Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Apache Spark Streaming consente di implementare applicazioni scalabili, con velocità effettiva elevata e a tolleranza di errore per l'elaborazione di flussi di dati. È possibile connettere applicazioni Spark Streaming in un cluster HDInsight Spark a vari tipi di origini dati, ad esempio Hub eventi di Azure, Azure IoT Hub, Apache Kafka, Apache Flume, Twitter, ZeroMQ, socket TCP non elaborati o monitorando il file system Apache Hadoop HDFS per le modifiche. Spark Streaming supporta la tolleranza di errore con la garanzia che un determinato evento venga elaborato una sola volta, anche in caso di errore di un nodo.
Spark Streaming crea processi con esecuzione prolungata durante i quali è possibile applicare trasformazioni ai dati e quindi esegue il push dei risultati in file system, database, dashboard e nella console. Spark Streaming elabora micro-batch di dati, raccogliendo prima un batch di eventi per un intervallo di tempo definito. Tale batch viene poi fatto proseguire per l'elaborazione e l'output. Gli intervalli di tempo dei batch sono in genere definiti in frazioni di secondo.

DStream
Spark Streaming rappresenta un flusso continuo di dati con un flusso discretizzato (DStream). È possibile creare questo flusso DStream da origini di input come Hub eventi o Kafka oppure applicando trasformazioni a un altro flusso DStream. Quando questo evento arriva all'applicazione Spark Streaming, l'evento viene archiviato in modo affidabile. Ovvero, i dati dell'evento vengono replicati in modo che più nodi ne abbiano una copia. Ciò garantisce che l'errore di un singolo nodo non comporti la perdita dell'evento.
Il core di Spark usa set di dati distribuiti resilienti (RDD, Resilient Distributed Dataset). I set RDD distribuiscono i dati tra più nodi nel cluster, in cui ogni nodo mantiene in genere i propri dati completamente in memoria per garantire prestazioni ottimali. Ogni RDD rappresenta gli eventi raccolti in un intervallo di batch. Quando è trascorso l'intervallo di batch, Spark Streaming produce un nuovo RDD contenente tutti i dati in tale intervallo. Questo set continuo di RDD viene raccolto in un flusso DStream. Un'applicazione Spark Streaming elabora i dati archiviati nel set RDD di ogni batch.

Processi di Spark Structured Streaming
Spark Structured Streaming è stato introdotto in Spark 2.0 come motore di analisi per l'uso con dati strutturati di flusso. Spark Structured Streaming usa le API del motore di invio in batch di SparkSQL. Come Spark Streaming, Spark Structured Streaming esegue i calcoli su micro-batch di dati in arrivo in modo continuo. Spark Structured Streaming rappresenta un flusso di dati come tabella di input con righe illimitate. Questo significa che la tabella di input continua a crescere con l'arrivo di nuovi dati. La tabella di input viene elaborata in modo continuo tramite una query con esecuzione prolungata e i risultati vengono scritti in una tabella di output.
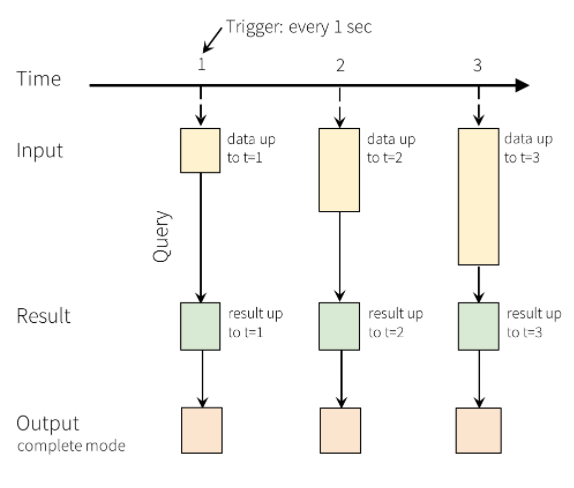
Con Structured Streaming, i dai raggiungono il sistema e vengono acquisiti immediatamente nella tabella di Input. È quindi necessario scrivere query che eseguono operazioni su questa tabella di Input. L'output della query produce un'altra tabella, denominata tabella dei risultati. La tabella dei risultati contiene i risultati della query, da cui è possibile ricavare i dati da inviare a un archivio di dati esterno, come un database relazionale. L'intervallo di trigger definisce la tempistica per l'elaborazione dei dati dalla tabella di Input. Per impostazione predefinita,Structured Streaming elabora i dati non appena arrivano. Tuttavia, è anche possibile configurare il trigger per l'esecuzione con intervalli più lunghi, in modo che i dati del flusso vengono elaborati in batch basati sul tempo. I dati nella tabella dei risultati possono essere aggiornati ogni volta che arrivano nuovi dati, per cui includono tutti i dati di output dall'inizio della query di streaming (modalità completa), oppure possono contenere solo i dati introdotti dopo l'ultima elaborazione della query (modalità accodamento).
Creare processi di Spark Streaming a tolleranza di errore
Per creare un ambiente a disponibilità elevata per i processi Spark Streaming, iniziare codificando i singoli processi per il ripristino in caso di errore. Questi processi con ripristino automatico sono a tolleranza di errore.
Gli RDD offrono varie proprietà utili per i processi Spark Streaming a disponibilità elevata e a tolleranza di errore:
- I batch di dati di input archiviati in set RDD come DStream vengono replicati automaticamente in memoria per la tolleranza di errore.
- I dati perduti a causa di un errore del nodo di lavoro possono essere ricalcolati dai dati di input replicati in nodi di lavoro diversi, a condizione che siano disponibili.
- Il recupero rapido da errori può essere completato entro un secondo, perché il recupero da errori/ritardi avviene tramite calcolo in memoria.
Semantica exactly-once con Spark Streaming
Per creare un'applicazione che elabora ogni evento una sola volta, valutare la modalità di riavvio per tutti i punti di errore del sistema e come è possibile evitare perdite di dati. La semantica exactly-once richiede che non si verifichi alcuna perdita di dati in alcun punto e che l'elaborazione dei messaggi sia riavviabile, indipendentemente da dove si verifica l'errore. Vedere Creare processi Spark Streaming con elaborazione di eventi di tipo exactly-once.
Spark Streaming e Apache Hadoop YARN
In HDInsight, il lavoro del cluster è coordinato da Yet Another Resource Negotiator (YARN). La progettazione della disponibilità elevata per Spark Streaming include tecniche per Spark Streaming e anche per i componenti YARN. Di seguito è illustrata una configurazione di esempio con YARN.
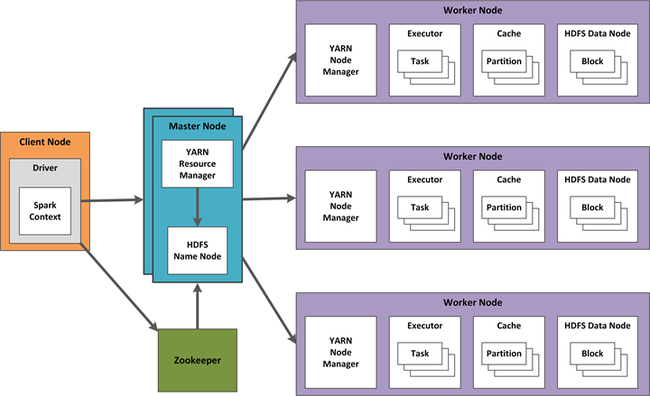
Nelle sezioni seguenti vengono descritte alcune considerazioni sulla progettazione di questa configurazione.
Piano per gli errori
Per creare una configurazione di YARN per la disponibilità elevata, è necessario definire un piano per affrontare possibili errori di executor o driver. Alcuni processi di Spark Streaming prevedono anche requisiti di garanzia per i dati che richiedono interventi di installazione e configurazione aggiuntivi. Ad esempio, un'applicazione per l'uso dei flussi potrebbe avere un requisito aziendale di garanzia della totale assenza di perdita di dati, indipendentemente dagli eventuali errori che possono verificarsi nel sistema di streaming host o nel cluster HDInsight.
In caso di errore di un executor, le relative attività e ricevitori vengono riavviati automaticamente da Spark, pertanto non è necessaria alcuna modifica della configurazione.
Tuttavia, se l'errore si verifica per un driver, anche tutti gli executor associati saranno in errore con conseguente perdita di tutti i blocchi e i risultati di calcolo ricevuti. Per eseguire il ripristino da un errore di driver, usare checkpoint DStream come descritto in Creare processi Spark Streaming con elaborazione di eventi exactly-once. La creazione di checkpoint DStream salva periodicamente il grafico aciclico diretto di DStream in una risorsa di archiviazione a tolleranza di errore, come Archiviazione di Azure. La creazione di checkpoint consente a Spark Structured Streaming di riavviare il driver in errore dalle informazioni di checkpoint. Questo riavvio del driver avvia nuovi esecutori e riavvia anche i ricevitori.
Per eseguire il ripristino dei driver con checkpoint DStream:
Configurare il riavvio automatico del driver su YARN con l'impostazione di configurazione
yarn.resourcemanager.am.max-attempts.Impostare una directory di checkpoint in un file system compatibile con HDFS con
streamingContext.checkpoint(hdfsDirectory).Ristrutturare il codice sorgente per l'uso di checkpoint per il ripristino, ad esempio:
def creatingFunc() : StreamingContext = { val context = new StreamingContext(...) val lines = KafkaUtils.createStream(...) val words = lines.flatMap(...) ... context.checkpoint(hdfsDir) } val context = StreamingContext.getOrCreate(hdfsDir, creatingFunc) context.start()Configurare il ripristino dei dati persi abilitando il log write-ahead (WAL) con
sparkConf.set("spark.streaming.receiver.writeAheadLog.enable","true")e disabilitare la replica in memoria per i flussi DStream di input conStorageLevel.MEMORY_AND_DISK_SER.
Per riepilogare, l'uso di checkpoint, WAL e ricevitori affidabili consentirà di fornire il ripristino dei dati "at-least-once":
- Exactly-once, purché i dati ricevuti non vadano persi e gli output siano idempotenti o transazionali.
- Exactly-once, con il nuovo approccio Kafka Direct che usa Kafka come log replicato invece di usare ricevitori o WAL.
Problematiche tipiche per la disponibilità elevata
È più difficile monitorare i processi di streaming rispetto ai processi batch. I processi di Spark Streaming hanno in genere un'esecuzione prolungata e YARN non aggrega i log fino al completamento di un processo. I checkpoint Spark vanno perduti durante gli aggiornamenti di applicazioni e Spark e sarà necessario cancellare la directory dei checkpoint durante l'aggiornamento.
Configurare la modalità del cluster YARN per l'esecuzione dei driver anche in caso di errore di un client. Per configurare il riavvio automatico per i driver:
spark.yarn.maxAppAttempts = 2 spark.yarn.am.attemptFailuresValidityInterval=1hL'interfaccia utente di Spark e Spark Streaming include un sistema di metriche configurabile. È anche possibile usare librerie aggiuntive come Graphite/Grafana per scaricare metriche del dashboard come 'numero di record elaborati', 'utilizzo memoria/GC in driver ed executor', 'ritardo totale', 'utilizzo del cluster' e così via. In Structured Streaming versione 2.1 o successiva, è possibile usare
StreamingQueryListenerper raccogliere metriche aggiuntive.È consigliabile segmentare i processi con esecuzione prolungata. Quando un'applicazione Spark Streaming viene inviata al cluster, è necessario definire la coda YARN in cui viene eseguito il processo. È possibile usare un'utilità di pianificazione della capacità YARN per inviare i processi con esecuzione prolungata a code separate.
Arrestare l'applicazione per l'uso dei flussi normalmente. Se gli offset sono noti e tutto lo stato dell'applicazione è archiviato esternamente, è possibile arrestare l'applicazione per l'uso dei flussi a livello di programmazione nella posizione appropriata. Una tecnica consiste nell'usare "hook di thread" in Spark, controllando la presenza di un flag esterno ogni n secondi. È anche possibile usare un file marcatore che viene creato in HDFS all'avvio dell'applicazione e poi rimosso quando si vuole arrestarla. Per l'approccio con file marcatore, usare un thread separato nell'applicazione Spark che chiama codice simile al seguente:
streamingContext.stop(stopSparkContext = true, stopGracefully = true) // to be able to recover on restart, store all offsets in an external database
Passaggi successivi
- Panoramica di Apache Spark Streaming
- Creare processi Apache Spark Streaming con elaborazione di eventi exactly-once
- Long-running Apache Spark Streaming Jobs on YARN (Processi di Apache Spark Streaming con esecuzione prolungata in YARN)
- Structured Streaming: Fault Tolerant Semantics (Flusso strutturato: semantica con tolleranza di errore)
- Discretized Streams: A Fault-Tolerant Model for Scalable Stream Processing (Flussi discretizzati: un modello a tolleranza di errore per l'elaborazione di flussi scalabile)