Gestire gli asset di file nelle cartelle Git di Databricks
Le cartelle Git di Databricks fungono da client Git per cloni gestiti da Databricks di repository di origine basati su Git, consentendo di eseguire un subset di operazioni Git sui relativi contenuti dall'area di lavoro. Nell'ambito di questa integrazione git, i file archiviati nel repository remoto vengono visualizzati come "asset" in base al tipo, con alcune limitazioni specifiche del tipo. I file del notebook, in particolare, hanno proprietà diverse in base al tipo. Leggere questo articolo per comprendere come usare gli asset, in particolare i notebook IPYNB, nelle cartelle Git.
Tipi di asset supportati
Solo alcuni tipi di asset di Azure Databricks sono supportati dalle cartelle Git. In questo caso, "supportato" significa "può essere serializzato, controllato dalla versione ed eseguito il push nel repository Git di supporto".
Attualmente, i tipi di asset supportati sono:
| Tipo di asset | Dettagli |
|---|---|
| file | I file sono dati serializzati e possono includere qualsiasi elemento, dalle librerie ai file binari al codice alle immagini. Per altre informazioni, vedere Che cosa sono i file dell'area di lavoro? |
| Notebook | I notebook sono in particolare i formati di file del notebook supportati da Databricks. I notebook sono considerati un tipo di asset di Azure Databricks separato da File perché non vengono serializzati. Le cartelle Git determinano un notebook in base all'estensione di file (ad esempio .ipynb) o alle estensioni di file combinate con un marcatore speciale nel contenuto del file (ad esempio, un # Databricks notebook source commento all'inizio dei file di .py origine). |
| Cartella | Una cartella è una struttura specifica di Azure Databricks che rappresenta informazioni serializzate su un raggruppamento logico di file in Git. Come previsto, l'utente esegue questa operazione come "cartella" quando visualizza una cartella Git di Azure Databricks o accede a questa cartella con l'interfaccia della riga di comando di Azure Databricks. |
I tipi di asset di Azure Databricks attualmente non supportati nelle cartelle Git includono quanto segue:
- Query DBSQL
- Avvisi
- Dashboard (inclusi i dashboard legacy)
Quando si lavora con gli asset in Git, osservare le limitazioni seguenti nella denominazione dei file:
- Una cartella non può contenere un notebook con lo stesso nome di un altro notebook, file o cartella nello stesso repository Git, anche se l'estensione del file è diversa. Per i notebook in formato di origine, l'estensione è
.pyper Python,.scalaper Scala,.sqlper SQL e.rper R. Per i notebook in formato IPYNB, l'estensione è.ipynb. Ad esempio, non è possibile usare un notebook in formato di origine denominatotest1.pye un notebook IPYNB denominatotest1nella stessa cartella Git perché il file del notebook Python in formato di origine (test1.py) verrà serializzato cometest1e si verificherà un conflitto. - Il carattere
/non è supportato nei nomi di file. Ad esempio, non è possibile avere un file denominatoi/o.pynella cartella Git.
Se si tenta di eseguire operazioni Git su file con nomi con questi modelli, verrà visualizzato il messaggio "Errore durante il recupero dello stato git". Se questo errore viene visualizzato in modo imprevisto, esaminare i nomi file degli asset nel repository Git. Se si trovano file con nomi con questi modelli in conflitto, rinominarli e ritentare l'operazione.
Nota
È possibile spostare gli asset non supportati esistenti in una cartella Git, ma non è possibile eseguire il commit delle modifiche apportate a tali asset nel repository. Non è possibile creare nuovi asset non supportati in una cartella Git.
Formati di notebook
Databricks considera due tipi di formati di notebook specifici di Databricks di alto livello: "source" e "ipynb". Quando un utente esegue il commit di un notebook nel formato "source", la piattaforma Databricks esegue il commit di un file flat con un suffisso linguistico, ad esempio .py, .sql, .scalao .r. Un notebook in formato "source" contiene solo il codice sorgente e non contiene output come le visualizzazioni e le visualizzazioni delle tabelle che sono i risultati dell'esecuzione del notebook.
