Integrare Apache Spark e Apache Hive con Hive Warehouse Connector in Azure HDInsight
Apache Hive Warehouse Connector (HWC) è una libreria che facilita l'utilizzo di Apache Spark e Apache Hive. Supporta attività come il trasferimento di dati tra dataframe Spark e tabelle Hive, anche tramite l'indirizzamento dei flussi di dati Spark in tabelle Hive. Hive Warehouse Connector funge da bridge tra Spark e Hive. Supporta anche Scala, Java e Python come linguaggi di programmazione per lo sviluppo.
Hive Warehouse Connector consente di sfruttare le funzionalità esclusive di Hive e Spark per creare potenti applicazioni Big Data.
Apache Hive offre il supporto per le transazioni di database ACID, ossia atomiche, coerenti, isolate e durature. Per altre informazioni su ACID e sulle transazioni in Hive, vedere Transazioni Hive. Hive offre anche controlli di sicurezza dettagliati tramite Apache Ranger e LLAP (Low Latency Analytical Processing), non disponibili in Apache Spark.
L'API Structured Streaming di Apache Spark offre funzionalità di flusso non disponibili in Apache Hive. A partire da HDInsight 4.0, Apache Spark 2.3.1 e Apache Hive 3.1.0 hanno cataloghi metastore separati, per cui l'interoperabilità risulta difficile.
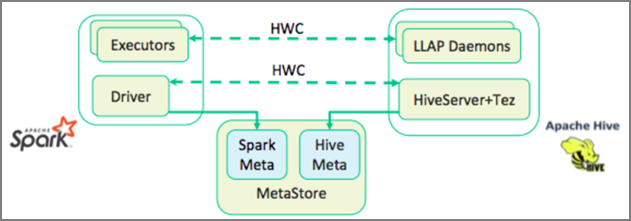
L'Hive Warehouse Connector (HWC) rende più semplice l'uso combinato di Spark e Hive. La libreria HWC carica i dati dai daemon LLAP agli esecutori Spark in parallelo. Questo processo la rende più efficiente e adattabile rispetto a una connessione JDBC standard da Spark a Hive. In questo modo vengono visualizzate due diverse modalità di esecuzione per HWC:
- Modalità Hive JDBC tramite HiveServer2
- Modalità Hive LLAP con daemon LLAP [scelta consigliata]
Per impostazione predefinita, HWC è configurato per l'uso di daemon Hive LLAP. Per l'esecuzione di query Hive (sia di lettura che di scrittura) usando le modalità precedenti con le rispettive API, vedere API HWC.
Alcune delle operazioni supportate da Hive Warehouse Connector sono:
- Descrizione di una tabella
- Creazione di una tabella per dati in formato ORC
- Selezione di dati Hive e recupero di un dataframe
- Scrittura di un dataframe in Hive in batch
- Esecuzione di un'istruzione di aggiornamento di Hive
- Lettura dei dati di una tabella da Hive, trasformazione in Spark e scrittura in una nuova tabella Hive
- Scrittura di un dataframe o di un flusso di Spark in Hive tramite HiveStreaming
Configurazione di Hive Warehouse Connector
Importante
- L'istanza di HiveServer2 Interactive installata nei cluster Spark 2.4 Enterprise Security Package non è supportata per l'uso con Hive Warehouse Connector. È invece necessario configurare un cluster HiveServer2 Interactive separato per ospitare i carichi di lavoro HiveServer2 Interactive. Una configurazione di Hive Warehouse Connector che usa un singolo cluster Spark 2.4 non è supportata.
- La libreria HWC (Hive Warehouse Connector) non è supportata per l'uso con cluster Interactive Query in cui è abilitata la funzionalità Gestione carico di lavoro (WLM).
In uno scenario in cui sono presenti solo carichi di lavoro Spark e si vuole usare la libreria HWC, assicurarsi che il cluster Interactive Query non abbia la funzionalità Gestione carico di lavoro abilitata (la configurazionehive.server2.tez.interactive.queuenon è impostata nelle configurazioni Hive).
