Scalabilità automatica dei cluster HDInsight su AKS
Nota
Azure HDInsight su AKS verrà ritirato il 31 gennaio 2025. Prima del 31 gennaio 2025, sarà necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare interruzioni improvvise dei carichi di lavoro. I cluster rimanenti nella sottoscrizione verranno arrestati e rimossi dall’host.
Solo il supporto di base sarà disponibile fino alla data di ritiro.
Importante
Questa funzionalità è attualmente disponibile solo in anteprima. Le Condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure includono termini legali aggiuntivi che si applicano a funzionalità di Azure in versione beta, in anteprima o in altro modo non ancora disponibili a livello generale. Per informazioni su questa anteprima specifica, vedere Informazioni sull'anteprima di Azure HDInsight nel servizio Azure Kubernetes. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire Microsoft per altri aggiornamenti nella Community di Azure HDInsight.
Il dimensionamento di un cluster per soddisfare i requisiti di prestazioni dei processi e gestire i costi in anticipo è sempre difficile da determinare. Uno dei vantaggi redditizi della creazione di data lakehouse sul cloud è l'elasticità, che implica l'uso della funzionalità di scalabilità automatica per ottimizzare facilmente l'utilizzo delle risorse. La scalabilità automatica con Kubernetes è fondamentale per creare un ecosistema ottimizzato per i costi. Siccome i modelli di utilizzo variano in base all'azienda, col tempo potrebbero verificarsi variazioni nei carichi del cluster che potrebbero causare un provisioning dei cluster insufficiente (prestazioni insufficienti) o eccessivo (costi non necessari a causa di risorse inattive).
La funzionalità di scalabilità automatica offerta in HDInsight su AKS può aumentare o diminuire automaticamente il numero di nodi di lavoro nel cluster. La scalabilità automatica usa le metriche del cluster e i criteri di ridimensionamento usati dai clienti.
Questa funzionalità è particolarmente adatta per carichi di lavoro cruciali, che potrebbero avere
- Modelli di traffico variabili o imprevedibili e che richiedono contratti di servizio su prestazioni elevate e scalabilità o
- Pianificazione predeterminata per rendere disponibili i nodi di lavoro necessari per eseguire correttamente i processi nel cluster.
La scalabilità automatica con i cluster HDInsight su AKS rende i cluster convenienti ed elastici in Azure.
Con la scalabilità automatica, i clienti possono ridurre i cluster senza influire sui carichi di lavoro. È abilitata con funzionalità avanzate, ad esempio la rimozione gestita automaticamente e il periodo di raffreddamento. Queste funzionalità consentono agli utenti di effettuare scelte informate sull'aggiunta e la rimozione di nodi in base al carico corrente del cluster.
Funzionamento
Questa funzionalità agisce ridimensionando il numero di nodi entro limiti predefiniti in base alle metriche del cluster o a una pianificazione definita delle operazioni di aumento e riduzione delle prestazioni. Esistono due tipi di condizioni per attivare eventi di scalabilità automatica: trigger basati su soglia per varie metriche delle prestazioni del cluster (c.d. ridimensionamento basato sul carico) e trigger basati sul tempo (c.d. ridimensionamento basato sulla pianificazione).
Il ridimensionamento basato sul carico modifica il numero di nodi nel cluster, all'interno di un intervallo impostato, per garantire un utilizzo ottimale della CPU e ridurre al minimo i costi in esecuzione.
Il ridimensionamento basato sulla pianificazione modifica il numero di nodi nel cluster in base a una pianificazione delle operazioni di aumento e riduzione delle prestazioni.
Nota
La scalabilità automatica non supporta la modifica del tipo di SKU di un cluster esistente.
