Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive le visualizzazioni legacy di Azure Databricks. Vedere Visualizzazioni nei notebook di Databricks e nell'editor SQL per il supporto della visualizzazione corrente durante la creazione di visualizzazioni nell'editor SQL o in un notebook. Per informazioni sull'uso delle visualizzazioni nei dashboard di intelligenza artificiale/BI, vedere Tipi di visualizzazione dei dashboard di intelligenza artificiale/BI.
Azure Databricks supporta inoltre in modalità nativa le librerie di visualizzazione in Python e R e consente di installare e usare librerie di terze parti.
Creare una visualizzazione legacy (sistema obsoleto)
Per creare una visualizzazione legacy da una cella dei risultati, fare clic su + e selezionare Visualizzazione legacy.
Le visualizzazioni legacy supportano un set completo di tipi di tracciato:
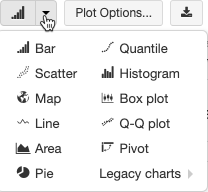
Scegliere e configurare un tipo di grafico legacy
Per scegliere un grafico a barre, fare clic sull'icona  .
.
Per scegliere un altro tipo di tracciato, fare clic sul ![]() a destra del a barre e scegliere il tipo di tracciato.
a destra del a barre e scegliere il tipo di tracciato.
Barra degli strumenti del grafico legacy
Sia i grafici a linee che i grafici a barre dispongono di una barra degli strumenti predefinita che supporta un set completo di interazioni lato client.
