Dimensionare manualmente i cluster Azure HDInsight
HDInsight offre elasticità con le opzioni per aumentare e ridurre il numero di nodi di lavoro nei cluster. Questa elasticità consente di ridurre un cluster fuori orario lavorativo o nei fine settimana. Quindi di espanderlo durante il picco delle richieste aziendali.
Aumentare le dimensioni del cluster prima dell'elaborazione batch periodica in modi che abbia risorse adeguate. Al termine dell'elaborazione e quando l'utilizzo diminuisce, ridurre le dimensioni del cluster HDInsight a un numero inferiore di nodi di lavoro.
È possibile dimensionare il cluster usando uno dei metodi seguenti. È anche possibile usare opzioni di scalabilità automatica per aumentare e ridurre automaticamente le dimensioni in risposta a determinate metriche.
Nota
Sono supportati solo i cluster con HDInsight versione 3.1.3 o successive. Se non si è certi della versione del cluster, è possibile controllare la pagina delle proprietà.
Utilità per dimensionare i cluster
Microsoft fornisce le utilità seguenti per dimensionare i cluster:
| Utilità | Descrizione |
|---|---|
| PowerShell Az | Set-AzHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| PowerShell AzureRM | Set-AzureRmHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| Interfaccia della riga di comando di Azure | az hdinsight resize --resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE |
| Interfaccia della riga di comando classica di Azure | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Azure portal | Aprire il riquadro del cluster HDInsight, selezionare Dimensioni cluster nel menu a sinistra, quindi nel riquadro Dimensioni cluster digitare il numero di nodi di lavoro e selezionare Salva. |
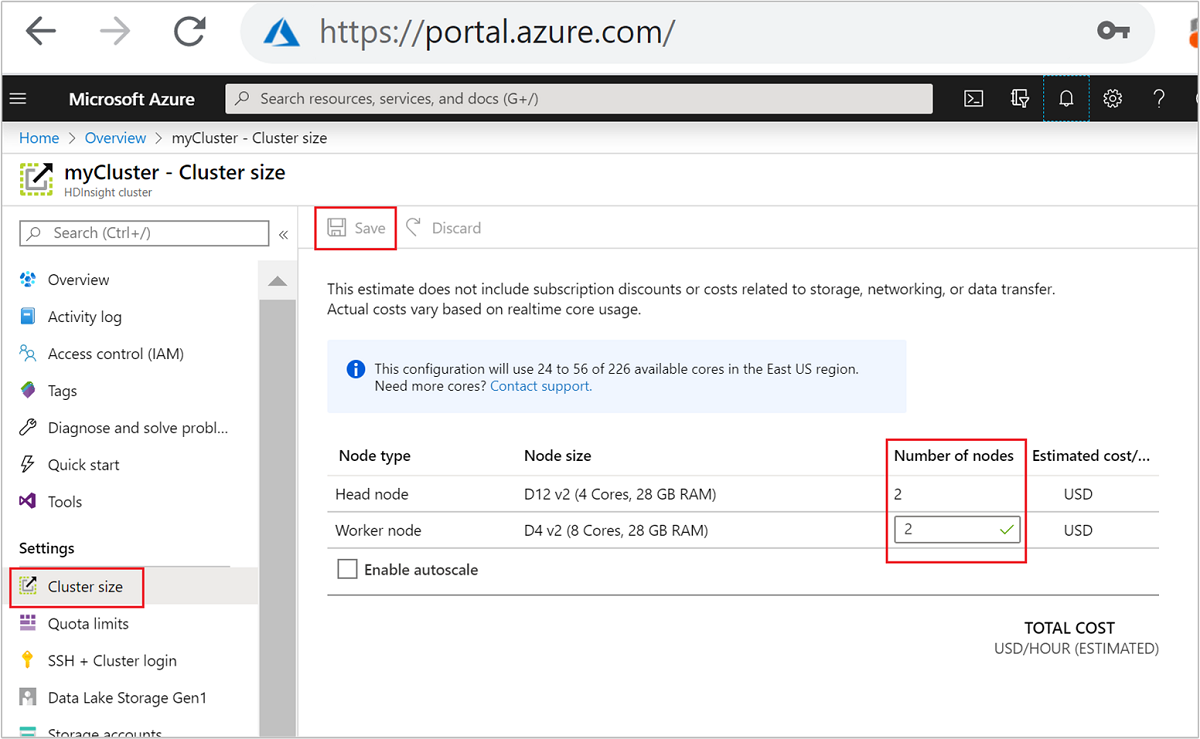
Usando uno di questi metodi, è possibile aumentare o ridurre il cluster HDInsight in pochi minuti.