Il formato "ipynb", tuttavia, include output associati e tali artefatti vengono automaticamente inseriti nel repository Git che esegue il backup della cartella Git durante il push del .ipynb notebook che li ha generati. Se si desidera eseguire il commit degli output insieme al codice, usare il formato e la configurazione del notebook "ipynb" per consentire a un utente di eseguire il commit di eventuali output generati. Di conseguenza, "ipynb" supporta anche un'esperienza di visualizzazione migliore in Databricks per i notebook inseriti in repository Git remoti tramite cartelle Git.
| Formato origine notebook | Dettagli |
|---|---|
| source | Può essere qualsiasi file di codice con un suffisso di file standard che segnala il linguaggio di codice, ad esempio .py, .scala.r e .sql. I notebook "source" vengono considerati come file di testo e non includeranno alcun output associato quando viene eseguito il commit in un repository Git. |
| ipynb | I file "ipynb" terminano con .ipynb e possono, se configurati, eseguire il push degli output (ad esempio le visualizzazioni) dalla cartella Git di Databricks al repository Git di backup. Un .ipnynb notebook può contenere codice in qualsiasi linguaggio supportato dai notebook di Databricks (nonostante la py parte di .ipynb). |
Se si vuole eseguire il push degli output nel repository dopo l'esecuzione di un notebook, usare un .ipynb notebook (Jupyter). Se si vuole solo eseguire il notebook e gestirlo in Git, usare un formato di "origine" come .py.
Per altre informazioni sui formati di notebook supportati, vedere Esportare e importare notebook di Databricks.
Nota
Che cosa sono gli "output"?
Gli output sono i risultati dell'esecuzione di un notebook nella piattaforma Databricks, incluse le visualizzazioni e le visualizzazioni delle tabelle.
Ricerca per categorie indicare quale formato usa un notebook, diverso dall'estensione di file?
Nella parte superiore di un notebook gestito da Databricks è in genere presente un commento a riga singola che indica il formato. Ad esempio, per un .py notebook di "origine", verrà visualizzata una riga simile alla seguente:
# Databricks notebook source
Per .ipynb i file, il suffisso di file viene usato per indicare che è il formato del notebook "ipynb".
Notebook IPYNB nelle cartelle Git di Databricks
Il supporto per i notebook di Jupyter (.ipynb file) è disponibile nelle cartelle Git. È possibile clonare i repository con .ipynb notebook, usarli nel prodotto Databricks e quindi eseguirne il commit e il push come .ipynb notebook. I metadati, ad esempio il dashboard del notebook, vengono mantenuti. Amministrazione può controllare se è possibile eseguire o meno il commit degli output.
Consenti commit dell'output del .ipynb notebook
Per impostazione predefinita, l'impostazione di amministrazione per le cartelle Git non consente .ipynb il commit dell'output del notebook. Gli amministratori dell'area di lavoro possono modificare questa impostazione:
Passare a impostazioni Amministrazione Impostazioni >area di lavoro.
In Cartelle Git Consenti alle cartelle > Git di esportare gli output IPYNB selezionare Consenti: gli output IPYNB possono essere attivati o disattivati.

Importante
Quando vengono inclusi gli output, le configurazioni di visualizzazione e dashboard vengono mantenute con il formato di file con estensione ipynb.
