Orchestrare i processi di Azure Databricks con Apache Airflow
Questo articolo descrive il supporto di Apache Airflow per orchestrare le pipeline di dati con Azure Databricks, contiene istruzioni per l'installazione e la configurazione di Airflow in locale e fornisce un esempio di distribuzione ed esecuzione di un flusso di lavoro di Azure Databricks con Airflow.
Orchestrazione dei processi in una pipeline di dati
Lo sviluppo e la distribuzione di una pipeline di elaborazione dati spesso richiedono la gestione di dipendenze complesse tra le attività. Ad esempio, una pipeline potrebbe leggere i dati da un'origine, pulire i dati, trasformare i dati puliti e scrivere i dati trasformati in una destinazione. È anche necessario il supporto per i test, la pianificazione e la risoluzione degli errori durante l'operazionalizzazione di una pipeline.
I sistemi del flusso di lavoro affrontano questi problemi consentendo di definire le dipendenze tra attività, pianificare l'esecuzione delle pipeline e monitorare i flussi di lavoro. Apache Airflow è una soluzione open source per la gestione e la pianificazione delle pipeline di dati. Il flusso di aria rappresenta le pipeline di dati come grafici aciclici diretti (DAG) di operazioni. Si definisce un flusso di lavoro in un file Python e Airflow gestisce la pianificazione e l'esecuzione. La connessione Airflow di Azure Databricks consente di sfruttare il motore Spark ottimizzato offerto da Azure Databricks con le funzionalità di pianificazione di Airflow.
Requisiti
- L'integrazione tra Airflow e Azure Databricks richiede Airflow versione 2.5.0 e successive. Gli esempi in questo articolo vengono testati con Airflow versione 2.6.1.
- Airflow richiede Python 3.8, 3.9, 3.10 o 3.11. Gli esempi in questo articolo vengono testati con Python 3.8.
- Le istruzioni in questo articolo per installare ed eseguire Airflow richiedono pipenv per creare un ambiente virtuale Python.
Operatori del flusso di aria per Databricks
Un DAG airflow è costituito da attività, in cui ogni attività esegue un operatore airflow. Gli operatori airflow che supportano l'integrazione con Databricks vengono implementati nel provider Databricks.
Il provider Databricks include operatori per eseguire diverse attività in un'area di lavoro di Azure Databricks, tra cui l'importazione di dati in una tabella, l'esecuzione di query SQL e l'uso delle cartelle Git di Databricks.
Il provider Databricks implementa due operatori per l'attivazione dei processi:
- DatabricksRunNowOperator richiede un processo di Azure Databricks esistente e usa la richiesta API POST /api/2.1/jobs/run-now per attivare un'esecuzione. Databricks consiglia di usare
DatabricksRunNowOperatorperché riduce la duplicazione delle definizioni di processo e le esecuzioni di processi attivate con questo operatore sono disponibili nell'interfaccia utente processi. - DatabricksSubmitRunOperator non richiede l'esistenza di un processo in Azure Databricks e usa la richiesta POST /api/2.1/jobs/runs/submit API per inviare la specifica del processo e attivare un'esecuzione.
Per creare un nuovo processo di Azure Databricks o reimpostare un processo esistente, il provider Databricks implementa DatabricksCreateJobsOperator. DatabricksCreateJobsOperator usa le richieste API POST /api/2.1/jobs/create e POST /api/2.1/jobs/reset. È possibile usare DatabricksCreateJobsOperator con per DatabricksRunNowOperator creare ed eseguire un processo.
Nota
L'uso degli operatori di Databricks per attivare un processo richiede la fornitura di credenziali nella configurazione della connessione Databricks. Vedere Creare un token di accesso personale di Azure Databricks per Airflow.
Gli operatori Databricks Airflow scrivono l'URL della pagina di esecuzione del processo nei log airflow ogni polling_period_seconds (il valore predefinito è 30 secondi). Per altre informazioni, vedere la pagina del pacchetto apache-airflow-providers-databricks nel sito Web Airflow.
Installare l'integrazione di Airflow di Azure Databricks in locale
Per installare Airflow e il provider Databricks in locale per il test e lo sviluppo, seguire questa procedura. Per altre opzioni di installazione di Airflow, inclusa la creazione di un'installazione di produzione, vedere installazione nella documentazione di Airflow.