Per configurare un grafico, fare clic su Opzioni di tracciamento….
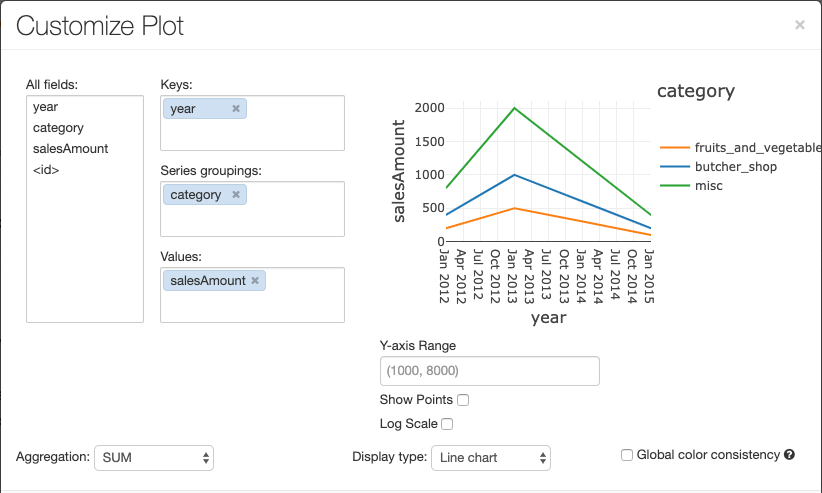
Il grafico a linee include alcune opzioni personalizzate per impostare un intervallo dell'asse Y, visualizzare e nascondere punti e visualizzare l'asse Y con una scala logaritmica.
Per informazioni sui tipi di grafico legacy, consultare:
Coerenza dei colori tra grafici
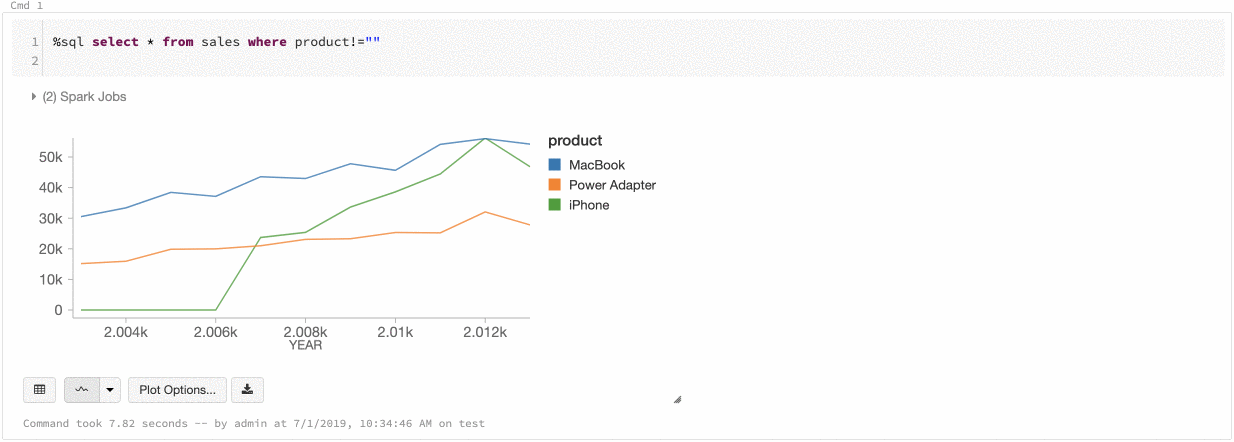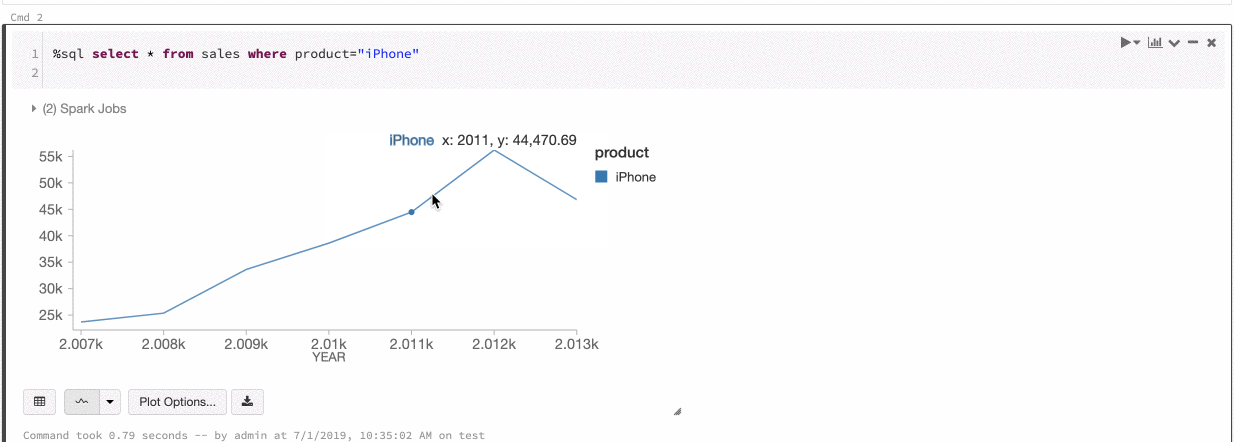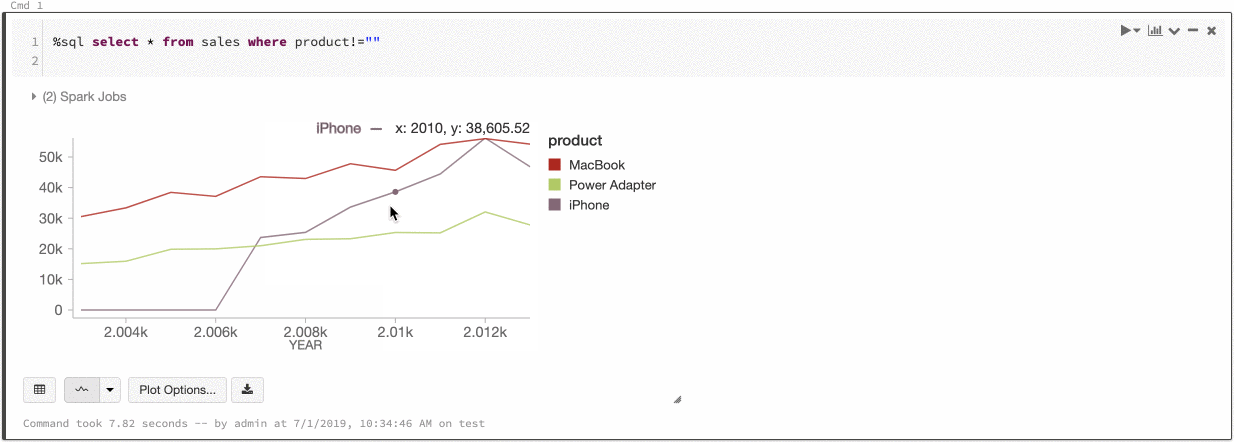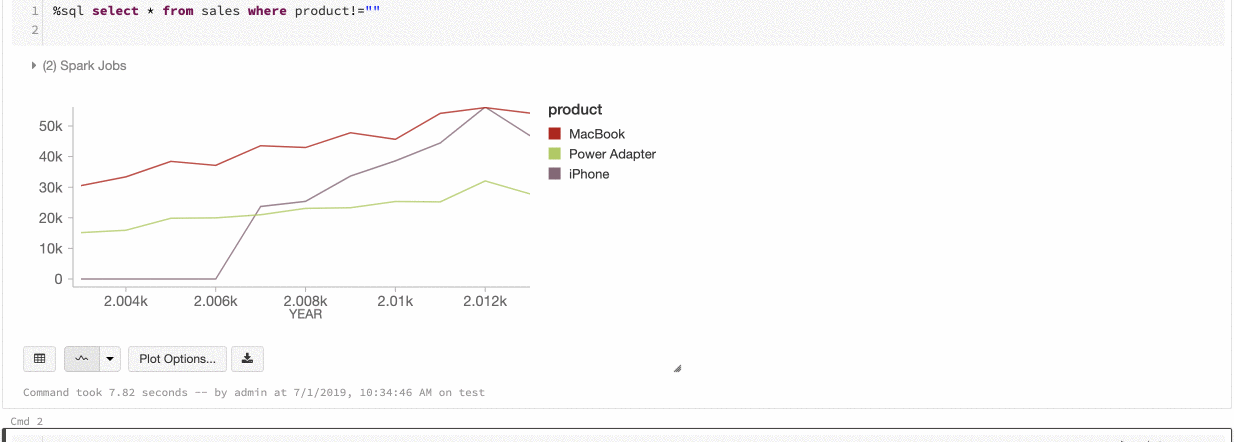
Azure Databricks supporta due tipi di coerenza dei colori nei grafici legacy: set di serie e globale.
Serie impostata coerenza dei colori permette di assegnare lo stesso colore allo stesso valore se si dispone di serie con gli stessi valori, ma in ordini diversi, ad esempio A = ["Apple", "Orange", "Banana"] e B = ["Orange", "Banana", "Apple"]. I valori vengono ordinati prima del tracciato, quindi entrambe le legende vengono ordinate allo stesso modo (["Apple", "Banana", "Orange"]) e gli stessi valori vengono assegnati agli stessi colori. Tuttavia, se si dispone di una serie C = ["Orange", "Banana"], non sarebbe coerente con i colori dell'insieme A perché l'insieme non è lo stesso. L'algoritmo