gennaio 2019
Queste funzionalità e i miglioramenti della piattaforma Azure Databricks sono stati rilasciati a gennaio 2019.
Nota
Le versioni vengono gestite in staging. L'account Azure Databricks potrebbe non essere aggiornato fino a una settimana dopo la data di rilascio iniziale.
Modifica imminente: Python 3 per diventare l'impostazione predefinita quando si creano cluster
29 gennaio 2019
Quando la piattaforma Databricks versione 2.91 viene rilasciata a metà febbraio, la versione predefinita di Python per i nuovi cluster passerà da Python 2 a Python 3. I cluster esistenti non modificheranno naturalmente le versioni di Python. Tuttavia, se si ha l'abitudine di prendere l'impostazione predefinita di Python 2 quando si creano nuovi cluster, è necessario iniziare a prestare attenzione alla selezione della versione di Python.
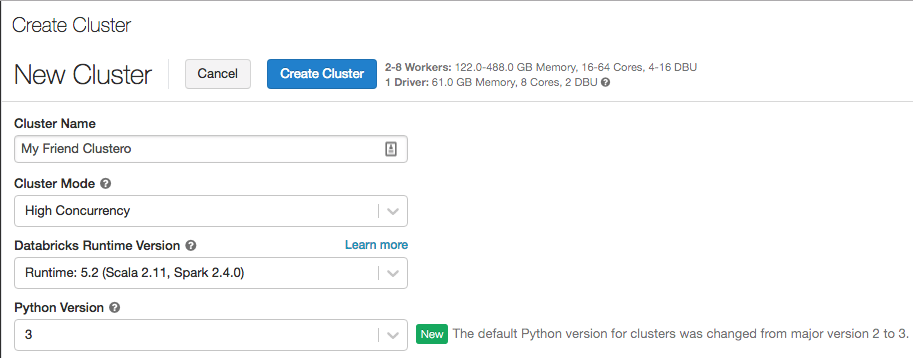
Versione Databricks Runtime 5.2 per Machine Learning (beta)
24 gennaio 2019
Databricks Runtime 5.2 ML è basato su Databricks Runtime 5.2 (non supportato). Contiene molte librerie di Machine Learning più diffuse, tra cui TensorFlow, PyTorch, Keras e XGBoost, e fornisce il training di TensorFlow distribuito usando Horovod. Oltre agli aggiornamenti della libreria a partire da Databricks Runtime ML 5.1, Databricks Runtime 5.2 ML include le nuove funzionalità seguenti:
- GraphFrames supporta ora l'API Pregel (Python) con le ottimizzazioni delle prestazioni di Databricks.
- HorovodRunner aggiunge:
- In un cluster GPU, i processi di training vengono mappati alle GPU anziché ai nodi di lavoro per semplificare il supporto dei tipi di istanza multi-GPU. Questo supporto predefinito consente di distribuire a tutte le GPU in un computer multi-GPU senza codice personalizzato.
HorovodRunner.run()restituisce ora il valore restituito dal primo processo di training.
Vedere le note sulla versione complete per Databricks Runtime 5.2 ML.
Versione Databricks Runtime 5.2
24 gennaio 2019
Databricks Runtime 5.2 è ora disponibile. Databricks Runtime 5.2 include Apache Spark 2.4.0, nuove funzionalità di Delta Lake e Structured Streaming e aggiornamenti e le librerie Python, R, Java e Scala aggiornate. Per informazioni dettagliate, vedere Databricks Runtime 5.2 (non supportato).