Per uno scenario in cui sono presenti sia carichi di lavoro Spark (HWC) che i carichi di lavoro nativi LLAP, è necessario creare due cluster Interactive Query separati con il database metastore condiviso. Un cluster per carichi di lavoro LLAP nativi in cui è possibile abilitare la funzionalità WLM in base alle esigenze e un altro cluster solo per il carico di lavoro HWC in cui la funzionalità WLM non deve essere configurata. È importante notare che è possibile visualizzare i piani di risorse WLM di entrambi i cluster anche se è abilitato in un solo cluster. Non apportare modifiche ai piani di risorse nel cluster in cui la funzionalità WLM è disabilitata perché ciò potrebbe influire sulla funzionalità WLM in altri cluster. - Anche se Spark supporta il linguaggio di calcolo R per semplificare l'analisi dei dati, la libreria Hive Warehouse Connector (HWC) non è supportata per l'uso con R. Per eseguire carichi di lavoro HWC, è possibile eseguire query da Spark a Hive usando l'API HiveWarehouseSession di tipo JDBC che supporta solo Scala, Java e Python.
- L'esecuzione di query (sia di lettura che di scrittura) tramite HiveServer2 tramite la modalità JDBC non è supportata per tipi di dati complessi come Arrays/Struct/Map.
- HWC supporta la scrittura solo in formati di file ORC. Le scritture non ORC (ad esempio: formati di file parquet e di testo) non sono supportate tramite HWC.
Hive Warehouse Connector richiede cluster distinti per i carichi di lavoro di Spark e Interactive Query. Eseguire le procedure seguenti per configurare questi cluster in Azure HDInsight.
Tipi e versioni di cluster supportati
| Versione HWC | Versione Spark | Versione di InteractiveQuery |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Interactive Query 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | Interactive Query 3.1 | HDI 5.0 |
Creare i cluster
Creare un cluster HDInsight Spark 4.0 con un account di archiviazione e una rete virtuale di Azure personalizzata. Per informazioni sulla creazione di un cluster in una rete virtuale di Azure, vedere Aggiungere HDInsight a una rete virtuale esistente.
Creare un cluster HDInsight Interactive Query (LLAP) 4.0 con lo stesso account di archiviazione e la stessa rete virtuale del cluster Spark.
Configurare le impostazioni di Hive Warehouse Connector
Raccogliere le informazioni preliminari
In un Web browser passare a
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVE, dove LLAPCLUSTERNAME è il nome del cluster Interactive Query.Passare a Summary>HiveServer2 Interactive JDBC URL (Riepilogo > URL JDBC interattivo per HiveServer2) e prendere nota del valore. Il valore può essere simile a:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.Passare a Configs>Advanced>Advanced hive-site>hive.zookeeper.quorum (Configurazioni > Avanzate > Impostazioni avanzate hive-site) e prendere nota del valore. Il valore può essere simile a:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.Passare a Configs>Advanced>General>hive.metastore.uris (Configurazioni > Avanzate > Generale) e prendere nota del valore. Il valore può essere simile a:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.Passare a Configs>Advanced>Advanced hive-interactive-site>hive.llap.daemon.service.hosts (Configurazioni > Avanzate > Impostazioni avanzate hive-interactive-site) e prendere nota del valore. Il valore può essere simile a:
@llap0.
Configurare le impostazioni del cluster Spark
In un Web browser passare a
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configs, dove CLUSTERNAME è il nome del cluster Apache Spark.Espandere Custom Spark2-defaults (Impostazioni predefinite Spark2 personalizzate).