di ordinamento assegnerebbe il primo colore a "Banana" nel set C, ma il secondo colore su "Banana" nel set A. Se si vuole che queste serie siano coerenti con il colore, è possibile specificare che i grafici devono avere la coerenza dei colori globale.
In uniformità globale del colore, ogni valore viene sempre associato allo stesso colore indipendentemente dai valori presenti nella serie. Per abilitare questa opzione, selezionare la casella di controllo Consistenza del colore globale per ogni grafico.
Nota
Per ottenere questa coerenza, Azure Databricks esegue hashing direttamente dai valori ai colori. Per evitare collisioni (dove due valori passano esattamente allo stesso colore), l'hash utilizza un ampio set di colori, il che ha come effetto collaterale che non si possono garantire colori belli o facilmente distinguibili; con molti colori è inevitabile che ce ne siano alcuni molto simili.
Visualizzazioni di Machine Learning
Oltre ai tipi di grafico standard, le visualizzazioni legacy supportano i parametri e i risultati di training di Machine Learning seguenti:
Residui
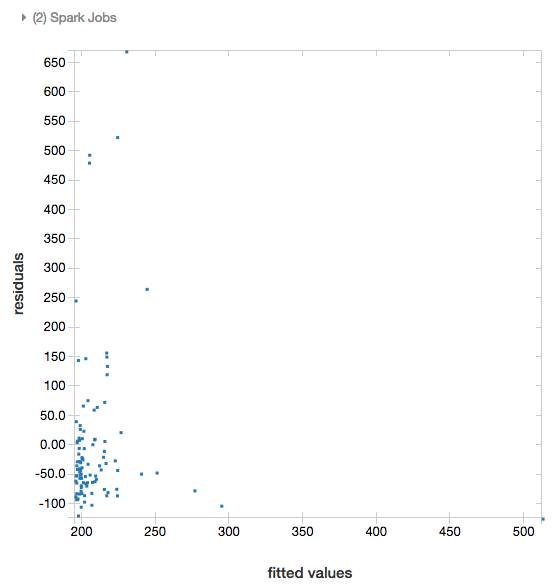
Per le regressioni lineari e logistiche, è possibile creare un grafico di adattamento rispetto ai residui. Per ottenere questo tracciato, specificare il modello e il dataframe.
