Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
- Foundry Local è disponibile in anteprima. Le versioni di anteprima pubblica consentono l'accesso anticipato alle funzionalità in fase di distribuzione attiva.
- Funzionalità, approcci e processi possono subire variazioni o avere funzionalità limitate, prima della disponibilità generale (GA).
Foundry Local SDK semplifica la gestione dei modelli di intelligenza artificiale negli ambienti locali fornendo operazioni del piano di controllo separate dal codice di inferenza del piano dati. Questo riferimento documenta le implementazioni dell'SDK per Python, JavaScript, C# e Rust.
Informazioni di riferimento su Python SDK
Prerequisiti
- Installare Foundry Local e assicurarsi che il
foundrycomando sia disponibile inPATH. - Usare Python 3.9 o versione successiva.
Installazione
Installare il pacchetto Python:
pip install foundry-local-sdk
Avvio rapido
Usare questo frammento di codice per verificare che l'SDK possa avviare il servizio e raggiungere il catalogo locale.
from foundry_local import FoundryLocalManager
manager = FoundryLocalManager()
manager.start_service()
catalog = manager.list_catalog_models()
print(f"Catalog models available: {len(catalog)}")
In questo esempio viene stampato un numero diverso da zero quando il servizio è in esecuzione e il catalogo è disponibile.
Riferimenti:
Classe FoundryLocalManager
La FoundryLocalManager classe fornisce metodi per gestire modelli, cache e il servizio locale Foundry.
Inizializzazione
from foundry_local import FoundryLocalManager
# Initialize and optionally bootstrap with a model
manager = FoundryLocalManager(alias_or_model_id=None, bootstrap=True)
-
alias_or_model_id: (facoltativo) Alias o ID modello da scaricare e caricare all'avvio. -
bootstrap: (valore predefinito True) Se True, avvia il servizio se non è in esecuzione e carica il modello, se specificato.
Nota sugli alias
Molti metodi descritti in questo riferimento hanno un alias_or_model_id parametro nella firma. È possibile passare al metodo un alias o un ID modello come valore. L'uso di un alias porterà a:
- Selezionare il modello migliore per l'hardware disponibile. Ad esempio, se è disponibile una GPU Nvidia CUDA, Foundry Local seleziona il modello CUDA. Se è disponibile una NPU supportata, Foundry Local seleziona il modello NPU.
- Consente di usare un nome più breve senza dover ricordare l'ID modello.
Suggerimento
È consigliabile passare al alias_or_model_id parametro un alias perché quando si distribuisce l'applicazione, Foundry Local acquisisce il modello migliore per il computer dell'utente finale in fase di esecuzione.
Annotazioni
Se si dispone di una NPU Intel in Windows, assicurarsi di aver installato il driver Intel NPU per un'accelerazione NPU ottimale.
Gestione dei servizi
| Metodo | Signature | Descrzione |
|---|---|---|
is_service_running() |
() -> bool |
Controlla se il servizio locale Foundry è in esecuzione. |
start_service() |
() -> None |
Avvia il servizio Foundry Locale. |
service_uri |
@property -> str |
Restituisce l'URI del servizio. |
endpoint |
@property -> str |
Restituisce l'endpoint del servizio. |
api_key |
@property -> str |
Restituisce la chiave API (da env o default). |
Gestione catalogo
| Metodo | Signature | Descrzione |
|---|---|---|
list_catalog_models() |
() -> list[FoundryModelInfo] |
Elenca tutti i modelli disponibili nel catalogo. |
refresh_catalog() |
() -> None |
Aggiorna il catalogo dei modelli. |
get_model_info() |
(alias_or_model_id: str, raise_on_not_found=False) -> FoundryModelInfo \| None |
Ottiene informazioni sul modello in base all'alias o all'ID. |
Gestione cache
| Metodo | Signature | Descrzione |
|---|---|---|
get_cache_location() |
() -> str |
Restituisce il percorso della directory della cache del modello. |
list_cached_models() |
() -> list[FoundryModelInfo] |
Elenca i modelli scaricati nella cache locale. |
Gestione modelli
| Metodo | Signature | Descrzione |
|---|---|---|
download_model() |
(alias_or_model_id: str, token: str = None, force: bool = False) -> FoundryModelInfo |
Scarica un modello nella cache locale. |
load_model() |
(alias_or_model_id: str, ttl: int = 600) -> FoundryModelInfo |
Carica un modello nel server di inferenza. |
unload_model() |
(alias_or_model_id: str, force: bool = False) -> None |
Scarica un modello dal server di inferenza. |
list_loaded_models() |
() -> list[FoundryModelInfo] |
Elenca tutti i modelli attualmente caricati nel servizio. |
FoundryModelInfo
I metodi list_catalog_models(), list_cached_models()e list_loaded_models() restituiscono un elenco di FoundryModelInfo oggetti . È possibile utilizzare le informazioni contenute in questo oggetto per perfezionare ulteriormente l'elenco. In alternativa, ottenere le informazioni per un modello direttamente chiamando il get_model_info(alias_or_model_id) metodo .
