Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Un modello MLflow è un formato standard per la creazione di pacchetti di modelli di Machine Learning che possono essere usati in un'ampia gamma di strumenti downstream, ad esempio l'inferenza di invio in batch in Apache Spark o la gestione in tempo reale tramite un'API REST. Il formato definisce una convenzione che consente di salvare un modello in versioni diverse (funzione python, pytorch, sklearn e così via), che possono essere comprese mediante diverse piattaforme di gestione e inferenza del modello.
Per informazioni su come registrare e assegnare punteggi a un modello di streaming, vedere Come salvare e caricare un modello di streaming.
MLflow 3 introduce miglioramenti significativi ai modelli MLflow introducendo un nuovo oggetto dedicato con metadati specifici LoggedModel , ad esempio metriche e parametri. Per altri dettagli, vedere Tenere traccia e confrontare i modelli usando i modelli registrati di MLflow.
Registrare e caricare modelli
Quando si registra un modello, MLflow registra automaticamente i file requirements.txt e conda.yaml. È possibile usare questi file per ricreare l'ambiente di sviluppo del modello e reinstallare le dipendenze usando virtualenv (scelta consigliata) o conda.
Importante
Anaconda Inc. ha aggiornato le condizioni del servizio per i canali anaconda.org. In base alle nuove condizioni di servizio, potrebbe essere necessaria una licenza commerciale se ci si affida alla distribuzione di Anaconda e al suo packaging. Per altre informazioni, vedere Domande frequenti su Anaconda edizione Commerciale. L'uso di qualsiasi canale Anaconda è disciplinato dalle condizioni del servizio.
I modelli MLflow registrati prima della versione 1.18 (Databricks Runtime 8.3 ML o versioni precedenti) sono stati registrati per impostazione predefinita con il canale conda defaults (https://repo.anaconda.com/pkgs/) come dipendenza. A causa di questa modifica della licenza, Databricks ha interrotto l'uso del canale per i modelli defaults registrati usando MLflow v1.18 e versioni successive. Il canale predefinito registrato è ora conda-forge, che punta alla community gestita dalla https://conda-forge.org/.
Se è stato registrato un modello prima di MLflow v1.18 senza escludere il canale defaults dall'ambiente conda per il modello, tale modello potrebbe avere una dipendenza dal canale defaults che potrebbe non essere prevista.
Per verificare manualmente se un modello ha questa dipendenza, è possibile esaminare il valore channel nel file conda.yaml incluso nel pacchetto con il modello registrato. Ad esempio, un conda.yaml modello con una defaults dipendenza del canale può essere simile al seguente:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Poiché Databricks non è in grado di stabilire se l'uso del repository di Anaconda per interagire con i propri modelli sia consentito dal rapporto con Anaconda, Databricks non obbliga i propri clienti ad apportare alcuna modifica. Se l'uso del repository Anaconda.com tramite l'uso di Databricks è consentito in base ai termini di Anaconda, non è necessario eseguire alcuna azione.
Se si vuole modificare il canale usato nell'ambiente di un modello, è possibile registrare nuovamente il modello nel registro dei modelli con un nuovo conda.yamloggetto . A tale scopo, è possibile specificare il canale nel parametro conda_env di log_model().
Per altre informazioni sull'API log_model(), vedere la documentazione di MLflow relativa alla versione del modello con cui si sta lavorando, ad esempio log_model per scikit-learn.
Per ulteriori informazioni su conda.yaml, si veda la documentazione MLflow.
Comandi API
Per registrare un modello nel server di rilevamento MLflow, usare mlflow.<model-type>.log_model(model, ...).
Per caricare un modello registrato in precedenza per l'inferenza o un ulteriore sviluppo, usare mlflow.<model-type>.load_model(modelpath), dove modelpath è uno dei seguenti:
- un percorso del modello (ad esempio
models:/{model_id}) (solo MLflow 3 ) - un percorso relativo all'esecuzione (quale
runs:/{run_id}/{model-path}) - un percorso dei volumi del catalogo Unity ,ad esempio
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - Un percorso di archiviazione degli artefatti gestito da MLflow che inizia con
dbfs:/databricks/mlflow-tracking/ - un percorso del modello registrato (quale
models:/{model_name}/{model_stage}).