Nell'esempio seguente viene eseguita una regressione lineare sulla popolazione della città in relazione al prezzo di vendita delle case e quindi vengono visualizzati i residui rispetto ai dati adattati.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
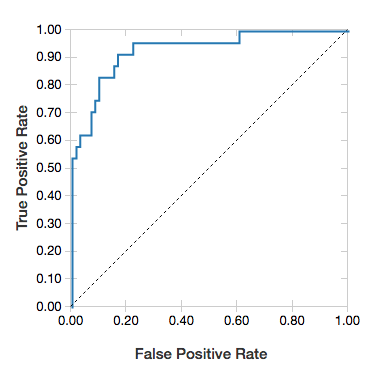
Curve ROC
Per le regressioni logistiche, è possibile eseguire il rendering di una curva ROC . Per ottenere questo tracciato, specificare il modello, i dati prepped immessi per il fit metodo e il parametro "ROC".
L'esempio seguente sviluppa un classificatore che stima se un individuo guadagna <=50.000 o >50.000 all'anno da vari attributi dell'individuo. Il set di dati Adult deriva dai dati del censimento ed è costituito dalle informazioni relative a 48842 individui e al loro reddito annuale.
Il codice di esempio di questa sezione usa la codifica one-hot.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
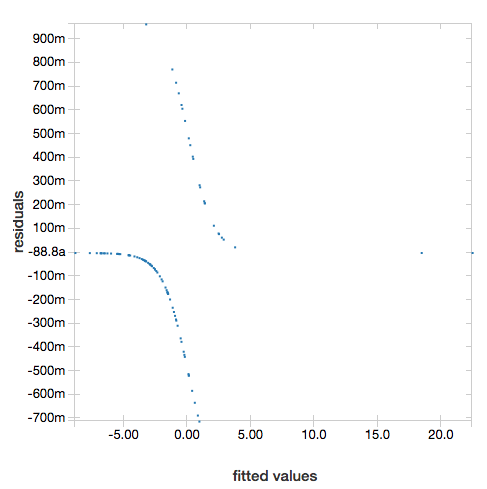
Per visualizzare i residui, omettere il parametro "ROC":
display(lrModel, preppedDataDF)
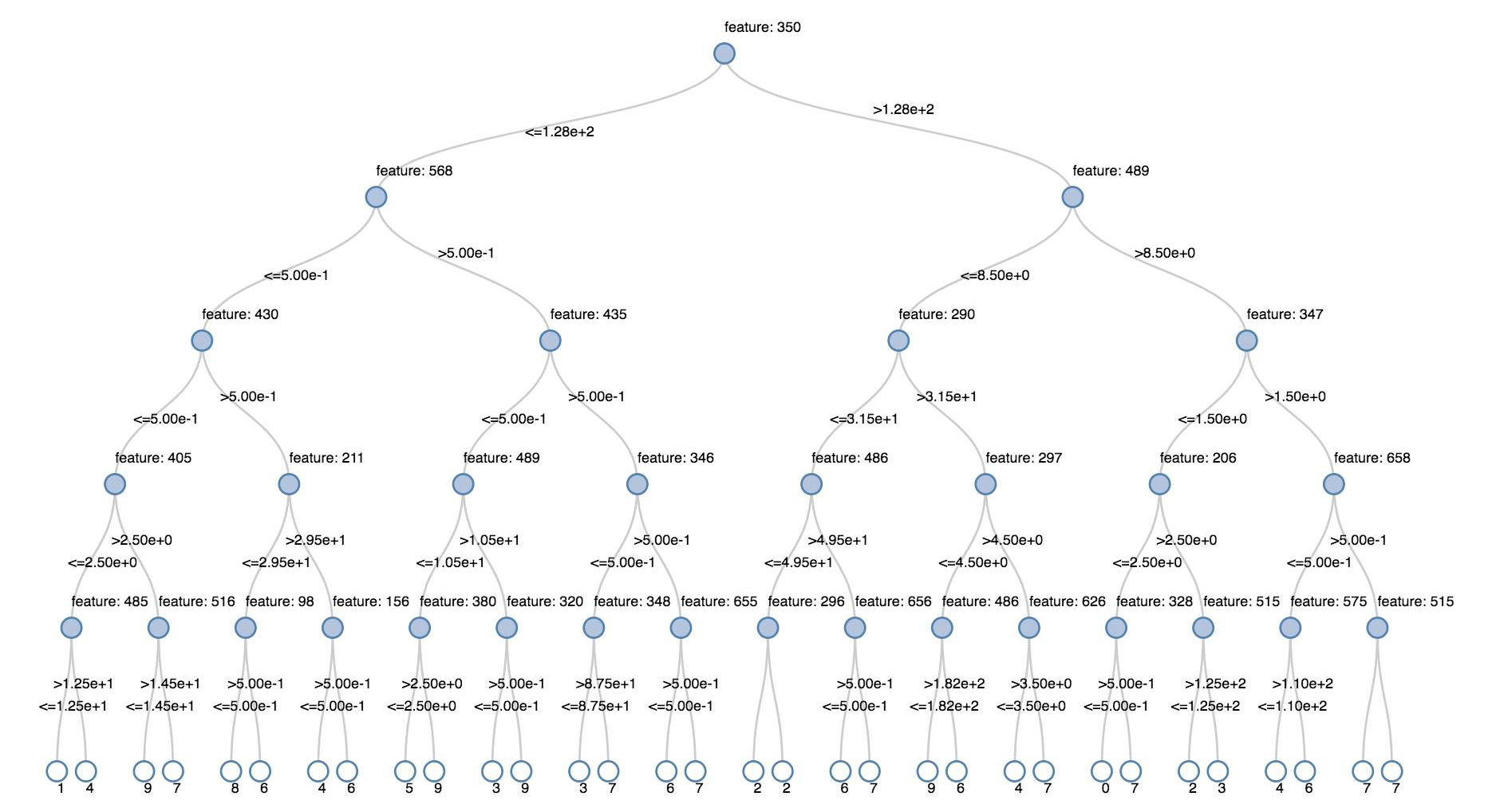
Alberi decisionali
Le visualizzazioni legacy supportano il rendering di un albero delle decisioni.
Per ottenere questa visualizzazione, fornire il modello di albero delle decisioni.
Negli esempi seguenti viene eseguito il training di un albero per riconoscere le cifre (0-9) del set di dati MNIST di immagini di cifre scritte a mano e quindi viene visualizzato l'albero.
Pitone
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Linguaggio di programmazione Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
DataFrame di streaming strutturato
Per visualizzare il risultato di una query di streaming in tempo reale, è possibile usare display per visualizzare un dataframe Structured Streaming in Scala e Python.
Pitone
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Linguaggio di programmazione Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display supporta i parametri facoltativi seguenti:
-
