API tabella e SQL nei cluster Apache Flink® in HDinsight su AKS
Nota
Azure HDInsight su AKS verrà ritirato il 31 gennaio 2025. Prima del 31 gennaio 2025, sarà necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare interruzioni improvvise dei carichi di lavoro. I cluster rimanenti nella sottoscrizione verranno arrestati e rimossi dall’host.
Importante
Questa funzionalità è attualmente disponibile solo in anteprima. Le Condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure includono termini legali aggiuntivi che si applicano a funzionalità di Azure in versione beta, in anteprima o in altro modo non ancora disponibili a livello generale. Per informazioni su questa anteprima specifica, vedere Informazioni sull'anteprima di Azure HDInsight nel servizio Azure Kubernetes. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire Microsoft per altri aggiornamenti nella Community di Azure HDInsight.
Apache Flink include due API relazionali, l'API Tabella e SQL, per l'elaborazione unificata di flussi e batch. L'API Tabella è un'API di query integrata nel linguaggio che consente la composizione di query da operatori relazionali, ad esempio selezione, filtro e join in modo intuitivo. Il supporto SQL di Flink è basato su Apache Calcite, che implementa lo standard SQL.
Le interfacce delle API Tabella e SQL si integrano perfettamente tra loro e l'API DataStream di Flink. È possibile passare facilmente tra tutte le API e le librerie basate su di esse.
Apache Flink SQL
Analogamente ad altri motori SQL, le query Flink operano sulle tabelle. Differisce da un database tradizionale perché Flink non gestisce i dati inattivi localmente; le query funzionano invece in modo continuo su tabelle esterne.
Le pipeline di elaborazione dei dati Flink iniziano con le tabelle di origine e terminano con le tabelle sink. Le tabelle di origine producono righe eseguite durante l'esecuzione della query; sono le tabelle a cui si fa riferimento nella clausola FROM di una query. I connettori possono essere di tipo HDInsight Kafka, HDInsight HBase, Hub eventi di Azure, database, file system o qualsiasi altro sistema il cui connettore si trova nel classpath.
Uso di Flink SQL Client nei cluster HDInsight su AKS
È possibile fare riferimento a questo articolo su come usare l'interfaccia della riga di comando da Secure Shell nel portale di Azure. Ecco alcuni esempi rapidi di come iniziare.
Per avviare il client SQL
./bin/sql-client.shPer passare un file SQL di inizializzazione da eseguire insieme a sql-client
./sql-client.sh -i /path/to/init_file.sqlPer impostare una configurazione in sql-client
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL
Flink SQL supporta le istruzioni CREATE seguenti
- CREATE TABLE
- CREATE DATABASE
- CREATE CATALOG
Di seguito è riportata una sintassi di esempio per definire una tabella di origine usando il connettore jdbc per connettersi a MSSQL, con ID e nome come colonne in un'istruzione CREATE TABLE
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
CREATE DATABASE :
CREATE DATABASE students;
CREATE CATALOG:
CREATE CATALOG myhive WITH ('type'='hive');
È possibile eseguire query continue nella parte superiore di queste tabelle
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Scrivere in una tabella sink da una tabella di origine:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Aggiunta di dipendenze
Le istruzioni JAR vengono usate per aggiungere file JAR utente nel classpath, rimuoverli o visualizzare i file JAR aggiunti nel classpath nel runtime.
Flink SQL supporta le istruzioni JAR seguenti:
- ADD JAR
- SHOW JARS
- REMOVE JAR
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
Metastore Hive nei cluster Apache Flink® in HDInsight su AKS
I cataloghi forniscono metadati, ad esempio database, tabelle, partizioni, viste e funzioni, e informazioni necessarie per accedere ai dati archiviati in un database o in altri sistemi esterni.
In HDInsight su AKS Flink supporta due opzioni di catalogo:
GenericInMemoryCatalog
GenericInMemoryCatalog è un'implementazione in memoria di un catalogo. Tutti gli oggetti sono disponibili solo per la durata della sessione SQL.
