Azure Data Manager per l'indicizzazione energetica e i flussi di lavoro di ricerca
Tutti i dati e i metadati associati inseriti nella piattaforma vengono indicizzati per abilitare la ricerca. I metadati sono accessibili per garantire la consapevolezza anche quando i dati non sono disponibili.
Servizio indicizzatore
Fornisce Indexer Service un meccanismo per l'indicizzazione di documenti che contengono dati strutturati e non strutturati.
Nota
Questo servizio non è un servizio pubblico e deve essere chiamato internamente da altri servizi di base della piattaforma.
Flusso di lavoro di indicizzazione
Il diagramma seguente illustra il flusso di lavoro di indicizzazione:
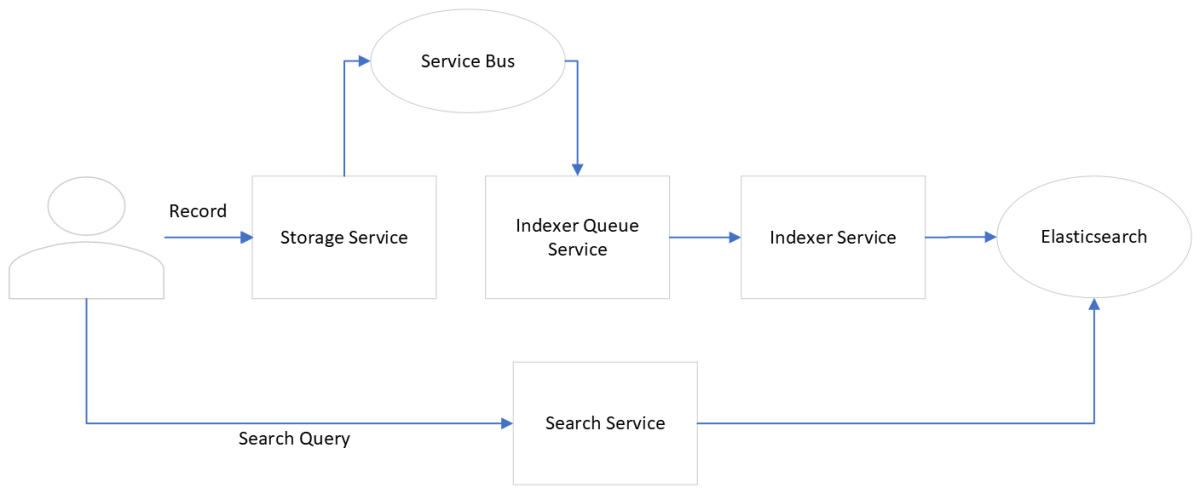
Quando un cliente carica i dati nella piattaforma, i metadati associati vengono inseriti usando .Storage service Storage service fornisce un set di API per gestire l'intero ciclo di vita dei metadati, ad esempio l'inserimento (persistenza), la modifica, l'eliminazione, il controllo delle versioni, il recupero e la gestione dello schema dei dati. Ogni record di metadati di archiviazione creato da Storage service contiene un parametro kind che fa riferimento a uno schema sottostante. Questo schema determina gli attributi che verranno indicizzati da Indexer service.
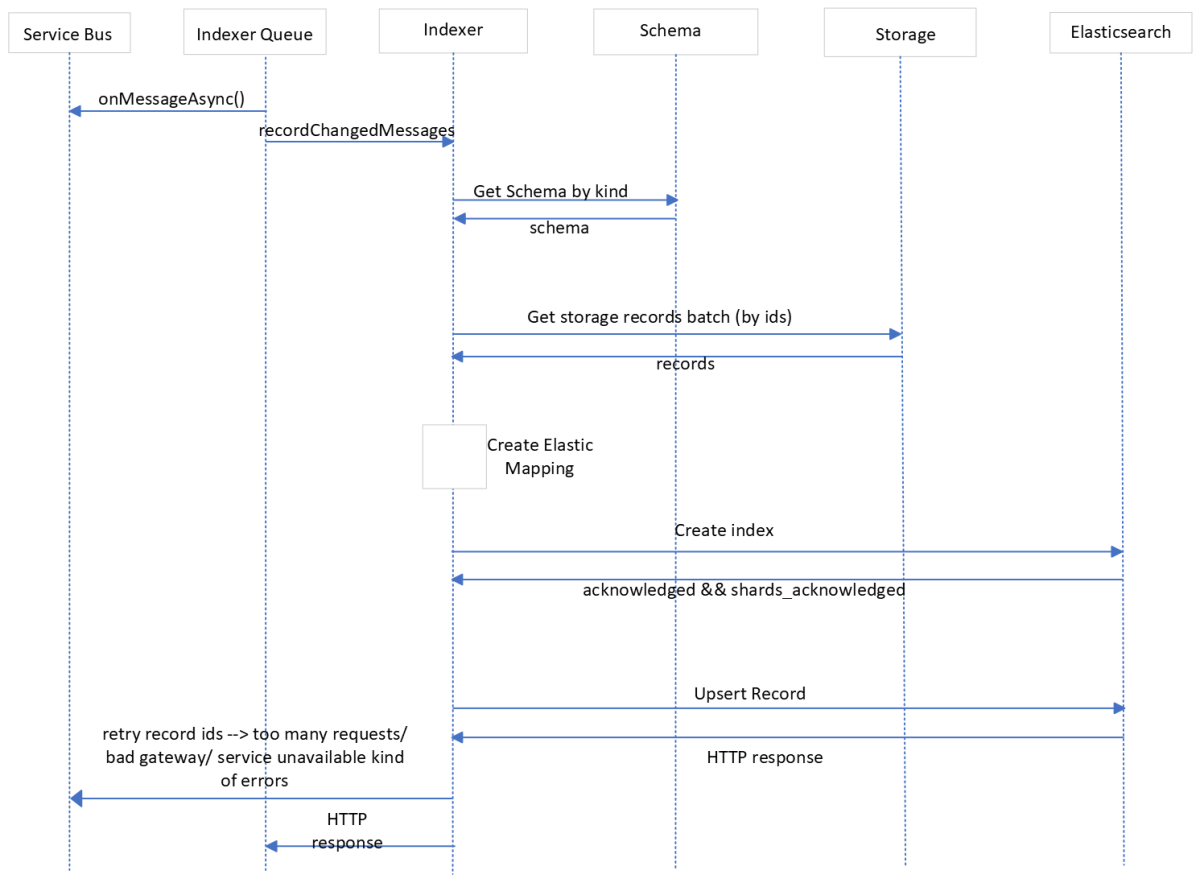
Quando crea Storage service un record di metadati, genera un evento recordChangedMessages raccolto nella bus di servizio di Azure (coda di messaggi). Il Indexer queue servizio esegue il pull del messaggio dal bus di servizio di Azure, esegue la convalida di base e lo invia all'oggetto Indexer service. Se si verificano errori durante l'invio Indexer servicedei messaggi a , il Indexer queue servizio ritenta l'invio del messaggio fino a un numero massimo di tentativi configurabili consentito. Se i tentativi di ripetizione hanno esito negativo, viene inviato un riconoscimento negativo al bus di servizio di Azure, che quindi archivia il messaggio.
Quando l'evento recordChangedMessages viene ricevuto da Indexer Service, recupera gli schemi necessari dalla cache dello schema o tramite le Schema service API. Viene Indexer Service quindi creato un nuovo indice all'interno di Elasticsearch (se non è già presente) e quindi viene inviata una query in blocco per creare o aggiornare i record in base alle esigenze. Se la risposta di Elasticsearch è una risposta di errore del servizio di tipo non disponibile o timeout della richiesta, crea Indexer Service recordChangedMessages per questi ID record non riusciti e inserisce il messaggio nel bus di servizio di Azure. Questi messaggi verranno nuovamente estratti dal Indexer Queue servizio e seguiranno lo stesso flusso di prima.
Per altre informazioni, vedere la documentazione osDU® del servizio Indicizzatore fornisce informazioni sul servizio indicizzatore
Flusso di lavoro di ricerca
Search service fornisce un meccanismo per l'individuazione di documenti di metadati indicizzati. L'API di ricerca supporta la ricerca full-text su campi stringa, query di intervallo su campo data, numerico o stringa e così via, insieme alle ricerche geospa spaziali.
Quando i record di metadati vengono caricati nella piattaforma tramite Storage service, è possibile configurare le autorizzazioni per i visualizzatori e i proprietari dei record di metadati nel campo acl . I visualizzatori e i proprietari vengono assegnati tramite gruppi definiti in Entitlement service. Quando si esegue una ricerca come utente, i record dei metadati corrispondenti verranno visualizzati solo per gli utenti assegnati al gruppo.
Per un'esercitazione dettagliata su Search service, vedere servizio di ricerca documentazione di OSDU®
Reindicizzare il flusso di lavoro
L'API reindicizzazione consente agli utenti di reindicizzare un tipo senza ripetere i record tramite l'API di archiviazione. Per informazioni dettagliate, vedere la documentazione di Reindex OSDU®
OSDU® è un marchio di The Open Group.
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per