streamName: il nome della query di streaming. -
trigger(Scala) eprocessingTime(Python): definisce la frequenza con cui viene eseguita la query di streaming. Se non specificato, il sistema controlla la disponibilità dei nuovi dati non appena viene completata l'elaborazione precedente. Per ridurre i costi di produzione, Databricks consiglia di sempre impostare un intervallo di trigger. L'intervallo di trigger predefinito è 500 ms. -
checkpointLocation: la posizione in cui il sistema scrive tutte le informazioni sul checkpoint. Se non specificato, il sistema genera automaticamente una posizione di checkpoint temporanea in DBFS. Per consentire al flusso di continuare l'elaborazione dei dati da dove è stata interrotta, è necessario specificare una posizione del checkpoint. Databricks consiglia che in produzione si specifichi sempre l'opzionecheckpointLocation.
Pitone
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Linguaggio di programmazione Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Per altre informazioni su questi parametri, vedere Avvio di query di streaming.
Funzione displayHTML
I notebook nei linguaggi di programmazione di Azure Databricks (Python, R e Scala) supportano la grafica HTML tramite la funzione displayHTML, pertanto è possibile passare qualsiasi codice HTML, CSS o JavaScript alla funzione. Questa funzione supporta la grafica interattiva tramite librerie JavaScript come D3.
Per esempi dell'uso di displayHTML, vedere:
Nota
L'iframe displayHTML viene servito dal dominio databricksusercontent.com e la sandbox dell'iframe include l'attributo allow-same-origin.
databricksusercontent.com deve essere accessibile dal browser. Se è attualmente bloccato dalla rete aziendale, deve essere aggiunto a un elenco di elementi consentiti.
Immagini
Le colonne che contengono tipi di dati immagine sono visualizzate come HTML avanzato. Azure Databricks tenta di eseguire il rendering delle anteprime delle immagini per DataFrame colonne che corrispondono allo schema di immagine Spark .
