Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Le applicazioni full-stack che combinano servizi front-end e back-end sono uno schema comune nello sviluppo Web moderno. L'interfaccia della riga di comando per sviluppatori di Azure (azd) supporta la distribuzione di applicazioni full-stack in cui il front-end e il back-end sono ospitati come servizi separati. Questo articolo illustra come distribuire applicazioni full-stack usando azd ed evidenzia strategie e vantaggi per una distribuzione efficace.
Che cos'è un'implementazione full-stack?
Una distribuzione full-stack con azd è in genere costituita da:
- Servizio front-end: un'applicazione Web rivolta agli utenti, spesso compilata con framework come React, Angular, Vue o Blazor. Il front-end potrebbe essere ospitato come sito statico o come applicazione in contenitori.
- Servizio back-end: un'API o un livello di servizio che gestisce la logica di business, l'accesso ai dati e le integrazioni. Il back-end è in genere ospitato in contenitori o come funzioni serverless.
- Risorse condivise: database, account di archiviazione, insiemi di credenziali delle chiavi e altre risorse di Azure che entrambi i servizi potrebbero usare.
Usando azd, puoi definire entrambi i servizi in un singolo file azure.yaml ed eseguirne il provisioning insieme utilizzando l'infrastruttura come codice (Bicep o Terraform).
Ciclo di vita dell'interfaccia della riga di comando per sviluppatori di Azure
L'interfaccia della riga di comando per sviluppatori di Azure segue un flusso di lavoro strutturato con eventi distinti del ciclo di vita:
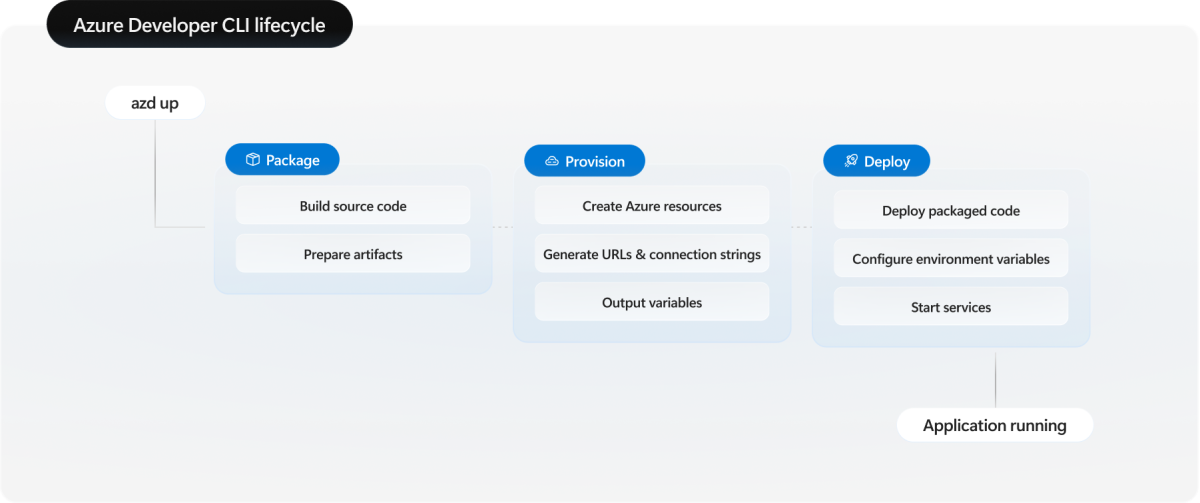
- Pacchetto: compilare il codice sorgente dell'applicazione e preparare gli artefatti per la distribuzione.
- Provision: Creare o aggiornare le risorse dell'infrastruttura di Azure utilizzando Bicep o Terraform.
- Distribuire: Distribuire il codice dell'applicazione impacchettato nell'infrastruttura fornita.
Il azd up comando esegue tutte e tre le fasi in sequenza. È anche possibile eseguire ogni fase in modo indipendente usando azd package, azd provisione azd deploy per un controllo più granulare. Comprendere questo ciclo di vita è essenziale per gestire le dipendenze tra i servizi, in particolare nelle distribuzioni full-stack in cui la tempistica e l'ordine sono importanti.
Per altre informazioni sul ciclo di vita e sulla personalizzazione del azd flusso di lavoro, vedere Esplorare il flusso di lavoro azd up.
