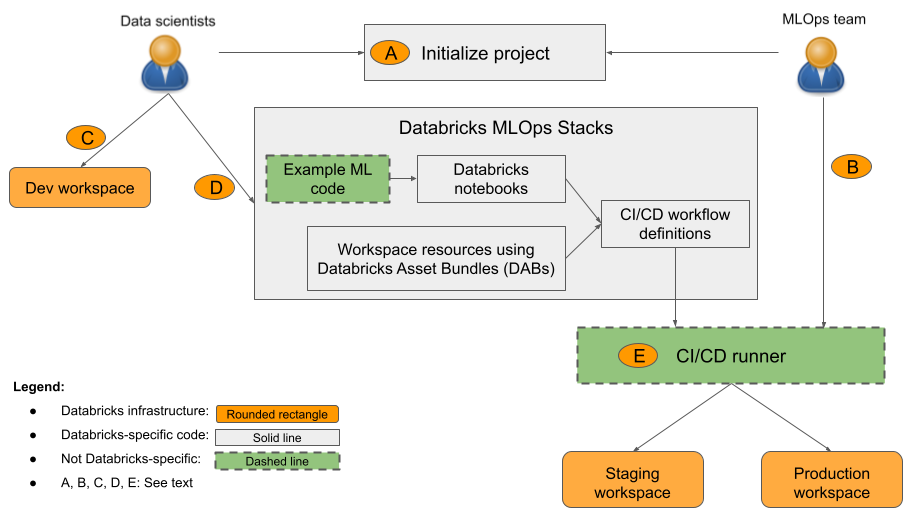
Nel diagramma:
-
R: Un Data Scientist o un ingegnere ML inizializza il progetto usando
databricks bundle init mlops-stacks. Quando si inizializza il progetto, è possibile scegliere di configurare i componenti del codice ml (in genere usati dai data scientist), i componenti CI/CD (in genere usati dai tecnici di MACHINE Learning) o entrambi. - B: Gli ingegneri ML configurano le credenziali del principale del servizio di Databricks per CI/CD.
- C: I data scientist sviluppano modelli in Databricks o nel sistema locale.
- D: I data scientist creano richieste pull per aggiornare il codice di Machine Learning.
- E: Il runner CI/CD esegue notebook, crea processi ed esegue altre attività nelle aree di lavoro staging e di produzione.
L'organizzazione può usare lo stack predefinito o personalizzarlo in base alle esigenze per aggiungere, rimuovere o modificare i componenti in base alle procedure dell'organizzazione. Per informazioni dettagliate, vedere il file leggimi del repository GitHub
MLOps Stacks è progettato con una struttura modulare per consentire ai diversi team di ML di lavorare in modo indipendente in un progetto, seguendo al tempo stesso le procedure consigliate di progettazione del software e mantenendo ci/CD di livello di produzione. I tecnici di produzione configurano l'infrastruttura di Machine Learning che consente ai data scientist di sviluppare, testare e distribuire pipeline e modelli di MACHINE Learning nell'ambiente di produzione.
Come illustrato nel diagramma, lo stack MLOps predefinito include i tre componenti seguenti:
- Codice ML. MLOps Stacks crea un insieme di modelli per un progetto ML, inclusi notebook per l'addestramento, l'inferenza batch e altro. Il modello standardizzato consente ai data scientist di iniziare rapidamente, unifica la struttura del progetto tra i team e applica codice modularizzato pronto per i test.
- Risorse ML come codice. Gli stack MLOps definiscono risorse come aree di lavoro e pipeline per attività come l'addestramento e l'inferenza batch. Le risorse sono definite in Bundle di automazione dichiarativa per facilitare il test, l'ottimizzazione e il controllo della versione per l'ambiente ML. Ad esempio, è possibile provare un tipo di istanza più grande per l'addestramento automatico del modello e la modifica viene tracciata automaticamente per riferimento futuro.
- CI/CD. È possibile usare GitHub Actions o Azure DevOps per testare e distribuire codice e risorse ml, assicurandosi che tutte le modifiche di produzione vengano eseguite tramite l'automazione e che solo il codice testato venga distribuito a prod.
