Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa guida di avvio rapido illustra come usare un modello di Azure Resource Manager per creare un cluster Apache Kafka in Azure HDInsight. Kafka è una piattaforma di streaming open source distribuita. Viene spesso usata come broker di messaggi perché offre funzionalità simili a una coda messaggi di pubblicazione/sottoscrizione.
Un modello di Azure Resource Manager è un file JSON (JavaScript Object Notation) che definisce l'infrastruttura e la configurazione del progetto. Il modello utilizza la sintassi dichiarativa. Si descrive la distribuzione prevista senza scrivere la sequenza di comandi di programmazione necessari per creare la distribuzione.
Possono accedere all'API Kafka solo risorse interne alla stessa rete virtuale. In questa guida di avvio rapido si accede al cluster direttamente usando SSH. Per connettere altri servizi, reti o macchine virtuali a Kafka, è necessario prima di tutto creare una rete virtuale e quindi creare le risorse all'interno della rete. Per altre informazioni, vedere il documento Connettersi ad Apache Kafka da una rete locale.
Se l'ambiente soddisfa i prerequisiti e si ha familiarità con l'uso dei modelli di Resource Manager, selezionare il pulsante Distribuisci in Azure. Il modello verrà aperto nel portale di Azure.

Prerequisiti
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Rivedere il modello
Il modello usato in questo avvio rapido proviene dai modelli di avvio rapido di Azure.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.26.54.24096",
"templateHash": "14433491779040889275"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the Kafka cluster to create. This must be a unique name."
}
},
"clusterLoginUserName": {
"type": "string",
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards."
}
},
"clusterLoginPassword": {
"type": "securestring",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"metadata": {
"description": "These credentials can be used to remotely access the cluster."
}
},
"sshPassword": {
"type": "securestring",
"minLength": 6,
"maxLength": 72,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"HeadNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E4_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"WorkerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E4_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the worerdnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"ZookeeperNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E4_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the Zookeepernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"variables": {
"defaultStorageAccount": {
"name": "[uniqueString(resourceGroup().id)]",
"type": "Standard_LRS"
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2023-01-01",
"name": "[variables('defaultStorageAccount').name]",
"location": "[parameters('location')]",
"sku": {
"name": "[variables('defaultStorageAccount').type]"
},
"kind": "StorageV2",
"properties": {
"minimumTlsVersion": "TLS1_2",
"supportsHttpsTrafficOnly": true,
"allowBlobPublicAccess": false
}
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2023-08-15-preview",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"clusterDefinition": {
"kind": "kafka",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(concat(reference(resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name), '2021-08-01').primaryEndpoints.blob), 'https:', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('HeadNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 4,
"hardwareProfile": {
"vmSize": "[parameters('WorkerNodeVirtualMachineSize')]"
},
"dataDisksGroups": [
{
"disksPerNode": 2
}
],
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "zookeepernode",
"targetInstanceCount": 3,
"hardwareProfile": {
"vmSize": "[parameters('ZookeeperNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name)]"
]
}
],
"outputs": {
"name": {
"type": "string",
"value": "[parameters('clusterName')]"
},
"resourceId": {
"type": "string",
"value": "[resourceId('Microsoft.HDInsight/clusters', parameters('clusterName'))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')), '2023-08-15-preview')]"
},
"resourceGroupName": {
"type": "string",
"value": "[resourceGroup().name]"
},
"location": {
"type": "string",
"value": "[parameters('location')]"
}
}
}
Nel modello sono definite due risorse di Azure:
- Microsoft.Storage/storageAccounts per creare un account di archiviazione di Azure.
- Microsoft.HDInsight/cluster: creare un cluster HDInsight.
Distribuire il modello
Selezionare il pulsante Distribuisci in Azure sotto per accedere ad Azure e aprire il modello di Resource Manager.
Immettere o selezionare i valori seguenti:
Proprietà Descrizione Subscription Nell'elenco a discesa selezionare la sottoscrizione di Azure che viene usata per il cluster. Gruppo di risorse Nell'elenco a discesa selezionare il gruppo di risorse esistente oppure selezionare Crea nuovo. Ufficio Come valore verrà inserita automaticamente la località usata per il gruppo di risorse. Nome del cluster Immettere un nome globalmente univoco. Per questo modello usare solo lettere minuscole e numeri. Nome utente dell'account di accesso del cluster Specificare il nome utente. Il valore predefinito è admin.Password di accesso al cluster Specificare una password. La password deve avere una lunghezza minima di 10 caratteri e contenere almeno una cifra, una lettera maiuscola, una lettera minuscola e un carattere non alfanumerico (ad eccezione di ' ` ").Nome utente SSH Specificare il nome utente. Il valore predefinito è sshuser.Password SSH Specificare la password. 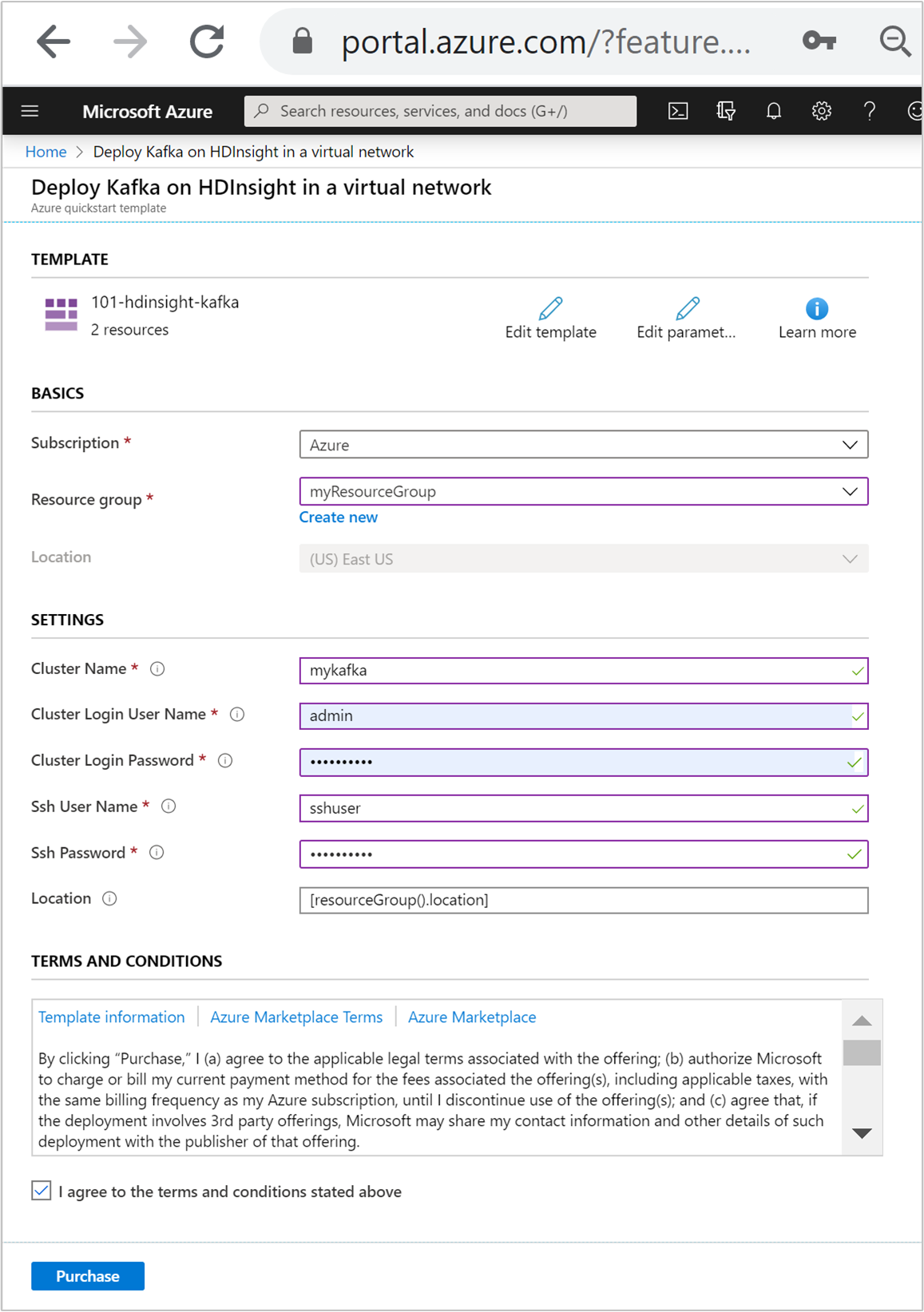
Leggere quanto riportato in CONDIZIONI. Selezionare quindi Accetto le condizioni riportate sopra e infine Acquista. Si riceverà una notifica che informa che la distribuzione è in corso. La creazione di un cluster richiede circa 20 minuti.
Esaminare le risorse distribuite
Al termine della creazione del cluster, si riceverà una notifica con il messaggio La distribuzione è riuscita e un collegamento Vai alla risorsa. Nella pagina del gruppo di risorse saranno presenti il nuovo cluster HDInsight e l'account di archiviazione predefinito associato. Ogni cluster ha una dipendenza dall'account di Archiviazione BLOB di Azure o da Azure Data Lake Storage Gen2. Viene indicato come account di archiviazione predefinito. Il cluster HDInsight e il relativo account di archiviazione predefinito devono avere un percorso condiviso nella stessa area di Azure. L'eliminazione dei cluster non comporta l'eliminazione dell'account di archiviazione.
Ottenere le informazioni sugli host Apache Zookeeper e broker
Quando si usa Kafka, è necessario conoscere gli host Apache Zookeeper e broker. Questi host vengono usati con l'API Kafka e molte delle utilità offerte con Kafka.
In questa sezione si ottengono le informazioni sull'host dall'API REST Ambari nel cluster.
Usare il comando ssh per connettersi al cluster. Modificare il comando seguente sostituendo CLUSTERNAME con il nome del cluster in uso e quindi immettere il comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netDalla connessione SSH usare il comando seguente per installare l'utilità
jq. Questa utilità consente di analizzare i documenti JSON ed è utile nel recupero delle informazioni sull'host:sudo apt -y install jqPer impostare una variabile di ambiente sul nome del cluster, usare il comando seguente:
read -p "Enter the Kafka on HDInsight cluster name: " CLUSTERNAMEAl prompt immettere il nome del cluster Kafka.
Per impostare una variabile di ambiente con le informazioni degli host Zookeeper, usare il comando seguente. Il comando recupera tutti gli host Zookeeper, quindi restituisce solo le prime due voci. per mantenere un certo livello di ridondanza nel caso in cui un host fosse irraggiungibile.
export KAFKAZKHOSTS=`curl -sS -u admin -G https://$CLUSTERNAME.azurehdinsight.net/api/v1/clusters/$CLUSTERNAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2`Al prompt immettere la password dell'account di accesso al cluster (non l'account SSH).
Usare il comando seguente per verificare che la variabile di ambiente sia impostata correttamente:
echo '$KAFKAZKHOSTS='$KAFKAZKHOSTSQuesto comando restituisce informazioni simili al testo seguente:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Per impostare una variabile di ambiente con le informazioni degli host broker, usare il comando seguente:
export KAFKABROKERS=`curl -sS -u admin -G https://$CLUSTERNAME.azurehdinsight.net/api/v1/clusters/$CLUSTERNAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2`Al prompt immettere la password dell'account di accesso al cluster (non l'account SSH).
Usare il comando seguente per verificare che la variabile di ambiente sia impostata correttamente:
echo '$KAFKABROKERS='$KAFKABROKERSQuesto comando restituisce informazioni simili al testo seguente:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Gestire gli argomenti di Apache Kafka
Kafka archivia i flussi di dati in argomenti. Per gestire gli argomenti è possibile usare l'utilità kafka-topics.sh.
Per creare un argomento usare il comando seguente nella connessione SSH:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --zookeeper $KAFKAZKHOSTSQuesto comando si connette a Zookeeper usando le informazioni sull'host archiviate in
$KAFKAZKHOSTSe quindi crea un argomento Kafka denominato test.I dati archiviati in questo argomento vengono divisi in otto partizioni.
Ogni partizione è replicata in tre nodi di ruolo di lavoro nel cluster.
Se il cluster è stato creato in un'area di Azure con tre domini di errore, usare il fattore di replica 3. In caso contrario usare il fattore di replica 4.
Nelle aree con tre domini di errore, il fattore di replica 3 consente di distribuire le repliche tra i domini di errore. Nelle aree con due domini di errore, il fattore di replica 4 distribuisce le repliche uniformemente tra i domini.
Per informazioni sul numero di domini di errore in un'area, vedere il documento Disponibilità delle macchine virtuali Linux.
Kafka non rileva i domini di errore di Azure. Quando si creano le repliche di partizione per gli argomenti, è possibile che le repliche non vengano distribuite in modo corretto per la disponibilità elevata.
Per garantire la disponibilità elevata, usare lo strumento per il ribilanciamento delle partizioni Apache Kafka. Questo strumento deve essere eseguito da una sessione SSH al nodo head del cluster Kafka.
Per garantire la massima disponibilità dei dati Kafka, è consigliabile ribilanciare le repliche di partizione per l'argomento nelle situazioni seguenti:
Quando si crea un nuovo argomento o una nuova partizione
Quando si aumentano le prestazioni di un cluster
Per elencare gli argomenti usare il comando seguente:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $KAFKAZKHOSTSQuesto comando elenca gli argomenti disponibili nel cluster Kafka.
Per eliminare un argomento usare il comando seguente:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --zookeeper $KAFKAZKHOSTSQuesto comando elimina l'argomento denominato
topicname.Avviso
Se si elimina l'argomento
testcreato in precedenza, è necessario crearlo di nuovo. Questo argomento si userà in passaggi indicati più avanti in questo documento.
Per altre informazioni sui comandi disponibili con l'utilità kafka-topics.sh, usare il comando seguente:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Produrre e utilizzare record
Kafka archivia i record in argomenti. I record vengono prodotti da producer e usati da consumer. I producer e i consumer comunicano con il servizio broker Kafka. Ogni nodo del ruolo di lavoro nel cluster HDInsight è un host del broker Kafka.
Seguire questa procedura per archiviare i record nell'argomento test creato in precedenza e quindi leggerli usando un consumer:
Per scrivere i record nell'argomento usare l'utilità
kafka-console-producer.shdalla connessione SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testDopo questo comando viene visualizzata una riga vuota.
Digitare un messaggio di testo nella riga vuota e premere INVIO. Digitare invece alcuni messaggi in questo modo e quindi usare Ctrl + C per tornare al prompt normale. Ogni riga viene inviata come record distinto all'argomento Kafka.
Per scrivere i record dall'argomento usare l'utilità
kafka-console-consumer.shdalla connessione SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningQuesto comando recupera i record dall'argomento e li visualizza. L'uso di
--from-beginningindica al consumer di partire dall'inizio del flusso, quindi verranno recuperati tutti i record.Se si usa una versione meno recente di Kafka, sostituire
--bootstrap-server $KAFKABROKERScon--zookeeper $KAFKAZKHOSTS.Usare Ctrl + C per arrestare il consumer.
È possibile creare producer e consumer anche a livello di codice. Per un esempio dell'uso di questa API, vedere il documento relativo alle API Producer e Consumer Apache Kafka con HDInsight.
Pulire le risorse
Al termine dell'argomento di avvio rapido, può essere opportuno eliminare il cluster. Con HDInsight, i dati vengono archiviati in Archiviazione di Azure ed è possibile eliminare tranquillamente un cluster quando non è in uso. Vengono addebitati i costi anche per i cluster HDInsight che non sono in uso. Poiché i costi per il cluster sono decisamente superiori a quelli per l'archiviazione, eliminare i cluster quando non vengono usati è una scelta economicamente conveniente.
Nel portale di Azure passare al cluster e selezionare Elimina.
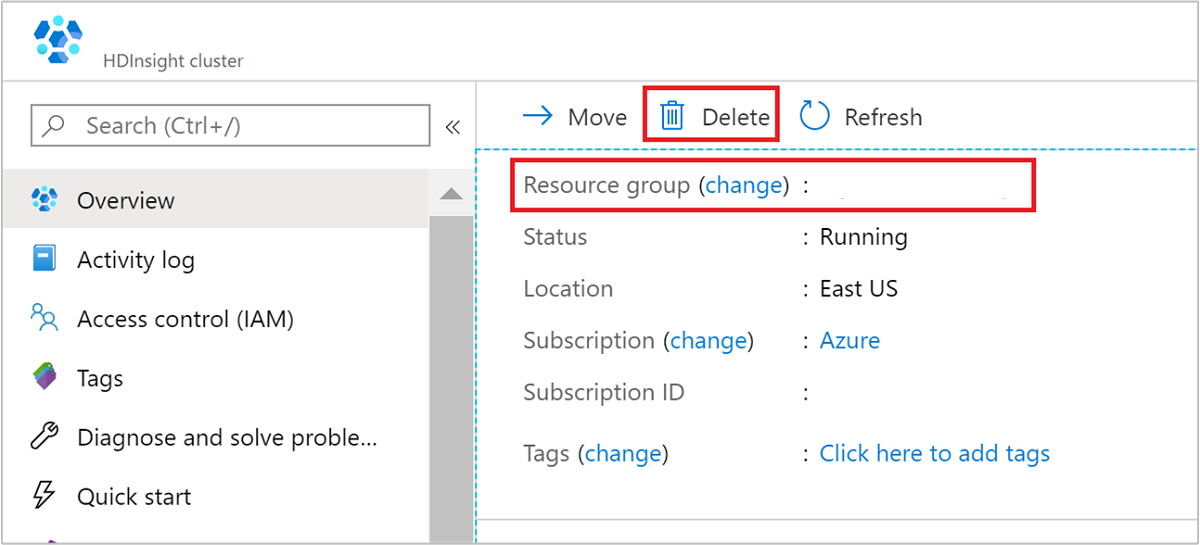
È anche possibile selezionare il nome del gruppo di risorse per aprire la pagina del gruppo di risorse e quindi selezionare Elimina gruppo di risorse. Eliminando il gruppo di risorse, si elimina sia il cluster HDInsight che l'account di archiviazione predefinito.
Passaggi successivi
In questa guida di avvio rapido è stato creato un cluster Apache Kafka in HDInsight tramite un modello di Resource Manager. L'articolo successivo illustra come creare un'applicazione che usa l'API Apache Kafka Streams ed eseguirla con Kafka in HDInsight.