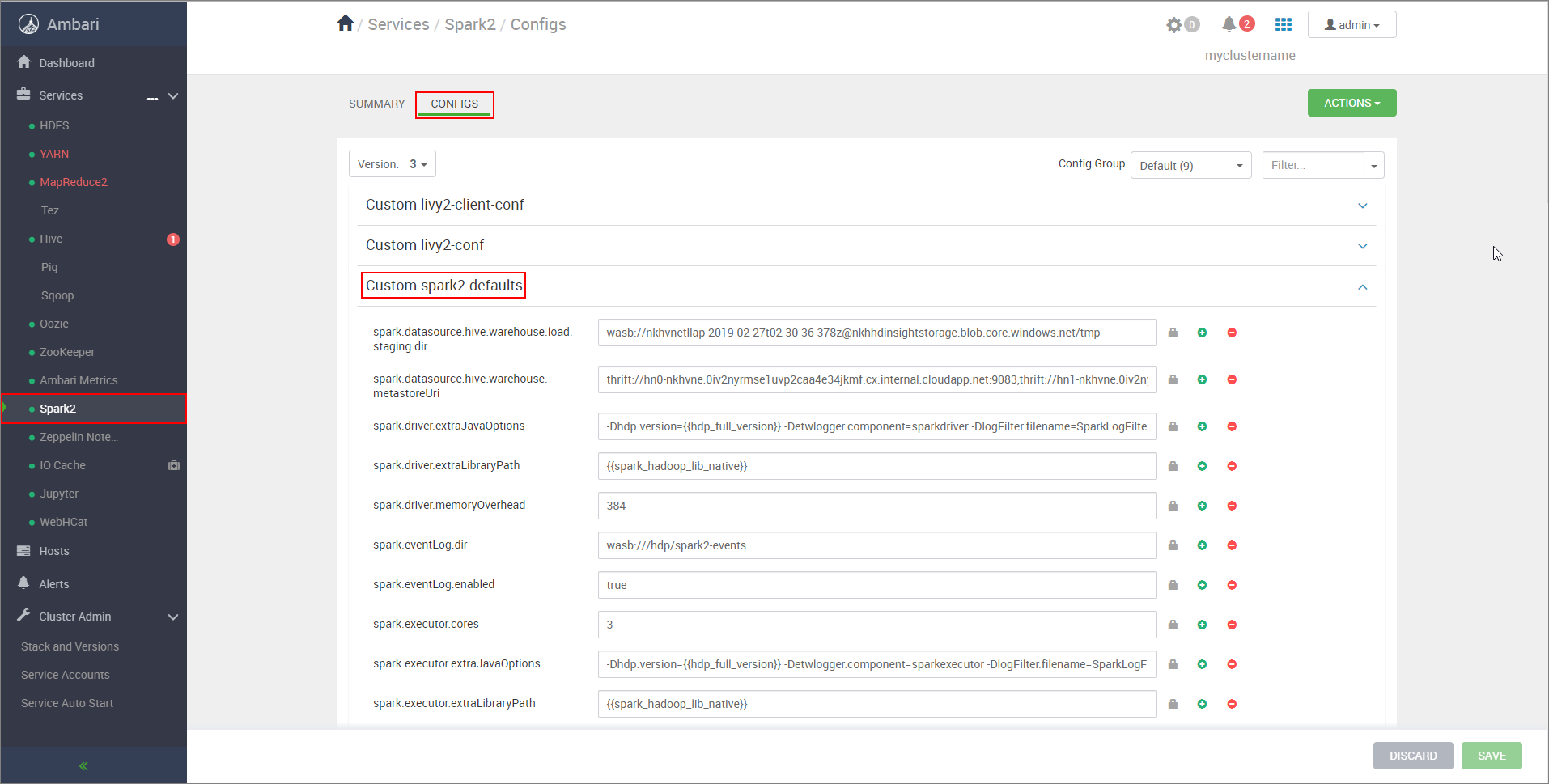
Selezionare Add Property (Aggiungi proprietà) per aggiungere le configurazioni seguenti:
Impostazione Valore spark.datasource.hive.warehouse.load.staging.dirSe si usa l'account di archiviazione di ADLS Gen2, usare abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
Se si usa Account di archiviazione BLOB di Azure, usarewasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp.
Impostare su una directory di gestione temporanea compatibile con HDFS appropriata. Se si hanno due cluster diversi, la directory di gestione temporanea deve essere una cartella nella directory di gestione temporanea dell'account di archiviazione del cluster LLAP in modo che HiveServer2 possa accedervi. SostituireSTORAGE_ACCOUNT_NAMEcon il nome dell'account di archiviazione usato dal cluster eSTORAGE_CONTAINER_NAMEcon il nome del contenitore di archiviazione.spark.sql.hive.hiveserver2.jdbc.urlValore ottenuto in precedenza da HiveServer2 Interactive JDBC URL spark.datasource.hive.warehouse.metastoreUriValore ottenuto in precedenza da hive.metastore.uris. spark.security.credentials.hiveserver2.enabledtrueper la modalità cluster YARN efalseper la modalità client YARN.spark.hadoop.hive.zookeeper.quorumValore ottenuto in precedenza da hive.zookeeper.quorum. spark.hadoop.hive.llap.daemon.service.hostsValore ottenuto in precedenza da hive.llap.daemon.service.hosts. Salvare le modifiche e riavviare tutti i componenti interessati.