Importante
- La versione classica dell'interfaccia della riga di comando di Azure è deprecata e deve essere usata solo con il modello di distribuzione classico. Per tutte le altre distribuzioni, usare l'interfaccia della riga di comando di Azure.
- Il modulo AzureRM di PowerShell è deprecato. Usare il modulo Az quando possibile.
Impatto delle operazioni di ridimensionamento
Quando si aggiungono nodi al cluster HDInsight in esecuzione (aumento delle dimensioni), i processi rimangono invariati. È possibile inviare nuovi processi in tutta sicurezza durante l'esecuzione del processo di ridimensionamento. Se l'operazione di ridimensionamento non riesce, l'errore lascia il cluster in uno stato funzionale.
Se si rimuovono nodi (riduzione delle dimensioni), i processi in sospeso o in esecuzione generano un errore al termine dell'operazione di ridimensionamento. L'errore è dovuto al riavvio di alcuni servizi durante il processo di ridimensionamento. Il cluster potrebbe rimanere bloccato in modalità provvisoria durante un'operazione di ridimensionamento manuale.
Impatto della modifica del numero di nodi dati per ogni tipo di cluster supportato da HDInsight:
Apache Hadoop
È possibile aumentare facilmente il numero di nodi di lavoro in un cluster Hadoop in esecuzione senza influire sui processi. È inoltre possibile inviare nuovi processi mentre è in corso l'operazione. Gli errori durante un'operazione di ridimensionamento vengono gestiti correttamente. Il cluster viene sempre lasciato in uno stato funzionale.
Quando le dimensioni di un cluster Hadoop vengono ridotte a un numero inferiore di nodi, alcuni servizi vengono riavviati. A causa di questo comportamento, tutti i processi in esecuzione e in sospeso avranno esito negativo al completamento dell'operazione di ridimensionamento. È tuttavia possibile inviare nuovamente i processi una volta completata l'operazione.
Apache HBase
È possibile aggiungere o rimuovere facilmente nodi nel cluster HBase mentre è in esecuzione. I server a livello di area vengono bilanciati automaticamente entro pochi minuti dal completamento dell'operazione di ridimensionamento. Tuttavia, è possibile bilanciare manualmente i server a livello di area. Accedere al nodo head del cluster ed eseguire i comandi seguenti:
pushd %HBASE_HOME%\bin hbase shell balancerPer altre informazioni sull'uso della shell HBase, vedere Iniziare a usare un esempio di Apache HBase in HDInsight.
Nota
Non applicabile per i cluster Kafka.
Apache Hive LLAP
Dopo il ridimensionamento a
Nnodi di lavoro, HDInsight imposta automaticamente le configurazioni seguenti e riavvia Hive.- Numero massimo totale di query simultanee:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Numero di nodi usati da LLAP di Hive:
num_llap_nodes = N - Numero di nodi per l'esecuzione del daemon LLAP di Hive:
num_llap_nodes_for_llap_daemons = N
- Numero massimo totale di query simultanee:
Come ridurre in modo sicuro le dimensioni di un cluster
Ridurre le dimensioni di un cluster con i processi in esecuzione
Per evitare che i processo in esecuzione generino un errore durante un operazione di riduzione delle dimensioni, è possibile provare tre soluzioni:
- Attendere il completamento dei processi prima di ridurre le dimensioni del cluster.
