Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
I cluster HDInsight Spark includono notebook Apache Zeppelin . Usare i notebook per eseguire processi Apache Spark. Questo articolo illustra come usare il notebook Zeppelin in un cluster HDInsight.
Prerequisiti
- Un cluster Apache Spark in HDInsight. Per istruzioni, vedere l'articolo dedicato alla creazione di cluster Apache Spark in Azure HDInsight.
- Lo schema URI per l'archiviazione primaria dei cluster. Lo schema è
wasb://per Archiviazione BLOB di Azure,abfs://per Azure Data Lake Storage Gen2 oadl://per Azure Data Lake Storage Gen1. Se il trasferimento sicuro è abilitato per l'archiviazione BLOB, l'URI saràwasbs://. Per altre informazioni, vedere Richiedere il trasferimento sicuro in Archiviazione di Azure.
Avviare un notebook di Apache Zeppelin
Nella panoramica del cluster Spark selezionare Notebook Zeppelin nei dashboard del cluster. Immettere le credenziali di amministratore per il cluster.
Nota
È anche possibile raggiungere il notebook di Zeppelin per il cluster aprendo l'URL seguente nel browser. Sostituire CLUSTERNAME con il nome del cluster:
https://CLUSTERNAME.azurehdinsight.net/zeppelinCreare un nuovo notebook. Nel riquadro dell'intestazione passare a Notebook>Create new note (Crea nuova nota).
Immettere un nome per il notebook e quindi selezionare Crea nota.
Verificare che l'intestazione del notebook mostri uno stato connesso. È indicato da un punto verde nell'angolo superiore destro.
Caricare i dati di esempio in una tabella temporanea. Quando si crea un cluster Spark in HDInsight, il file di dati di esempio ,
hvac.csvviene copiato nell'account di archiviazione associato in\HdiSamples\SensorSampleData\hvac.Nel paragrafo vuoto creato per impostazione predefinita del nuovo notebook, incollare il frammento di codice riportato di seguito.
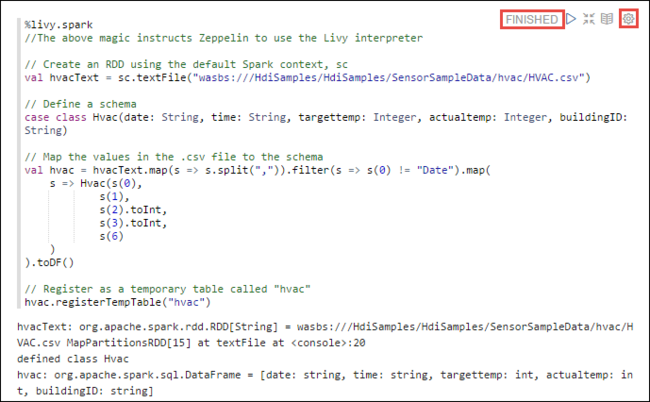
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Premere MAIUSC + INVIO o selezionare il pulsante Riproduci per il paragrafo per eseguire il frammento di codice. Lo stato nell'angolo destro del paragrafo deve passare da PRONTO, IN ATTESA, IN ESECUZIONE, a COMPLETATO. L'output viene visualizzato nella parte inferiore dello stesso paragrafo. Lo screenshot è simile all'immagine seguente:
È inoltre possibile fornire un titolo a ogni paragrafo. Nell'angolo destro del paragrafo selezionare l'icona Impostazioni (sprocket) e quindi selezionare Mostra titolo.
Nota
L'interprete %spark2 non è supportato nei notebook Zeppelin in tutte le versioni di HDInsight e %sh interprete non supportato da HDInsight 4.0 in poi.
È ora possibile eseguire istruzioni SPARK SQL nella
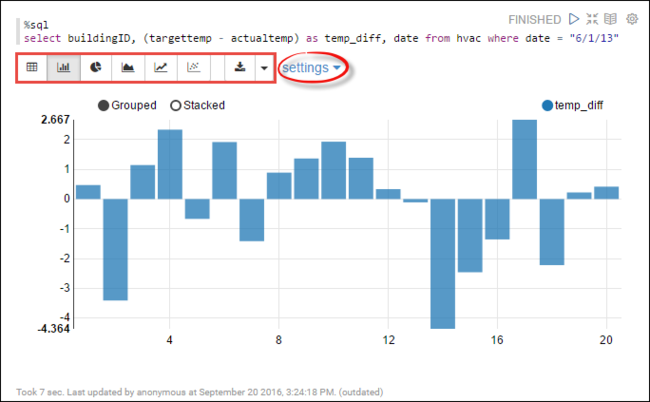
hvactabella. Incollare la query seguente in un nuovo paragrafo. La query recupera l'ID compilazione. Inoltre, la differenza tra la destinazione e le temperature effettive per ogni edificio in una data specificata. Premere MAIUSC + INVIO.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"L'istruzione %sql all'inizio indica al notebook di usare l'interprete Livy Scala.
Selezionare l'icona Grafico a barre per modificare la visualizzazione. le impostazioni vengono visualizzate dopo aver selezionato grafico a barre, consente di scegliere Chiavi e Valori. Nella schermata riportata di seguito sono illustrate questo output.
È inoltre possibile eseguire istruzioni SQL Spark tramite le variabili nella query. Il frammento di codice seguente illustra come definire una variabile,
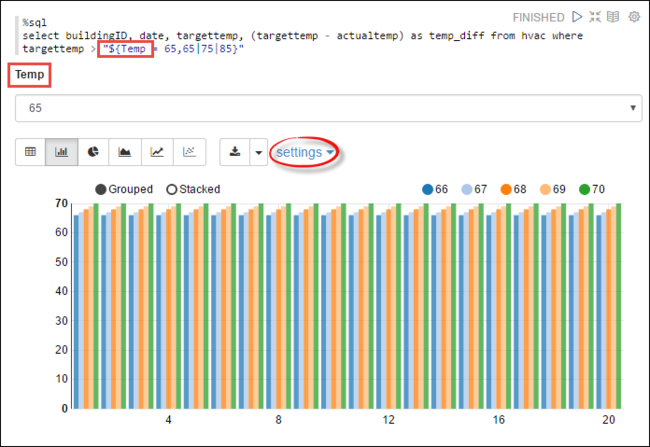
Temp, nella query con i valori possibili con cui eseguire una query. Quando si esegue la query per la prima volta, un elenco a tendina viene popolato automaticamente con i valori specificati per la variabile.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"Incollare questo frammento di codice in un nuovo paragrafo e premere MAIUSC+INVIO. Selezionare quindi 65 dall'elenco a discesa Temp .
Selezionare l'icona Grafico a barre per modificare la visualizzazione. Selezionare quindi le impostazioni e apportare le modifiche seguenti:
Gruppi: aggiungere targettemp.
Valori: 1. Rimuovere la data. 2. Aggiungere temp_diff. 3. Modificare l'aggregatore da SUM a AVG.
Nella schermata riportata di seguito sono illustrate questo output.
Come usare pacchetti esterni con il notebook
Il notebook Zeppelin nel cluster Apache Spark in HDInsight può usare pacchetti esterni forniti dalla community che non sono inclusi nel cluster. Cercare nel repository Maven l'elenco completo dei pacchetti disponibili. È anche possibile ottenere un elenco dei pacchetti disponibili da altre origini. Ad esempio, un elenco completo dei pacchetti creati dalla community è disponibile nel sito Web spark-packages.org.
In questo articolo viene illustrato come usare il pacchetto spark-csv con Jupyter Notebook.
Aprire le impostazioni dell'interprete. Nell'angolo in alto a destra selezionare il nome utente connesso e quindi selezionare Interprete.
Scorrere fino a livy2, quindi selezionare Modifica.
Passare alla chiave
livy.spark.jars.packagese impostarne il valore nel formatogroup:id:version. Se si vuole usare il pacchetto spark-csv, è quindi necessario impostare il valore della chiave sucom.databricks:spark-csv_2.10:1.4.0.
Selezionare Salva e quindi OK per riavviare l'interprete Livy.
Per comprendere come arrivare al valore della chiave immessa, ecco come.
a. Individuare un pacchetto nel repository Maven. Per questo articolo è stato usato spark-csv.
b. Recuperare dal repository i valori per GroupId, ArtifactId e Version.
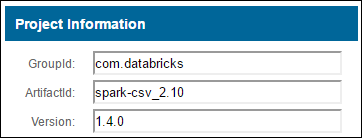
c. Concatenare i tre valori, separati da due punti (:).
com.databricks:spark-csv_2.10:1.4.0
Posizione di salvataggio dei notebook Zeppelin
I notebook Zeppelin salvati nei nodi head del cluster. Se si elimina il cluster, verranno quindi eliminati anche i notebook. Se si desidera conservare i notebook per usarli in un secondo momento in altri cluster, è necessario esportarli al termine dell'esecuzione dei processi. Per esportare un notebook, selezionare l'icona Esporta come illustrato nell'immagine come indicato di seguito.
Questa azione salva il notebook come file JSON nel percorso di download.
Nota
In HDI 4.0 il percorso della directory del notebook zeppelin è,
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/Ad esempio: /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
Mentre in HDI 5.0 e questo percorso è diverso
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/Ad esempio: /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
Il nome file archiviato è diverso in HDI 5.0. Viene archiviato come
<notebook_name>_<sessionid>.zplnAd esempio: testzeppelin_2JJK53XQA.zpln
In HDI 4.0 il nome del file è solo note.json archiviato nella directory session_id.
Ad esempio: /2JMC9BZ8X/note.json
HDI Zeppelin salva sempre il notebook nel percorso
/usr/hdp/<version>/zeppelin/notebook/nel disco locale di hn0.Se si vuole che il notebook sia disponibile anche dopo l'eliminazione del cluster, è possibile provare a usare l'archiviazione file di Azure (usando il protocollo SMB) e collegarlo al percorso locale. Per altre informazioni, vedere Montare una condivisione file di Azure SMB in Linux
Dopo il montaggio, è possibile modificare la configurazione zeppelin.notebook.dir nel percorso montato nell'interfaccia utente di Ambari.
- La condivisione file SMB come risorsa di archiviazione GitNotebookRepo non è consigliata per zeppelin versione 0.10.1
Usare Shiro per configurare l'accesso agli interpreti Zeppelin nei cluster ESP (Enterprise Security Package)
Come indicato in precedenza, l'interprete %sh non è supportato da HDInsight 4.0 in poi. Inoltre, poiché %sh l'interprete introduce potenziali problemi di sicurezza, ad esempio i keytab di accesso usando i comandi della shell, è stato rimosso anche dai cluster ESP di HDInsight 3.6. Significa che %sh l'interprete non è disponibile quando si fa clic su Crea nuova nota o nell'interfaccia utente dell'interprete per impostazione predefinita.
Gli utenti del dominio con privilegi possono usare il Shiro.ini file per controllare l'accesso all'interfaccia utente dell'interprete. Solo questi utenti possono creare nuovi %sh interpreti e impostare le autorizzazioni per ogni nuovo %sh interprete. Per controllare l'accesso usando il shiro.ini file, seguire questa procedura:
Definire un nuovo ruolo usando un nome di gruppo di dominio esistente. Nell'esempio seguente è
adminGroupNameun gruppo di utenti con privilegi in Microsoft Entra ID. Non usare caratteri speciali o spazi vuoti nel nome del gruppo. I caratteri dopo=assegnare le autorizzazioni per questo ruolo.*indica che il gruppo dispone di autorizzazioni complete.[roles] adminGroupName = *Aggiungere il nuovo ruolo per l'accesso agli interpreti Zeppelin. Nell'esempio seguente, a tutti gli utenti in
adminGroupNameviene concesso l'accesso agli interpreti Zeppelin e possono creare nuovi interpreti. È possibile inserire più ruoli tra parentesi quadre inroles[], separati da virgole. Gli utenti che dispongono delle autorizzazioni necessarie possono quindi accedere agli interpreti Zeppelin.[urls] /api/interpreter/** = authc, roles[adminGroupName]
Esempio shiro.ini per più gruppi di dominio:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Gestione delle sessioni di Livy
Il primo paragrafo di codice nel notebook Zeppelin crea una nuova sessione Livy nel cluster. Questa sessione viene condivisa in tutti i notebook Zeppelin creati in un secondo momento. Se la sessione Livy viene terminata per qualsiasi motivo, i processi non verranno eseguiti dal notebook Zeppelin.
In questo caso, è necessario eseguire i passaggi seguenti prima di poter avviare l'esecuzione di processi da un notebook Zeppelin.
Riavviare l'interprete Livy dal notebook Zeppelin. A tale scopo, aprire le impostazioni dell'interprete selezionando il nome utente connesso nell'angolo in alto a destra, quindi selezionare Interprete.
Scorrere fino a livy2, quindi selezionare Riavvia.
Eseguire una cella di codice da un notebook Zeppelin esistente. Questo codice crea una nuova sessione Livy nel cluster HDInsight.
Informazioni generali
Convalidare il servizio
Per convalidare il servizio da Ambari, passare a https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary dove CLUSTERNAME è il nome del cluster.
Per convalidare il servizio da una riga di comando, connettersi tramite SSH al nodo head. Passare a zeppelin usando il comando sudo su zeppelin. Comandi di stato:
| Comando | Descrizione |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
Stato del servizio. |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
Versione del servizio. |
ps -aux | grep zeppelin |
Identificare IL PID. |
Percorsi dei log
| Service | Percorso |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| Log del server | /var/log/zeppelin |
Interprete di configurazione, Shiro, site.xml, log4j |
/usr/hdp/current/zeppelin-server/conf o /etc/zeppelin/conf |
| Directory PID | /var/run/zeppelin |
Abilitazione della registrazione di debug
Passare a
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summarydove CLUSTERNAME è il nome del cluster.Passare a CONFIGS>Advanced zeppelin-log4j-properties>log4j_properties_content.
Modificare
log4j.appender.dailyfile.Threshold = INFOinlog4j.appender.dailyfile.Threshold = DEBUG.Aggiungere
log4j.logger.org.apache.zeppelin.realm=DEBUG.Salvare le modifiche e riavviare il servizio.