Compatibilità dei cluster
La tabella seguente descrive i tipi di cluster compatibili con la funzionalità di scalabilità automatica e gli elementi disponibili o pianificati.
| Carico di lavoro | In base al carico | In base alla pianificazione |
|---|---|---|
| Flink | Pianificato | Sì |
| Trino | Sì** | Sì** |
| Spark | Sì** | Sì** |
** La rimozione gestita automaticamente è configurabile.
Metodo di ridimensionamento
Ridimensionamento basato sulla pianificazione:
Quando si prevede che i processi verranno eseguiti in base a pianificazioni fisse e per una durata prevedibile o si prevede un utilizzo ridotto in determinate ore del giorno, ad esempio ambienti di test e sviluppo in orari post-lavorativi, processi di fine giornata.

Ridimensionamento in base al carico:
Quando i modelli di carico oscillano in modo sostanziale e imprevedibile durante il giorno, ad esempio per l'elaborazione di dati di ordini con oscillazioni casuali in modelli di carico basati su vari fattori.
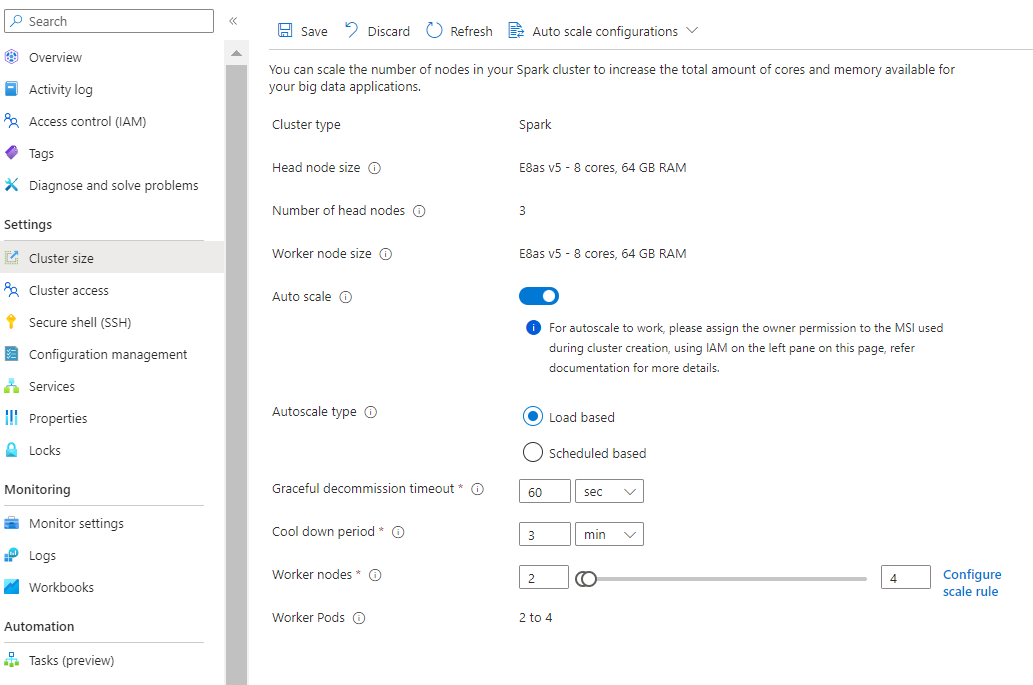
Con la nuova opzione per la configurazione della regola di ridimensionamento, ora è possibile personalizzare le regole di ridimensionamento.
Suggerimento
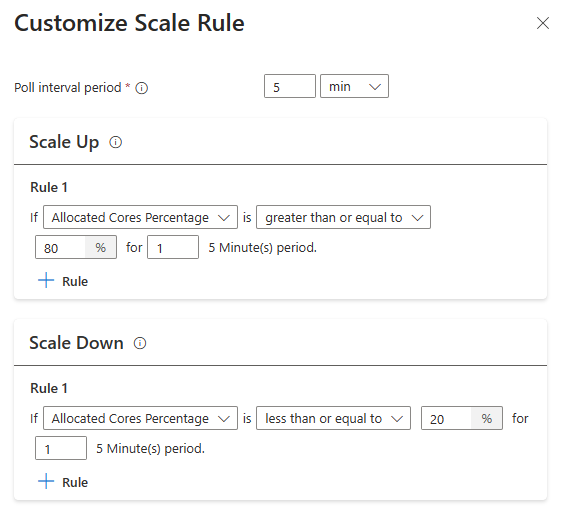
- Le regole di aumento hanno la precedenza quando vengono attivate una o più regole. Anche se una sola delle regole per aumentare le prestazioni suggerisce un provisioning insufficiente del cluster, il cluster tenterà l'aumento. Per la riduzione, non deve essere attivata alcuna regola di aumento.