Aprire un terminale ed eseguire i comandi seguenti:
mkdir airflow
cd airflow
pipenv --python 3.8
pipenv shell
export AIRFLOW_HOME=$(pwd)
pipenv install apache-airflow
pipenv install apache-airflow-providers-databricks
mkdir dags
airflow db init
airflow users create --username admin --firstname <firstname> --lastname <lastname> --role Admin --email <email>
Sostituire <firstname>, <lastname>e <email> con il nome utente e l'indirizzo di posta elettronica. Verrà richiesto di immettere una password per l'utente amministratore. Assicurarsi di salvare questa password perché è necessario accedere all'interfaccia utente di Airflow.
Questo script esegue i passaggi seguenti:
- Crea una directory denominata
airflowe cambia in tale directory. pipenvUsa per creare e generare un ambiente virtuale Python. Databricks consiglia di usare un ambiente virtuale Python per isolare le versioni dei pacchetti e le dipendenze del codice in tale ambiente. Questo isolamento consente di ridurre le mancate corrispondenze impreviste della versione del pacchetto e i conflitti di dipendenza del codice.- Inizializza una variabile di ambiente denominata
AIRFLOW_HOMEimpostata sul percorso dellaairflowdirectory. - Installa Airflow e i pacchetti del provider Airflow Databricks.
- Crea una
airflow/dagsdirectory. Airflow usa ladagsdirectory per archiviare le definizioni di DAG. - Inizializza un database SQLite usato da Airflow per tenere traccia dei metadati. In una distribuzione airflow di produzione è necessario configurare Airflow con un database standard. Il database SQLite e la configurazione predefinita per la
airflowdistribuzione airflow vengono inizializzati nella directory . - Crea un utente amministratore per Airflow.
Suggerimento
Per confermare l'installazione del provider Databricks, eseguire il comando seguente nella directory di installazione di Airflow:
airflow providers list
Avviare il server Web Airflow e l'utilità di pianificazione
Il server Web Airflow è necessario per visualizzare l'interfaccia utente airflow. Per avviare il server Web, aprire un terminale nella directory di installazione di Airflow ed eseguire i comandi seguenti:
Nota
Se l'avvio del server Web Airflow non riesce a causa di un conflitto di porte, è possibile modificare la porta predefinita nella configurazione Airflow.
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow webserver
L'utilità di pianificazione è il componente Airflow che pianifica i DAG. Per avviare l'utilità di pianificazione, aprire un nuovo terminale nella directory di installazione di Airflow ed eseguire i comandi seguenti:
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow scheduler
Testare l'installazione di Airflow
Per verificare l'installazione di Airflow, è possibile eseguire uno dei DAG di esempio inclusi in Airflow:
- In una finestra del browser aprire
http://localhost:8080/home. Accedere all'interfaccia utente di Airflow con il nome utente e la password creati durante l'installazione di Airflow. Viene visualizzata la pagina DaG Airflow. - Fare clic sull'interruttore DAG Pause/Unpause (Sospendi/Annulla) per annullare la sospensione di uno dei gruppi di disponibilità di esempio,
example_python_operatorad esempio . - Attivare il DAG di esempio facendo clic sul pulsante Trigger DAG (Trigger DAG ).
- Fare clic sul nome del dag per visualizzare i dettagli, incluso lo stato di esecuzione del DAG.
Creare un token di accesso personale di Azure Databricks per Airflow
Airflow si connette a Databricks usando un token di accesso personale di Azure Databricks. Per creare un token di accesso personale:
- Nell'area di lavoro di Azure Databricks fare clic sul nome utente di Azure Databricks nella barra superiore e quindi selezionare Impostazioni nell'elenco a discesa.
- Fare clic su Sviluppatore.
- Accanto a Token di accesso fare clic su Gestisci.
- Fare clic su Generare nuovi token.
- (Facoltativo) Immettere un commento che consente di identificare questo token in futuro e modificare la durata predefinita del token di 90 giorni. Per creare un token senza durata (scelta non consigliata), lasciare vuota la casella Durata (giorni) (vuota).
- Fare clic su Genera.
- Copiare il token visualizzato in un percorso sicuro e quindi fare clic su Fine.
Nota
Assicurarsi di salvare il token copiato in un percorso sicuro. Non condividere il token copiato con altri utenti. Se si perde il token copiato, non è possibile rigenerare lo stesso token esatto. È invece necessario ripetere questa procedura per creare un nuovo token. Se si perde il token copiato o si ritiene che il token sia stato compromesso, Databricks consiglia vivamente di eliminare immediatamente il token dall'area di lavoro facendo clic sull'icona del cestino (Revoca) accanto al token nella pagina Token di accesso.