Vista JSON della configurazione cluster
15-22 gennaio 2019
La pagina di configurazione del cluster supporta ora una visualizzazione JSON:
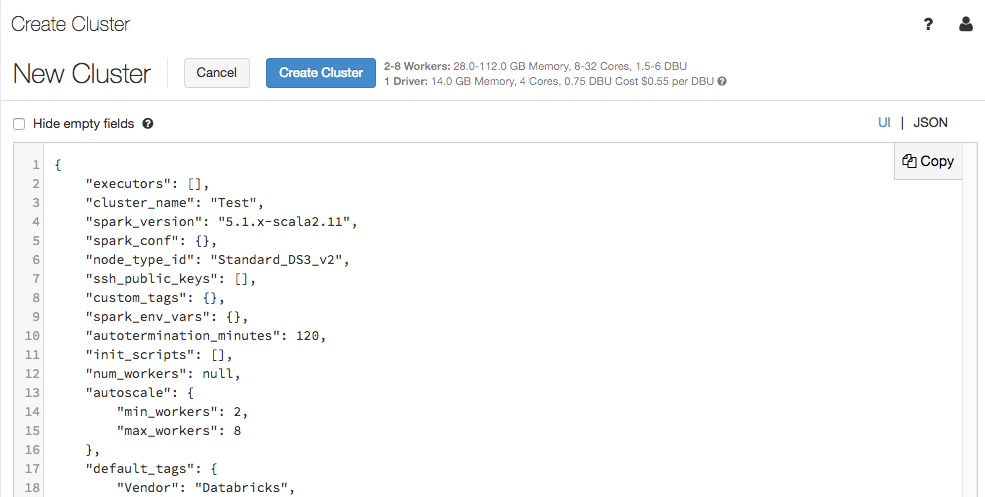
La visualizzazione JSON è di sola lettura. È tuttavia possibile copiare il codice JSON e usarlo per creare e aggiornare i cluster con l'API Clusters.
Interfaccia utente del cluster
15-22 gennaio 2019: versione 2.89
La pagina di creazione del cluster è stata pulita e riorganizzata per semplificare l'uso, incluso un nuovo interruttore Opzioni avanzate.
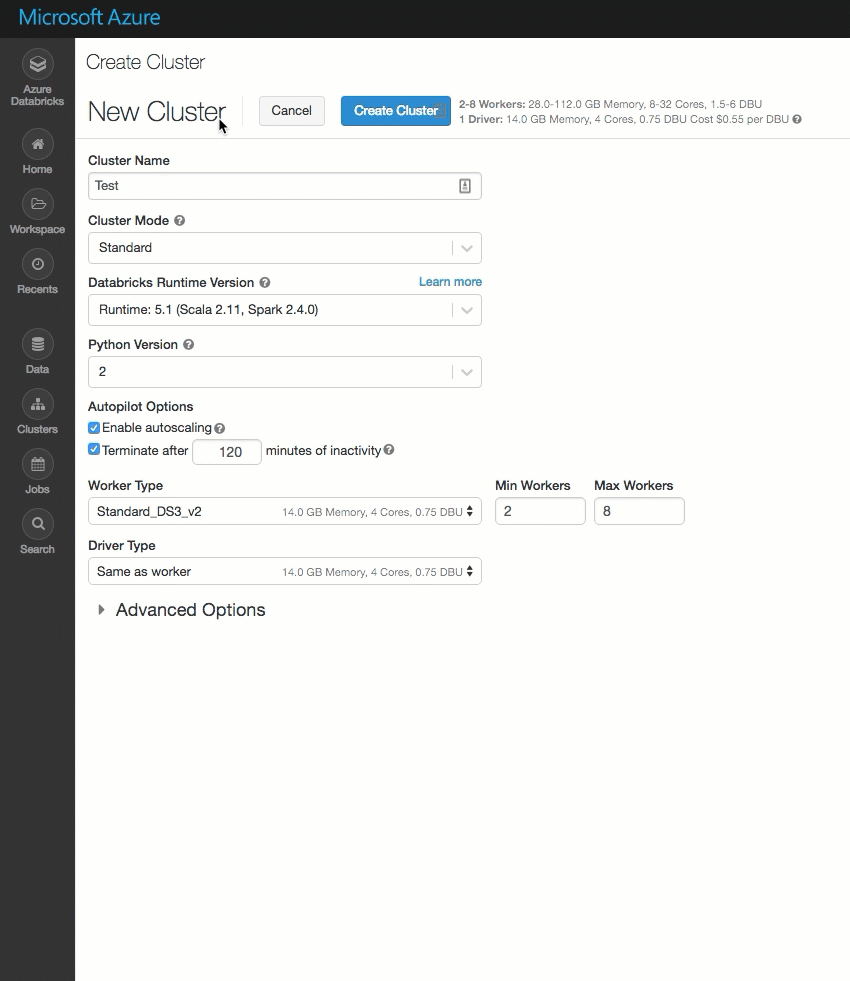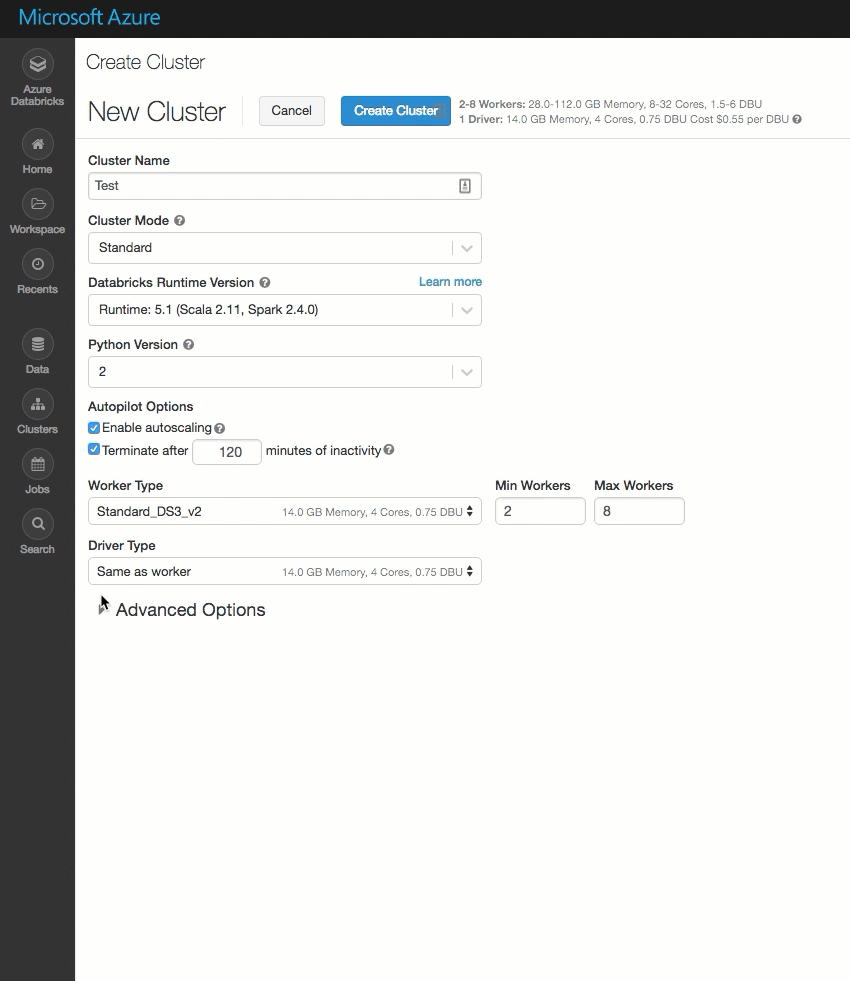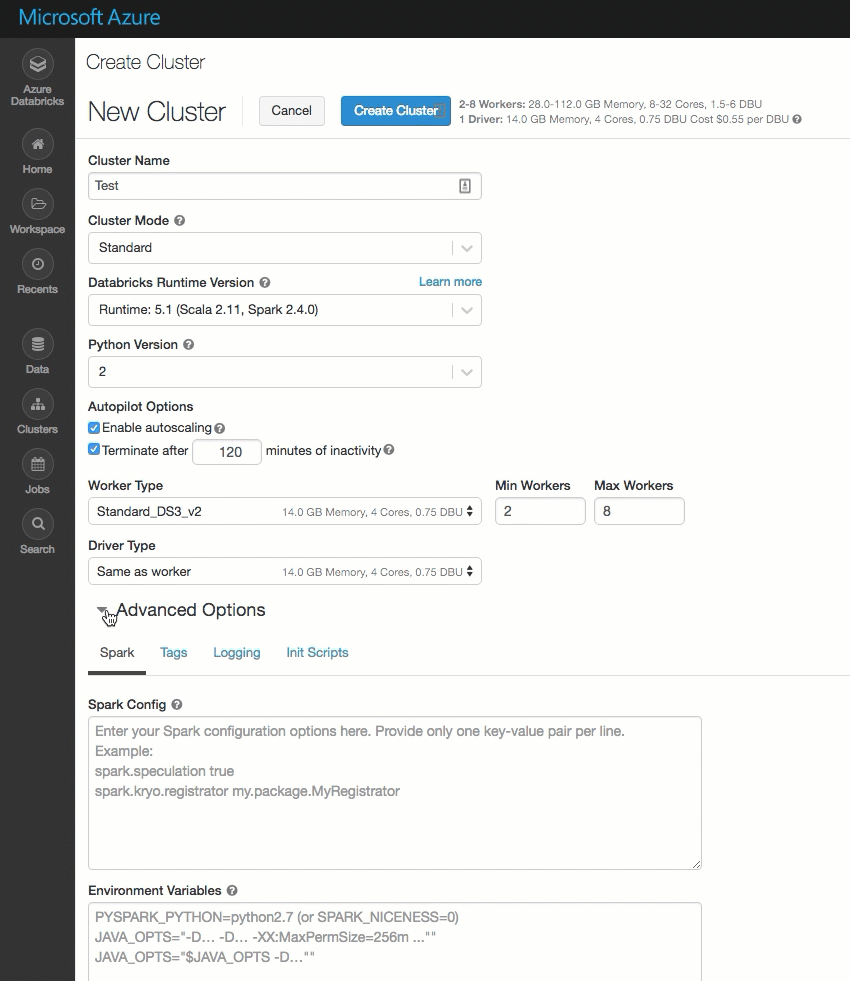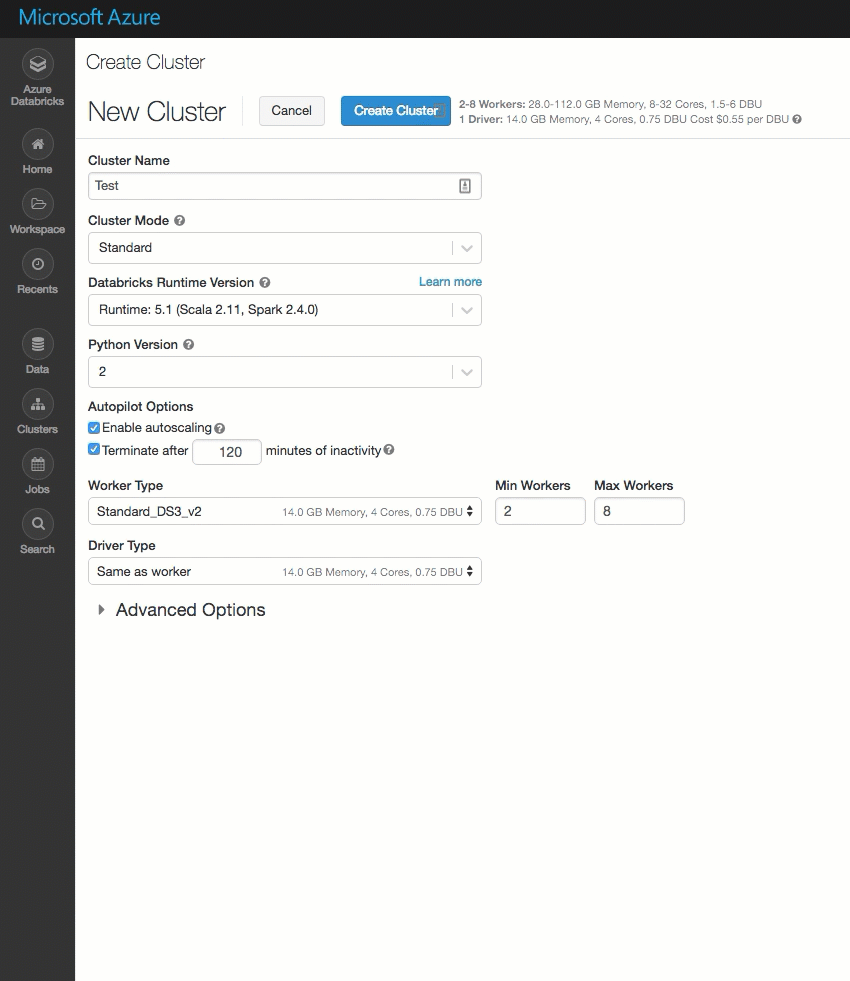