Controllare i commit degli artefatti dell'output del notebook IPYNB
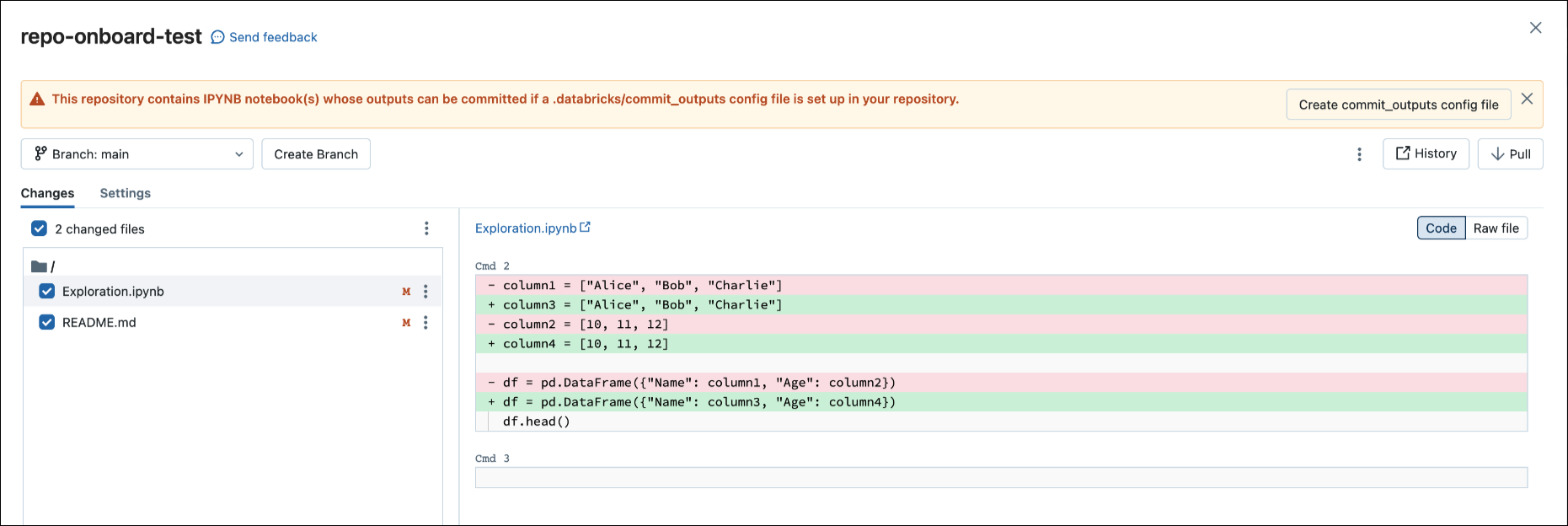
Quando si esegue il commit di un .ipynb file, Databricks crea un file di configurazione che consente di controllare la modalità di commit degli output: .databricks/commit_outputs.
Se si dispone di un
.ipynbfile di notebook ma non di un file di configurazione nel repository, aprire il modale Stato Git.Nella finestra di dialogo di notifica fare clic su Crea commit_outputs file.
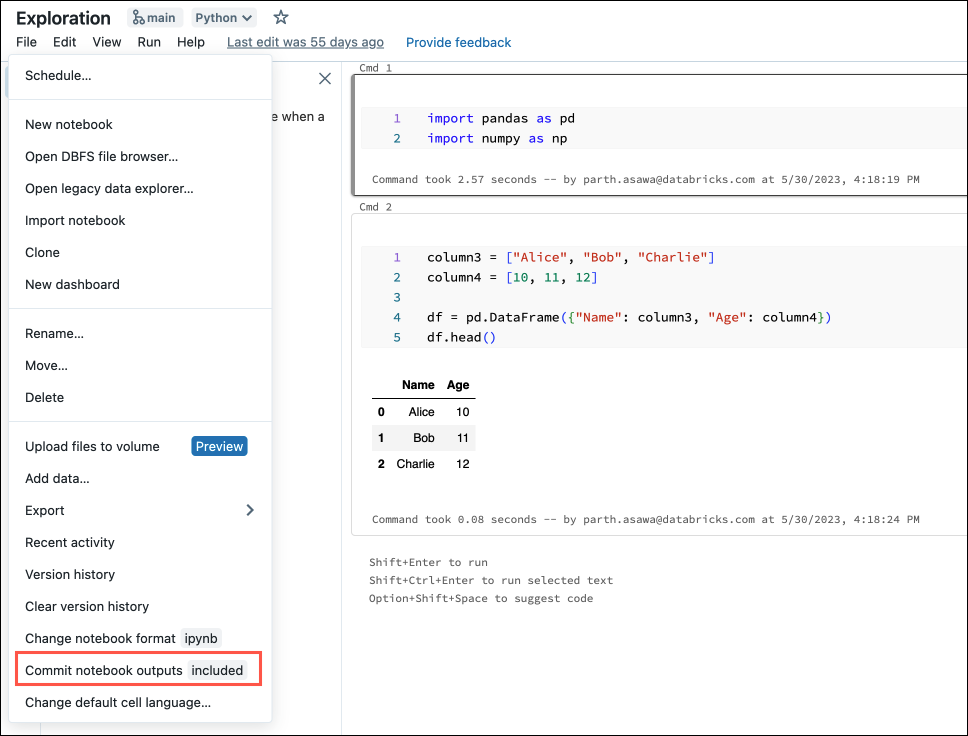
È anche possibile generare file di configurazione dal menu File . Il menu File include un controllo che consente di aggiornare automaticamente il file di configurazione per specificare l'inclusione o l'esclusione degli output per un notebook specifico.
