Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
È possibile configurare un hub eventi in modo che i dati inviati a un hub eventi vengano acquisiti in un account di archiviazione di Azure o in Azure Data Lake Storage Gen 1 o Gen 2. Questo articolo illustra come scrivere codice Python per inviare eventi a un hub eventi e leggere i dati acquisiti dall'archivio BLOB di Azure. Per altre informazioni su questa funzionalità, vedere Panoramica delle funzionalità di acquisizione di Hub eventi.
Questa guida introduttiva usa Azure Python SDK per illustrare la funzionalità di acquisizione. L'app sender.py invia dati di telemetria ambientale simulati agli hub eventi in formato JSON. L'hub eventi è configurato per l'uso della funzionalità di acquisizione per scrivere questi dati nell'archivio BLOB in batch. L'app capturereader.py legge questi blob e crea un file di aggiunta per ogni dispositivo. L'app scrive quindi i dati in file CSV.
Questa guida introduttiva spiega come:
- Creare un account di archiviazione BLOB di Azure e un contenitore nel portale di Azure.
- Creare uno spazio dei nomi di Event Hubs utilizzando il portale Azure.
- Creare un hub eventi con la funzionalità di acquisizione abilitata e connetterlo all'account di archiviazione.
- Invia dati all'Event Hub usando uno script Python.
- Leggere ed elaborare i file da Event Hubs Capture usando un altro script Python.
Prerequisiti
Python 3.8 o versione successiva, con pip installato e aggiornato.
Una sottoscrizione di Azure. Se non se ne ha una, creare un account gratuito prima di iniziare.
Uno spazio dei nomi di Hub eventi e un hub eventi attivi. Creare uno spazio dei nomi di Hub eventi e un hub eventi al suo interno. Prendere nota del nome dello spazio dei nomi di Hub eventi, del nome dell'hub eventi e della chiave di accesso primaria per lo spazio dei nomi. Per ottenere la chiave di accesso, vedere Ottenere una stringa di connessione di Hub eventi. Il nome predefinito della chiave è RootManageSharedAccessKey. Per questo argomento di avvio rapido, è necessaria solo la chiave primaria. Non è necessaria la stringa di connessione.
Un account di archiviazione di Azure, un contenitore BLOB nell'account di archiviazione e una stringa di connessione all'account di archiviazione. Se questi elementi non sono disponibili, seguire questa procedura:
- Creare un account di archiviazione di Azure
- Creare un contenitore Blob nell'account di archiviazione
- Ottieni la stringa di connessione all'account di archiviazione
Assicurarsi di registrare la stringa di connessione e il nome del contenitore per usarli in seguito in questa guida introduttiva.
Abilitare la funzionalità di acquisizione per l'hub eventi
Attivare la funzione di acquisizione per l'hub eventi. Per farlo, seguire le istruzioni in abilitare l'acquisizione di hub eventi attraverso il portale di Azure. Selezionare l'account di archiviazione e il contenitore BLOB creato nel passaggio precedente. Selezionare Avro per Formato di serializzazione degli eventi di output.
Creare uno script Python per inviare eventi all'hub eventi
In questa sezione viene creato uno script Python che invia 200 eventi (10 dispositivi * 20 eventi) a un hub eventi. Questi eventi sono una lettura ambientale di esempio inviata in formato JSON.
Aprire l'editor Python preferito, ad esempio Visual Studio Code.
Creare uno script denominato sender.py.
Incollare il codice seguente in sender.py.