Distribuire Azure Databricks nella rete virtuale di Azure (aggiunta nella rete virtuale)
10 gennaio 2019
Importante
Questa funzionalità è disponibile in anteprima pubblica.
La distribuzione predefinita di Azure Databricks è un servizio completamente gestito in Azure: tutte le risorse del piano di calcolo, inclusa una rete virtuale (VNet) a cui verranno associati tutti i cluster, vengono distribuiti in un gruppo di risorse bloccato. Se è necessaria la personalizzazione della rete, tuttavia, è ora possibile distribuire Azure Databricks nella propria rete virtuale (talvolta denominata inserimento reti virtuali), consentendo di:
- Connessione Azure Databricks ad altri servizi di Azure (ad esempio Archiviazione di Azure) in modo più sicuro usando gli endpoint di servizio.
- Connessione alle origini dati locali da usare con Azure Databricks, sfruttando le route definite dall'utente.
- Connessione Azure Databricks a un'appliance virtuale di rete per esaminare tutto il traffico in uscita e intraprendere azioni in base alle regole di autorizzazione e negazione.
- Configurare Azure Databricks per l'uso di DNS personalizzato.
- Configurare le regole del gruppo di sicurezza di rete (NSG) per specificare le restrizioni del traffico in uscita.
- Distribuire cluster di Azure Databricks nella rete virtuale esistente.
La distribuzione di Azure Databricks nella propria rete virtuale consente anche di sfruttare gli intervalli CIDR flessibili (ovunque tra /16-/24 per la rete virtuale e tra /18-/26 per le subnet).
La configurazione con l'interfaccia utente di portale di Azure è rapida e semplice: quando si crea un'area di lavoro, è sufficiente selezionare Distribuisci l'area di lavoro di Azure Databricks nel Rete virtuale, selezionare la rete virtuale e fornire intervalli CIDR per due subnet. Azure Databricks aggiorna la rete virtuale con due nuove subnet e gruppi di sicurezza di rete usando intervalli CIDR forniti dall'utente, consente l'accesso al traffico subnet in ingresso e in uscita e distribuisce l'area di lavoro nella rete virtuale aggiornata.