Configurare Hive Warehouse Connector per i cluster con Enterprise Security Package (ESP)
Enterprise Security Package fornisce funzionalità di livello aziendale come l'autenticazione basata su Active Directory, il supporto multiutente e il controllo degli accessi in base al ruolo per i cluster Apache Hadoop in Azure HDInsight. Per altre informazioni su ESP, vedere Usare Enterprise Security Package in HDInsight.
Oltre alle configurazioni indicate nella sezione precedente, aggiungere la configurazione seguente per usare Hive Warehouse Connector nei cluster ESP.
Dall'interfaccia utente Web Ambari del cluster Spark passare a Spark2>CONFIGS>Custom spark2-defaults (Spark2 > Configurazioni > Impostazioni predefinite Spark2 personalizzate).
Aggiornare la proprietà seguente.
Impostazione Valore spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>In un Web browser passare a
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary, dove CLUSTERNAME è il nome del cluster Interactive Query. Fare clic su Interfaccia di HiveServer2. Verrà visualizzato il nome di dominio completo (FQDN) del nodo head in cui è in esecuzione LLAP, come illustrato nello screenshot. Sostituire<llap-headnode>con questo valore.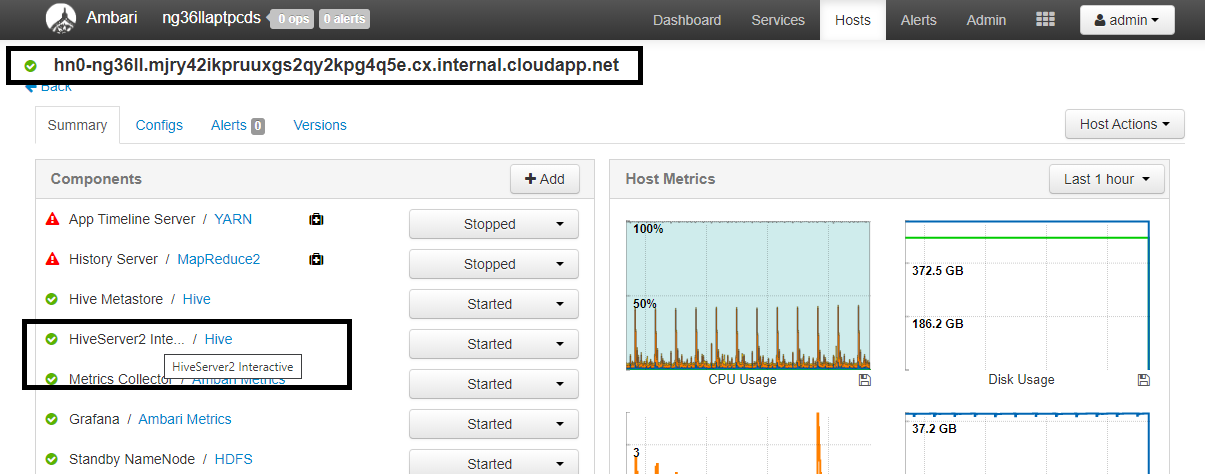
Usare il comando ssh per connettersi al cluster Interactive Query. Cercare il parametro
default_realmnel file/etc/krb5.conf. Sostituire<AAD-DOMAIN>con questo valore come una stringa in maiuscolo, altrimenti non sarà possibile trovare le credenziali.
Ad esempio,
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
Salvare le modifiche e riavviare i componenti interessati.
Utilizzo di Hive Warehouse Connector
È possibile scegliere tra alcuni metodi per connettersi al cluster Interactive Query ed eseguire query con Hive Warehouse Connector. I metodi supportati includono gli strumenti seguenti:
Ecco alcuni esempi di connessione a Hive Warehouse Connector da Spark.
Spark-shell
Si tratta di un modo per eseguire Spark in modo interattivo tramite una versione modificata della shell Scala.
Usare il comando ssh per connettersi al cluster Apache Spark. Modificare il comando seguente sostituendo CLUSTERNAME con il nome del cluster in uso e quindi immettere il comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netNella sessione ssh eseguire il comando seguente per prendere nota della versione di
hive-warehouse-connector-assembly:ls /usr/hdp/current/hive_warehouse_connectorModificare il codice seguente con la versione di
hive-warehouse-connector-assemblyidentificata in precedenza. Eseguire quindi il comando per avviare la shell Spark:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseDopo l'avvio della shell Spark, è possibile avviare un'istanza di Hive Warehouse Connector usando i comandi seguenti:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
Spark-submit è un'utilità per inviare qualsiasi programma (o processo) Spark ai cluster Spark.