Per i modelli Python MLflow, un'opzione aggiuntiva consiste nell'usare mlflow.pyfunc.load_model() per caricare il modello come funzione Python generica.
È possibile usare il frammento di codice seguente per caricare il modello e assegnare un punteggio ai punti dati.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
In alternativa, è possibile esportare il modello come UDF (User Defined Function, funzione definita dall'utente) Apache Spark da usare per l'assegnazione dei punteggi in un cluster Spark, come processo batch o come lavoro di Spark Streaming in tempo reale.
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
Dipendenze del modello di log
Per caricare correttamente un modello, dovresti assicurarti che le dipendenze del modello vengano caricate con le versioni corrette nell'ambiente del notebook. In Databricks Runtime 10.5 ML e versioni successive MLflow avvisa se viene rilevata una mancata corrispondenza tra l'ambiente corrente e le dipendenze del modello.
Funzionalità aggiuntive per semplificare il ripristino delle dipendenze dei modelli sono incluse in Databricks Runtime 11.0 ML e versioni successive. In Databricks Runtime 11.0 ML e versioni successive, per i modelli della versione pyfunc, è possibile chiamare mlflow.pyfunc.get_model_dependencies per recuperare e scaricare le dipendenze dei modelli. Questa funzione restituisce un percorso al file delle dipendenze che è quindi possibile installare usando %pip install <file-path>. Quando si carica un modello come UDF PySpark, specificare env_manager="virtualenv" nella chiamata mlflow.pyfunc.spark_udf. In questo modo le dipendenze del modello vengono ripristinate nel contesto dell'UDF PySpark e non influiscono sull'ambiente esterno.
È anche possibile usare questa funzionalità in Databricks Runtime 10.5 o versioni precedenti, installando manualmente MLflow versione 1.25.0 o successive:
%pip install "mlflow>=1.25.0"
Per informazioni aggiuntive su come registrare le dipendenze dei modelli (Python e non Python) e gli artefatti, vedere Registrare dipendenze del modello.
Informazioni su come registrare le dipendenze del modello e gli artefatti personalizzati per la gestione del modello:
- Implementare modelli con dipendenze
- Usare librerie Python personalizzate con Model Serving
- Creare un pacchetto di artefatti personalizzati per la gestione dei modelli
Frammenti di codice generati automaticamente nell'interfaccia utente di MLflow
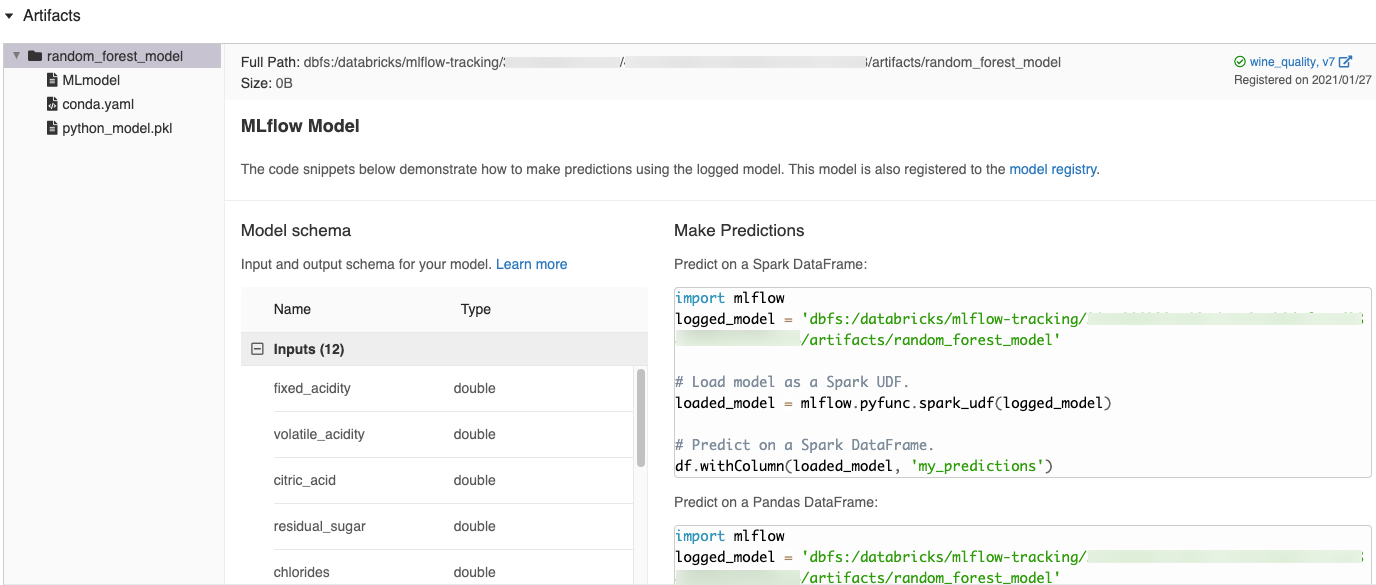
Quando si registra un modello in un notebook di Azure Databricks, Azure Databricks genera automaticamente frammenti di codice che è possibile copiare e usare per caricare ed eseguire il modello. Per visualizzare questi frammenti di codice:
- Passare alla schermata Esecuzioni per l'esecuzione che ha generato il modello. (Vedi Visualizzazione dell'esperimento del notebook per sapere come visualizzare la schermata Esecuzioni).
- Scorrere fino alla sezione Artefatti.
- Fare clic sul nome del modello da registrare. Viene aperto un pannello a destra che mostra il codice che è possibile usare per caricare il modello registrato ed eseguire previsioni su Spark o DataFrame Pandas.
Esempi
Per esempi di modelli di registrazione, vedere gli esempi in Tenere traccia degli esempi delle esecuzioni di training di Machine Learning.
Registrare i modelli nel Registro modelli
È possibile registrare i modelli nel Registro modelli MLflow, un archivio modelli centralizzato che fornisce un'interfaccia utente e un set di API per gestire il ciclo di vita completo dei modelli MLflow. Per istruzioni su come usare il Registro modelli per gestire i modelli nel catalogo unity di Databricks, vedere Gestire il ciclo di vita del modello in Unity Catalog. Per usare il Registro modelli di area di lavoro, vedere Gestire il ciclo di vita del modello usando il Registro modelli di area di lavoro (legacy).
Quando i modelli creati con MLflow 3 vengono registrati nel registro dei modelli di Catalogo Unity, è possibile visualizzare i dati, ad esempio parametri e metriche in un'unica posizione centrale, in tutti gli esperimenti e le aree di lavoro. Per informazioni, vedere Miglioramenti del Registro di sistema dei modelli con MLflow 3.
Per registrare un modello usando l'API, usare il comando seguente:
MLflow 3
mlflow.register_model("models:/{model_id}", "{registered_model_name}")
MLflow 2.x
mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}")
Salvare i modelli in volumi del catalogo Unity
Per salvare un modello in locale, usare mlflow.<model-type>.save_model(model, modelpath).
modelpath deve essere un percorso di volumi del catalogo Unity. Ad esempio, se si usa un percorso dei volumi del catalogo Unity /Volumes/catalog_name/schema_name/volume_name/my_project_models per archiviare il lavoro del progetto, è necessario usare il percorso del modello /Volumes/catalog_name/schema_name/volume_name/my_project_models:
modelpath = "/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
Per i modelli di MLlib usare pipeline di Machine Learning.
Scaricare artefatti dei modelli
È possibile scaricare gli artefatti del modello registrati (quali, file di modello, tracciati e metriche) per un modello registrato con varie API.
Esempio di API Python:
mlflow.set_registry_uri("databricks-uc")
mlflow.artifacts.download_artifacts(f"models:/{model_name}/{model_version}")
Esempio di API Java:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
Esempio di Comando CLI:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
Implementare modelli per la gestione online
Nota
Prima di distribuire il modello, è utile verificare che il modello sia in grado di essere servito. Vedere la documentazione di MLflow per informazioni su come usare mlflow.models.predict per convalidare i modelli prima della distribuzione.
Usare Model Serving per ospitare modelli di Machine Learning registrati nel registro dei modelli di Catalogo Unity come endpoint REST. Questi endpoint vengono aggiornati automaticamente in base alla disponibilità delle versioni del modello.