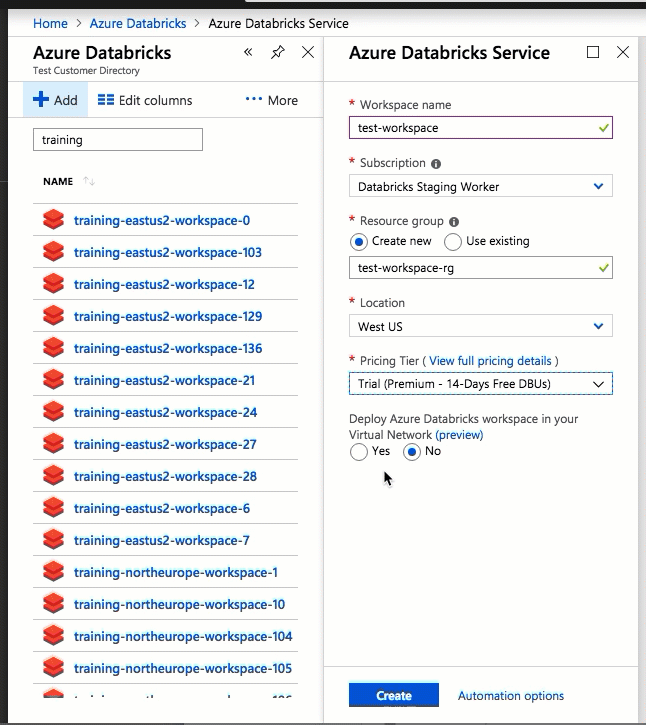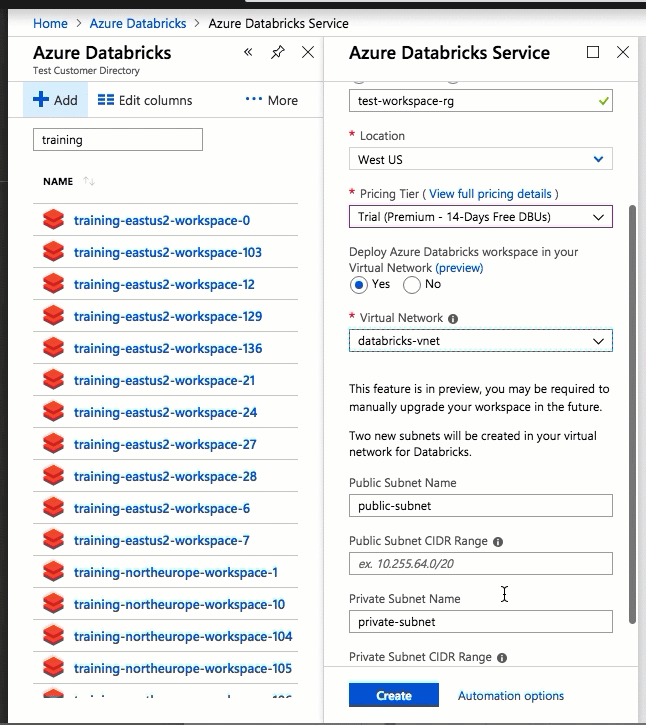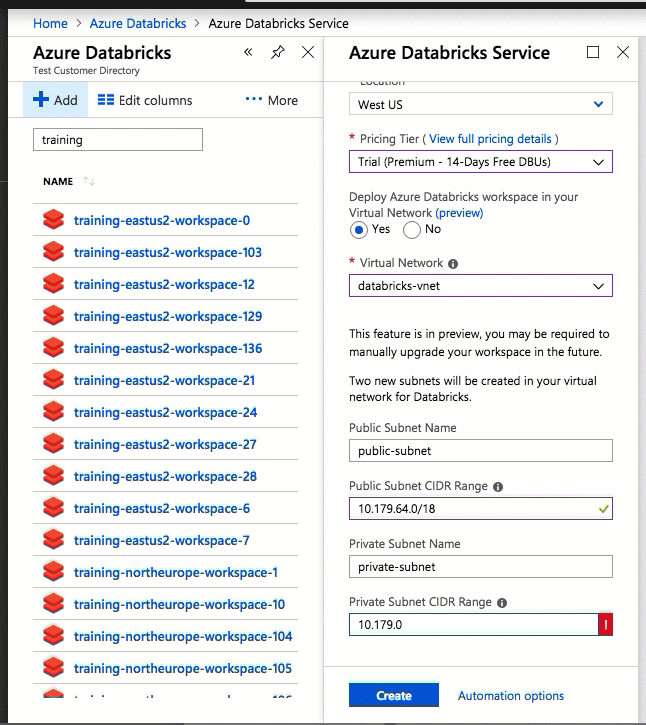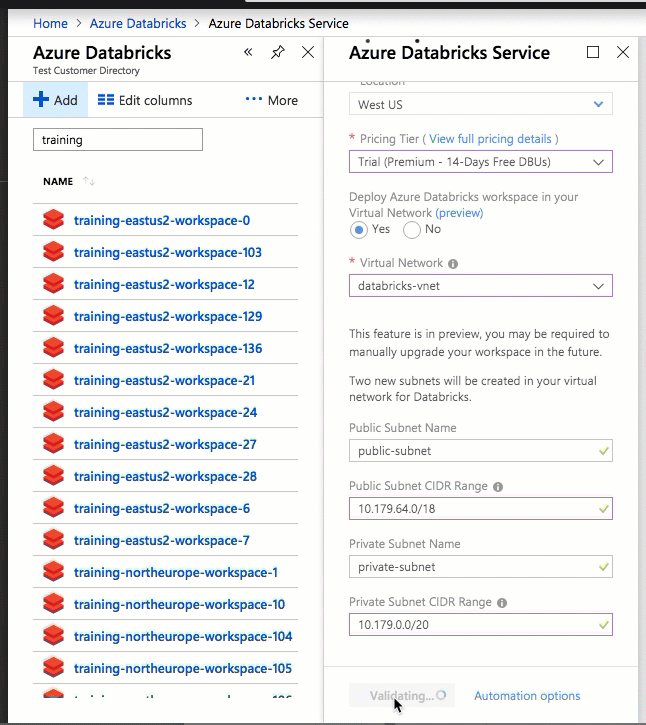
Se si preferisce configurare manualmente la rete virtuale per l'inserimento di reti virtuali, ad esempio si vogliono usare subnet esistenti, usare gruppi di sicurezza di rete esistenti o creare regole di sicurezza personalizzate, è possibile usare modelli arm forniti da Azure-Databricks anziché l'interfaccia utente del portale.
Nota
Questa funzionalità era precedentemente disponibile solo per la registrazione. Rimane in anteprima , ma è ora completamente self-service.
Per informazioni dettagliate, vedere Distribuire Azure Databricks nella rete virtuale di Azure (VNet injection) e Connessione'area di lavoro di Azure Databricks nella rete locale.
Interfaccia utente delle librerie
2-9 gennaio 2019: versione 2.88
I miglioramenti dell'interfaccia utente della libreria rilasciati originariamente a novembre 2018 e ripristinati poco dopo sono stati ridistribuiti. Questi aggiornamenti semplificano il caricamento, l'installazione e la gestione delle librerie per i cluster Di Azure Databricks.
