Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Informazioni sui problemi principali e sulle soluzioni quando si usa Hadoop Distributed File System (HDFS). Per un elenco completo dei comandi vedere la Guida ai comandi HDFS e la Guida alla shell del file system.
Come si accede al sistema HDFS locale dall'interno di un cluster?
Problema
Accedere al sistema HDFS locale dalla riga di comando e dal codice dell'applicazione anziché usare l'archiviazione BLOB di Azure o Azure Data Lake Storage dall'interno del cluster HDInsight.
Procedura per la risoluzione
Al prompt dei comandi usare
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...in modo letterale, come nel comando seguente:hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /userDal codice sorgente usare l'URI
hdfs://mycluster/in modo letterale come nell'applicazione di esempio seguente:import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }Eseguire il file con estensione jar compilato, ad esempio un file denominato
java-unit-tests-1.0.jar, nel cluster HDInsight con il comando seguente:hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
Eccezione di archiviazione per la scrittura nel BLOB
Problema
Quando si usano i comandi hadoop o hdfs dfs per scrivere file di dimensioni pari o superiori a ~12 GB in un cluster HBase, è possibile che si verifichi l'errore seguente:
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
Causa
i cluster HBase in HDInsight usano per impostazione predefinita dimensioni di blocco pari a 256 KB per la scrittura nelle risorse di archiviazione di Azure. Benché questa impostazione sia ottimale per le API HBase o REST, genera un errore se si usano le utilità da riga di comando hadoop o hdfs dfs.
Risoluzione
usare fs.azure.write.request.size per specificare dimensioni maggiori per i blocchi. È possibile eseguire questa modifica in base all’utilizzo tramite il parametro -D. Il comando seguente è un esempio di utilizzo di questo parametro con il comando hadoop:
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
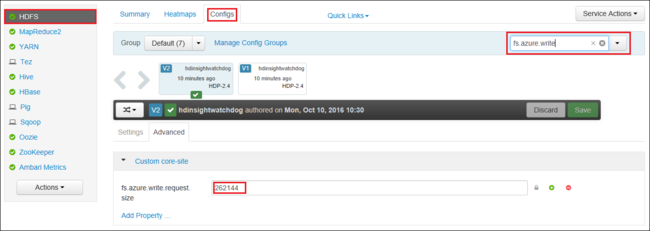
È anche possibile aumentare globalmente il valore di fs.azure.write.request.size usando Apache Ambari. La procedura seguente consente di cambiare il valore nell'interfaccia utente Web di Ambari:
Nel browser passare all'interfaccia utente Web di Ambari per il cluster, L'URL è
https://CLUSTERNAME.azurehdinsight.net, doveCLUSTERNAMEè il nome del cluster. Quando richiesto, immettere il nome dell'amministratore e la password per il cluster.Sul lato sinistro dello schermo selezionale HDFS e quindi fare clic sulla scheda Configs (Configurazioni).
Nel campo Filter (Filtro) immettere
fs.azure.write.request.size.Modificare il valore da 262144 (256 KB) al nuovo valore. Ad esempio, 4194304 (4 MB).
Per altre informazioni sull'uso di Ambari, vedere Gestire i cluster HDInsight mediante l'utilizzo dell'interfaccia utente Web Apache Ambari.
du
Il comando -du visualizza le dimensioni dei file e delle directory contenuti nella directory specificata o la lunghezza di un file nel caso si tratti solo di un file.
L'opzione -s genera un riepilogo aggregato delle lunghezze dei file da visualizzare.
L'opzione -h formatta le dimensioni del file.
Esempio:
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
rm
Il comando -rm elimina i file specificati come argomenti.
Esempio:
hdfs dfs -rm hdfs://mycluster/tmp/testfile
Passaggi successivi
Se il problema riscontrato non è presente in questo elenco o se non si riesce a risolverlo, visitare uno dei canali seguenti per ottenere ulteriore assistenza:
Ricevere risposte dagli esperti di Azure tramite la pagina Supporto della community per Azure.
Connettersi con @AzureSupport, l'account ufficiale Microsoft Azure per migliorare l'esperienza del cliente. Mette in contatto la community di Azure con le risorse giuste: risposte, supporto ed esperti.
Se serve ulteriore assistenza, è possibile inviare una richiesta di supporto dal portale di Azure. Selezionare Supporto nella barra dei menu o aprire l'hub Guida e supporto. Per informazioni più dettagliate, vedere Come creare una richiesta di supporto in Azure. L'accesso al supporto per la gestione delle sottoscrizioni e la fatturazione è incluso nella sottoscrizione di Microsoft Azure e il supporto tecnico viene fornito tramite uno dei piani di supporto di Azure.