Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Questa funzionalità è Sperimentale.
Questo articolo illustra come usare la materializzazione per le visualizzazioni delle metriche per accelerare le prestazioni delle query.
La materializzazione per le visualizzazioni delle metriche accelera le query usando viste materializzate. Lakeflow Spark Declarative Pipelines orchestra le viste materializzate definite dall'utente per una vista metrica specifica. In fase di query, Query Optimizer instrada in modo intelligente le query utente nella visualizzazione metrica alla visualizzazione materializzata migliore usando la corrispondenza automatica delle query con riconoscimento dell'aggregazione, nota anche come riscrittura delle query.
Questo approccio offre i vantaggi del pre-calcolo e degli aggiornamenti incrementali automatici. Pertanto, non è necessario determinare quale tabella di aggregazione o vista materializzata interrogare per obiettivi di prestazioni diversi ed elimina la necessità di gestire pipeline di produzione separate.
Informazioni generali
Il diagramma seguente illustra come le viste delle metriche gestiscono la definizione e l'esecuzione di query:
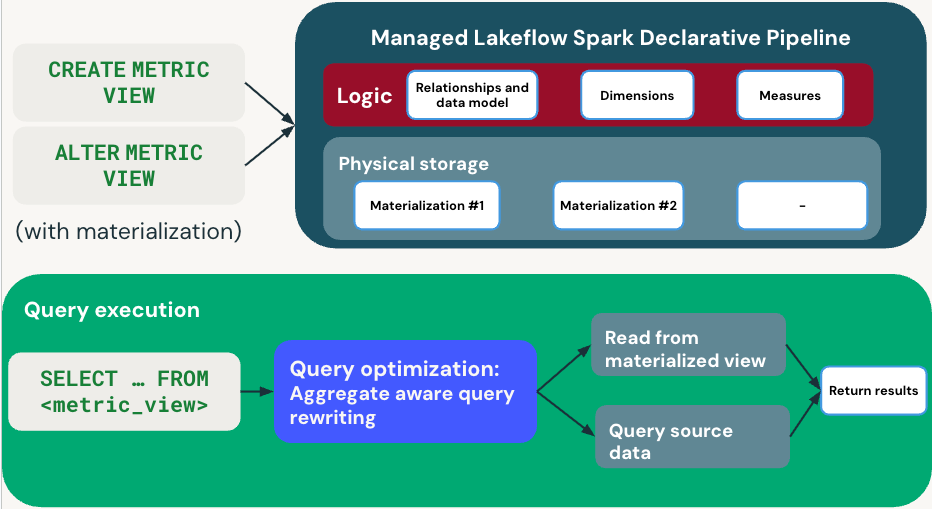
Fase di definizione
Quando si definisce una visualizzazione delle metriche con materializzazione, CREATE METRIC VIEW o ALTER METRIC VIEW specifica le dimensioni, le misure e la pianificazione dell'aggiornamento. Databricks crea una pipeline gestita che gestisce le viste materializzate.
Esecuzione della query
Quando si esegue SELECT ... FROM <metric_view>, Query Optimizer usa la riscrittura delle query con riconoscimento dell'aggregazione per ottimizzare le prestazioni:
- Percorso rapido: legge da viste materializzate pre-calcolate, se applicabile.
- Percorso di fallback: legge direttamente dai dati di origine quando le materializzazioni non sono disponibili.
Query Optimizer bilancia automaticamente le prestazioni e l'aggiornamento scegliendo tra dati materializzati e di origine. I risultati vengono visualizzati in modo trasparente indipendentemente dal percorso usato.
Requisiti
Per usare la materializzazione per le visualizzazioni delle metriche:
- L'area di lavoro deve avere il calcolo serverless abilitato. Questa operazione è necessaria per eseguire le pipeline dichiarative di Lakeflow Spark.
- Databricks Runtime 17.2 o versione successiva.
Informazioni di riferimento sulla configurazione
Tutte le informazioni correlate alla materializzazione vengono definite in un campo di primo livello denominato materialization nella definizione YAML della visualizzazione delle metriche.
Annotazioni
Quando questa funzionalità viene eseguita, le visualizzazioni delle metriche della versione 1.1 con materializzazione potrebbero generare l'errore seguente nella pipeline sottostante:
[METRIC_VIEW_INVALID_VIEW_DEFINITION] The metric view definition is invalid. Reason: Invalid YAML version: 1.1.
In questo caso, usare invece la versione 0.1. Si noti che la versione 0.1 non supporta alcune funzionalità disponibili nella versione 1.1. La materializzazione per le visualizzazioni delle metriche sarà disponibile in tutte le aree di lavoro entro le prossime settimane.