import time import os import uuid import datetime import random import json from azure.eventhub import EventHubProducerClient, EventData # This script simulates the production of events for 10 devices. devices = [] for x in range(0, 10): devices.append(str(uuid.uuid4())) # Create a producer client to produce and publish events to the event hub. producer = EventHubProducerClient.from_connection_string(conn_str="EVENT HUBS NAMESPACE CONNECTION STRING", eventhub_name="EVENT HUB NAME") for y in range(0,20): # For each device, produce 20 events. event_data_batch = producer.create_batch() # Create a batch. You will add events to the batch later. for dev in devices: # Create a dummy reading. reading = { 'id': dev, 'timestamp': str(datetime.datetime.utcnow()), 'uv': random.random(), 'temperature': random.randint(70, 100), 'humidity': random.randint(70, 100) } s = json.dumps(reading) # Convert the reading into a JSON string. event_data_batch.add(EventData(s)) # Add event data to the batch. producer.send_batch(event_data_batch) # Send the batch of events to the event hub. # Close the producer. producer.close()Sostituire i valori seguenti negli script:
- Sostituire
EVENT HUBS NAMESPACE CONNECTION STRINGcon la stringa di connessione per lo spazio dei nomi di Hub eventi. - Sostituisci
EVENT HUB NAMEcon il nome del tuo hub eventi.
- Sostituire
Eseguire lo script per inviare eventi all'hub eventi.
Nel portale di Azure è possibile verificare che l'hub eventi abbia ricevuto i messaggi. Passare alla visualizzazione Messaggi nella sezione Metriche . Aggiornare la pagina per aggiornare il grafico. La pagina potrebbe richiedere alcuni secondi per visualizzare che i messaggi sono stati ricevuti.
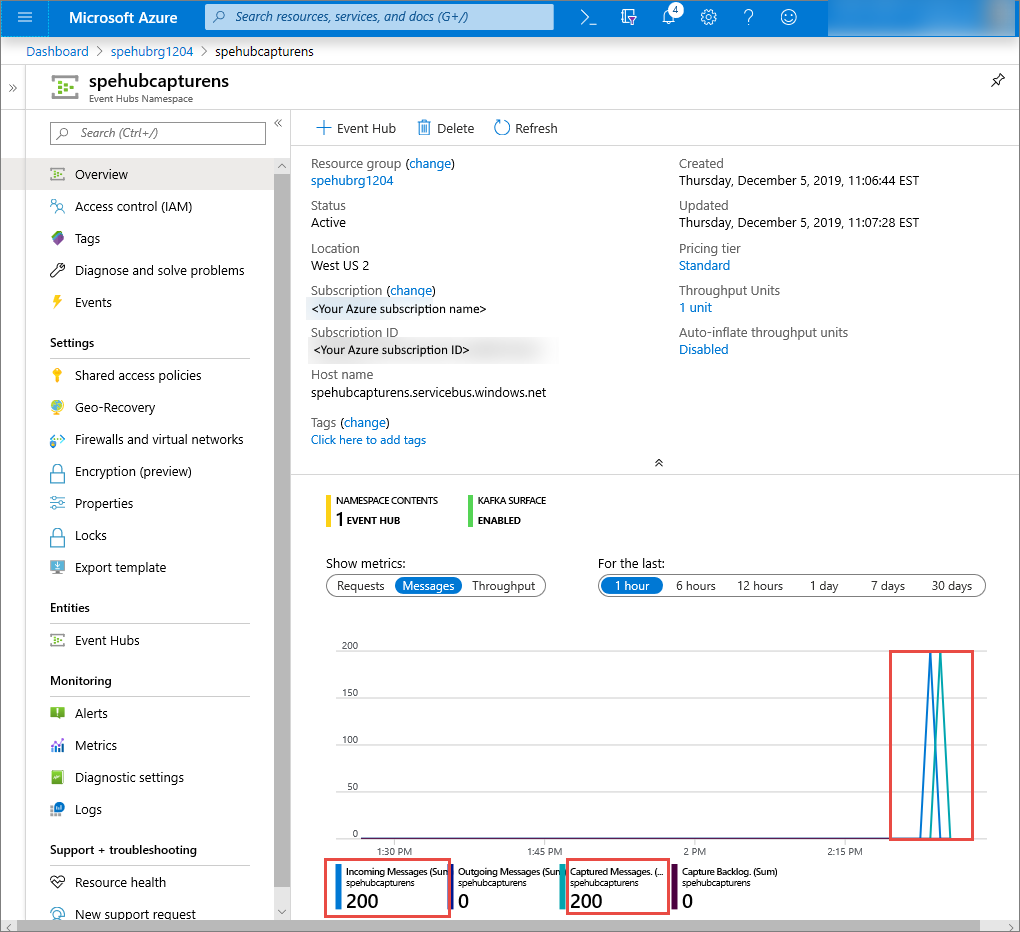

Creare uno script Python per leggere i file di acquisizione
In questo esempio i dati acquisiti vengono archiviati nell'archivio BLOB di Azure. Lo script in questa sezione legge i file di dati acquisiti dall'account di archiviazione di Azure e genera file CSV per poter aprire e visualizzare facilmente. Nella directory di lavoro corrente dell'applicazione sono visualizzati 10 file. Questi file contengono le letture ambientali per i 10 dispositivi.