L'interfaccia utente di Azure Databricks supporta ora sia le librerie dell'area di lavoro che le librerie installate nel cluster. Esiste una libreria dell'area di lavoro nell'area di lavoro e può essere installata in uno o più cluster. Una libreria installata dal cluster è una libreria esistente solo nel contesto del cluster in cui è installato. In aggiunta:
- È ora possibile creare una libreria da un file caricato nell'archivio oggetti.
- È ora possibile installare e disinstallare le librerie dalla pagina dei dettagli della libreria e dalla scheda Librerie di un cluster.
- Le librerie installate usando l'API ora vengono visualizzate nella scheda Librerie di un cluster.
Per informazioni dettagliate, vedere Librerie.
Eventi del cluster
2-9 gennaio 2019: versione 2.88
Sono stati aggiunti nuovi eventi del cluster per riflettere lo stato del driver Spark. Per informazioni dettagliate, vedere API cluster.
Controllo della versione notebook tramite Azure DevOps Services
2-9 gennaio 2019: versione 2.88
Azure Databricks ora semplifica l'uso di Azure DevOps Services (in precedenza VSTS) per controllare la versione dei notebook. L'autenticazione è automatica, la configurazione è semplice e si gestiscono le revisioni dei notebook esattamente come si fa con l'integrazione di GitHub.
Per informazioni dettagliate, vedere Controllo della versione Git per notebook (legacy).For details, see Git version control for notebooks (legacy).
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per