Nel menu File selezionare Commit notebooks outputs (Esegui commit degli output dei notebook).
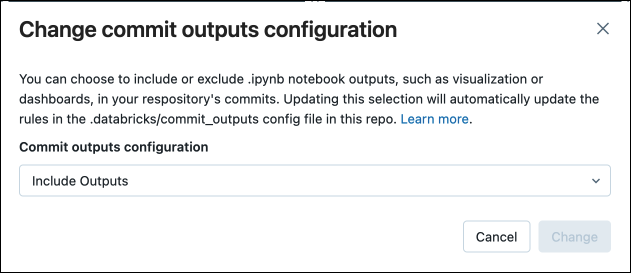
Nella finestra di dialogo confermare la scelta di eseguire il commit degli output del notebook.
Convertire un notebook di origine in IPYNB
È possibile convertire un notebook di origine esistente in una cartella Git in un notebook IPYNB tramite l'interfaccia utente di Azure Databricks.
Aprire un notebook di origine nell'area di lavoro.
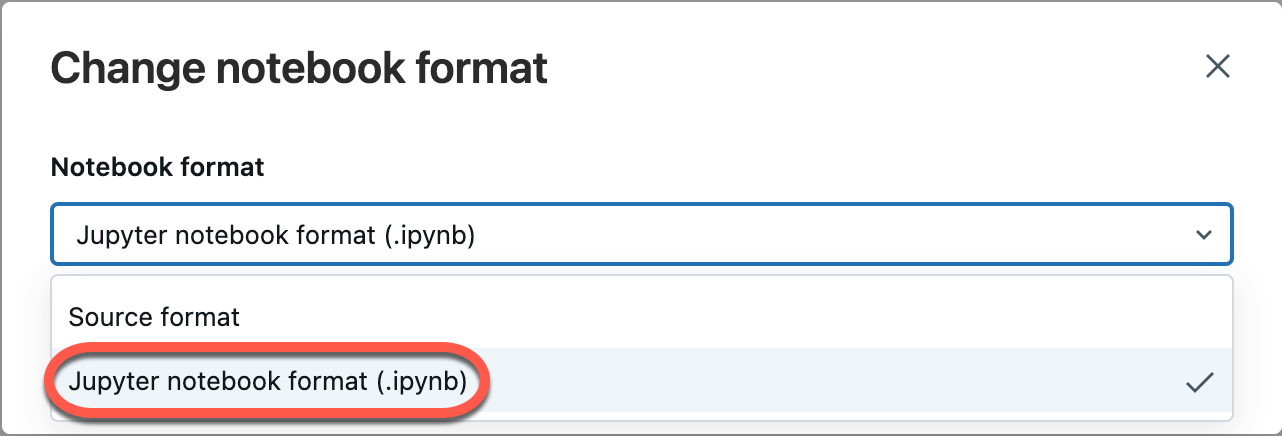
Selezionare File dal menu dell'area di lavoro e quindi selezionare Cambia formato notebook [origine]. Se il notebook è già in formato IPYNB, [source] sarà [ipynb] nell'elemento di menu.
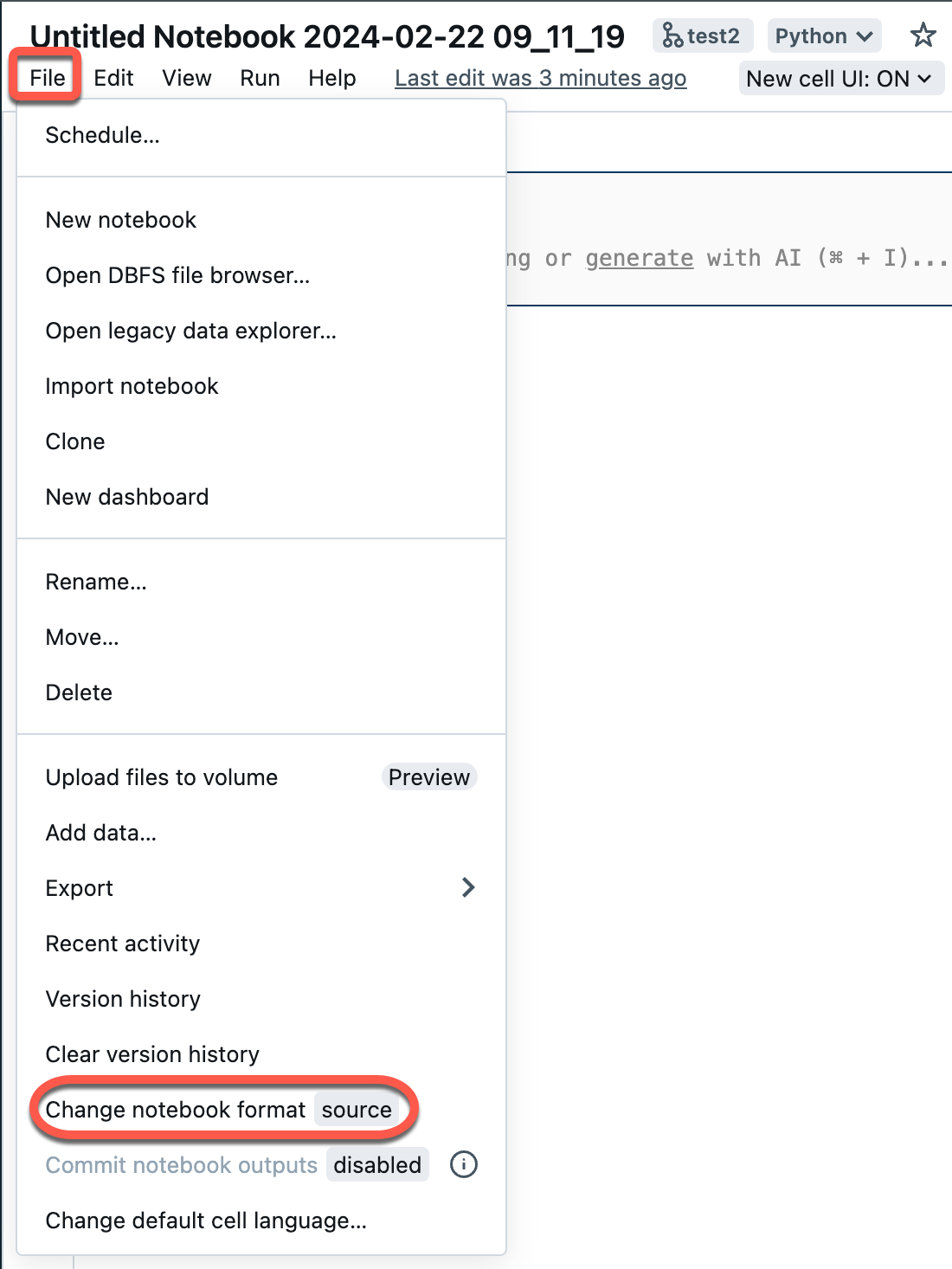
Nella finestra di dialogo modale selezionare "Formato notebook jupyter (.ipynb)" e fare clic su Cambia.
È anche possibile:
- Creare nuovi
.ipynbnotebook. - Visualizzare le differenze come differenze di codice (modifiche del codice nelle celle) o differenze non elaborate (le modifiche al codice vengono presentate come sintassi JSON, che include output del notebook come metadati).
Per altre informazioni sui tipi di notebook supportati in Azure Databricks, vedere Esportare e importare notebook di Databricks.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per