Il rendering delle miniature funziona per tutte le immagini lette correttamente tramite la funzione spark.read.format('image'). Per i valori di immagine generati tramite altri mezzi, Azure Databricks supporta il rendering di 1, 3 o 4 immagini di canale (dove ogni canale è costituito da un singolo byte), con i vincoli seguenti:
-
Immagini a unico canale: il campo
modedeve essere uguale a 0. I campiheight,widthenChannelsdevono descrivere in modo accurato i dati di immagine binari nel campodata. -
Immagini a tre canali: il campo
modedeve essere uguale a 16. I campiheight,widthenChannelsdevono descrivere in modo accurato i dati di immagine binari nel campodata. Il campodatadeve contenere i dati di pixel in blocchi da tre byte, con l'ordinamento dei canali(blue, green, red)per ogni pixel. -
Immagini a quattro canali: il campo
modedeve essere uguale a 24. I campiheight,widthenChannelsdevono descrivere in modo accurato i dati di immagine binari nel campodata. Il campodatadeve contenere i dati di pixel in blocchi da quattro byte, con l'ordinamento dei canali(blue, green, red, alpha)per ogni pixel.
Esempio
Si supponga di disporre di una cartella contenente alcune immagini:

Se si leggono le immagini in un dataframe e quindi si visualizza il dataframe, Azure Databricks esegue il rendering delle anteprime delle immagini:
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Visualizzazioni in Python
Contenuto della sezione:
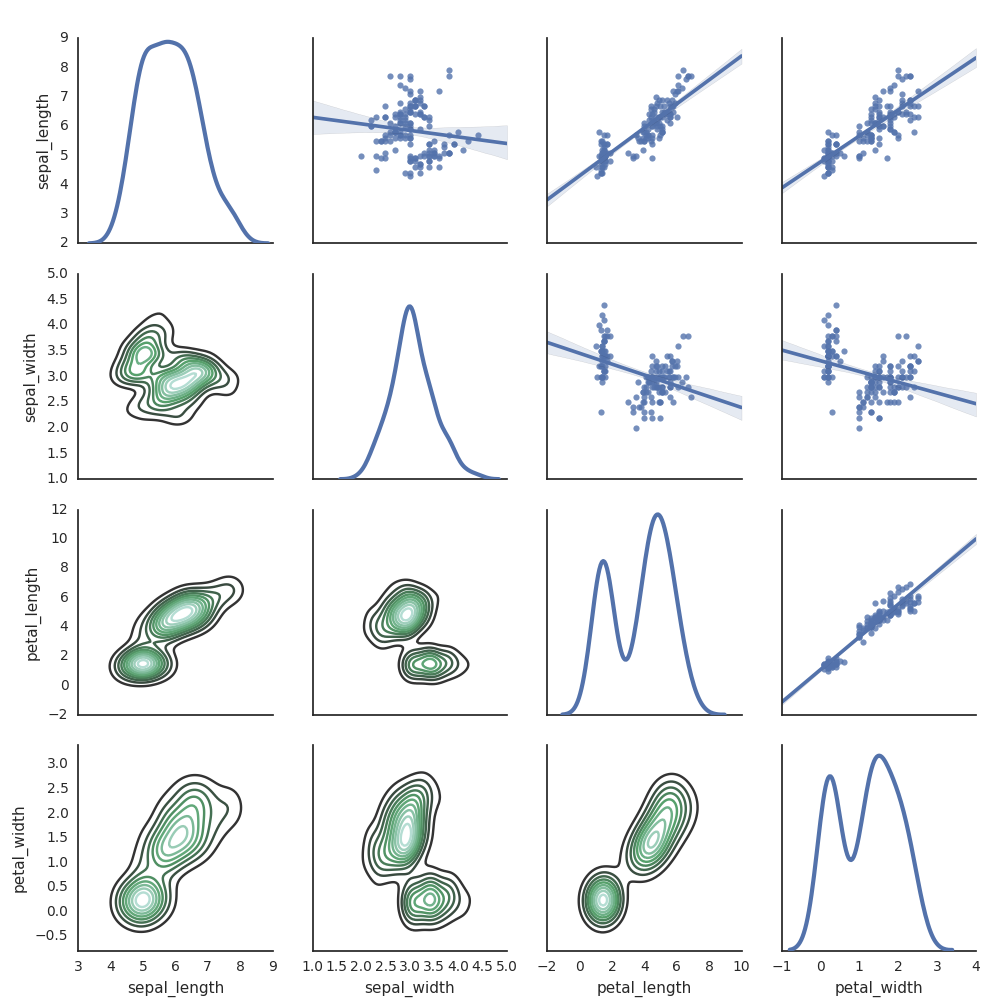
Seaborn
È anche possibile usare altre librerie Python per generare tracciati. Databricks Runtime include la libreria per visualizzazioni seaborn. Per creare un tracciato seaborn, importare la libreria, creare un tracciato e passarlo alla funzione display.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
Altre librerie Python
Visualizzazioni in R
Per tracciare i dati in R, usare la funzione display come segue:
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
È possibile usare la funzione predefinita plot di R.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
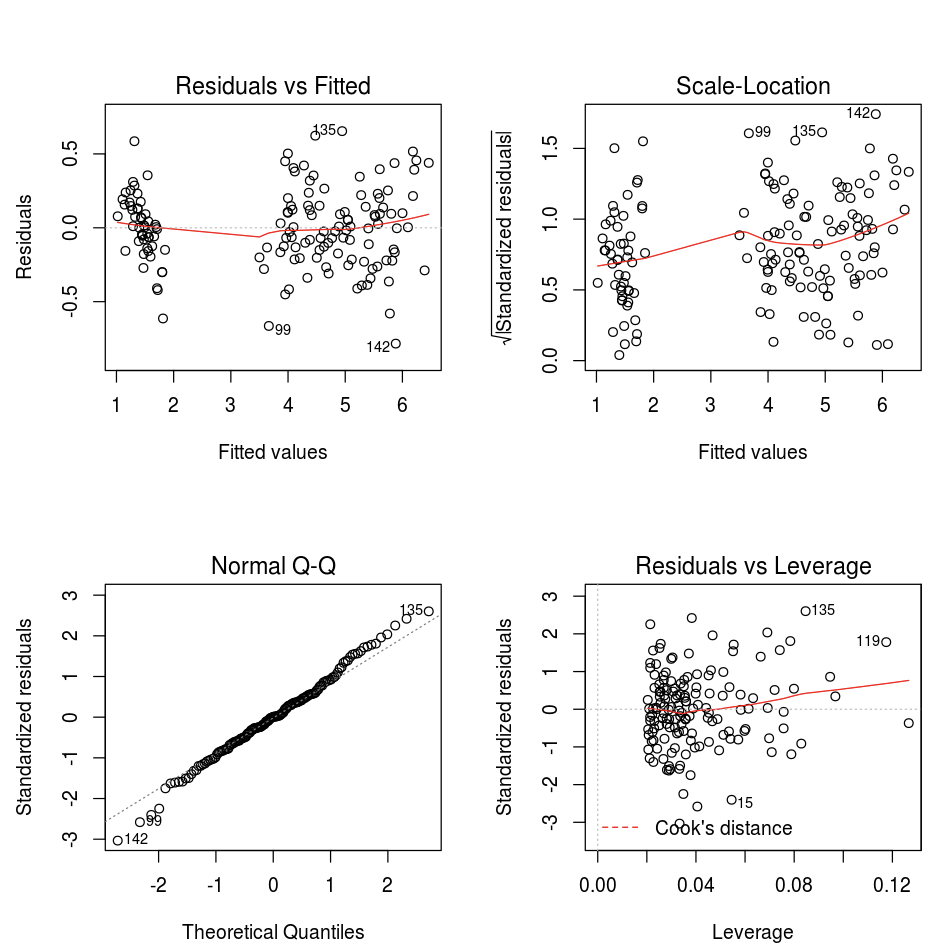
È anche possibile usare qualsiasi pacchetto di visualizzazione R. Il notebook R acquisisce il tracciato risultante come .png e lo visualizza in linea.
