Avvio rapido: Eseguire query Apache Hive in Azure HDInsight con Apache Zeppelin
Questo argomento di avvio rapido illustra come usare Apache Zeppelin per eseguire query Apache Hive in Azure HDInsight. I cluster Interactive Query HDInsight includono notebook Apache Zeppelin che è possibile usare per eseguire query Hive interattive.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Cluster HDInsight Interactive Query. Per creare un cluster HDInsight, vedere Creare un cluster. Assicurarsi di scegliere il tipo di cluster Interactive Query.
Creare una nota di Apache Zeppelin
Nell'URL
https://CLUSTERNAME.azurehdinsight.net/zeppelinseguente sostituireCLUSTERNAMEcon il nome del cluster. Immettere quindi l'URL in un Web browser.Immettere il nome utente e la password dell'account di accesso del cluster. Dalla pagina di Zeppelin è possibile creare una nuova nota o aprire le note esistenti. HiveSample contiene alcune query Hive di esempio.
Selezionare Create new note (Crea una nuova nota).
Nella finestra di dialogo Create new note (Crea una nuova nota) digitare o selezionare i valori seguenti:
- Nome nota: immettere un nome per la nota.
- Interprete predefinito: selezionare jdbc dall'elenco a discesa.
Selezionare Create Note (Crea nota).
Immettere la query Hive seguente nella sezione del codice e quindi premere MAIUSC+INVIO:
%jdbc(hive) show tables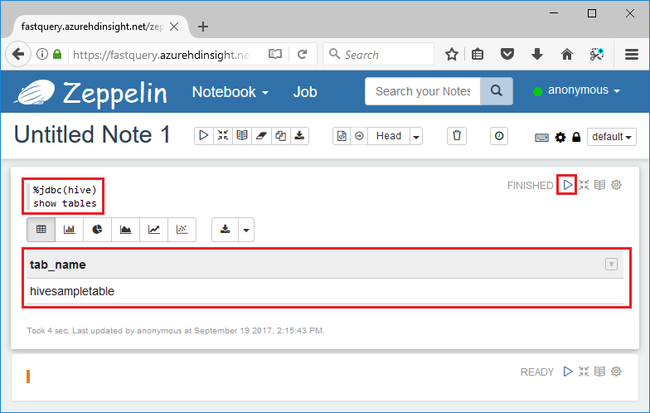
L'istruzione %jdbc(hive) nella prima riga indica al notebook di usare l'interprete JDBC Hive.
La query dovrebbe restituire una tabella Hive denominata hivesampletable.
Di seguito sono illustrate altre due query Hive che è possibile eseguire su hivesampletable:
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}Rispetto a Hive tradizionale, i risultati della query vengono restituiti più velocemente.
Esempi aggiuntivi
Creare una tabella. Eseguire il codice seguente nel notebook Zeppelin:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Caricare i dati nella nuova tabella. Eseguire il codice seguente nel notebook Zeppelin:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Inserire un singolo record. Eseguire il codice seguente nel notebook Zeppelin:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Per una sintassi aggiuntiva, vedere il manuale del linguaggio Hive.
Pulire le risorse
Al termine dell'argomento di avvio rapido, può essere opportuno eliminare il cluster. Con HDInsight, i dati vengono archiviati in Archiviazione di Azure ed è possibile eliminare tranquillamente un cluster quando non è in uso. Vengono addebitati i costi anche per i cluster HDInsight che non sono in uso. Poiché i costi per il cluster sono decisamente superiori a quelli per l'archiviazione, eliminare i cluster quando non vengono usati è una scelta economicamente conveniente.
Per eliminare un cluster, vedere Eliminare un cluster HDInsight tramite browser, PowerShell o l'interfaccia della riga di comando di Azure.
Passaggi successivi
Questo argomento di avvio rapido ha illustrato come usare Apache Zeppelin per eseguire query Apache Hive in Azure HDInsight. Per altre informazioni sulle query Hive, l'articolo successivo illustrerà come eseguire query con Visual Studio.