Il processo spark-submit imposterà e configurerà Spark e Hive Warehouse Connector in base alle istruzioni fornite, eseguirà il programma a esso passato, quindi rilascerà ordinatamente le risorse usate.
Dopo aver compilato il codice Scala/Java insieme alle dipendenze in un file JAR di assembly, usare il comando seguente per avviare un'applicazione Spark. Sostituire <VERSION> e <APP_JAR_PATH> con i valori effettivi.
Modalità client YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarModalità cluster YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
Questa utilità viene usata anche quando l'intera applicazione è stata scritta in pySpark e inserita in pacchetti in file .py (Python), in modo da poter inviare l'intero codice al cluster Spark per l'esecuzione.
Per le applicazioni Python, passare un file .py al posto di /<APP_JAR_PATH>/myHwcAppProject.jare aggiungere il file di configurazione (Python .zip) seguente al percorso di ricerca con --py-files.
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Eseguire query nei cluster con Enterprise Security Package (ESP)
Usare kinit prima di avviare il comando spark-shell o spark-submit. Sostituire USERNAME con il nome di un account di dominio con autorizzazioni di accesso al cluster, quindi eseguire il comando seguente:
kinit USERNAME
Protezione dei dati nei cluster ESP Spark
Creare una tabella
democon alcuni dati di esempio immettendo i comandi seguenti:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');Visualizzare il contenuto della tabella con il comando seguente. Prima dell'applicazione del criterio, nella tabella
demoviene visualizzata la colonna completa.hive.executeQuery("SELECT * FROM demo").show()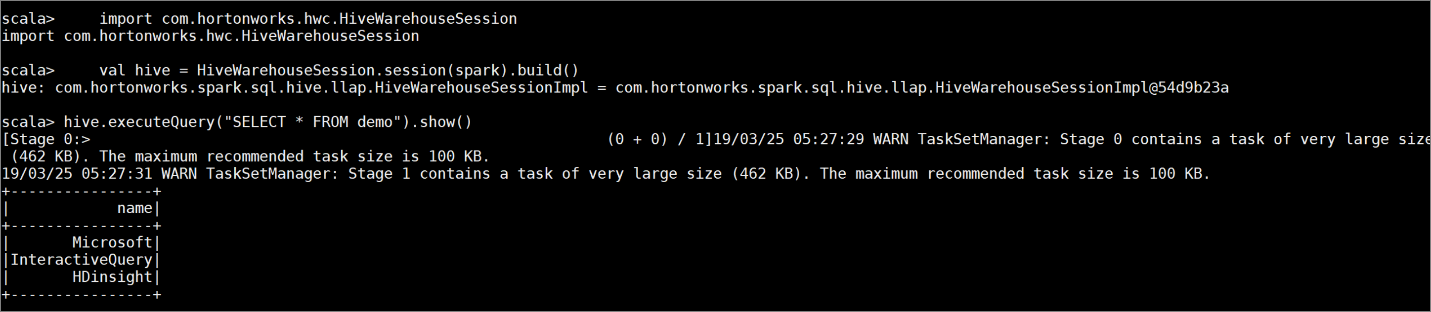
Applicare un criterio di mascheramento colonna che mostra solo gli ultimi quattro caratteri della colonna.
Passare all'interfaccia utente di amministrazione di Ranger all'indirizzo
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/.Fare clic sul servizio Hive del cluster in Hive.