Questi oggetti contengono i campi seguenti:
| Campo | TIPO | Descrzione |
|---|---|---|
alias |
str |
Alias del modello. |
id |
str |
Identificatore univoco del modello. |
version |
str |
Versione del modello. |
execution_provider |
str |
Acceleratore (provider di esecuzione) utilizzato per eseguire il modello. |
device_type |
DeviceType |
Tipo di dispositivo del modello: CPU, GPU, NPU. |
uri |
str |
URI del modello. |
file_size_mb |
int |
Dimensioni del modello su disco in MB. |
supports_tool_calling |
bool |
Indica se il modello supporta la chiamata allo strumento. |
prompt_template |
dict \| None |
Modello di richiesta per il modello. |
provider |
str |
Provider del modello (dove è pubblicato il modello). |
publisher |
str |
Autore del modello (che ha pubblicato il modello). |
license |
str |
Nome della licenza del modello. |
task |
str |
Attività del modello. Uno tra chat-completions e automatic-speech-recognition. |
ep_override |
str \| None |
Eseguire l'override per il provider di esecuzione, se diverso dall'impostazione predefinita del modello. |
Fornitori di esecuzione
Uno dei seguenti:
-
CPUExecutionProvider- Esecuzione basata sulla CPU -
CUDAExecutionProvider- Esecuzione GPU NVIDIA CUDA -
WebGpuExecutionProvider- Esecuzione di WebGPU -
QNNExecutionProvider- Esecuzione della rete neurale Qualcomm (NPU) -
OpenVINOExecutionProvider- Esecuzione di Intel OpenVINO -
NvTensorRTRTXExecutionProvider- Esecuzione di NVIDIA TensorRT -
VitisAIExecutionProvider- Esecuzione dell'intelligenza artificiale AMD Vitis
Esempio di utilizzo
Il codice seguente illustra come usare la FoundryLocalManager classe per gestire i modelli e interagire con il servizio locale Foundry.
from foundry_local import FoundryLocalManager
# By using an alias, the most suitable model will be selected
# to your end-user's device.
alias = "qwen2.5-0.5b"
# Create a FoundryLocalManager instance. This will start the Foundry.
manager = FoundryLocalManager()
# List available models in the catalog
catalog = manager.list_catalog_models()
print(f"Available models in the catalog: {catalog}")
# Download and load a model
model_info = manager.download_model(alias)
model_info = manager.load_model(alias)
print(f"Model info: {model_info}")
# List models in cache
local_models = manager.list_cached_models()
print(f"Models in cache: {local_models}")
# List loaded models
loaded = manager.list_loaded_models()
print(f"Models running in the service: {loaded}")
# Unload a model
manager.unload_model(alias)
Questo esempio elenca modelli, ne scarica uno, lo carica e poi lo rimuove.
Riferimenti:
Eseguire l'integrazione con OpenAI SDK
Installare il pacchetto OpenAI:
pip install openai
Il codice seguente illustra come integrare FoundryLocalManager con l'SDK di OpenAI per interagire con un modello locale.
import openai
from foundry_local import FoundryLocalManager
# By using an alias, the most suitable model will be downloaded
# to your end-user's device.
alias = "qwen2.5-0.5b"
# Create a FoundryLocalManager instance. This will start the Foundry
# Local service if it is not already running and load the specified model.
manager = FoundryLocalManager(alias)
# The remaining code uses the OpenAI Python SDK to interact with the local model.
# Configure the client to use the local Foundry service
client = openai.OpenAI(
base_url=manager.endpoint,
api_key=manager.api_key # API key is not required for local usage
)
# Set the model to use and generate a streaming response
stream = client.chat.completions.create(
model=manager.get_model_info(alias).id,
messages=[{"role": "user", "content": "Why is the sky blue?"}],
stream=True
)
# Print the streaming response
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
Questo esempio trasmette una risposta di completamento della chat dal modello locale.
Riferimenti:
Informazioni di riferimento su JavaScript SDK
Prerequisiti
- Installare Foundry Local e assicurarsi che il
foundrycomando sia disponibile inPATH.
Installazione
Installare il pacchetto da npm:
npm install foundry-local-sdk
Avvio rapido
Usare questo frammento di codice per verificare che l'SDK possa avviare il servizio e raggiungere il catalogo locale.
import { FoundryLocalManager } from "foundry-local-sdk";
const manager = new FoundryLocalManager();
await manager.startService();
const catalogModels = await manager.listCatalogModels();
console.log(`Catalog models available: ${catalogModels.length}`);
In questo esempio viene stampato un numero diverso da zero quando il servizio è in esecuzione e il catalogo è disponibile.
Riferimenti:
Classe FoundryLocalManager
La FoundryLocalManager classe consente di gestire modelli, controllare la cache e interagire con il servizio locale Foundry in ambienti browser e Node.js.
Inizializzazione
import { FoundryLocalManager } from "foundry-local-sdk";
const foundryLocalManager = new FoundryLocalManager();
Opzioni disponibili:
-
host: URL di base del servizio locale Foundry -
fetch: (facoltativo) Implementazione di recupero personalizzato per ambienti come Node.js
Nota sugli alias
Molti metodi descritti in questo riferimento hanno un aliasOrModelId parametro nella firma. È possibile passare al metodo un alias o un ID modello come valore. L'uso di un alias porterà a:
- Selezionare il modello migliore per l'hardware disponibile. Ad esempio, se è disponibile una GPU Nvidia CUDA, Foundry Local seleziona il modello CUDA. Se è disponibile una NPU supportata, Foundry Local seleziona il modello NPU.
- Consente di usare un nome più breve senza dover ricordare l'ID modello.
Suggerimento
È consigliabile passare al aliasOrModelId parametro un alias perché quando si distribuisce l'applicazione, Foundry Local acquisisce il modello migliore per il computer dell'utente finale in fase di esecuzione.
Annotazioni
Se si dispone di una NPU Intel in Windows, assicurarsi di aver installato il driver Intel NPU per un'accelerazione NPU ottimale.
