Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Azure DevOps Services | Azure DevOps Server 2022 - Azure DevOps Server 2019
Git ha guadagnato molta popolarità negli ultimi anni come repository di codice sorgente distribuito che consente agli utenti di lavorare con il repository completo in uno stato disconnesso. I vantaggi di Git sono ben documentati, ma cosa accade se è necessario eseguire il rollback dell'orologio nel repository primario? Questa operazione non è così intuitiva e richiede autorizzazioni elevate, come ci si potrebbe aspettare per un elemento che influisce su ogni singolo utente del repository.
In che modo è possibile eseguire il rollback del repository centrale in modo sicuro?
Scenario del problema
Si supponga di eseguire il commit di un file di grandi dimensioni, ad esempio un video, nel server Git. In un sistema di codice sorgente tradizionale, è conveniente archiviare tutto in un'unica posizione e quindi tirare giù ciò che serve. Tuttavia, con Git, l'intero repository viene clonato nel computer locale di ogni utente. Con un file di grandi dimensioni, anche ogni singolo utente del progetto dovrà scaricare i file di grandi dimensioni. Con ogni file di grandi dimensioni successivo commesso sul server, il problema continua a crescere finché il repository non diventa troppo grande per essere efficiente per gli utenti. A peggiorare le cose, anche se si rimuove l'elemento problematico dal repository locale e si esegue un nuovo commit, il file continuerà a esistere nella cronologia del repository, il che significa che verrà ancora scaricato sui computer locali di tutti come parte della cronologia.
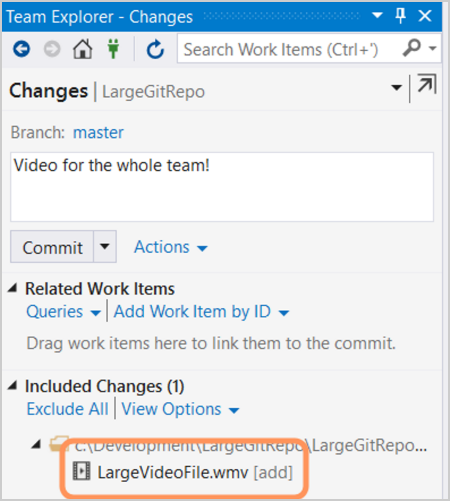
Aggiunta di file di grandi dimensioni nel repository locale
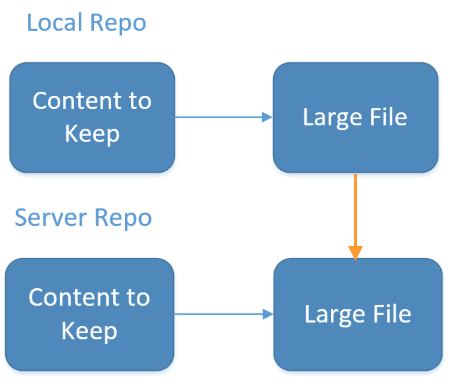
Dopo il commit dal repository locale, il server avrà anche il file di grandi dimensioni
Bloccare il repository
Importante
La procedura seguente rimuoverà il video dalla cronologia dei rami, ma il file rimane nella cronologia dei repository quando si clona il repository da Azure Repos. La rimozione dei file dalla cronologia del tuo branch evita che i file vengano aggiornati, il che creerà un'altra versione del file di grandi dimensioni nel tuo repository. Altre informazioni su la gestione di file di grandi dimensioni in Git e consulta questo post del blog per ulteriori spiegazioni e approfondire le soluzioni alternative per questo comportamento quando si usano repository Git di Azure Repos.
Per risolvere questo problema, è necessario iniziare dall'origine, che, in questo caso, è il repository del server. Chiedere al team di interrompere il push nel repository, ma se si verificano push aggiuntivi durante questo processo, è necessario tenerne conto anche in modo da non perdere dati.
Rebase e push forzato
Se nessun altro membro del team ha apportato modifiche al repository, di solito tramite un push, puoi seguire la strada più semplice, che consiste nel far apparire il tuo repository locale come desideri (cioè senza il file di grandi dimensioni), e poi forzare l'applicazione delle modifiche al server.
Nota: potrebbe essere necessario clonare o correggere il repository locale prima di iniziare questo lavoro. Ciò potrebbe comportare la perdita di lavoro o modifiche, quindi procedere con cautela.
Per impostazione predefinita, è probabile che sia possibile modificare solo i file di progetto e il repository locali e eseguire il push delle modifiche nel server, quindi non è possibile apportare altre modifiche, ad esempio eliminazioni o ribasing, a livello di server. Sarà quindi necessario acquisire le autorizzazioni push (preferite) o di amministratore del progetto dall'amministratore oppure trovare qualcuno che li ha e che è disposto ad aiutare. Per altre informazioni sulle autorizzazioni Git, vedere qui.
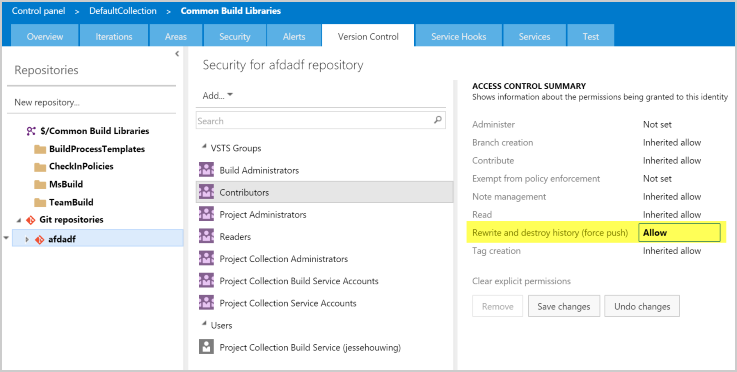
Successivamente, è necessario ribasere il repository.
- Tuttavia, usare
git logprima di tutto per trovare i valori hash SHA dei commit più recenti. Queste informazioni saranno necessarie in un momento. Questo perché è necessario conoscere il commit valido più recente. Per ottenere queste informazioni, aprire un prompt dei comandi Git e digitare:
git log
In alternativa, è possibile ottenere l'hash SHA dalla visualizzazione della cronologia dei rami in Visual Studio Team Explorer.
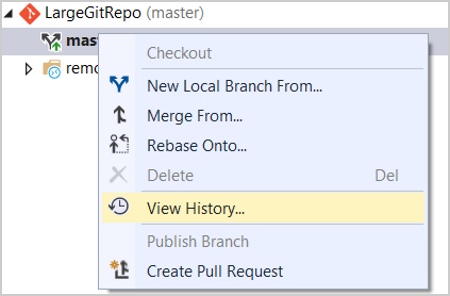
- Ora, apri un prompt dei comandi Git.
Finestra di dialogo di sincronizzazione
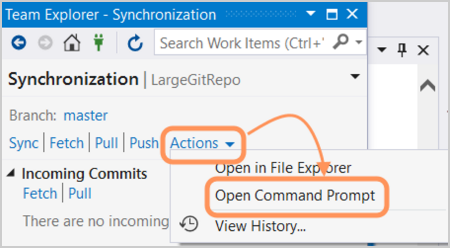
- Trovare il numero hash SHA di interesse.
Prompt dei comandi
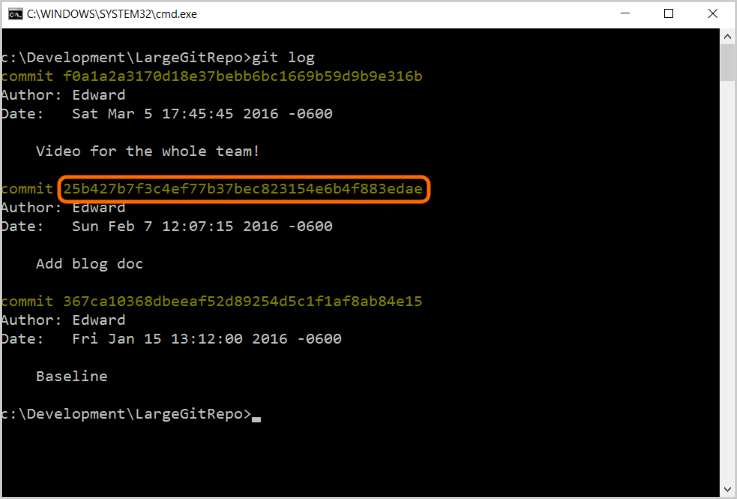
- Avrai bisogno dello SHA che inizia con "25b4"
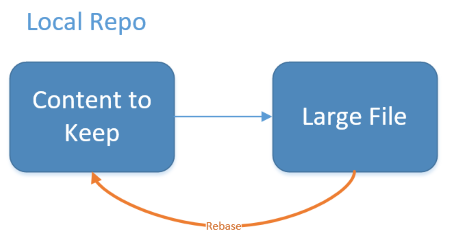
Tenere presente che Git usa i puntatori per determinare dove si trova l'head o il ramo corrente nel repository. Per questo motivo, lo stato del repository a cui si è interessati sarà a un certo punto del passato. Per "tornare indietro nel tempo" e fare in modo che lo stato desiderato precedente sia il nuovo stato corrente, è necessario usare il comando git rebase:
git rebase -i <SHA hash of desired new current branch>
L'opzione -i offre un po' di sicurezza aggiuntiva, perché visualizzerà la cronologia in un editor (l'implementazione di Git nella riga di comando in Windows visualizza il classico vi editor, che si può ricordare se si è lavorato con un sistema basato su Unix.
- Per questo esempio, immettere:
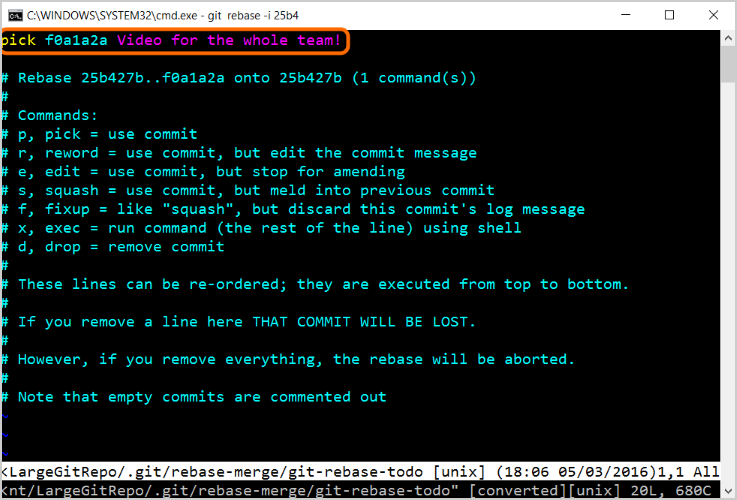
git rebase -i 25b4
- Quando l'editor viene visualizzato, rimuovere tutte le righe "pick", ad eccezione del ramo che si desidera mantenere come nuova testa. Quando tutto appare come vuoi, in vidigitare ":w<premere>" per salvare o "!q<premere>" per uscire senza salvare.
Prompt dei comandi
Si modificheranno le righe che non si desiderano più
prompt dei comandi
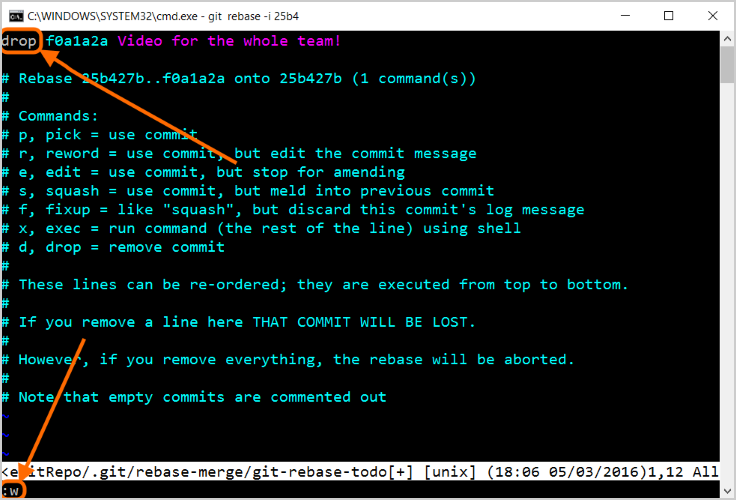
- Modificare "
pick" in "drop" come illustrato, quindi digitare ":w" (in vi) per salvare e ":q!" per avviare il rebase.
Digitare di nuovo git log: il ramo problematico dovrebbe essere assente dal log. In caso affermativo, si è pronti per il passaggio finale, che richiede autorizzazioni di amministratore del progetto.
git log
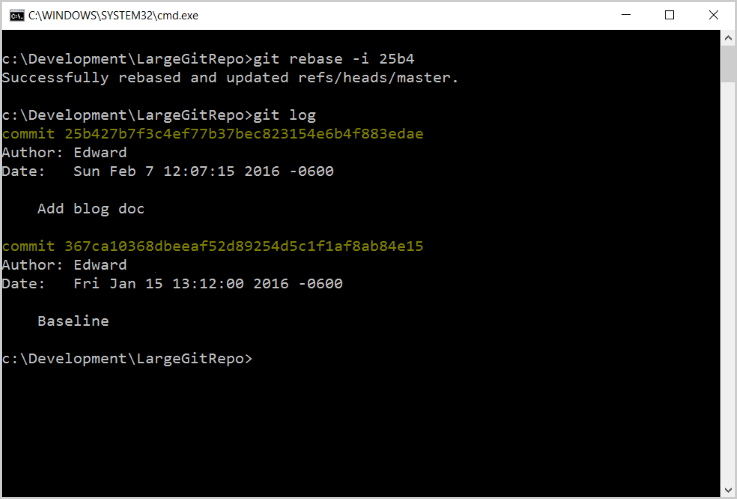
Si noti che il commit per il video di grandi dimensioni è ora sparito dal repository locale
- Tipo:
git push --force
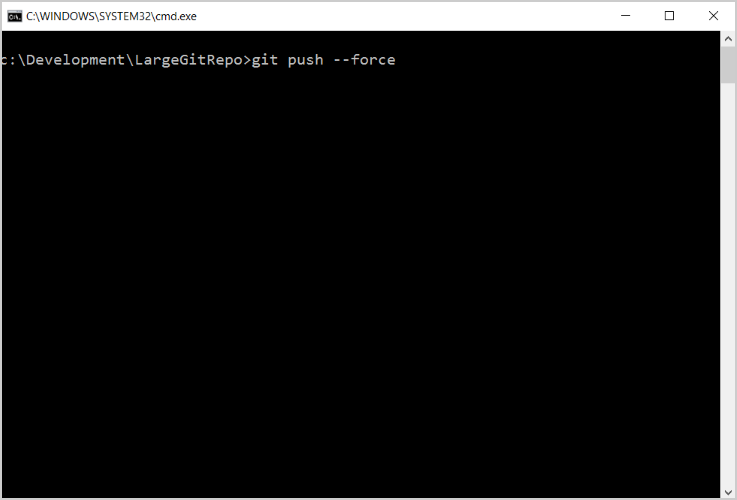
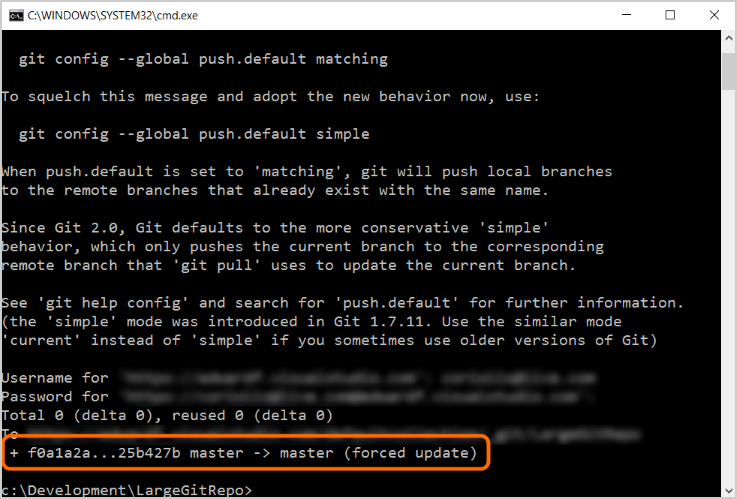
Questo comando costringerà il tuo repository a sovrascrivere il repository sul server.
Usare con cautela, in quanto è possibile perdere facilmente i dati sul server!!
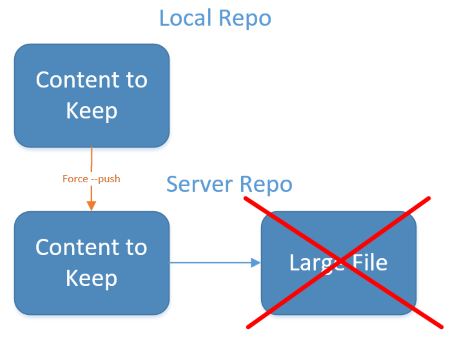
Si noti che è necessario eseguire l'autenticazione nel server affinché funzioni
Se si usa Azure Repos, potrebbe essere necessario configurare una credenziale alternativa che non usa caratteri speciali, ad esempio "@" in un indirizzo di posta elettronica. A tale scopo, seguire le istruzioni qui.
A questo punto, il ramo verrà rimosso definitivamente dal server e i cloni e le sincronizzazioni successivi da parte dei membri del team di progetto non scaricheranno i file di grandi dimensioni che si stava tentando di rimuovere. Gli utenti dovranno eseguire il pull-down dal server per assicurarsi che siano sincronizzati con il nuovo stato del repository del server.
Se gli utenti hanno commit più recenti
Se altri utenti hanno già eseguito il commit nel repository del server, è necessario tenere presente una considerazione aggiuntiva. Si vuole rimuovere il ramo che contiene i file di grandi dimensioni, ma non si vogliono perdere le modifiche apportate dal team. Per affrontare questo, quando l'editor si apre come parte del rebase, esamina attentamente i commit. Assicurarsi che i commit che si desidera conservare siano elencati nelle righe 'pick'; eliminare quelli da rimuovere, ad esempio dove è stato aggiunto un file di grandi dimensioni.
Si noti che, dopo il rebase, anche gli altri utenti del team dovranno eseguire nuovamente il rebase affinché tutti dispongano di una copia coerente del repository del server. Questo è un dolore per tutti e normalmente dovrebbe essere evitato. Pertanto, se è necessario rimuovere un push come indicato qui, è importante coordinarsi con il team. Per informazioni dettagliate sul rebasing, consultare la documentazione ufficiale di rebasing qui.
La chiave consiste nel assicurarsi di sapere quali commit sono desiderati e indesiderati. Esaminare attentamente il log di Git o la cronologia nel proprio IDE (ad esempio Visual Studio) e prendere nota meticolosa degli hash SHA da mantenere ed eliminare.
Negli scenari in cui il file di grandi dimensioni è stato presente per un po' di tempo e sono state eseguite diramazioni e fusioni successive, è possibile rimuovere il file usando l'opzione git filter-branch. Se vuoi provare, segui qui le istruzioni .
Considerazioni sulle procedure consigliate
Risparmia molto lavoro assicurarsi che i file di grandi dimensioni rimangano fuori dal repository principale sin dall'inizio. Tenendo presente questo aspetto, ecco alcune procedure consigliate di buon senso per il team da tenere presente:
Cose da fare
- Fai commit delle modifiche con frequenza. È sempre possibile correggerli successivamente con uno squash o un rebase.
- Usa i rami per isolare le modifiche. I rami sono economici e privati e l'unione è semplice. È anche possibile eseguire il backup delle modifiche in un ramo eseguendo il push nel server.
- Usare una convenzione di denominazione durante la pubblicazione di rami di argomenti. Assegnare al ramo il nome "
users/<alias>/<branchname>". In questo modo sarà possibile raggruppare i rami e semplificare l'identificazione del "proprietario" da parte di altri utenti. - Ricordarsi di eseguire il push delle modifiche.
Commit != Checkin.(Commit + Push) == Checkin. - Considerate di usare
.gitignoreper file binari di grandi dimensioni, così che non vengano aggiunti al repository inizialmente. Maggiori informazioni qui. - Prendere in considerazione l'uso del controllo della versione NuGet o TFS per archiviare i file binari di grandi dimensioni.
Cose da non fare
- Non ribasare dopo aver fatto un push. Il ribasaggio dei commit di cui è stato eseguito il push in Git può non essere valido perché impone a tutti gli altri nel repository di ribasere le modifiche locali e non sarà soddisfatto se è necessario eseguire questa operazione. Il ribasing dei commit di cui è stato eseguito il push nel proprio ramo personale, anche se eseguito il push, non è un'operazione significativa a meno che altre persone non eseguano il pull di tali commit.
- Non eseguire il commit dei file binari nel repository. Git non comprime i file binari nel modo in cui fa TFVC e poiché tutti i repository contengono l'intera cronologia, il commit di file binari implica un ingombro permanente.
Sommario
In alcuni casi, elementi indesiderati, ad esempio file di grandi dimensioni, vengono aggiunti a un repository e devono essere rimossi per mantenere il repository pulito e leggero. Per ottenere questo, puoi mettere in ordine il repository locale usando il comando git rebase, quindi utilizzare il comando git push --force per sovrascrivere il repository sul server con il tuo repository locale.
Autori: Edward Fry e Jesse Houwing | Collegati con gli autori e con ALM | DevOps Rangers qui
(c) 2015 Microsoft Corporation. Tutti i diritti riservati. Questo documento viene fornito "as-is". Le informazioni e i pareri espressi in questo documento, inclusi URL e altri riferimenti al sito Internet, possono cambiare senza preavviso. L'utente si assume tutti i rischi derivanti dal loro utilizzo.
Questo documento non fornisce diritti legali a alcuna proprietà intellettuale in alcun prodotto Microsoft. È consentito copiare e utilizzare il presente documento solo a scopo di riferimento interno.