Condizioni di scalabilità in base al carico
Quando vengono rilevate le condizioni seguenti, la scalabilità automatica invia una richiesta di ridimensionamento
| Aumentare | Riduzione |
|---|---|
| I core allocati sono maggiori dell'80% per l'intervallo di polling di 5 minuti (periodo di controllo di 1 minuto) | I core allocati sono minori o uguali al 20% per l'intervallo di polling di 5 minuti (periodo di controllo di 1 minuto) |
Per l'aumento, la scalabilità automatica genera una richiesta di aumento per aggiungere il numero di nodi richiesto. L'aumento si basa sul numero di nuovi nodi di lavoro necessari per soddisfare i requisiti correnti di CPU e memoria. Questo valore è limitato al numero massimo di nodi di lavoro impostati.
Per la riduzione, la scalabilità automatica genera una richiesta di rimozione di alcuni nodi. Le considerazioni sulla riduzione includono il numero di pod per nodo, i requisiti correnti di CPU e memoria e i nodi di lavoro, che sono candidati per la rimozione in base all'esecuzione del processo corrente. L'operazione di riduzione prevede prima la disattivazione e quindi il ritiro dei nodi dal cluster.
Importante
Il motore delle regole di scalabilità automatica scarica in modo proattivo gli eventi precedenti ogni 30 minuti per ottimizzare la memoria di sistema. Di conseguenza, esiste un limite massimo di 30 minuti nell'intervallo della regola di ridimensionamento. Per garantire l'attivazione coerente e affidabile delle azioni di ridimensionamento, è fondamentale impostare l'intervallo delle regole di ridimensionamento su un valore minore del limite. Rispettando questa linea guida, è possibile garantire un processo di ridimensionamento uniforme ed efficiente, gestendo in modo efficace le risorse di sistema.
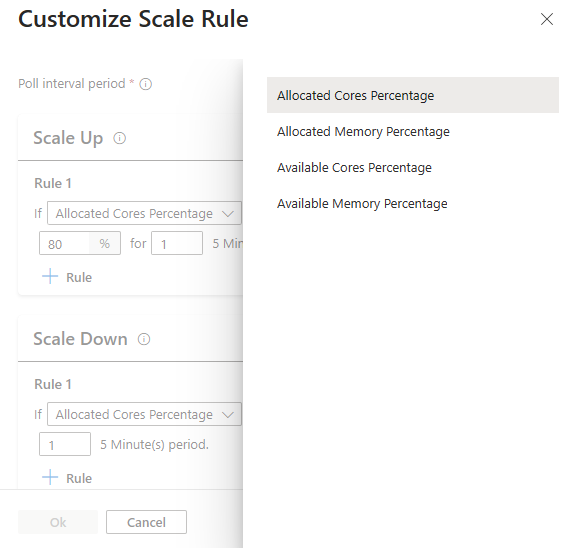
Metriche del cluster
La scalabilità automatica monitora continuamente il cluster e raccoglie le metriche seguenti per il ridimensionamento basato sul carico:
Metriche del cluster disponibili a scopo di ridimensionamento
| Metrico | Descrizione |
|---|---|
| Percentuale di core disponibili | Numero totale di core disponibili nel cluster rispetto al numero totale di core nel cluster. |
| Percentuale di memoria disponibile | La memoria totale (in MB) disponibile nel cluster rispetto alla quantità totale di memoria nel cluster. |
| Percentuale di core allocati | Numero totale di core allocati nel cluster rispetto al numero totale di core nel cluster. |
| Percentuale di memoria usata | La quantità di memoria allocata nel cluster rispetto alla quantità totale di memoria nel cluster. |
Per impostazione predefinita, le metriche precedenti vengono controllate ogni 300 secondi; questo valore è anche configurabile quando si personalizza l'intervallo di polling con l'opzione di personalizzazione della scalabilità automatica. La scalabilità automatica decide per l'aumento o la riduzione in base a queste metriche.
Nota
Per impostazione predefinita, la scalabilità automatica usa il calcolatore di risorse predefinito per YARN per Apache Spark. Il ridimensionamento basato sul carico è disponibile per i cluster Apache Spark.
Rimozione gestita automaticamente
Le aziende hanno bisogno di modi per ottenere il ridimensionamento dei petabyte e rimuovere automaticamente le risorse quando non sono più necessarie. In questo scenario, la funzionalità di rimozione gestita automaticamente risulta utile.
La rimozione gestita automaticamente consente il completamento dei processi anche dopo che la scalabilità automatica ha attivato la rimozione dei nodi di lavoro. Questa funzionalità consente di continuare il provisioning dei nodi fino al completamento dei processi.
Trino: per impostazione predefinita, la rimozione gestita automaticamente è abilitata per i nodi di lavoro. Il coordinatore consente al nodo di lavoro di terminare le attività per la quantità di tempo configurata prima di rimuovere il ruolo di lavoro dal cluster. È possibile configurare il timeout usando il parametro Trino nativo
shutdown.grace-periodo nella pagina di configurazione del servizio del portale di Azure.Apache Spark: la riduzione può influire o arrestare eventuali processi in esecuzione nel cluster. Se si abilitano le impostazioni di rimozione gestita automaticamente nel portale di Azure, incorpora la rimozione gestita automaticamente dei nodi YARN e garantisce che tutte le operazioni in corso in un nodo di lavoro vengano completato prima che il nodo venga rimosso dal cluster HDInsight su AKS.
Periodo di raffreddamento
Per evitare operazioni di aumento continue, il motore della scalabilità automatica attende un intervallo configurabile prima di avviare un'altra serie di operazioni di aumento. Il vapore predefinito è impostato a 180 secondi
Nota
- Nelle regole di ridimensionamento personalizzate, nessun trigger della regola può avere un intervallo di attivazione maggiore di 30 minuti. Dopo che si verifica un evento di ridimensionamento automatico, la quantità di tempo di attesa prima di applicare un altro criterio di ridimensionamento.
- Il periodo di raffreddamento deve essere maggiore dell'intervallo dei criteri, in modo che le metriche del cluster essere reimpostate.
Operazioni preliminari
Per il funzionamento della scalabilità automatica, è necessario assegnare l'autorizzazione di proprietario o collaboratore a MSI (usata durante la creazione del cluster) a livello di cluster, usando IAM nel riquadro sinistro.
Fare riferimento all'illustrazione seguente e ai passaggi elencati su come aggiungere un'assegnazione di ruolo

Selezionare Aggiungi assegnazione di ruolo,
- Tipo di assegnazione: ruoli di amministratore con privilegi
- Ruolo: Proprietario o Collaboratore
- Membri: scegliere Identità gestita e selezionare l'Identità gestita assegnata dall'utente che è stata assegnata durante la fase di creazione del cluster.
- Assegnare il ruolo .

Creare un cluster con scalabilità automatica basata sulla pianificazione
Dopo aver creato il pool di cluster, creare un nuovo cluster con il carico di lavoro desiderato (nel tipo di cluster) e completare gli altri passaggi come parte del normale processo di creazione del cluster.
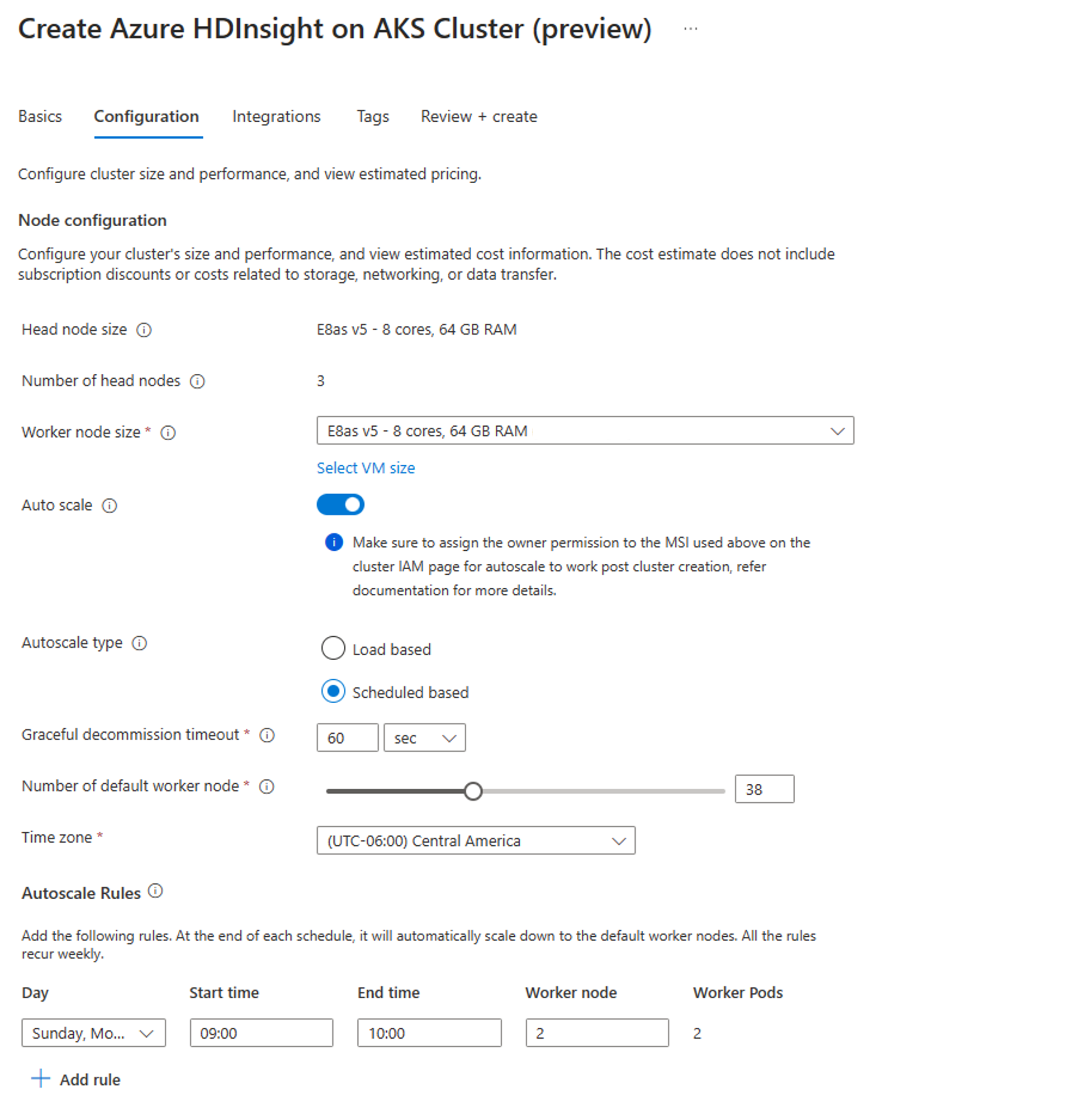
Nella scheda Configurazione, abilitare l'interruttore Ridimensiona automaticamente.
Selezionare la scalabilità Basata sulla pianificazione
Selezionare il fuso orario e quindi fare clic su + Aggiungi regola
Selezionare i giorni della settimana in cui applicare la nuova condizione.
Modificare l'ora in cui la condizione deve essere applicata e il numero di nodi su cui deve essere ridimensionato il cluster.
Nota
- Per i funzionamento della scalabilità automatica, l'utente deve avere ruolo "proprietario" o "collaboratore" nel cluster MSI.
- Il valore predefinito definisce le dimensioni iniziali del cluster al momento della creazione.
- La differenza tra due pianificazioni è impostata per impostazione predefinita per 30 minuti.
- Il valore dell'ora segue il formato di 24 ore
- In caso di finestra continua di oltre 24 ore nei giorni, è necessario impostare la pianificazione della scalabilità automatica tra giorni e la scalabilità automatica presuppone che le 23:59 siano 00:00 (con lo stesso numero di nodi) che si estendono tra due giorni dalle 22:00 alle 23:59, dalle 00:00 alle 02:00 dalle 22:00 alle 02:00.
- Per impostazione predefinita, le pianificazioni vengono impostate nell'ora UTC (Coordinated Universal Time). È sempre possibile eseguire l'aggiornamento al fuso orario corrispondente al fuso orario locale nell'elenco a discesa disponibile. Quando ci si trova in un fuso orario che osserva l'ora legale, la pianificazione non viene modificata automaticamente, ma è necessario gestire gli aggiornamenti della pianificazione.

Creare un cluster con scalabilità automatica basata sul carico
Dopo aver creato il pool di cluster, creare un nuovo cluster con il carico di lavoro desiderato (nel tipo di cluster) e completare gli altri passaggi come parte del normale processo di creazione del cluster.
Nella scheda Configurazione, abilitare l'interruttore Ridimensiona automaticamente.
Selezionare la scalabilità automatica Basata sul carico
In base al tipo di carico di lavoro, sono disponibili opzioni per aggiungere il timeout della rimozione gestita automaticamente e il periodo di raffreddamento
Selezionare il numero minimo e massimo di nodi e, se necessario, configurare le regole di ridimensionamento per personalizzare la scalabilità automatica in base alle esigenze.

Suggerimento
- La sottoscrizione in uso ha una quota di capacità per ogni area. Il numero totale di core dei nodi head e il numero massimo di nodi di lavoro non può superare la quota di capacità. Questa quota tuttavia è un limite flessibile, in quanto è sempre possibile creare un ticket di supporto per aumentarla facilmente.
- Se si supera il limite della quota totale di core, verrà visualizzato un messaggio di errore che indica
The maximum node count you can select is {maxCount} due to the remaining quota in the selected subscription ({remaining} cores). - Le regole di aumento hanno la precedenza quando vengono attivate una o più regole. Anche se una sola delle regole per aumentare le prestazioni suggerisce un provisioning insufficiente del cluster, il cluster tenterà l'aumento. Per la riduzione, non deve essere attivata alcuna regola di aumento.
- In anteprima pubblica, HDInsight su AKS supporta fino a 500 nodi in un cluster.

Creare un cluster con un modello di Resource Manager
Scalabilità automatica basata sulla pianificazione
È possibile creare un cluster HDInsight su AKS con scalabilità automatica basata sulla pianificazione usando un modello di Azure Resource Manager, aggiungendo una scalabilità automatica alla sezione clusterProfile -> autoscaleProfile.
Il nodo con scalabilità automatica contiene una ricorrenza con un fuso orario e una pianificazione che descrive quando viene eseguita la modifica. Per un modello di Resource Manager completo, vedere l'esempio JSON
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "ScheduleBased",
"gracefulDecommissionTimeout": 60,
"scheduleBasedConfig": {
"schedules": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday"
],
"startTime": "09:00",
"endTime": "10:00",
"count": 2
},
{
"days": [
"Sunday",
"Saturday"
],
"startTime": "12:00",
"endTime": "22:00",
"count": 5
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "22:00",
"endTime": "23:59",
"count": 6
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "00:00",
"endTime": "05:00",
"count": 6
}
],
"timeZone": "UTC",
"defaultCount": 110
}
}
}
Suggerimento
- È necessario impostare pianificazioni non in conflitto usando distribuzioni ARM per evitare errori delle operazioni di ridimensionamento.
Scalabilità automatica basata sul carico
È possibile creare un cluster HDInsight su AKS con scalabilità automatica basata sul carico usando un modello di Azure Resource Manager, aggiungendo una scalabilità automatica alla sezione clusterProfile -> autoscaleProfile.
Il nodo con scalabilità automatica contiene
- un intervallo di polling, periodo di raffreddamento,
- rimozione gestita automaticamente,
- numero minimo e massimo di nodi,
- regole di soglia standard,
- metriche di ridimensionamento che descrivono quando viene apportata la modifica.
Per un modello di Resource Manager completo, vedere l'esempio JSON di seguito
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "LoadBased",
"gracefulDecommissionTimeout": 60,
"loadBasedConfig": {
"minNodes": 2,
"maxNodes": 157,
"pollInterval": 300,
"cooldownPeriod": 180,
"scalingRules": [
{
"actionType": "scaleup",
"comparisonRule": {
"threshold": 80,
"operator": " greaterThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
},
{
"actionType": "scaledown",
"comparisonRule": {
"threshold": 20,
"operator": " lessThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
}
]
}
}
}
Tramite l'API REST
Per abilitare o disabilitare la scalabilità automatica in un cluster in esecuzione usando l'API REST, effettuare una richiesta PATCH all'endpoint di scalabilità automatica: https://management.azure.com/subscriptions/{{USER_SUB}}/resourceGroups/{{USER_RG}}/providers/Microsoft.HDInsight/clusterpools/{{CLUSTER_POOL_NAME}}/clusters/{{CLUSTER_NAME}}?api-version={{HILO_API_VERSION}}
- Usare i parametri appropriati nel payload della richiesta. Il payload JSON può essere usato per abilitare la scalabilità automatica.
- Usare il payload (autoscaleProfile: null) o usare il flag (abilitato, false) per disabilitare la scalabilità automatica.
- Per informazioni di riferimento, vedere gli esempi JSON indicati nel passaggio precedente.
Sospendere la scalabilità automatica per un cluster in esecuzione
Nella scalabilità automatica è stata introdotta la funzionalità di sospensione. Ora, usando il portale di Azure, è possibile sospendere la scalabilità automatica in un cluster in esecuzione. Il diagramma seguente illustra come selezionare la sospensione e la ripresa della scalabilità automatica

La ripresa è possibile quando si desidera riprendere le operazioni di scalabilità automatica.

Suggerimento
Quando si configurano più pianificazioni e si sospende la scalabilità automatica, la pianificazione successiva non viene attivata. Il numero di nodi rimane invariato, anche se i nodi si trovano in uno stato di rimozione.
Copiare le configurazioni di scalabilità automatica
Usando il portale di Azure, ora è possibile copiare le stesse configurazioni della scalabilità automatica per una stessa forma di cluster nel pool di cluster; è possibile usare questa funzionalità ed esportare o importare le stesse configurazioni.

Monitoraggio delle attività di scalabilità automatica
Stato del cluster
Lo stato del cluster elencato nel portale di Azure consente di monitorare le attività di scalabilità automatica. Tutti i messaggi di stato del cluster visualizzati sono descritti nell'elenco.
| Stato del cluster | Descrizione |
|---|---|
| Completato | Il cluster funziona normalmente. Tutte le attività di scalabilità automatica precedenti sono state completate correttamente. |
| Accettata | L'operazione del cluster (ad esempio un aumento) viene accettata, in attesa del completamento dell'operazione. |
| Non riuscito | Ciò implica che un'operazione corrente non è riuscita per qualche motivo e il cluster potrebbe non funzionare. |
| Annullati | L'operazione corrente è annullata. |
Per visualizzare il numero corrente di nodi nel cluster, passare al grafico Dimensioni del cluster nella pagina Panoramica del cluster.

Cronologia delle operazioni
È possibile visualizzare la cronologia degli aumenti e delle riduzioni del cluster come parte delle metriche del cluster. È possibile anche elencare tutte le azioni di ridimensionamento del giorno o della settimana precedente o di un altro periodo.

Risorse aggiuntive