Gestione dei servizi
| Metodo | Signature | Descrzione |
|---|---|---|
init() |
(aliasOrModelId?: string) => Promise<FoundryModelInfo \| void> |
Inizializza l'SDK e, facoltativamente, carica un modello. |
isServiceRunning() |
() => Promise<boolean> |
Controlla se il servizio locale Foundry è in esecuzione. |
startService() |
() => Promise<void> |
Avvia il servizio Foundry Locale. |
serviceUrl |
string |
URL di base del servizio locale Foundry. |
endpoint |
string |
L'endpoint dell'API (serviceUrl + /v1). |
apiKey |
string |
Chiave API (nessuno). |
Gestione catalogo
| Metodo | Signature | Descrzione |
|---|---|---|
listCatalogModels() |
() => Promise<FoundryModelInfo[]> |
Elenca tutti i modelli disponibili nel catalogo. |
refreshCatalog() |
() => Promise<void> |
Aggiorna il catalogo dei modelli. |
getModelInfo() |
(aliasOrModelId: string, throwOnNotFound = false) => Promise<FoundryModelInfo \| null> |
Ottiene informazioni sul modello in base all'alias o all'ID. |
Gestione cache
| Metodo | Signature | Descrzione |
|---|---|---|
getCacheLocation() |
() => Promise<string> |
Restituisce il percorso della directory della cache del modello. |
listCachedModels() |
() => Promise<FoundryModelInfo[]> |
Elenca i modelli scaricati nella cache locale. |
Gestione modelli
| Metodo | Signature | Descrzione |
|---|---|---|
downloadModel() |
(aliasOrModelId: string, token?: string, force = false, onProgress?) => Promise<FoundryModelInfo> |
Scarica un modello nella cache locale. |
loadModel() |
(aliasOrModelId: string, ttl = 600) => Promise<FoundryModelInfo> |
Carica un modello nel server di inferenza. |
unloadModel() |
(aliasOrModelId: string, force = false) => Promise<void> |
Scarica un modello dal server di inferenza. |
listLoadedModels() |
() => Promise<FoundryModelInfo[]> |
Elenca tutti i modelli attualmente caricati nel servizio. |
Esempio di utilizzo
Il codice seguente illustra come usare la FoundryLocalManager classe per gestire i modelli e interagire con il servizio locale Foundry.
import { FoundryLocalManager } from "foundry-local-sdk";
// By using an alias, the most suitable model will be downloaded
// to your end-user's device.
// TIP: You can find a list of available models by running the
// following command in your terminal: `foundry model list`.
const alias = "qwen2.5-0.5b";
const manager = new FoundryLocalManager();
// Initialize the SDK and optionally load a model
const modelInfo = await manager.init(alias);
console.log("Model Info:", modelInfo);
// Check if the service is running
const isRunning = await manager.isServiceRunning();
console.log(`Service running: ${isRunning}`);
// List available models in the catalog
const catalog = await manager.listCatalogModels();
// Download and load a model
await manager.downloadModel(alias);
await manager.loadModel(alias);
// List models in cache
const localModels = await manager.listCachedModels();
// List loaded models
const loaded = await manager.listLoadedModels();
// Unload a model
await manager.unloadModel(alias);
Questo esempio scarica e carica un modello, quindi elenca i modelli memorizzati nella cache e caricati.
Riferimenti:
Integrazione con il client OpenAI
Installare il pacchetto OpenAI:
npm install openai
Il codice seguente illustra come integrare con FoundryLocalManager il client OpenAI per interagire con un modello locale.
import { OpenAI } from "openai";
import { FoundryLocalManager } from "foundry-local-sdk";
// By using an alias, the most suitable model will be downloaded
// to your end-user's device.
// TIP: You can find a list of available models by running the
// following command in your terminal: `foundry model list`.
const alias = "qwen2.5-0.5b";
// Create a FoundryLocalManager instance. This will start the Foundry
// Local service if it is not already running.
const foundryLocalManager = new FoundryLocalManager();
// Initialize the manager with a model. This will download the model
// if it is not already present on the user's device.
const modelInfo = await foundryLocalManager.init(alias);
console.log("Model Info:", modelInfo);
const openai = new OpenAI({
baseURL: foundryLocalManager.endpoint,
apiKey: foundryLocalManager.apiKey,
});
async function streamCompletion() {
const stream = await openai.chat.completions.create({
model: modelInfo.id,
messages: [{ role: "user", content: "What is the golden ratio?" }],
stream: true,
});
for await (const chunk of stream) {
if (chunk.choices[0]?.delta?.content) {
process.stdout.write(chunk.choices[0].delta.content);
}
}
}
streamCompletion();
Questo esempio trasmette una risposta di completamento della chat dal modello locale.
Riferimenti:
Utilizzo del browser
L'SDK include una versione compatibile con browser in cui è necessario specificare manualmente l'URL host:
import { FoundryLocalManager } from "foundry-local-sdk/browser";
// Specify the service URL
// Run the Foundry Local service using the CLI: `foundry service start`
// and use the URL from the CLI output
const host = "HOST";
const manager = new FoundryLocalManager({ host });
// Note: The `init`, `isServiceRunning`, and `startService` methods
// are not available in the browser version
Annotazioni
La versione del browser non supporta i metodi init, isServiceRunning e startService. È necessario assicurarsi che il servizio locale Foundry sia in esecuzione prima di usare l'SDK in un ambiente browser. È possibile avviare il servizio usando l'interfaccia della riga di comando locale di Foundry: foundry service start. È possibile ottenere l'URL del servizio dall'output dell'interfaccia della riga di comando.