Flusso del progetto MLOps
Un progetto MLOps Stacks predefinito include una pipeline di Machine Learning con flussi di lavoro CI/CD per testare e distribuire l'addestramento del modello automatizzato e i lavori di inferenza batch negli ambienti di sviluppo, collaudo e produzione Databricks. MLOps Stacks è configurabile, quindi è possibile modificare la struttura del progetto per soddisfare i processi dell'organizzazione.
Il diagramma mostra il processo implementato dallo stack MLOps predefinito. Nell'area di lavoro sviluppo, i data scientist eseggono l'iterazione sul codice di Machine Learning e sulle richieste pull dei file. Le PR attivano unit test e test di integrazione nello spazio di lavoro di staging isolato di Databricks. Quando una richiesta pull viene integrata in main, i processi di training del modello e di inferenza batch eseguiti nell'ambiente di staging vengono immediatamente aggiornati per eseguire il codice più recente. Dopo aver unito una richiesta pull a main, puoi creare un nuovo ramo di rilascio nel processo di rilascio pianificato e distribuire le modifiche al codice nell'ambiente di produzione.
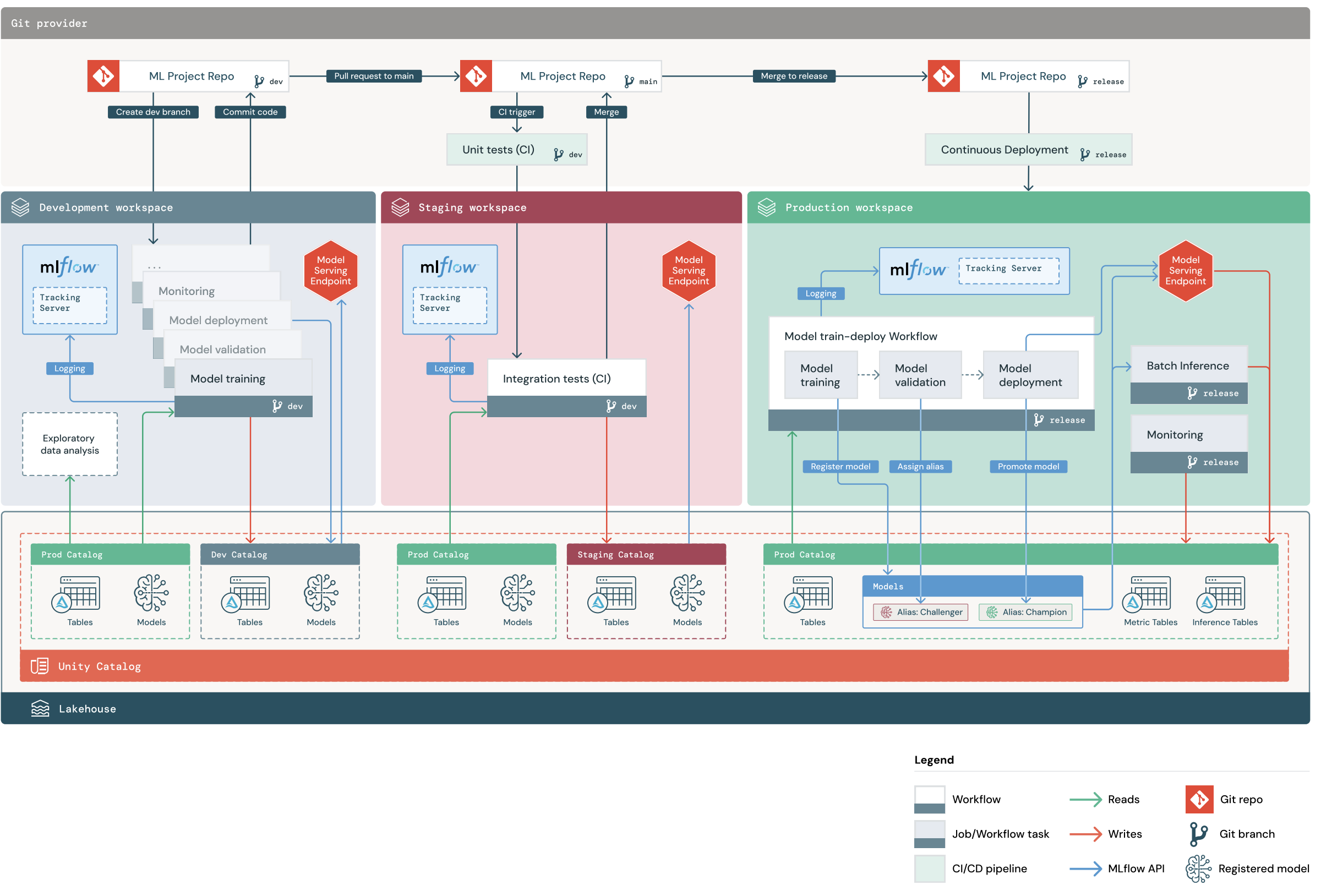
Struttura del progetto MLOps Stacks
Uno stack di MLOps usa pacchetti di automazione dichiarativa, una raccolta di file sorgente che funge da definizione end-to-end di un progetto. Questi file di origine includono informazioni su come devono essere testate e distribuite. La raccolta dei file come bundle semplifica la condivisione delle modifiche alla versione e l'uso di procedure consigliate per la progettazione software, ad esempio controllo del codice, revisione del codice, test e CI/CD.
Il diagramma mostra i file creati per lo stack MLOps predefinito. Per informazioni dettagliate sui file inclusi nello stack, vedere la documentazione sul repository GitHub o sui pacchetti di automazione dichiarativa per gli stack MLOps.
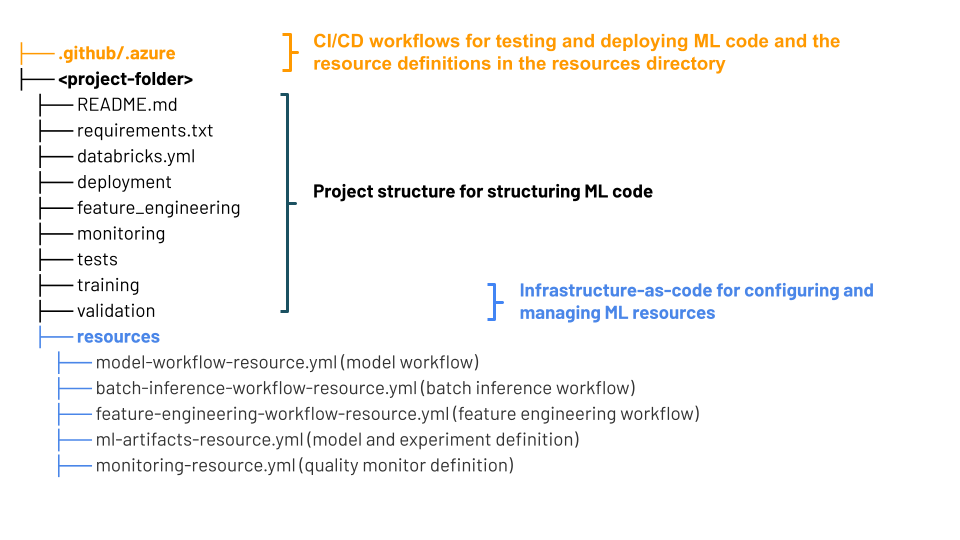
I componenti degli MLOps Stacks
Uno "stack" si riferisce al set di strumenti usati in un processo di sviluppo. Lo stack MLOps predefinito sfrutta la piattaforma databricks unificata e usa gli strumenti seguenti:
| Componente | Strumento in Databricks |
|---|---|
| Codice di sviluppo del modello ml | Notebook di Databricks, MLflow |
| Sviluppo e gestione delle funzionalità | Progettazione di funzionalità |
| Repository di modelli di Machine Learning | Modelli nel catalogo Unity |
| Gestione del modello di Machine Learning | Mosaic AI Model Serving |
| Infrastruttura come codice | Bundle di automazione dichiarativa |
| Orchestrator | Attività Lakeflow |
| Integrazione e Distribuzione Continua (CI/CD) | GitHub Actions, Azure DevOps |
| Monitoraggio delle prestazioni dei dati e dei modelli | Profilatura dei dati |
Passaggi successivi
Per iniziare, vedere Pacchetto di automazione dichiarativa per gli stack MLOps o il repository degli stack MLOps di Databricks su GitHub.