HiveCatalog
HiveCatalog ha due funzioni: risorsa di archiviazione permanente per i metadati Flink puri e interfaccia per la lettura e la scrittura di metadati Hive esistenti.
Nota
I cluster HDInsight su AKS includono un'opzione integrata di metastore Hive per Apache Flink. È possibile scegliere metastore Hive durante la creazione del cluster
Come creare e registrare database Flink nei cataloghi
È possibile fare riferimento a questo articolo su come usare l'interfaccia della riga di comando e iniziare a usare Flink SQL Client da Secure Shell nel portale di Azure.
Avviare la sessione
sql-client.sh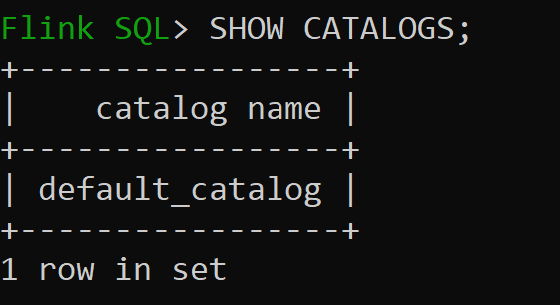
Default_catalog è il catalogo in memoria predefinito
Ora è possibile controllare il database predefinito del catalogo in memoria
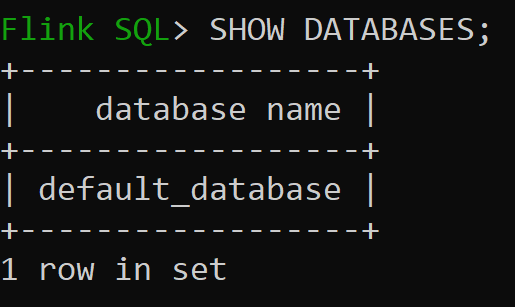
Creiamo ora il catalogo Hive della versione 3.1.2 per usarlo
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Nota
HDInsight su AKS supporta Hive 3.1.2 e Hadoop 3.3.2.
hive-conf-dirè impostato sul percorso/opt/hive-confCreiamo ora un database nel catalogo Hive e impostiamolo come predefinito per la sessione (a meno che non venga modificato).
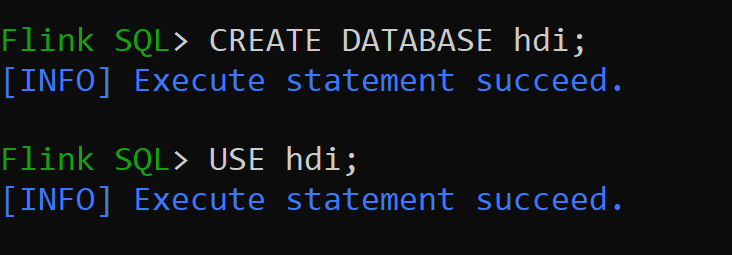
Come creare e registrare tabelle Hive in Hive Catalog
Seguire le istruzioni in Come creare e registrare database Flink nel catalogo
Creare una tabella Flink di tipo connettore Hive senza partizione
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');Inserire dati in hive_table
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';Leggere dati da hive_table
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsNota
La directory Hive Warehouse si trova nel contenitore designato dell'account di archiviazione scelto durante la creazione del cluster Apache Flink, disponibile nella directory hive/warehouse/
Creiamo ora una tabella Flink di tipo connettore Hive con partizione
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
Importante
Esiste una limitazione nota in Apache Flink. Le ultime "n" colonne vengono scelte per le partizioni, indipendentemente dalla colonna di partizione definita dall'utente. FLINK-32596 La chiave di partizione sarà errata quando si usa il dialetto Flink per creare una tabella Hive.
Riferimento
- API Tabella e SQL in Apache Flink
- Apache, Apache Flink, Flink e i nomi dei progetti open source associati sono marchi di Apache Software Foundation (ASF).