Esempio di utilizzo
import { FoundryLocalManager } from "foundry-local-sdk/browser";
// Specify the service URL
// Run the Foundry Local service using the CLI: `foundry service start`
// and use the URL from the CLI output
const host = "HOST";
const manager = new FoundryLocalManager({ host });
const alias = "qwen2.5-0.5b";
// Get all available models
const catalog = await manager.listCatalogModels();
console.log("Available models in catalog:", catalog);
// Download and load a specific model
await manager.downloadModel(alias);
await manager.loadModel(alias);
// View models in your local cache
const localModels = await manager.listCachedModels();
console.log("Cached models:", localModels);
// Check which models are currently loaded
const loaded = await manager.listLoadedModels();
console.log("Loaded models in inference service:", loaded);
// Unload a model when finished
await manager.unloadModel(alias);
Riferimenti:
Informazioni di riferimento su C# SDK
Guida alla configurazione del progetto
Sono disponibili due pacchetti NuGet per Foundry Local SDK, ovvero WinML e un pacchetto multipiattaforma, che hanno la stessa superficie API, ma sono ottimizzati per piattaforme diverse:
-
Windows: usa il
Microsoft.AI.Foundry.Local.WinMLpacchetto specifico per le applicazioni Windows, che usa il framework Windows Machine Learning (WinML). -
Multipiattaforma: usa il
Microsoft.AI.Foundry.Localpacchetto che può essere usato per applicazioni multipiattaforma (Windows, Linux, macOS).
A seconda della piattaforma di destinazione, seguire queste istruzioni per creare una nuova applicazione C# e aggiungere le dipendenze necessarie:
Usare Foundry Local nel progetto C# seguendo queste istruzioni specifiche di Windows o multipiattaforma (macOS/Linux/Windows):
- Creare un nuovo progetto C# e accederne:
dotnet new console -n app-name cd app-name - Aprire e modificare il
app-name.csprojfile in:<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>net9.0-windows10.0.26100</TargetFramework> <RootNamespace>app-name</RootNamespace> <ImplicitUsings>enable</ImplicitUsings> <Nullable>enable</Nullable> <WindowsAppSDKSelfContained>false</WindowsAppSDKSelfContained> <WindowsPackageType>None</WindowsPackageType> <EnableCoreMrtTooling>false</EnableCoreMrtTooling> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.AI.Foundry.Local.WinML" Version="0.8.2.1" /> <PackageReference Include="Microsoft.Extensions.Logging" Version="9.0.10" /> <PackageReference Include="OpenAI" Version="2.5.0" /> </ItemGroup> </Project> - Creare un
nuget.configfile nella radice del progetto con il contenuto seguente in modo che i pacchetti vengano ripristinati correttamente:<?xml version="1.0" encoding="utf-8"?> <configuration> <packageSources> <clear /> <add key="nuget.org" value="https://api.nuget.org/v3/index.json" /> <add key="ORT" value="https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/ORT/nuget/v3/index.json" /> </packageSources> <packageSourceMapping> <packageSource key="nuget.org"> <package pattern="*" /> </packageSource> <packageSource key="ORT"> <package pattern="*Foundry*" /> </packageSource> </packageSourceMapping> </configuration>
Avvio rapido
Usare questo frammento di codice per verificare che l'SDK possa inizializzare e accedere al catalogo del modello locale.
using Microsoft.AI.Foundry.Local;
using Microsoft.Extensions.Logging;
using System.Linq;
var config = new Configuration
{
AppName = "app-name",
LogLevel = Microsoft.AI.Foundry.Local.LogLevel.Information,
};
using var loggerFactory = LoggerFactory.Create(builder =>
{
builder.SetMinimumLevel(Microsoft.Extensions.Logging.LogLevel.Information);
});
var logger = loggerFactory.CreateLogger<Program>();
await FoundryLocalManager.CreateAsync(config, logger);
var manager = FoundryLocalManager.Instance;
var catalog = await manager.GetCatalogAsync();
var models = await catalog.ListModelsAsync();
Console.WriteLine($"Models available: {models.Count()}");
In questo esempio viene stampato il numero di modelli disponibili per l'hardware.
Riferimenti:
Riprogettazione
Per migliorare la possibilità di distribuire applicazioni usando l'intelligenza artificiale su dispositivo, sono state apportate modifiche sostanziali all'architettura di C# SDK nella versione 0.8.0 e versioni successive. In questa sezione vengono illustrate le modifiche chiave per facilitare la migrazione delle applicazioni alla versione più recente dell'SDK.
Annotazioni
Nella versione 0.8.0 dell'SDK e versioni successive sono state apportate modifiche di rilievo nell'API rispetto alle versioni precedenti.
Il diagramma seguente mostra come l'architettura precedente, per le versioni anteriori a 0.8.0, si basava fortemente sull'uso di un server REST per gestire modelli e attività di inferenza, come le completamenti delle chat.

L'SDK usa una chiamata procedurale remota (RPC) per trovare l'eseguibile dell'interfaccia della riga di comando locale di Foundry nel computer, avviare il server Web e quindi comunicare con esso tramite HTTP. Questa architettura presentava diverse limitazioni, tra cui:
- Complessità nella gestione del ciclo di vita del server Web.
- Distribuzione impegnativa: gli utenti finali devono avere installato l'interfaccia della riga di comando Fonderia Locale sui loro computer e sulla loro applicazione.
- La gestione delle versioni dell'interfaccia della riga di comando e dell'SDK potrebbe causare problemi di compatibilità.