Considerazioni sulla progettazione dell'infrastruttura
Quando si progetta un'applicazione full-stack con azd, scegliere i servizi di hosting di Azure appropriati per il front-end e il back-end:
| Tipo di servizio | Opzioni di hosting | Caso d'uso |
|---|---|---|
| Interfaccia utente (Front-end) | App Web statiche di Azure, servizio app di Azure, app contenitore di Azure | Siti statici, applicazioni a pagina singola, app renderizzate lato server |
| Back-end | Azure Container Apps, Azure App Service, Azure Functions, Azure Kubernetes Service | API, microservizi, funzioni serverless |
Scopri di più sull'hosting di applicazioni in Azure.
Comprendere l'interdipendenza tra le applicazioni front-end e back-end
Le distribuzioni full-stack spesso riscontrano problemi di dipendenza circolari in cui ogni servizio necessita di informazioni sull'altro prima che possa essere completamente configurato. Comprendere queste interdipendenze consente di progettare flussi di lavoro di distribuzione efficaci.
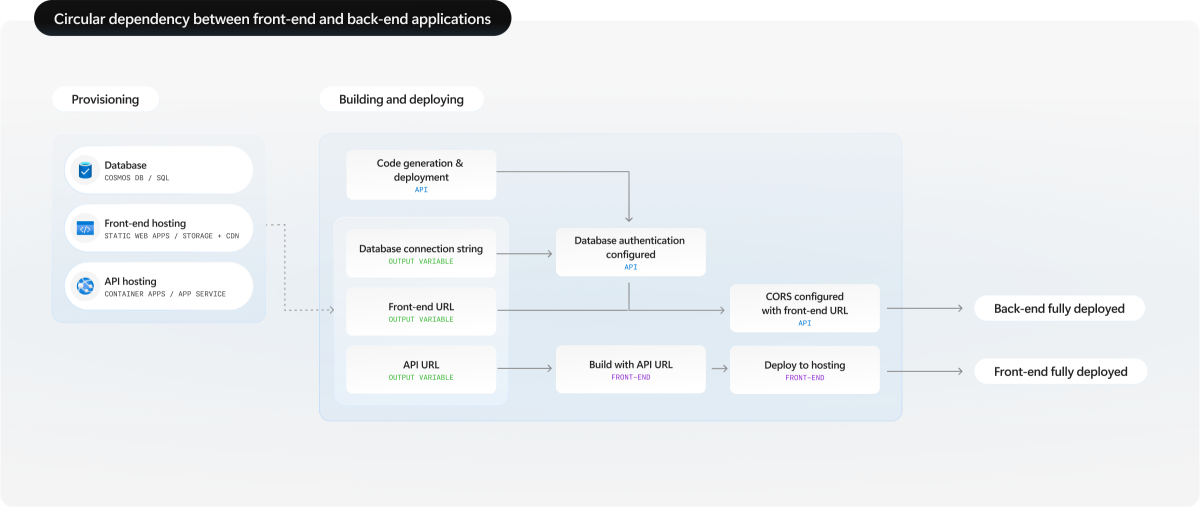
Front-end richiede l'URL back-end: l'applicazione front-end deve in genere conoscere l'URL dell'endpoint dell'API back-end in fase di compilazione o runtime. Tuttavia, il servizio back-end non ha un URL finché non viene distribuito in Azure.
Il back-end richiede l'URL front-end: il servizio back-end potrebbe richiedere l'URL front-end per configurare i criteri CORS, ma il front-end non ha un URL finché non viene distribuito.
Dipendenze delle risorse condivise: entrambi i servizi possono dipendere da risorse condivise come database, insiemi di credenziali delle chiavi o account di archiviazione. È necessario effettuare il provisioning di queste risorse prima che uno dei due servizi possa essere configurato per usarle.
Configurazione specifica dell'ambiente: ambienti diversi (sviluppo, gestione temporanea, produzione) richiedono URL e configurazioni degli endpoint diversi, ma questi valori non sono noti fino al completamento del provisioning.
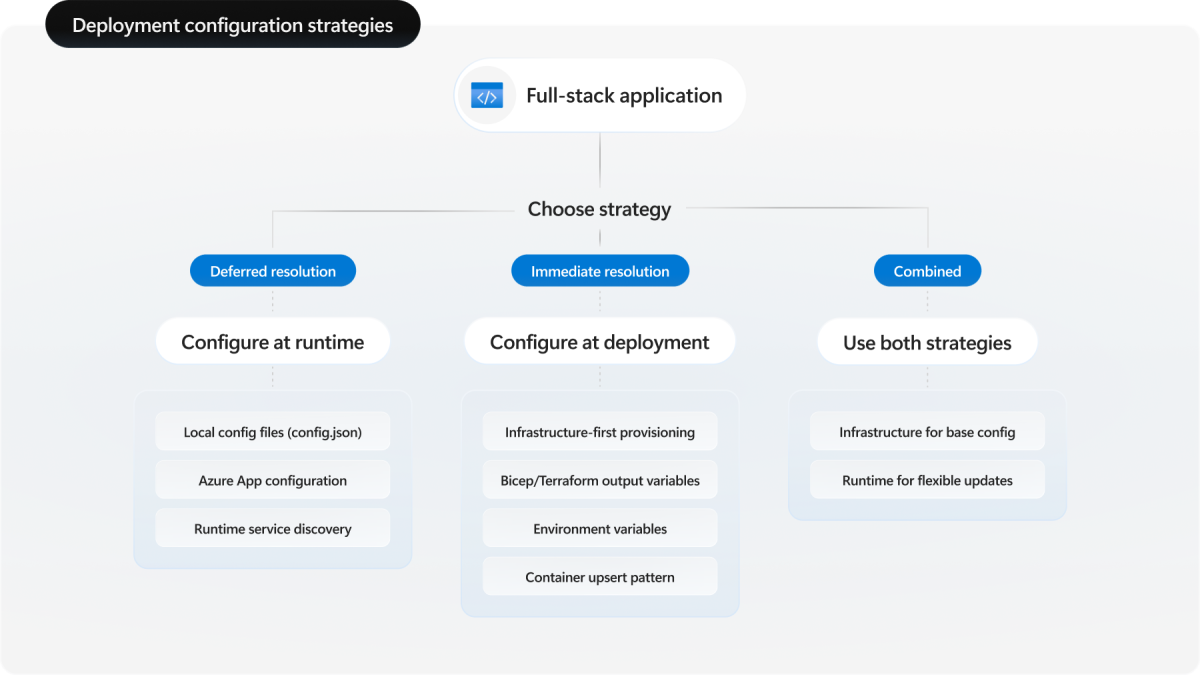
Informazioni sulle strategie di configurazione
L'interfaccia della riga di comando per sviluppatori di Azure gestisce queste interdipendenze tramite due approcci:
- Configurazione in fase di distribuzione: risolvere le dipendenze durante il provisioning e la distribuzione
- Configurazione di runtime: rinviare la configurazione delle dipendenze a quando viene eseguita l'applicazione
Questi approcci rappresentano le decisioni di progettazione prese durante la compilazione dell'applicazione. È possibile usare una strategia esclusivamente o combinare entrambe a seconda dell'architettura e dei requisiti.
Configurazione della fase di distribuzione
La configurazione in fase di distribuzione indica che le connessioni e le configurazioni del servizio vengono determinate e bloccate durante le fasi azd provision e azd deploy. Usando questo approccio, è possibile configurare i servizi con URL di endpoint specifici, stringhe di connessione e altre informazioni sulle dipendenze prima di iniziare l'esecuzione. Questa configurazione diventa parte dell'ambiente del servizio distribuito, come variabili di ambiente o nei file di configurazione inclusi nella distribuzione.
Provisioning prioritario dell'infrastruttura: quando si esegue azd up o azd provision, l'infrastruttura viene creata per prima. Questo passaggio genera gli URL e le stringhe di connessione necessari prima dell'inizio della distribuzione, assicurando che i servizi dipendenti dispongano delle informazioni necessarie.
Variabili di output: Bicep e Terraform possono restituire valori, ad esempio URL e stringhe di connessione, dopo il provisioning. Questi output diventano disponibili come variabili di ambiente durante la fase di distribuzione, in modo da poter configurare i servizi con gli endpoint corretti prima dell'avvio.
Distribuzione sequenziale: per scenari complessi, potrebbe essere necessario distribuire i servizi in un ordine specifico. Usare azdhook per controllare la sequenza di distribuzione, assicurandosi che i servizi prerequisiti siano in esecuzione prima della distribuzione dei servizi dipendenti.
Modello upsert del contenitore: I Moduli Verificati di Azure forniscono modelli di app per contenitori come questo container-app-upsert che funzionano perfettamente con il flusso di lavoro in due fasi di azd. Durante il provisioning, vengono creati l'infrastruttura e il contenitore iniziale. Durante la distribuzione, azd esegue l'upsert dell'immagine del contenitore con variabili di ambiente aggiornate che includono i valori generati durante il provisioning, ad esempio stringhe di connessione al database o URL del servizio. Questo modello risolve il problema del pollo e dell'uovo consentendo all'infrastruttura di esistere prima e poi aggiornare la configurazione del contenitore con tutte le informazioni sulle dipendenze necessarie.
Flusso di lavoro di esempio per un front-end React con un back-end dell'API contenitore:
- Eseguire
azd up, che esegue le fasi di packaging, provisioning e distribuzione in sequenza. - Durante il provisioning, Bicep crea l'infrastruttura di Azure Container Apps usando i moduli AVM
container-app-upserte fornisce l'URL dell'API back-end. - Durante la distribuzione,
azdesegue automaticamente l'upsert di entrambi i contenitori con le variabili di ambiente corrette, incluso l'URL dell'API per il front-end. - Entrambi i servizi iniziano con la configurazione corretta. Le esecuzioni future di
azd upoazd deployaggiornano i contenitori con qualsiasi nuovo valore di configurazione.
Configurazione del runtime
La configurazione di runtime consente alle applicazioni di caricare la configurazione quando l'applicazione viene eseguita anziché durante la distribuzione. Questo approccio offre flessibilità per aggiornare endpoint di servizio, stringhe di connessione e criteri senza ridistribuire l'applicazione.
Origini di configurazione: le applicazioni possono caricare la configurazione di runtime da due origini primarie:
File di configurazione locali: distribuire un file di configurazione, ad esempio
config.json, insieme all'applicazione. L'applicazione carica questo file all'avvio per ottenere gli URL dell'endpoint corrente, le impostazioni di autenticazione e altri valori di configurazione. Questo approccio funziona bene per framework lato client come React, Angular, Vue e Blazor WebAssembly che possono recuperare la configurazione all'avvio dell'applicazione nel browser.Servizi di configurazione cloud: usare Configurazione app di Azure o servizi simili per gestire centralmente la configurazione in tutti gli ambienti. Le applicazioni eseguono query sul servizio di configurazione all'avvio o su richiesta per recuperare i valori correnti. Questo approccio è utile per le architetture di microservizi in cui più servizi necessitano di aggiornamenti di configurazione coordinati.
Vantaggi: con entrambi gli approcci, le modifiche alla configurazione diventano immediatamente disponibili senza ridistribuire. Aggiornare il file di configurazione tramite la pipeline di distribuzione o modificare i valori in Configurazione app di Azure tramite il portale di Azure. Quando l'applicazione viene riavviata o aggiornata la configurazione, vengono prelevati i nuovi valori. Questo modello è particolarmente utile per:
- Applicazioni front-end che devono individuare URL API back-end, endpoint di autenticazione e percorsi di microservizi
- Servizi back-end che devono aggiornare i criteri CORS quando cambiano gli URL front-end
- Servizi che richiedono una configurazione diversa tra ambienti di sviluppo, gestione temporanea e produzione
Flusso di lavoro di esempio per un front-end React che individua un'API back-end:
- Eseguire
azd upper effettuare il provisioning dell'infrastruttura e distribuire entrambi i servizi. - Un hook post-deploy genera un file
config.jsoncontenente l'URL back-end e lo carica nell'ubicazione di archiviazione del front-end. - L'app React recupera
config.jsonall'avvio per individuare l'endpoint API. - Per aggiornare l'endpoint in un secondo momento, modificare
config.jsonsenza ridistribuire il front-end.
Questo approccio non funziona per i siti generati in modo statico in cui tutto il contenuto viene pre-sottoposto a rendering in fase di compilazione.
Pianificare il processo di distribuzione del flusso di lavoro
Prendere in considerazione questi fattori durante la progettazione della distribuzione full-stack:
- Identificare le dipendenze: Mappare i servizi che necessitano di informazioni da altri servizi. Per le dipendenze unidirezionali, ad esempio un'API dipendente da un database, la piattaforma di provisioning (Bicep o Terraform) gestisce l'ordinamento automaticamente. Per le dipendenze circolari, ad esempio i servizi front-end e back-end che richiedono entrambi gli URL all'avvio, è necessario progettare il coordinamento impiegando strategie di configurazione al momento del deployment o runtime.
- Provisioning prima della distribuzione: assicurarsi che tutta l'infrastruttura esista prima di distribuire il codice applicativo.
- Usare le variabili di ambiente: passare la configurazione tra i livelli dell'infrastruttura e dell'applicazione usando le variabili di ambiente azd.
- Progettare per più ambienti: pianificare le differenze di configurazione tra gli ambienti di sviluppo, gestione temporanea e produzione.
- Prendere in considerazione l'ordine di distribuzione: alcuni scenari potrebbero richiedere la distribuzione di servizi in una sequenza specifica.
Il azd up comando gestisce la maggior parte degli scenari di distribuzione eseguendo automaticamente il provisioning seguito dalla distribuzione in un singolo flusso di lavoro. Per le singole applicazioni standard, questo approccio funziona correttamente e richiede una configurazione minima.
Per distribuzioni più complesse, ad esempio lo stack completo con dipendenze circolari:
Configurare l'ordine di servizio: nel
azure.yamlfile definire i servizi nell'ordine in cui devono essere distribuiti. Mentreazddistribuisce i servizi in parallelo per impostazione predefinita, è possibile usare hook per applicare la distribuzione sequenziale quando necessario.Personalizzare i passaggi del flusso di lavoro: eseguire l'override del flusso di lavoro predefinito definendo una proprietà personalizzata
azd upworkflowsnelazure.yamlfile. Ad esempio, è possibile modificare il comportamento predefinito per eseguire il provisioning prima di compilare il codice sorgente dell'applicazione:name: todo-nodejs-mongo metadata: template: todo-nodejs-mongo@0.0.1-beta workflows: up: steps: - azd: provision - azd: package - azd: deployQuesto modello è utile quando il processo di compilazione richiede valori di configurazione disponibili solo dopo il completamento del provisioning.
Provision e distribuzione separati: invece di utilizzare
azd up, eseguireazd provisioneazd deploycome comandi distinti. Questa separazione è utile quando è necessario verificare la configurazione dell'infrastruttura prima di distribuire il codice dell'applicazione o per la risoluzione dei problemi di distribuzione. È possibile effettuare il provisioning dell'infrastruttura una sola volta, quindi distribuire e ridistribuire il codice dell'applicazione più volte senza eseguire il provisioning.Personalizzare con gli hook: aggiungere gli hook pre e post nel file
azure.yamlper eseguire logica personalizzata tra le fasi di provisioning e distribuzione. Usare hook per popolare i file di configurazione, convalidare lo stato dell'ambiente o coordinare sequenze di distribuzione complesse.
Procedure consigliate
Quando si compilano applicazioni full-stack con azd, seguire queste procedure consigliate:
- Eseguire il mapping delle dipendenze in anticipo: identificare quali servizi necessitano di informazioni da altri servizi durante la fase di progettazione. Distinguere tra le dipendenze unidirezionali che Bicep o Terraform gestiscono automaticamente e le dipendenze circolari che richiedono strategie di configurazione durante la distribuzione o il runtime.
- Scegliere la strategia di configurazione corretta: usare la configurazione in fase di distribuzione quando i servizi necessitano di una configurazione bloccata in durante la distribuzione. Usare la configurazione di runtime quando è necessaria flessibilità per aggiornare la configurazione senza ridistribuire. Combinare entrambe le strategie quando appropriato.
-
Usare i moduli verificati di Azure : sfruttare i moduli Bicep verificati di Azure , ad esempio
container-app-upsertper le app contenitore. Questi modelli funzionano perfettamente conazdil flusso di lavoro in due fasi per risolvere le dipendenze circolari. -
Personalizzare i flussi di lavoro quando necessario: per le distribuzioni semplici, usare
azd upcon le impostazioni predefinite. Per scenari complessi con dipendenze circolari, personalizzare laworkflowsproprietà nelazure.yamlfile per controllare l'ordine dei pacchetti, il provisioning e i passaggi di distribuzione. - Sfruttare la configurazione di runtime: per la massima flessibilità in tutti gli ambienti, usare Configurazione app di Azure o file di configurazione locali per gestire gli endpoint di servizio e le impostazioni che è possibile aggiornare senza ridistribuire.
- Test in ambienti diversi: assicurarsi che la strategia di configurazione funzioni correttamente in ambienti di sviluppo, gestione temporanea e produzione in cui gli URL e le configurazioni del servizio differiscono.