Se non è possibile creare o usare token nell'area di lavoro, questo potrebbe essere dovuto al fatto che l'amministratore dell'area di lavoro ha disabilitato i token o non ha concesso l'autorizzazione per creare o usare token. Vedere l'amministratore dell'area di lavoro o quanto segue:
Nota
Come procedura consigliata per la sicurezza, quando si esegue l'autenticazione con strumenti automatizzati, sistemi, script e app, Databricks consiglia di usare token di accesso personali appartenenti alle entità servizio anziché agli utenti dell'area di lavoro. Per creare token per le entità servizio, vedere Gestire i token per un'entità servizio.
È anche possibile eseguire l'autenticazione ad Azure Databricks usando un token microsoft Entra ID (in precedenza Azure Active Directory). Vedere Databricks Connection (Connessione a Databricks) nella documentazione di Airflow.
Configurare una connessione di Azure Databricks
L'installazione di Airflow contiene una connessione predefinita per Azure Databricks. Per aggiornare la connessione per connettersi all'area di lavoro usando il token di accesso personale creato in precedenza:
- In una finestra del browser aprire
http://localhost:8080/connection/list/. Se viene richiesto di accedere, immettere il nome utente e la password dell'amministratore. - In ID Conn individuare databricks_default e fare clic sul pulsante Modifica record .
- Sostituire il valore nel campo Host con il nome dell'istanza dell'area di lavoro della distribuzione di Azure Databricks,
https://adb-123456789.cloud.databricks.comad esempio . - Nel campo Password immettere il token di accesso personale di Azure Databricks.
- Fare clic su Salva.
Se si usa un token ID Microsoft Entra, vedere Connessione a Databricks nella documentazione di Airflow per informazioni sulla configurazione dell'autenticazione.
Esempio: Creare un DAG airflow per eseguire un processo di Azure Databricks
L'esempio seguente illustra come creare una semplice distribuzione airflow eseguita nel computer locale e distribuisce un esempio di DAG per attivare le esecuzioni in Azure Databricks. In questo esempio si eseguiranno le seguenti attività:
- Creare un nuovo notebook e aggiungere codice per stampare un messaggio di saluto in base a un parametro configurato.
- Creare un processo di Azure Databricks con una singola attività che esegue il notebook.
- Configurare una connessione Airflow all'area di lavoro di Azure Databricks.
- Creare un DAG Airflow per attivare il processo del notebook. Il dag viene definito in uno script Python usando
DatabricksRunNowOperator. - Usare l'interfaccia utente airflow per attivare il DAG e visualizzare lo stato dell'esecuzione.
Creare un notebook
Questo esempio usa un notebook contenente due celle:
- La prima cella contiene un widget di testo Databricks Utilities che definisce una variabile denominata
greetingimpostata sul valoreworldpredefinito . - La seconda cella stampa il valore della
greetingvariabile preceduta dahello.
Per creare il notebook:
Passare all'area di lavoro di Azure Databricks, fare clic su
 Nuovo nella barra laterale e selezionare Notebook.
Nuovo nella barra laterale e selezionare Notebook.Assegnare un nome al notebook, ad esempio Hello Airflow, e assicurarsi che il linguaggio predefinito sia impostato su Python.
Copiare il codice Python seguente e incollarlo nella prima cella del notebook.
dbutils.widgets.text("greeting", "world", "Greeting") greeting = dbutils.widgets.get("greeting")Aggiungere una nuova cella sotto la prima cella e copiare e incollare il codice Python seguente nella nuova cella:
print("hello {}".format(greeting))
Creare un processo
Fare clic su
 Flussi di lavoro nella barra laterale.
Flussi di lavoro nella barra laterale.Fare clic su
 .
.Viene visualizzata la scheda Attività con la finestra di dialogo Crea attività.
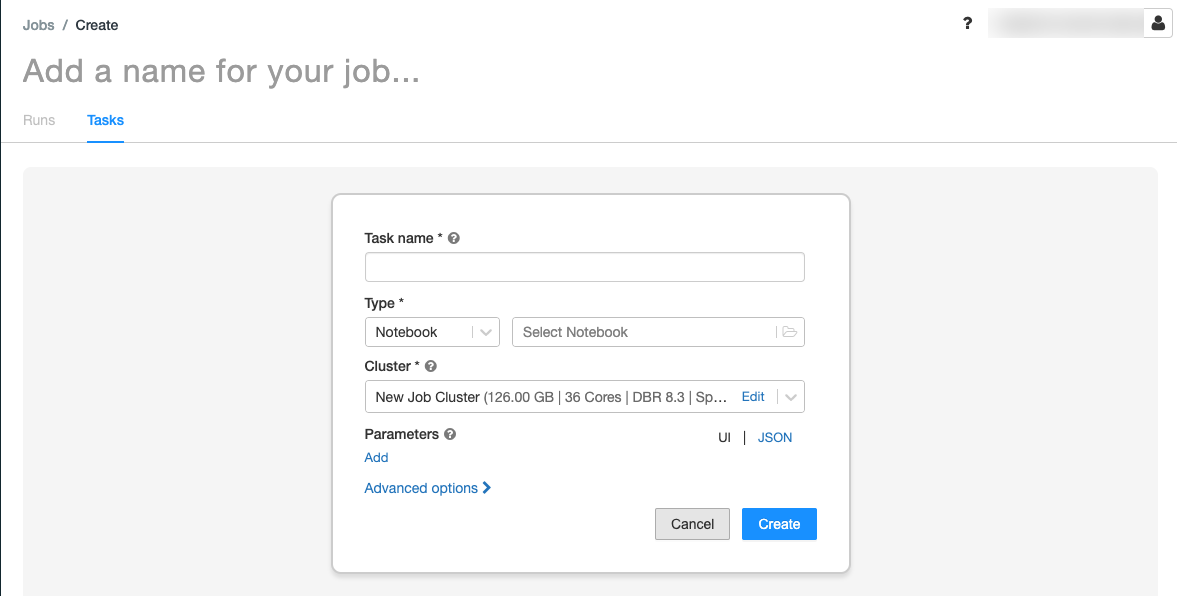
Sostituire Aggiungi un nome per il processo con il nome del processo.
Nel campo Nome attività immettere un nome per l'attività, ad esempio greeting-task.
Nel menu a discesa Tipo selezionare Notebook.
Nel menu a discesa Origine selezionare Area di lavoro.
Fare clic sulla casella di testo Percorso e usare il browser file per trovare il notebook creato, fare clic sul nome del notebook e fare clic su Conferma.
Fare clic su Aggiungi in Parametri. Nel campo Chiave immettere
greeting. Nel campo Valore immettereAirflow user.Fare clic su Crea attività.
Nel pannello Dettagli processo copiare il valore id processo. Questo valore è necessario per attivare il processo da Airflow.
Eseguire il processo
Per testare il nuovo processo nell'interfaccia utente dei flussi di lavoro di Azure Databricks, fare clic  nell'angolo in alto a destra. Al termine dell'esecuzione, è possibile verificare l'output visualizzando i dettagli dell'esecuzione del processo.
nell'angolo in alto a destra. Al termine dell'esecuzione, è possibile verificare l'output visualizzando i dettagli dell'esecuzione del processo.
Creare un nuovo DAG airflow
Si definisce un DAG Airflow in un file Python. Per creare un daG per attivare il processo del notebook di esempio:
In un editor di testo o in un IDE creare un nuovo file denominato
databricks_dag.pycon il contenuto seguente:from airflow import DAG from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator from airflow.utils.dates import days_ago default_args = { 'owner': 'airflow' } with DAG('databricks_dag', start_date = days_ago(2), schedule_interval = None, default_args = default_args ) as dag: opr_run_now = DatabricksRunNowOperator( task_id = 'run_now', databricks_conn_id = 'databricks_default', job_id = JOB_ID )Sostituire
JOB_IDcon il valore dell'ID processo salvato in precedenza.Salvare il file nella
airflow/dagsdirectory. Airflow legge e installa automaticamente i file DAG archiviati inairflow/dags/.
Installare e verificare il DAG in Airflow
Per attivare e verificare il DAG nell'interfaccia utente airflow:
- In una finestra del browser aprire
http://localhost:8080/home. Viene visualizzata la schermata DaG airflow. - Individuare
databricks_dage fare clic sull'interruttore DAG Pause/Unpause per rimuovere il dag. - Attivare il DAG facendo clic sul pulsante Trigger DAG (Trigger DAG ).
- Fare clic su un'esecuzione nella colonna Esecuzioni per visualizzare lo stato e i dettagli dell'esecuzione.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per