Il materialization campo contiene i campi obbligatori seguenti:
- schedule: supporta la stessa sintassi della clausola schedule nelle viste materializzate.
-
mode: deve essere impostato su
relaxed. -
materialized_views: elenco di viste materializzate da concretizzare.
- name: nome della materializzazione.
- dimensioni: elenco di dimensioni da materializzare. Sono consentiti solo riferimenti diretti ai nomi delle dimensioni; le espressioni non sono supportate.
- misure: elenco di misure da materializzare. Sono consentiti solo riferimenti diretti ai nomi delle misure; le espressioni non sono supportate.
-
type: specifica se la vista materializzata è aggregata o meno. Accetta due valori possibili:
aggregatedeunaggregated.- Se
typeèaggregated, deve essere presente almeno una dimensione o una misura. - Se
typeèunaggregated, non è necessario definire alcuna dimensione o misura.
- Se
Annotazioni
La TRIGGER ON UPDATE clausola non è supportata per la materializzazione per le visualizzazioni delle metriche.
Definizione di esempio
version: 0.1
source: prod.operations.orders_enriched_view
filter: revenue > 0
dimensions:
- name: category
expr: substring(category, 5)
- name: color
expr: color
measures:
- name: total_revenue
expr: SUM(revenue)
- name: number_of_suppliers
expr: COUNT(DISTINCT supplier_id)
materialization:
schedule: every 6 hours
mode: relaxed
materialized_views:
- name: baseline
type: unaggregated
- name: revenue_breakdown
type: aggregated
dimensions:
- category
- color
measures:
- total_revenue
- name: suppliers_by_category
type: aggregated
dimensions:
- category
measures:
- number_of_suppliers
Mode
In relaxed modalità, la riscrittura automatica delle query verifica solo se le viste materializzate candidate hanno le dimensioni e le misure necessarie per gestire la query.
Ciò significa che vengono ignorati diversi controlli:
- Non vengono controllati se la vista materializzata è aggiornata.
- Non vengono controllati se sono presenti impostazioni SQL corrispondenti, ad esempio
ANSI_MODEoTIMEZONE. - Non vengono controllati se la vista materializzata restituisce risultati deterministici.
Se la query include una delle condizioni seguenti, la riscrittura della query non si verifica e la query esegue il fallback alle tabelle di origine:
- Sicurezza a livello di riga (RLS) o maschera a livello di colonna (CLM) in viste materializzate.
- Funzioni non deterministiche come
current_timestamp()nelle viste materializzate. Questi elementi possono essere visualizzati nella definizione della vista metrica o in una tabella di origine usata dalla vista metrica.
Annotazioni
Durante il periodo di rilascio sperimentale, relaxed è l'unica modalità supportata. Se questi controlli hanno esito negativo, la query ripiega sui dati di origine.
Tipi di materializzazioni per le visualizzazioni delle metriche
Le sezioni seguenti illustrano i tipi di viste materializzate disponibili per le visualizzazioni delle metriche.
Tipo aggregato
Questo tipo pre-calcola le aggregazioni per le combinazioni di misure e dimensioni specificate per la copertura mirata.
Ciò è utile per definire come destinazione specifici modelli di query o widget di aggregazione comuni. Databricks consiglia di includere potenziali colonne di filtro come dimensioni nella configurazione della vista materializzata. Le colonne di filtro potenziali sono colonne usate in fase di query nella WHERE clausola .
Tipo non raggruppato
Questo tipo materializza l'intero modello di dati non raggruppato (ad esempio, i campi source, join e filter) per una copertura più ampia con minore impatto sulle prestazioni rispetto al tipo aggregato.
Usare questo tipo quando sono soddisfatte le condizioni seguenti:
- L'origine è una vista costosa o una query SQL.
- I join definiti nella visualizzazione delle metriche sono costosi.
Annotazioni
Se l'origine è un riferimento diretto alla tabella senza un filtro selettivo applicato, una vista materializzata non raggruppata potrebbe non offrire vantaggi.
Ciclo di vita della materializzazione
In questa sezione viene illustrato come vengono create, gestite e aggiornate le materializzazioni durante il ciclo di vita.
Creare e modificare
La creazione o la modifica di una vista metrica (tramite CREATE, ALTERo Esplora cataloghi) viene eseguita in modo sincrono. Le viste materializzate specificate si materializzano in modo asincrono utilizzando le pipeline dichiarative di Lakeflow Spark.
Quando si crea una visualizzazione delle metriche, Databricks crea una Pipeline dichiarativa di Lakeflow Spark e pianifica immediatamente un aggiornamento iniziale se sono specificate viste materializzate. La vista metrica rimane interrogabile senza materializzazioni ricorrendo all'interrogazione sui dati di origine.
Quando si modifica una visualizzazione delle metriche, non vengono pianificati nuovi aggiornamenti, a meno che non si abiliti la materializzazione per la prima volta. Le viste materializzate non vengono usate per la riscrittura automatica delle query fino al completamento dell'aggiornamento pianificato successivo.
La modifica della pianificazione della materializzazione non attiva un aggiornamento.
Vedere Aggiornamento manuale per un controllo più corretto sul comportamento di aggiornamento.
Esaminare la pipeline sottostante
La materializzazione per le visualizzazioni delle metriche viene implementata usando le pipeline dichiarative di Lakeflow Spark. Un collegamento alla pipeline è presente nella scheda Panoramica in Esplora cataloghi. Per informazioni su come accedere a Esplora cataloghi, vedere Informazioni su Esplora cataloghi.
È anche possibile accedere a questa pipeline eseguendo DESCRIBE EXTENDED nella visualizzazione delle metriche. La sezione Aggiorna informazioni contiene un collegamento alla pipeline.
DESCRIBE EXTENDED my_metric_view;
Output di esempio:
-- Returns additional metadata such as parent schema, owner, access time etc.
> DESCRIBE TABLE EXTENDED customer;
col_name data_type comment
------------------------------- ------------------------------ ----------
... ... ...
# Detailed Table Information
... ...
Language YAML
Table properties ...
# Refresh information
Latest Refresh status Succeeded
Latest Refresh https://...
Refresh Schedule EVERY 3 HOURS
Aggiornamento manuale
Dal collegamento alla pagina delle Pipeline dichiarative di Lakeflow Spark, è possibile avviare manualmente un aggiornamento della pipeline per aggiornare le materializzazioni. È anche possibile orchestrare questa operazione usando una chiamata API basata sull'ID della pipeline.
Ad esempio, lo script Python seguente avvia un aggiornamento della pipeline:
from databricks.sdk import WorkspaceClient
client = WorkspaceClient()
pipeline_id = "01484540-0a06-414a-b10f-e1b0e8097f15"
client.pipelines.start_update(pipeline_id)
Per eseguire un aggiornamento manuale come parte di un processo Lakeflow, creare uno script Python con la logica precedente e aggiungerlo come attività di tipo script Python. In alternativa, è possibile creare un notebook con la stessa logica e aggiungere un'attività di tipo Notebook.
Aggiornamento incrementale
Le viste materializzate usano l'aggiornamento incrementale quando possibile e presentano le stesse limitazioni relative alle origini dati e alla struttura del piano.
Per informazioni dettagliate sui prerequisiti e sulle restrizioni, vedere Aggiornamento incrementale per le viste materializzate.
Riscrittura automatica delle query
Le query a una visualizzazione metrica cercano di utilizzare le sue materializzazioni il più possibile. Esistono due strategie di riscrittura delle query: corrispondenza esatta e corrispondenza non raggruppata.

Quando si esegue una query su una vista metrica, l'optimizer analizza la query e le materializzazioni disponibili definite dall'utente. La query viene eseguita automaticamente sulla materializzazione migliore anziché sulle tabelle di base usando questo algoritmo:
- Tenta prima una corrispondenza esatta.
- Se esiste una materializzazione non aggregata, tenta una corrispondenza non aggregata.
- Se la riscrittura delle query ha esito negativo, la query legge direttamente dalle tabelle di origine.
Annotazioni
Le materializzazioni devono completarsi prima che la riscrittura delle query possa avere effetto.
Verificare che la query usi viste materializzate
Per verificare se una query usa una vista materializzata, eseguire EXPLAIN EXTENDED sulla tua query per vedere il piano di esecuzione della query. Se la query utilizza viste materializzate, il nodo foglia include __materialization_mat___metric_view il nome della materializzazione dal file YAML.
In alternativa, il profilo di query mostra le stesse informazioni.
Corrispondenza esatta
Per essere idonei per la strategia di corrispondenza esatta, le espressioni di raggruppamento della query devono corrispondere esattamente alle dimensioni di materializzazione. Le espressioni di aggregazione della query devono essere un sottoinsieme delle misure di materializzazione.
Corrispondenza non raggruppata
Se è disponibile una materializzazione non raggruppata, questa strategia è sempre idonea.
Billing
L'aggiornamento delle viste materializzate comporta addebiti per l'utilizzo delle pipeline dichiarative di Lakeflow Spark.
Restrizioni note
Le restrizioni seguenti si applicano alla materializzazione per le visualizzazioni delle metriche:
- Una visualizzazione delle metriche con materializzazione che fa riferimento a un'altra visualizzazione metrica come origine non può avere una materializzazione non raggruppata.