- Terminare manualmente i processi.
- Rinviare i processi al termine dell'operazione di ridimensionamento.
Per visualizzare un elenco dei processi in sospeso e in esecuzione, è possibile usare l'interfaccia utente Resource Manager di YARN seguendo questi passaggi:
Selezionare il proprio cluster nel portale di Azure. Il cluster viene aperto in una nuova pagina del portale.
Nella visualizzazione principale passare a Cluster dashboards>Ambari home. Immettere le credenziali del cluster.
Nell'interfaccia utente di Ambari selezionare YARN nell'elenco dei servizi del menu a sinistra.
Nella pagina YARN selezionare Quick Links e passare il puntatore sul nodo head attivo, quindi selezionare Resource Manager UI.
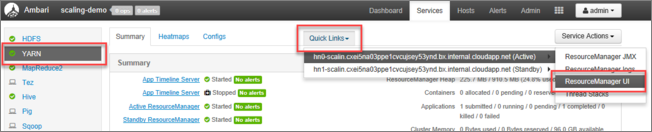
È possibile accedere direttamente all'interfaccia utente Resource Manager con https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/cluster.
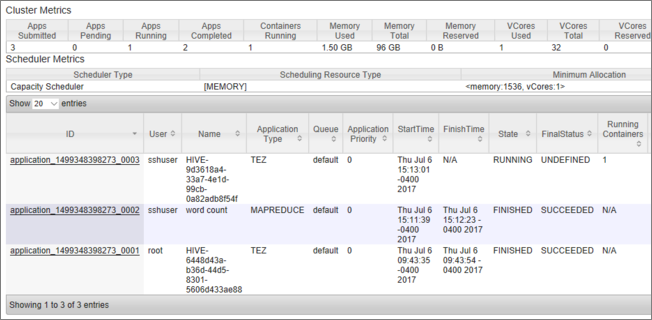
Verrà visualizzato un elenco dei processi, insieme allo stato corrente di ognuno. Lo screenshot mostra un processo attualmente in esecuzione:
Per terminare manualmente l'applicazione in esecuzione, eseguire il comando seguente dalla shell SSH:
yarn application -kill <application_id>
Ad esempio:
yarn application -kill "application_1499348398273_0003"
Blocco in modalità provvisoria
Quando si riducono le dimensioni di un cluster, HDInsight usa le interfacce di gestione di Apache Ambari per rimuovere prima di tutto i nodi di lavoro aggiuntivi. I nodi replicano i blocchi HDFS in altri nodi di lavoro online. Successivamente, HDInsight riduce in modo sicuro le dimensioni del cluster. HDFS passa in modalità provvisoria durante l'operazione di ridimensionamento. HDFS dovrebbe riattivarsi una volta completato il ridimensionamento. In alcuni casi, tuttavia, HDFS si blocca in modalità provvisoria durante un'operazione di ridimensionamento a causa di un blocco di file in fase di replica.
Per impostazione predefinita, HDFS è configurato con un'impostazione dfs.replication pari a 1, che controlla il numero di copie disponibili di ogni blocco di file. Ogni copia di un blocco di file viene archiviata in un nodo diverso del cluster.
Se il numero previsto di copie di blocchi non è disponibile, HDFS entra in modalità provvisoria e Ambari genera avvisi. HDFS può entrare in modalità provvisoria per un'operazione di ridimensionamento. Il cluster potrebbe rimanere bloccato in modalità provvisoria se il numero di nodi richiesto non viene rilevato per la replica.
Errori di esempio quando la modalità sicura è attiva
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
È possibile esaminare i log dei nodi dei nomi nella cartella /var/log/hadoop/hdfs/, in prossimità del momento in cui il cluster è stato ridimensionato, per visualizzare quando è stata attivata la modalità sicura. I file di log sono denominati Hadoop-hdfs-namenode-<active-headnode-name>.*.