Nell'editor Python creare uno script denominato capturereader.py. Questo script legge i file acquisiti e crea un file per ogni dispositivo per scrivere i dati solo per quel dispositivo.
Incollare il codice seguente in capturereader.py.
import os import string import json import uuid import avro.schema from azure.storage.blob import ContainerClient, BlobClient from avro.datafile import DataFileReader, DataFileWriter from avro.io import DatumReader, DatumWriter def processBlob2(filename): reader = DataFileReader(open(filename, 'rb'), DatumReader()) dict = {} for reading in reader: parsed_json = json.loads(reading["Body"]) if not 'id' in parsed_json: return if not parsed_json['id'] in dict: list = [] dict[parsed_json['id']] = list else: list = dict[parsed_json['id']] list.append(parsed_json) reader.close() for device in dict.keys(): filename = os.getcwd() + '\\' + str(device) + '.csv' deviceFile = open(filename, "a") for r in dict[device]: deviceFile.write(", ".join([str(r[x]) for x in r.keys()])+'\n') def startProcessing(): print('Processor started using path: ' + os.getcwd()) # Create a blob container client. container = ContainerClient.from_connection_string("AZURE STORAGE CONNECTION STRING", container_name="BLOB CONTAINER NAME") blob_list = container.list_blobs() # List all the blobs in the container. for blob in blob_list: # Content_length == 508 is an empty file, so process only content_length > 508 (skip empty files). if blob.size > 508: print('Downloaded a non empty blob: ' + blob.name) # Create a blob client for the blob. blob_client = ContainerClient.get_blob_client(container, blob=blob.name) # Construct a file name based on the blob name. cleanName = str.replace(blob.name, '/', '_') cleanName = os.getcwd() + '\\' + cleanName with open(cleanName, "wb+") as my_file: # Open the file to write. Create it if it doesn't exist. my_file.write(blob_client.download_blob().readall()) # Write blob contents into the file. processBlob2(cleanName) # Convert the file into a CSV file. os.remove(cleanName) # Remove the original downloaded file. # Delete the blob from the container after it's read. container.delete_blob(blob.name) startProcessing()Sostituire
AZURE STORAGE CONNECTION STRINGcon la stringa di connessione per l'account di archiviazione di Azure. Il nome del contenitore creato in questa guida introduttiva è capture. Se è stato usato un nome diverso per il contenitore, sostituire capture con il nome del contenitore nell'account di archiviazione.
Eseguire gli script
Aprire un prompt dei comandi con un percorso contenente Python, quindi eseguire questi comandi per installare i pacchetti dei prerequisiti di Python:
pip install azure-storage-blob pip install azure-eventhub pip install avro-python3Passare alla directory in cui sono stati salvati sender.py e capturereader.py ed eseguire questo comando:
python sender.pyQuesto comando avvia un nuovo processo Python per eseguire il processo di invio dati.
Attendere alcuni minuti per l'esecuzione dell'acquisizione e quindi immettere il comando seguente nella finestra di comando originale:
python capturereader.pyQuesto processore di acquisizione usa la directory locale per scaricare tutti i BLOB dall'account di archiviazione e dal contenitore. Elabora i file che non sono vuoti e scrive i risultati come file CSV nella directory locale.
Passaggi successivi
Vedere esempi di Python in GitHub.