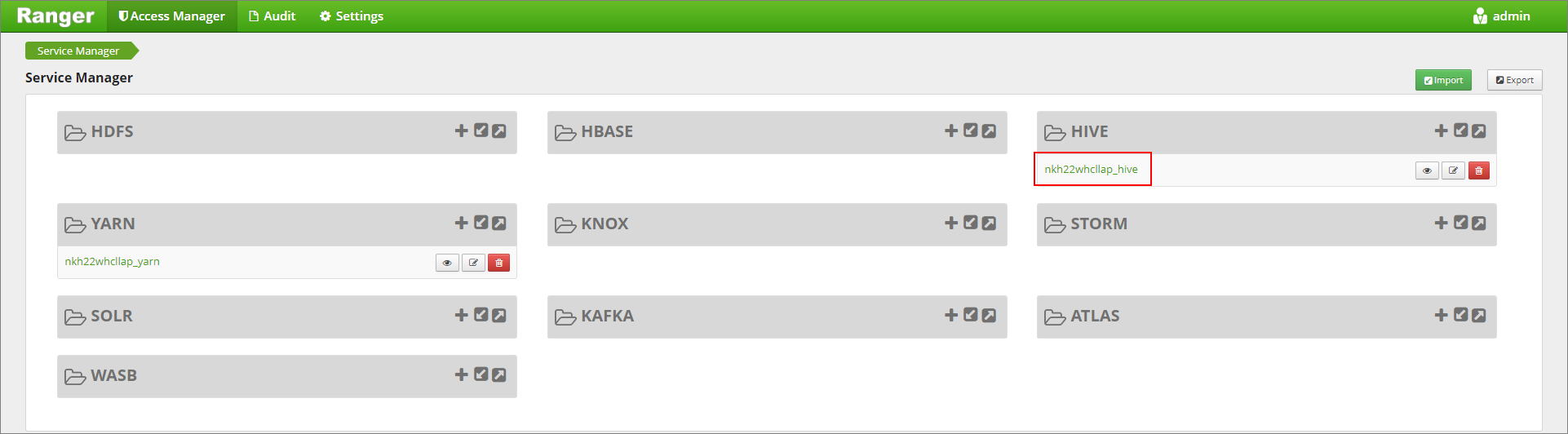
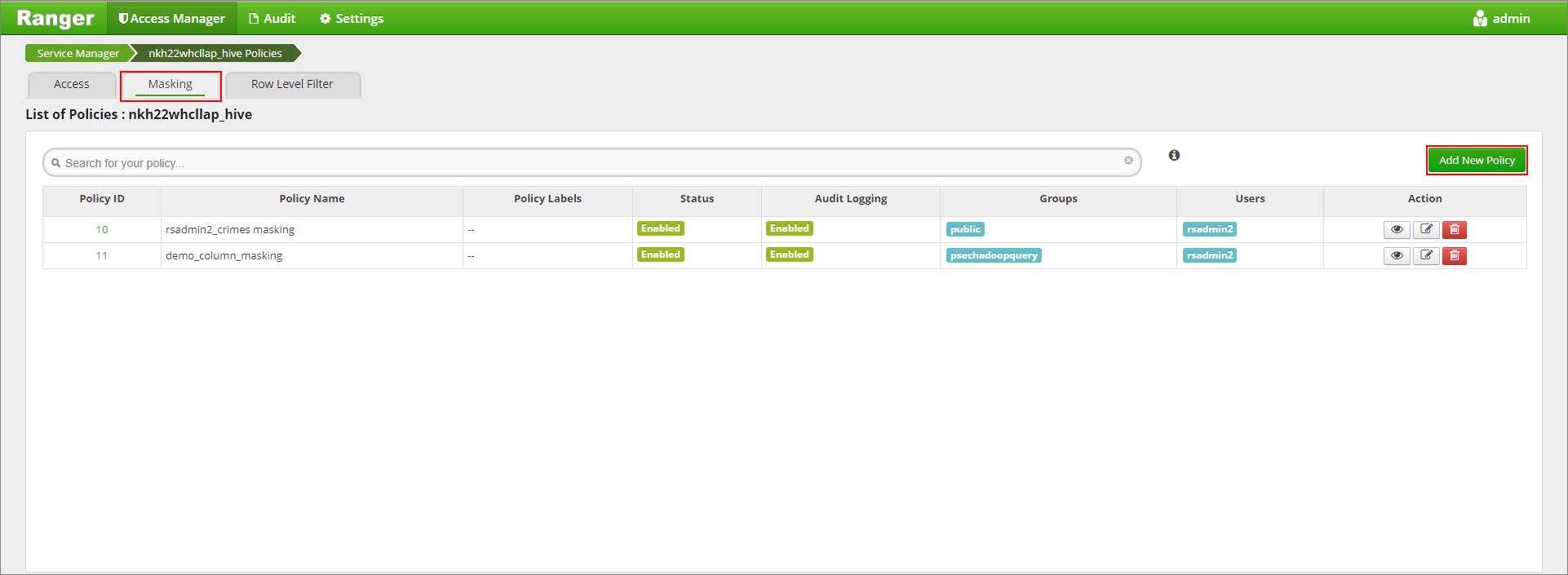
Fare clic sulla scheda Masking (Mascheramento) e quindi su Add New Policy (Aggiungi nuovo criterio)
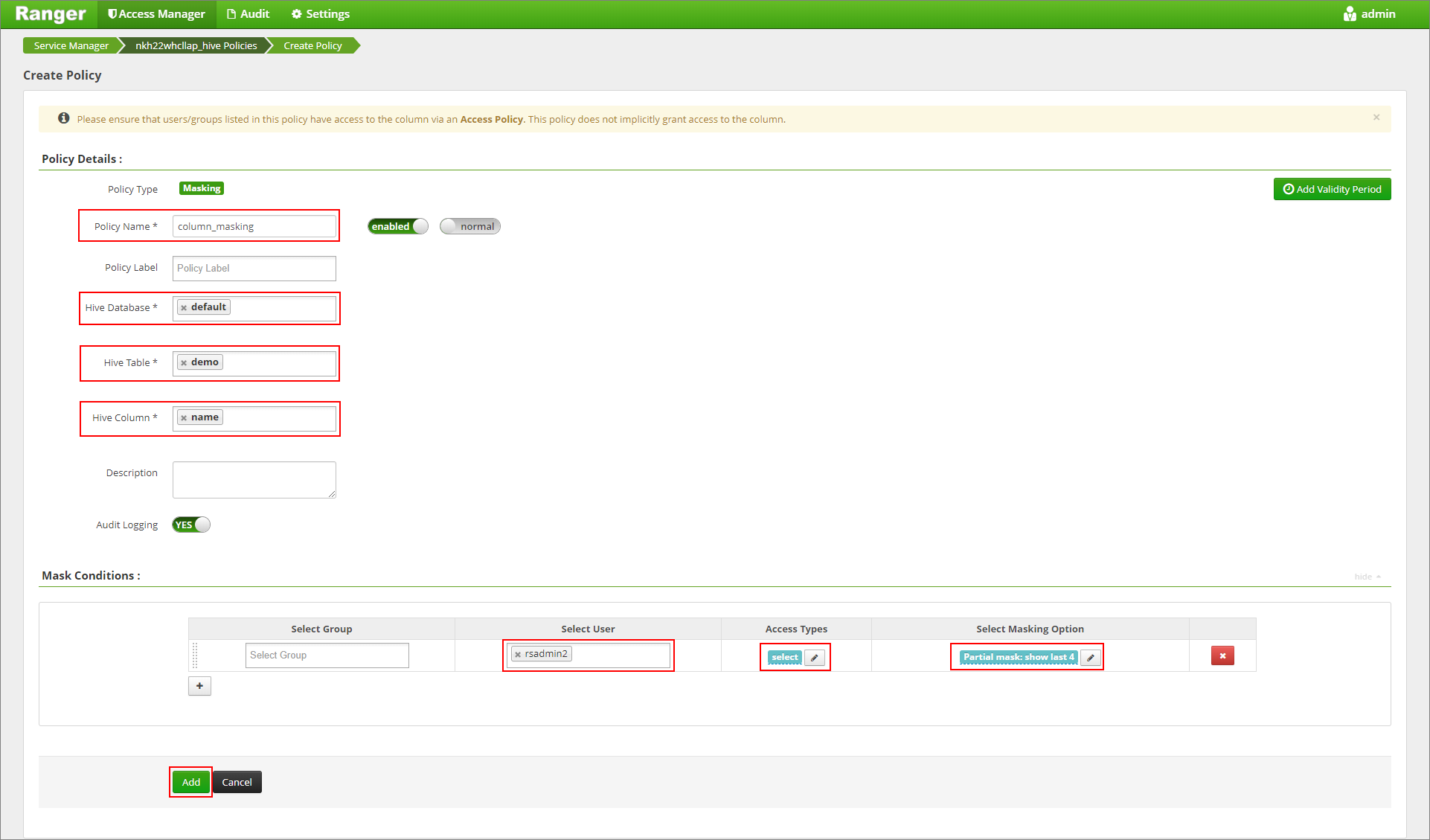
Specificare un nome per il criterio. Selezionare database: Impostazione predefinita, Tabella Hive: demo, Colonna Hive: nome, Utente: rsadmin2, Tipi di accesso: seleziona e Mascheramento parziale: mostra ultimi 4 nel menu Seleziona opzione di mascheramento. Fare clic su Aggiungi.
Visualizzare di nuovo il contenuto della tabella. Dopo l'applicazione del criterio Ranger, vengono visualizzati solo gli ultimi quattro caratteri della colonna.