Per risolvere questi problemi, l'architettura riprogettata in versione 0.8.0 e versioni successive usa un approccio più semplificato. La nuova architettura è la seguente:

In questa nuova architettura:
- L'applicazione è autonoma. Non richiede che l'interfaccia della riga di comando locale di Foundry venga installata separatamente nel computer dell'utente finale, semplificando la distribuzione delle applicazioni.
- Il server Web REST è facoltativo. È comunque possibile usare il server Web se si vuole integrare con altri strumenti che comunicano tramite HTTP. Per informazioni dettagliate su come usare questa funzionalità, vedere Usare i completamenti della chat tramite il server REST con Foundry Local .
- L'SDK offre il supporto nativo per i completamenti delle chat e le trascrizioni audio, consentendo di creare applicazioni di intelligenza artificiale conversazionale con un minor numero di dipendenze. Per informazioni dettagliate su come usare questa funzionalità, vedere Usare l'API di completamento della chat nativa di Foundry .
- Nei dispositivi Windows è possibile usare una build di Windows ML che gestisce l'accelerazione hardware per i modelli nel dispositivo caricando il runtime e i driver corretti.
Modifiche api
La versione 0.8.0 e versioni successive forniscono un'API più orientata agli oggetti e componibile. Il punto di ingresso principale continua a essere la FoundryLocalManager classe , ma invece di essere un set flat di metodi che operano tramite chiamate statiche a un'API HTTP senza stato, l'SDK ora espone metodi sull'istanza FoundryLocalManager che mantengono lo stato sul servizio e sui modelli.
| Primitivo | Versioni < 0.8.0 | Versioni >= 0.8.0 |
|---|---|---|
| Configuration | N/A | config = Configuration(...) |
| Recupera il manager | mgr = FoundryLocalManager(); |
await FoundryLocalManager.CreateAsync(config, logger);var mgr = FoundryLocalManager.Instance; |
| Ottenere il catalogo | N/A | catalog = await mgr.GetCatalogAsync(); |
| Elenco Modelli | mgr.ListCatalogModelsAsync(); |
catalog.ListModelsAsync(); |
| Ottenere un modello | mgr.GetModelInfoAsync("aliasOrModelId"); |
catalog.GetModelAsync(alias: "alias"); |
| Get Variant | N/A | model.SelectedVariant; |
| Imposta variante | N/A | model.SelectVariant(); |
| Scaricare un modello | mgr.DownloadModelAsync("aliasOrModelId"); |
model.DownloadAsync() |
| Caricare un modello | mgr.LoadModelAsync("aliasOrModelId"); |
model.LoadAsync() |
| Scaricare un modello | mgr.UnloadModelAsync("aliasOrModelId"); |
model.UnloadAsync() |
| Elencare i modelli caricati | mgr.ListLoadedModelsAsync(); |
catalog.GetLoadedModelsAsync(); |
| Ottenere il percorso del modello | N/A | model.GetPathAsync() |
| Avviare il servizio | mgr.StartServiceAsync(); |
mgr.StartWebServerAsync(); |
| Arrestare il servizio | mgr.StopServiceAsync(); |
mgr.StopWebServerAsync(); |
| Percorso della cache | mgr.GetCacheLocationAsync(); |
config.ModelCacheDir |
| Elencare i modelli memorizzati nella cache | mgr.ListCachedModelsAsync(); |
catalog.GetCachedModelsAsync(); |
L'API consente a Foundry Local di essere più configurabile tramite il server Web, la registrazione, la posizione della cache e la selezione delle varianti del modello. Ad esempio, la Configuration classe consente di configurare il nome dell'applicazione, il livello di registrazione, gli URL del server Web e le directory per i dati dell'applicazione, la cache dei modelli e i log:
var config = new Configuration
{
AppName = "app-name",
LogLevel = Microsoft.AI.Foundry.Local.LogLevel.Information,
Web = new Configuration.WebService
{
Urls = "http://127.0.0.1:55588"
},
AppDataDir = "./foundry_local_data",
ModelCacheDir = "{AppDataDir}/model_cache",
LogsDir = "{AppDataDir}/logs"
};
Riferimenti:
Nella versione precedente di Foundry Local C# SDK non è stato possibile configurare queste impostazioni direttamente tramite l'SDK, che ha limitato la possibilità di personalizzare il comportamento del servizio.
Ridurre le dimensioni del pacchetto dell'applicazione
Foundry Local SDK integra il pacchetto NuGet come dipendenza. Il Microsoft.ML.OnnxRuntime.Foundry pacchetto fornisce il bundle di runtime di inferenza, ovvero il set di librerie necessarie per eseguire in modo efficiente l'inferenza in dispositivi hardware specifici del fornitore. Il bundle di runtime di inferenza include i componenti seguenti:
-
Libreria di runtime ONNX: motore di inferenza principale (
onnxruntime.dll). -
Libreria ONNX Runtime Execution Provider (EP). Back-end specifico per l'hardware in ONNX Runtime che ottimizza ed esegue parti di un modello di Machine Learning su un acceleratore hardware. Per esempio:
- EP CUDA:
onnxruntime_providers_cuda.dll - QNN EP:
onnxruntime_providers_qnn.dll
- EP CUDA:
-
Librerie IHV (Independent Hardware Vendor). Per esempio:
- WebGPU: dipendenze DirectX (
dxcompiler.dll,dxil.dll) - QNN: dipendenze QNN Qualcomm (
QnnSystem.dll, ecc.)
- WebGPU: dipendenze DirectX (
La tabella seguente riepiloga le librerie EP e IHV in bundle con l'applicazione e le operazioni che WinML scaricherà/installerà in fase di esecuzione:
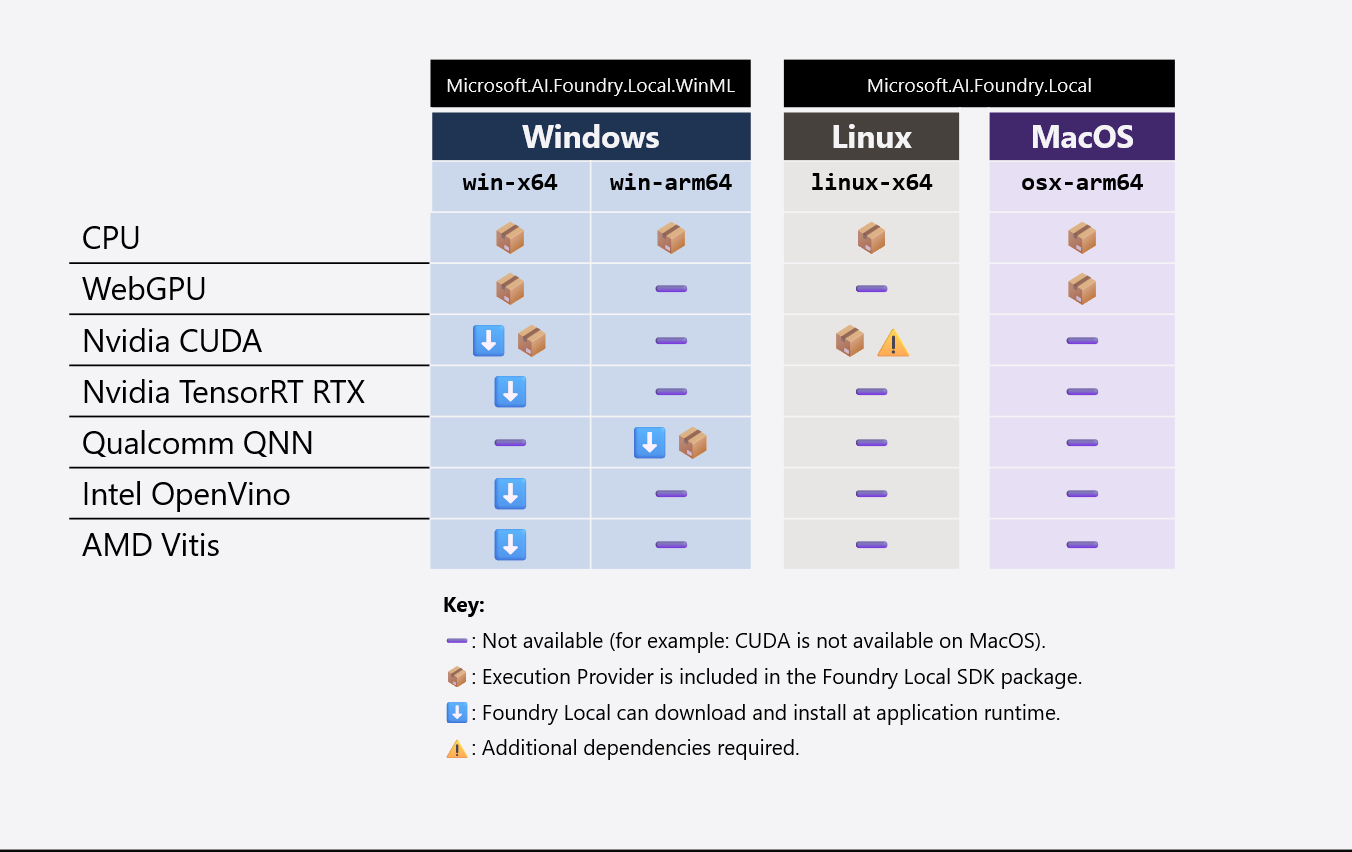
Su tutte le piattaforme e architetture, è necessario il CPU EP. Le librerie WEBGPU EP e IHV sono di piccole dimensioni (ad esempio, WebGPU aggiunge solo ~7 MB al pacchetto dell'applicazione) e sono necessarie in Windows e macOS. Tuttavia, gli EPS CUDA e QNN sono di grandi dimensioni ,ad esempio CUDA aggiunge ~1 GB al pacchetto dell'applicazione, quindi è consigliabile escludere questi EP dal pacchetto dell'applicazione. WinML scaricherà/installerà CUDA e QNN in fase di esecuzione se l'utente finale ha hardware compatibile.
Annotazioni
Microsoft sta lavorando per rimuovere gli EPS CUDA e QNN dal Microsoft.ML.OnnxRuntime.Foundry pacchetto nelle versioni future, in modo che non sia necessario includere un ExcludeExtraLibs.props file per rimuoverli dal pacchetto dell'applicazione.
Per ridurre le dimensioni del pacchetto dell'applicazione, è possibile creare un ExcludeExtraLibs.props file nella directory del progetto con il contenuto seguente, che esclude le librerie CUDA e QNN EP e IHV quando si pubblica l'applicazione:
<Project>
<!-- we want to ensure we're using the onnxruntime libraries from Foundry Local Core so
we delete the WindowsAppSdk versions once they're unzipped. -->
<Target Name="ExcludeOnnxRuntimeLibs" AfterTargets="ExtractMicrosoftWindowsAppSDKMsixFiles">
<Delete Files="$(MicrosoftWindowsAppSDKMsixContent)\onnxruntime.dll"/>
<Delete Files="$(MicrosoftWindowsAppSDKMsixContent)\onnxruntime_providers_shared.dll"/>
<Message Importance="Normal" Text="Deleted onnxruntime libraries from $(MicrosoftWindowsAppSDKMsixContent)." />
</Target>
<!-- Remove CUDA EP and IHV libraries on Windows x64 -->
<Target Name="ExcludeCudaLibs" Condition="'$(RuntimeIdentifier)'=='win-x64'" AfterTargets="ResolvePackageAssets">
<ItemGroup>
<!-- match onnxruntime*cuda.* (we're matching %(Filename) which excludes the extension) -->
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)',
'^onnxruntime.*cuda.*', RegexOptions.IgnoreCase))" />
</ItemGroup>
<Message Importance="Normal" Text="Excluded onnxruntime CUDA libraries from package." />
</Target>
<!-- Remove QNN EP and IHV libraries on Windows arm64 -->
<Target Name="ExcludeQnnLibs" Condition="'$(RuntimeIdentifier)'=='win-arm64'" AfterTargets="ResolvePackageAssets">
<ItemGroup>
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)%(Extension)',
'^QNN.*\.dll', RegexOptions.IgnoreCase))" />
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)',
'^libQNNhtp.*', RegexOptions.IgnoreCase))" />
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="'%(FileName)%(Extension)' == 'onnxruntime_providers_qnn.dll'" />
</ItemGroup>
<Message Importance="Normal" Text="Excluded onnxruntime QNN libraries from package." />
</Target>
<!-- need to manually copy on linux-x64 due to the nuget packages not having the correct props file setup -->
<ItemGroup Condition="'$(RuntimeIdentifier)' == 'linux-x64'">
<!-- 'Update' as the Core package will add these dependencies, but we want to be explicit about the version -->
<PackageReference Update="Microsoft.ML.OnnxRuntime.Gpu" />
<PackageReference Update="Microsoft.ML.OnnxRuntimeGenAI.Cuda" />
<OrtNativeLibs Include="$(NuGetPackageRoot)microsoft.ml.onnxruntime.gpu.linux/$(OnnxRuntimeVersion)/runtimes/$(RuntimeIdentifier)/native/*" />
<OrtGenAINativeLibs Include="$(NuGetPackageRoot)microsoft.ml.onnxruntimegenai.cuda/$(OnnxRuntimeGenAIVersion)/runtimes/$(RuntimeIdentifier)/native/*" />
</ItemGroup>
<Target Name="CopyOrtNativeLibs" AfterTargets="Build" Condition=" '$(RuntimeIdentifier)' == 'linux-x64'">
<Copy SourceFiles="@(OrtNativeLibs)" DestinationFolder="$(OutputPath)"></Copy>
<Copy SourceFiles="@(OrtGenAINativeLibs)" DestinationFolder="$(OutputPath)"></Copy>
</Target>
</Project>
Nel file di progetto (.csproj) aggiungere la riga seguente per importare il ExcludeExtraLibs.props file:
<!-- other project file content -->
<Import Project="ExcludeExtraLibs.props" />
Windows: Dipendenze CUDA
Il pacchetto EP CUDA viene inserito nell'applicazione Linux tramite Microsoft.ML.OnnxRuntime.Foundry, ma non sono incluse le librerie IHV. Se si vuole consentire agli utenti finali con dispositivi abilitati per CUDA di trarre vantaggio da prestazioni più elevate, è necessario aggiungere le librerie IHV CUDA seguenti all'applicazione:
- CUBLAS v12.8.4 (scaricare da NVIDIA Developer)
- cublas64_12.dll
- cublasLt64_12.dll
- CUDA RT v12.8.90 (scarica da NVIDIA Developer)
- cudart64_12.dll
- CUDNN v9.8.0 (scarica da NVIDIA Developer)
- cudnn_graph64_9.dll
- cudnn_ops64_9.dll
- cudnn64_9.dll
- CUDA FFT v11.3.3.83 (scarica da NVIDIA Developer)
- cufft64_11.dll
Avviso
L'aggiunta delle librerie EP CUDA e IHV all'applicazione aumenta le dimensioni del pacchetto dell'applicazione di 1 GB.
Samples
- Per le applicazioni di esempio che illustrano come utilizzare il Foundry Local C# SDK, vedere il repository GitHub degli esempi locali di C# di Foundry.
Informazioni di riferimento sulle API
- Per altre informazioni su Foundry Local C# SDK, vedere Foundry Local C# SDK API Reference (Informazioni di riferimento sull'API C# locale di Foundry).
Informazioni di riferimento su Rust SDK
Rust SDK per Foundry Local consente di gestire i modelli, controllare la cache e interagire con il servizio locale Foundry.
Prerequisiti
- Installare Foundry Local e assicurarsi che il
foundrycomando sia disponibile inPATH. - Usare Rust 1.70.0 o versione successiva.
Installazione
Per usare Foundry Local Rust SDK, aggiungere quanto segue a Cargo.toml:
[dependencies]
foundry-local = "0.1.0"
In alternativa, è possibile aggiungere il crate cassa Foundry Local usando cargo:
cargo add foundry-local
Avvio rapido
Usare questo frammento di codice per verificare che l'SDK possa avviare il servizio e leggere il catalogo locale.
use anyhow::Result;
use foundry_local::FoundryLocalManager;
#[tokio::main]
async fn main() -> Result<()> {
let mut manager = FoundryLocalManager::builder().bootstrap(true).build().await?;
let models = manager.list_catalog_models().await?;
println!("Catalog models available: {}", models.len());
Ok(())
}
In questo esempio viene stampato un numero diverso da zero quando il servizio è in esecuzione e il catalogo è disponibile.
Riferimenti:
FoundryLocalManager
Responsabile delle operazioni di Foundry Local SDK.
Fields
-
service_uri: Option<String>— URI del servizio Foundry. -
client: Option<HttpClient>— Client HTTP per le richieste API. -
catalog_list: Option<Vec<FoundryModelInfo>>— Elenco memorizzato nella cache dei modelli di catalogo. -
catalog_dict: Option<HashMap<String, FoundryModelInfo>>— Dizionario memorizzato nella cache dei modelli di catalogo. -
timeout: Option<u64>— Timeout client HTTP facoltativo.
Methods
pub fn builder() -> FoundryLocalManagerBuilder
Creare un nuovo generatore perFoundryLocalManager.pub fn service_uri(&self) -> Result<&str>
Ottenere l'URI del servizio.
Restituisce: URI del servizio Foundry.fn client(&self) -> Result<&HttpClient>
Ottenere l'istanza del client HTTP.
Restituisce: client HTTP.pub fn endpoint(&self) -> Result<String>
Ottenere l'endpoint per il servizio.
Restituisce: endpoint URL.pub fn api_key(&self) -> String
Ottenere la chiave API per l'autenticazione.
Restituisce: chiave API.pub fn is_service_running(&mut self) -> bool
Controllare se il servizio è in esecuzione e impostare l'URI del servizio, se trovato.
Restituisce:truese è in esecuzione, altrimentifalse.pub fn start_service(&mut self) -> Result<()>
Avvia il servizio locale Foundry.pub async fn list_catalog_models(&mut self) -> Result<&Vec<FoundryModelInfo>>
Ottenere un elenco dei modelli disponibili nel catalogo.pub fn refresh_catalog(&mut self)
Aggiornare la cache del catalogo.pub async fn get_model_info(&mut self, alias_or_model_id: &str, raise_on_not_found: bool) -> Result<FoundryModelInfo>
Ottenere informazioni sul modello in base all'alias o all'ID.
Argomenti:-
alias_or_model_id: alias o ID modello. -
raise_on_not_found: Se true, errore se non trovato.
-
pub async fn get_cache_location(&self) -> Result<String>
Ottieni il percorso della cache come stringa.pub async fn list_cached_models(&mut self) -> Result<Vec<FoundryModelInfo>>
Elencare i modelli memorizzati nella cache.pub async fn download_model(&mut self, alias_or_model_id: &str, token: Option<&str>, force: bool) -> Result<FoundryModelInfo>
Scaricare un modello.
Argomenti:-
alias_or_model_id: alias o ID modello. -
token: token di autenticazione facoltativo. -
force: forzare il download se già memorizzato nella cache.
-
pub async fn load_model(&mut self, alias_or_model_id: &str, ttl: Option<i32>) -> Result<FoundryModelInfo>
Caricare un modello per l'inferenza.
Argomenti:-
alias_or_model_id: alias o ID modello. -
ttl: time-to-live opzionale in secondi.
-
pub async fn unload_model(&mut self, alias_or_model_id: &str, force: bool) -> Result<()>
Scaricare un modello.
Argomenti:-
alias_or_model_id: alias o ID modello. -
force: forzare lo scaricamento anche se in uso.
-
pub async fn list_loaded_models(&mut self) -> Result<Vec<FoundryModelInfo>>
Elencare i modelli caricati.
FoundryLocalManagerBuilder
Generatore per la creazione di un'istanza FoundryLocalManager.
Fields
-
alias_or_model_id: Option<String>— Alias o ID del modello da scaricare e caricare. -
bootstrap: bool— Indica se avviare il servizio se non è in esecuzione. -
timeout_secs: Option<u64>— Timeout del client HTTP in secondi.
Methods
pub fn new() -> Self
Creare una nuova istanza di generatore.pub fn alias_or_model_id(mut self, alias_or_model_id: impl Into<String>) -> Self
Impostare l'alias o l'ID modello per il download e il caricamento.pub fn bootstrap(mut self, bootstrap: bool) -> Self
Imposta se avviare il servizio quando non è in esecuzione.pub fn timeout_secs(mut self, timeout_secs: u64) -> Self
Impostare un timeout del client HTTP in secondi.pub async fn build(self) -> Result<FoundryLocalManager>
Creare l'istanzaFoundryLocalManager.
FoundryModelInfo
Rappresenta informazioni su un modello.
Fields
-
alias: String— L'alias del modello. -
id: String— ID modello. -
version: String— La versione del modello. -
runtime: ExecutionProvider— Il provider di esecuzione (CPU, CUDA e così via). -
uri: String— URI del modello. -
file_size_mb: i32— Dimensioni del file del modello in MB. -
prompt_template: serde_json::Value— Richiedi modello per il modello. -
provider: String— Nome del provider. -
publisher: String— Nome editore. -
license: String— Tipo di licenza. -
task: String— Attività modello (ad esempio, generazione di testo).
Methods
from_list_response(response: &FoundryListResponseModel) -> Self
Crea un oggettoFoundryModelInfoda una risposta del catalogo.to_download_body(&self) -> serde_json::Value
Converte le informazioni sul modello in un corpo JSON per le richieste di download.
ExecutionProvider
Enumerazione per i provider di esecuzione supportati.
CPUWebGPUCUDAQNN
Methods
get_alias(&self) -> String
Restituisce un alias stringa per il provider di esecuzione.
ModelRuntime
Descrive l'ambiente di runtime per un modello.
device_type: DeviceTypeexecution_provider: ExecutionProvider