La causa radice è che Hive dipende dai file temporanei in HDFS durante l'esecuzione di query. Quando HDFS entra in modalità provvisoria, Hive non può eseguire le query perché non può scrivere in HDFS. I file temporanei in HDFS si trovano nell'unità locale montata nelle singole macchine virtuali dei nodi di lavoro. I file vengono replicati tra gli altri nodi di lavoro in almeno tre repliche.
Come impedire che HDInsight resti bloccato in modalità provvisoria
Esistono diversi modi per impedire che HDInsight venga lasciato in modalità sicura:
- Interrompere tutti i processi Hive prima della riduzione di HDInsight. In alternativa, pianificare il processo di riduzione per evitare conflitti con i processi Hive in esecuzione.
- Pulire manualmente i file temporanei della directory
tmpdi Hive in Hadoop Distributed File System prima della riduzione. - Ridurre HDInsight solo a tre nodi di lavoro come minimo. Evitare di arrivare a un solo nodo di lavoro.
- Eseguire il comando per disattivare la modalità sicura, se necessario.
Le sezioni seguenti descrivono queste opzioni.
Arrestare tutti i processi Hive
Interrompere tutti i processi Hive prima di eseguire la riduzione a un solo nodo di lavoro. Se il carico di lavoro è pianificato, eseguire la riduzione al termine delle operazioni di Hive.
Arrestare i processi Hive prima del ridimensionamento per ridurre al minimo il numero di file temporanei nella cartella tmp (se presenti).
Pulire manualmente i file temporanei di Hive
Se sono rimasti file temporanei di Hive, è possibile pulire questi file manualmente prima della riduzione per evitare la modalità sicura.
Controllare la posizione usata per i file temporanei di Hive esaminando la proprietà di configurazione
hive.exec.scratchdir. Questo parametro è impostato all'interno di/etc/hive/conf/hive-site.xml:<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Arrestare i servizi Hive e assicurarsi che tutte le query e i processi siano stati completati.
Elencare il contenuto della directory dei file temporanei indicata sopra,
hdfs://mycluster/tmp/hive/, per verificare se contiene file:hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveEcco un esempio di output quando sono presenti file:
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoSe si è certi che questi file non sono più necessari ad Hive, è possibile rimuoverli. Assicurarsi che Hive non abbia query in esecuzione esaminando la pagina dell'interfaccia utente Resource Manager di YARN.
Riga di comando di esempio per rimuovere file da Hadoop Distributed File System:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
Ridurre le dimensioni di HDInsight a tre o più nodi di lavoro
Se i cluster si bloccano spesso in modalità provvisoria quando si riduce il numero di nodi di lavoro a meno di tre, mantenere almeno tre nodi di lavoro.
La presenza di tre nodi di lavoro è più costosa rispetto al ridimensionamento a un solo nodo di lavoro. Tuttavia, questa azione impedisce al cluster di rimanere bloccato in modalità provvisoria.
Ridurre le dimensioni di HDInsight a un nodo di lavoro
Anche quando le dimensioni del cluster vengono ridotte a un nodo, il nodo di lavoro 0 rimane inattivo. Il nodo di lavoro 0 non può mai essere rimosso.
Eseguire il comando per disattivare la modalità sicura
L'opzione finale consiste nell'eseguire il comando per uscire dalla modalità provvisoria. Se HDFS è entrato in modalità provvisoria perché il file Hive è in fase di replica, eseguire il comando seguente per uscire dalla modalità provvisoria:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Ridurre le dimensioni di un cluster Apache HBase
I server a livello di area vengono bilanciati automaticamente entro pochi minuti dal completamento di un'operazione di ridimensionamento. Per bilanciare manualmente i server a livello di area, completare questa procedura:
Connettersi al cluster HDInsight tramite SSH. Per altre informazioni, vedere l'articolo su come usare SSH con HDInsight.
Avviare la shell HBase:
hbase shellUsare il comando seguente per bilanciare manualmente i server a livello di area:
balancer
Passaggi successivi
Per informazioni specifiche sul ridimensionamento del cluster HDInsight, vedere: