Che cos'è Apache Spark™ in HDInsight nel servizio Azure Kubernetes? (anteprima)
Importante
Questa funzionalità è attualmente disponibile solo in anteprima. Le condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure disponibili in versione beta, in anteprima o non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere Informazioni sull'anteprima di Azure HDInsight nel servizio Azure Kubernetes. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire microsoft per altri aggiornamenti nella community di Azure HDInsight.
Apache Spark™ è un framework di elaborazione parallela che supporta l'elaborazione in memoria per migliorare le prestazioni delle applicazioni analitiche di Big Data.
Apache Spark™ offre primitive per il calcolo dei cluster in memoria. Un processo Spark può caricare i dati e memorizzarli nella cache in memoria ed eseguire query su di essi ripetutamente. L'elaborazione in memoria è più veloce rispetto alle applicazioni basate su disco, ad esempio Hadoop, che condivide i dati tramite hadoop distributed file system (HDFS). Apache Spark consente l'integrazione con i linguaggi di programmazione Scala e Python per consentire di modificare set di dati distribuiti come raccolte locali. Non è necessario strutturare tutti gli elementi come operazioni di mapping e riduzione.
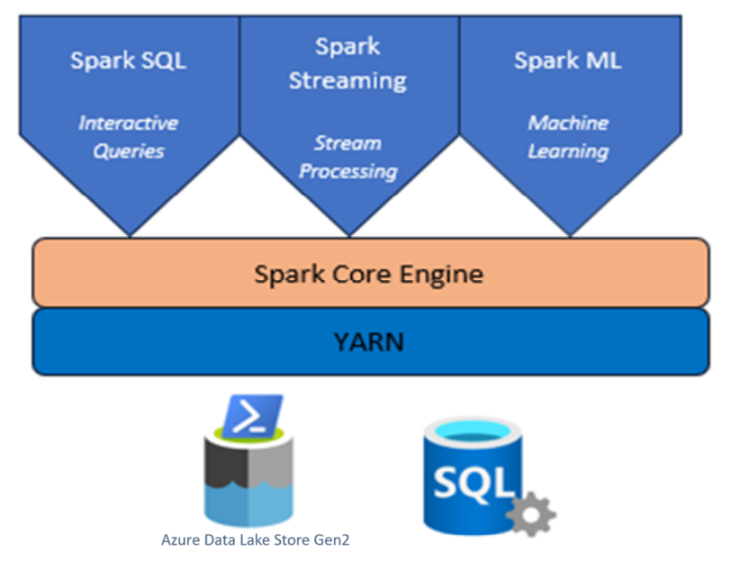
Cluster Apache Spark con HDInsight nel servizio Azure Kubernetes
Azure HDInsight è un servizio di analisi open source, gestito e ad ampio spettro per le aziende.
Apache Spark™ in Azure HDInsight nel servizio Azure Kubernetes è il servizio Spark gestito in Microsoft Azure. Con Apache Spark in Azure HDInsight nel servizio Azure Kubernetes, è possibile archiviare ed elaborare tutti i dati all'interno di Azure. I cluster Spark in HDInsight sono compatibili con o Azure Data Lake Archiviazione Gen2, consente di applicare l'elaborazione Spark negli archivi dati esistenti.
Il framework Apache Spark per HDInsight nel servizio Azure Kubernetes consente l'analisi rapida dei dati e il cluster computing usando l'elaborazione in memoria. Jupyter Notebook consente di interagire con i dati, combinare codice con testo di markdown ed eseguire semplici visualizzazioni.
Apache Spark nel servizio Azure Kubernetes in HDInsight composto da più componenti come pod.
Controller del cluster
I controller del cluster sono responsabili dell'installazione e della gestione del rispettivo servizio. Diversi controller vengono installati e gestiti in un cluster Spark.
Componenti del servizio Apache Spark
Servizio Zookeeper: un cluster Zookeeper a tre nodi, funge da coordinatore distribuito o archiviazione a disponibilità elevata per altri servizi.
Servizio Yarn: cluster Hadoop Yarn, i processi Spark verranno pianificati nel cluster come applicazioni Yarn.
Interfacce client: cluster Apache Spark in HDInsight nel servizio Azure Kubernetes, fornisce varie interfacce client. Livy Server, Jupyter Notebook, Server cronologia Spark fornisce servizi Spark agli utenti del servizio Azure Kubernetes.
Riferimento
- Apache, Apache Spark, Spark e i nomi dei progetti open source associati sono marchi di Apache Software Foundation (ASF).
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per