Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
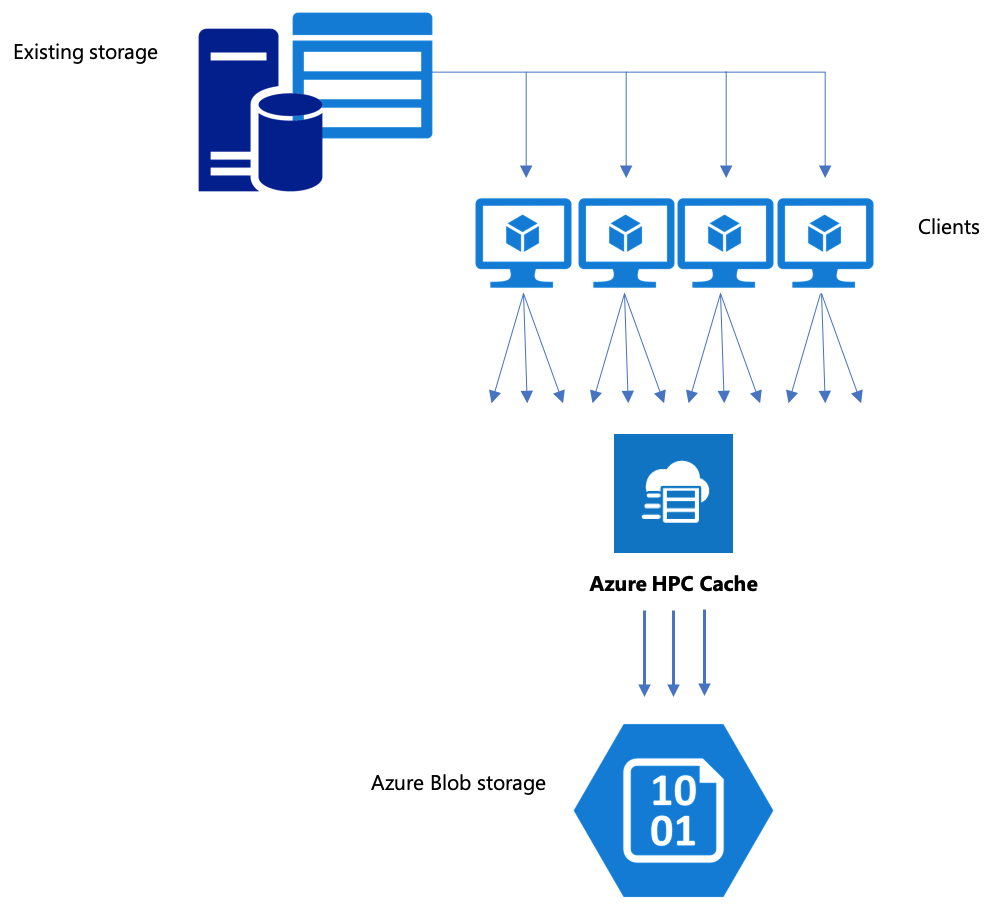
Se il flusso di lavoro include lo spostamento dei dati nell'archivio BLOB di Azure, assicurarsi di usare una strategia efficiente. È necessario creare la cache, aggiungere il contenitore BLOB come destinazione di archiviazione e quindi copiare i dati usando Cache HPC di Azure.
Questo articolo illustra i modi migliori per spostare i dati nell'archivio BLOB da usare con Cache HPC di Azure.
Tip
Questo articolo non si applica all'archiviazione blob montata su NFS (destinazioni di archiviazione ADLS-NFS). È possibile usare qualsiasi metodo basato su NFS per popolare un contenitore BLOB ADLS-NFS prima o dopo l'aggiunta alla cache HPC. Per altre informazioni, vedere Pre-caricare i dati con il protocollo NFS .
Tenere presenti questi fatti:
Cache HPC di Azure usa un formato di archiviazione specializzato per organizzare i dati nell'archiviazione BLOB. Ecco perché una destinazione di archiviazione BLOB deve essere un nuovo contenitore vuoto o un contenitore BLOB usato in precedenza per i dati di Cache HPC di Azure.
La copia dei dati tramite cache HPC di Azure in una destinazione di archiviazione back-end è più efficiente quando si usano più client e operazioni parallele. Un semplice comando di copia da un client sposta lentamente i dati.
Le strategie descritte in questo articolo funzionano per popolare un contenitore BLOB vuoto o per l'aggiunta di file a una destinazione di archiviazione usata in precedenza.
Copiare dati tramite cache HPC di Azure
Cache HPC di Azure è progettata per gestire più client contemporaneamente, quindi per copiare i dati tramite la cache, è consigliabile usare scritture parallele da più client.
I cp comandi o copy usati in genere per trasferire i dati da un sistema di archiviazione a un altro sono processi a thread singolo che copiano un solo file alla volta. Ciò significa che il file server inserisce un solo file alla volta, ovvero uno spreco di risorse della cache.
Questa sezione illustra le strategie per la creazione di un sistema di copia di file multi-client e multithread per spostare i dati nell'archiviazione blob con la cache HPC di Azure. Illustra i concetti di trasferimento dei file e i punti decisionali che possono essere usati per la copia efficiente dei dati usando più client e semplici comandi di copia.
Spiega anche alcune utilità che possono essere utili. L'utilità msrsync può essere usata per automatizzare parzialmente il processo di divisione di un set di dati in bucket e l'uso di comandi rsync. Lo parallelcp script è un'altra utilità che legge automaticamente la directory di origine e rilascia i comandi di copia.
Pianificazione strategica
Quando si crea una strategia per copiare i dati in parallelo, è necessario comprendere i compromessi nelle dimensioni dei file, nel numero di file e nella profondità della directory.
- Quando i file sono di piccole dimensioni, la metrica di interesse è i file al secondo.
- Quando i file sono di grandi dimensioni (10MiBi o superiori), la metrica di interesse è byte al secondo.
Ogni processo di copia ha una velocità effettiva e una velocità di trasferimento dei file, che può essere misurata in base alla lunghezza del comando di copia e al factoring delle dimensioni e del numero di file. Spiegare come misurare i tassi non rientra nell'ambito di questo documento, ma è fondamentale capire se si tratta di file di piccole o grandi dimensioni.
Le strategie per l'inserimento di dati paralleli con Cache HPC di Azure includono:
Copia manuale: è possibile creare manualmente una copia multithread in un client eseguendo più comandi di copia contemporaneamente in background su set predefiniti di file o percorsi. Per informazioni dettagliate, vedere Inserimento dati cache HPC di Azure: metodo di copia manuale .
La copia parzialmente automatizzata con
msrsync-msrsyncè un'utilità wrapper che esegue più processi paralleli.rsyncPer informazioni dettagliate, vedere Inserimento dati cache HPC di Azure - metodo msrsync.Copia tramite script con
parallelcp: informazioni su come creare ed eseguire uno script di copia parallela nell'inserimento di dati di Cache HPC di Azure - metodo di script di copia parallela.
Passaggi successivi
Dopo aver configurato lo storage, scopri come i client possono montare la cache.