Contenuto della sezione:
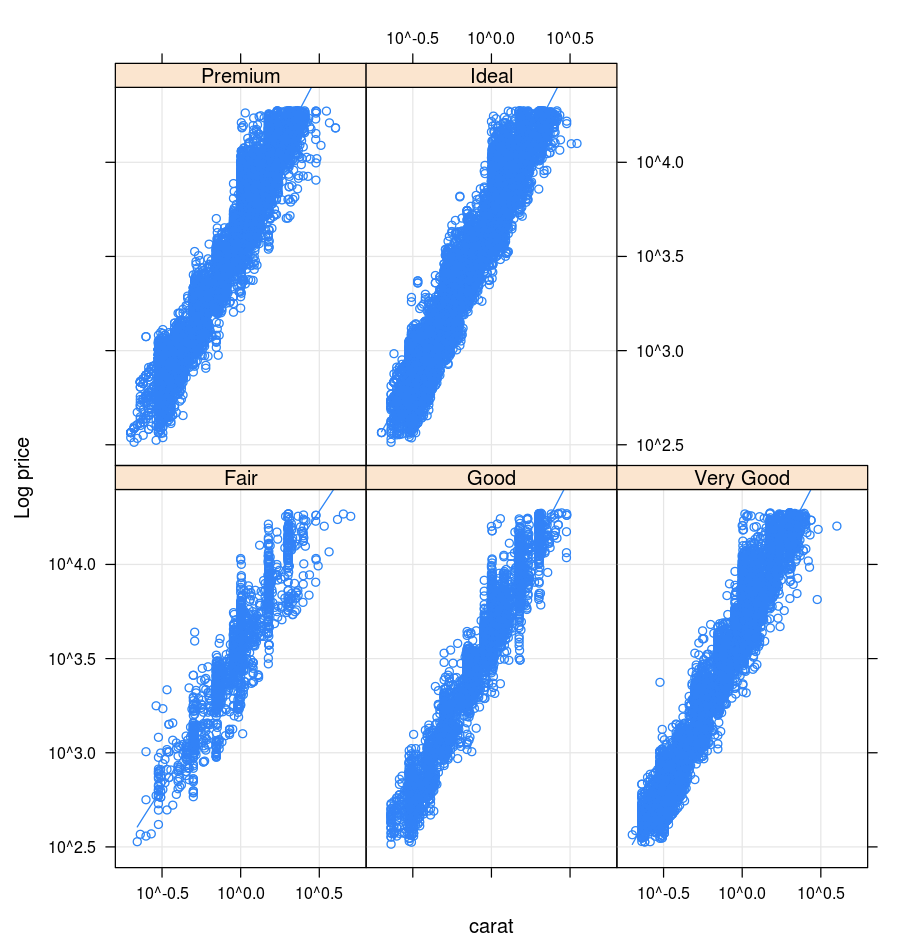
Traliccio
Il pacchetto Lattice supporta i grafici a traliccio, ovvero grafici che visualizzano una variabile o la relazione tra variabili, subordinata a una o più altre variabili.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
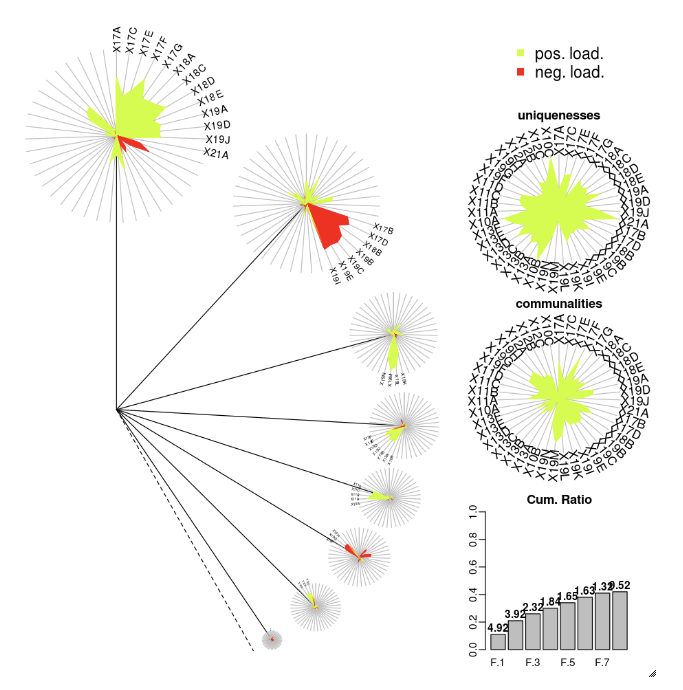
DandEFA
Il pacchetto DandEFA supporta i tracciati dandelion.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
Plotly
Il pacchetto Plotly R si basa su htmlwidgets per R. Per istruzioni di installazione e un notebook, vedere htmlwidgets.
Altre librerie R
Visualizzazioni in Scala
Per tracciare i dati in Scala, usare la funzione display come segue:
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Notebook di approfondimento per Python e Scala
Per un approfondimento sulle visualizzazioni Python, vedere il notebook:
Per un approfondimento sulle visualizzazioni in Scala, vedi il notebook: