Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La funzionalità di priming di Cache HPC di Azure consente ai clienti di precaricare i file nella cache.
È possibile usare questa funzionalità per recuperare il set di lavoro dei file previsto e popolare la cache prima dell'inizio del lavoro. Questa tecnica viene talvolta chiamata cache warming.
Il priming della cache migliora le prestazioni aumentando gli hit nella cache. Se un computer client richiede una risorsa che deve essere letta dall'archiviazione back-end, la latenza per il recupero e la restituzione del file può essere significativa, soprattutto se il sistema di archiviazione è un NAS locale. Se si effettua il priming della cache con i file necessari prima di avviare un'attività di calcolo, le richieste di file saranno più efficienti durante il processo.
Questa funzionalità usa un file manifesto JSON per specificare i file da caricare. Ogni processo di priming accetta un singolo file manifesto.
Creare processi di priming della cache usando il portale di Azure o con gli endpoint dell'API REST di Azure menzionati alla fine di questo documento.
È possibile creare fino a 10 attività di priming. A seconda delle dimensioni della cache, è possibile eseguire contemporaneamente da 3 a 10 processi di priming; altri vengono accodati fino a quando le risorse non vengono liberate.
Configurazione e prerequisiti
Prima di poter creare un processo di priming, seguire questa procedura:
- Creare una Cache HPC di Azure. (Per assistenza, fare riferimento a Creare una Cache HPC di Azure.)
- Definire almeno una destinazione di archiviazione, inclusa la creazione del relativo percorso (o percorsi) dello spazio dei nomi aggregato. Documentazione sulla destinazione di archiviazione
- Creare il manifesto del processo di priming (vedere le istruzioni di seguito) e archiviarlo in un contenitore BLOB accessibile alla cache HPC. In alternativa, se si usano le API REST di Azure per creare i processi di priming, è possibile archiviare il manifesto in qualunque URL accessibile dalla cache HPC.
Creare un file manifesto di priming
Il manifesto di priming è un file JSON che definisce il contenuto che verrà precaricato nella cache quando viene eseguito il processo di priming.
Nel manifesto, specificare il percorso dello spazio dei nomi per le directory o i file da precaricare. È anche possibile configurare regole di inclusione ed esclusione per personalizzare il contenuto caricato.
Manifesto di priming di esempio
{
"config": {
"cache_mode": "0",
"maxreadsize": "0",
"resolve_symlink": "0",
"threads":"8",
"skip_estimation":"0"
},
"files": [
"/bin/tool.py",
"/bin/othertool.py"
],
"directories": [
{"path": "/lib/toollib"},
{
"path": "/lib/otherlib",
"include": ["\\.py$"]
},
{
"path": "/lib/xsupport",
"include": ["\\.py$"],
"exclude": ["\\.elc$", "\\.pyc$"]
}
],
"include": ["\\.txt$"],
"exclude": ["~$", "\\.bak$"]
}
Esistono tre sezioni del file manifesto di priming:
Configurazione (
config): impostazioni per il processo di primingIstruzioni di file e directory:
files: singoli file che verranno precaricatidirectories: percorsi di file che verranno precaricati
Istruzioni di inclusione ed esclusione globali (
includeeexclude): stringhe di espressioni regolari che modificano l'attività di priming della directory
Impostazioni di configurazione
La sezione config del file manifesto imposta questi parametri:
Modalità cache: imposta il comportamento del processo di priming. Le opzioni sono:
- 0 - Dati: caricare tutti i dati e gli attributi del file specificati nella cache. Si tratta dell'impostazione predefinita.
- 1 - Metadati: caricare solo gli attributi del file.
- 2 - Stima: caricare gli attributi del file e restituire anche un numero stimato di file, directory e dimensioni totali dei dati (in byte) di cui verrebbe eseguito il priming se il contenuto in questo manifesto venisse eseguito in modalità Dati.
maxreadsize: imposta il numero massimo di byte che verranno precaricati per ogni file. Lasciare impostato su 0 (impostazione predefinita) per caricare sempre l'intero file, indipendentemente dalle dimensioni.resolve_symlink: impostare su true (1) se si desidera risolvere i collegamenti simbolici durante il priming. Seresolve_symlinkè abilitato, le destinazioni dei collegamenti simbolici vengono caricate completamente, indipendentemente dalle regole di inclusione ed esclusione.threads: il numero di thread di priming da usare. I valori validi sono compresi tra 1 e 128. Il valore predefinito è 8, per un bilanciamento tra priming e il servizio delle richieste client.skip_estimation: prima di iniziare la copia dei file, il processo di priming esegue una stima della quantità di dati di cui eseguire il priming. Impostare il flagskip_estimationsu true (1) se si desidera passare direttamente alla fase di priming del file. Se si ignora la fase di stima, il report di stato potrebbe essere meno accurato. Il valore predefinito è 0, per includere la fase di stima.
Percorso di file e directory
Le sezioni files e directories del manifesto specificano quali file vengono precaricati durante il processo di priming.
Specificare file e directory in base ai percorsi dello spazio dei nomi della cache. Questi sono gli stessi percorsi usati dai client per accedere ai file tramite la cache HPC e non devono essere uguali ai percorsi di sistema di archiviazione o ai nomi di esportazione. Per altre informazioni, leggere Pianificare lo spazio dei nomi aggregato.
Avviare i percorsi dalla radice dello spazio dei nomi della cache.
Nota
Gli elementi elencati in files vengono inclusi anche se corrispondono a regole di esclusione successive.
Il valore directories contiene un elenco di percorsi valutati per il precaricamento del contenuto nella cache. Tutti le sottostrutture vengono incluse nel processo di priming, a meno che non vengano escluse in modo specifico.
I valori del percorso della directory possono includere istruzioni di inclusione ed esclusione personalizzate, che si applicano solo al percorso con cui vengono definite. Ad esempio, la riga "directories": [{"path": "/cache/library1", "exclude": "\\.bak$"}] precarica tutti i file nel percorso dello spazio dei nomi /cache/library1/ ad eccezione dei file in tale percorso che terminano con .bak.
Le istruzioni di inclusione/esclusione a livello di directory non corrispondono alle istruzioni di inclusione ed esclusione globali descritte di seguito. Prestare attenzione a leggere i dettagli sul modo in cui le istruzioni a livello di directory interagiscono con le istruzioni di inclusione ed esclusione globali.
Nota
A causa del modo in cui viene analizzato il file manifesto, sono necessari due caratteri di escape per proteggere un carattere stringa problematico nelle istruzioni di inclusione ed esclusione. Ad esempio, usare l'espressione \\.txt per trovare la corrispondenza con i file .txt.
Istruzioni di inclusione ed esclusione
Dopo i file e le directory, è possibile specificare istruzioni include e exclude globali. Queste impostazioni globali si applicano a tutte le directory. Non si applicano ai file specificati in un'istruzione files.
In generale, le regole vengono confrontate nell’ordine, quindi le istruzioni visualizzate in precedenza nel file manifesto vengono applicate prima di quelle successive. Le descrizioni in questo articolo presuppongono, inoltre, che le regole precedenti siano già state applicate e non corrispondano.
Istruzioni di inclusione: durante l'analisi delle directory, il processo di priming ignora tutti i file che non corrispondono alle espressioni regolari nell'impostazione
include.Istruzioni di esclusione: durante l'analisi delle directory, il processo di priming ignora tutti i file che corrispondono alle espressioni regolari nell'impostazione
exclude.Altre informazioni sull'interazione delle regole di esclusione globali con altre regole:
Le regole di esclusione globali sostituiscono le regole di inclusione globali. Pertanto, se un nome file corrisponde sia a un’espressione di inclusione globale che a un’espressione di esclusione globale, non verrà precaricata dal processo di priming.
Le regole di inclusione a livello di directory sostituiscono regole di esclusione globali.
Un nome file che corrisponde sia a un’espressione di inclusione a livello di directory che a un’espressione di esclusione globale verrà precaricato dal processo di priming.
Le istruzioni di file sostituiscono tutte le regole di esclusione.
È possibile omettere le istruzioni di inclusione ed esclusione per inserire tutti i file nelle directory.
Altre informazioni sulle regole di inclusione/esclusione e sul modo in cui corrispondono ai nomi file:
Se un nome corrisponde a una voce nell'elenco di esclusione per directory, viene ignorato.
Se esiste un elenco di inclusione per directory, il nome viene incluso o escluso a seconda che venga visualizzato o meno in tale elenco.
Se un nome corrisponde a una voce nell'elenco di esclusione globale, viene ignorato.
Se esiste un elenco di inclusioni globale, il nome viene incluso se viene visualizzato nell'elenco o escluso se non viene visualizzato in tale elenco.
Se esiste un elenco di inclusione per directory, il nome viene escluso. In caso contrario, viene incluso.
Se una directory e un predecessore di tale directory vengono entrambi visualizzati nell'elenco delle directory, le regole specifiche per la directory vengono applicate insieme alle regole globali e le regole per la directory predecessore vengono ignorate.
Nomi e regole distinguono maiuscole e minuscole. Le origini che non distinguono maiuscole e minuscole non sono supportate.
Il numero totale di regole di file e regole di directory non può essere superiore a 4000. Il numero di regole di espressioni regolari per ogni elenco di inclusione/esclusione non può essere superiore a 5.
Se una specifica di directory si sovrappone a un'altra, ha la precedenza quella con il percorso più esplicito.
È un errore per un manifesto specificare più volte lo stesso percorso nell'elenco di file o nell'elenco di directory.
Caricare un file manifesto di priming
Quando il file manifesto è pronto, caricarlo in un contenitore BLOB di Azure in un account di archiviazione accessibile dalla cache HPC. Se si usano LE API anziché il portale per creare i processi di priming, è possibile l’archiviazione in un altro server Web, ma è necessario eseguire passaggi diversi per accertarsi che la cache possa accedervi.
Se si crea un processo di priming dal portale di Azure, selezionare il file manifesto nella pagina delle impostazioni Priming cache della cache HPC, come descritto di seguito. Selezionandolo dalle impostazioni della cache, viene creato automaticamente una firma di accesso condiviso (SAS) che fornisce alla cache l'accesso limitato al file di priming.
Se si usano le API per creare il processo di priming anziché usare il portale, accertarsi che la cache sia autorizzata ad accedere a tale file. Archiviare il file in un percorso accessibile, ad esempio in un server Web controllato all’interno della cache o della rete di archiviazione, oppure creare manualmente un URL SAS per il file di priming.
Per informazioni su come creare un URL SAS dell'account per il file manifesto di priming, leggere Concedere l'accesso limitato alle risorse di Archiviazione di Azure usando firme di accesso condiviso (SAS). Il file manifesto deve essere accessibile con HTTPS.
La cache accede al file manifesto una sola volta all'avvio del processo di priming. L'URL SAS generato per la cache non è esposto.
Creare un processo di priming
Usare il portale di Azure per creare un processo di priming. Visualizzare Cache HPC di Azure nel portale e selezionare la pagina Priming cache nell’intestazione Impostazioni.
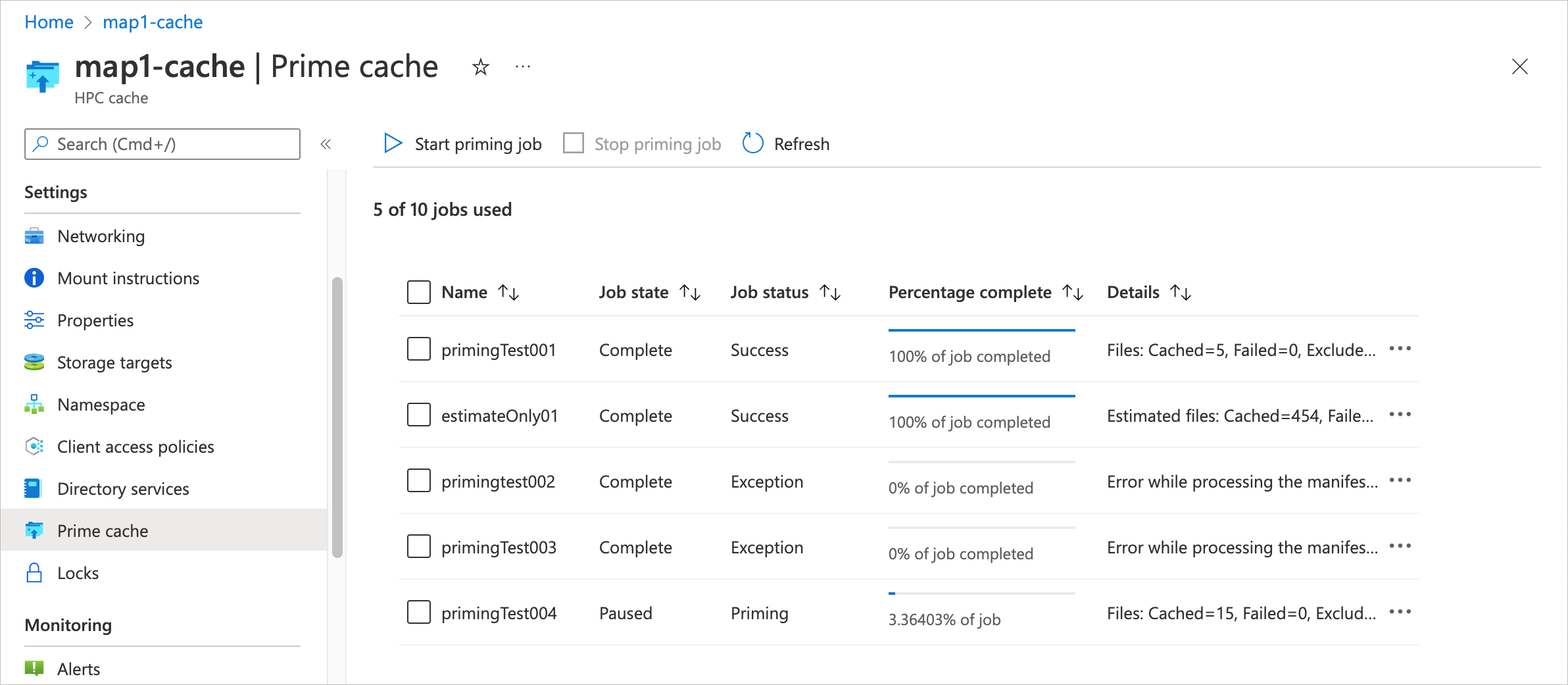
Fare clic sul testo Avvia processo di priming nella parte superiore della tabella per definire un nuovo processo.
Nel campo Nome processo, digitare un nome univoco per il processo di priming.
Usare il campo File priming per selezionare il file manifesto di priming. Selezionare l'account di archiviazione, il contenitore e il file in cui è archiviato il manifesto di priming.
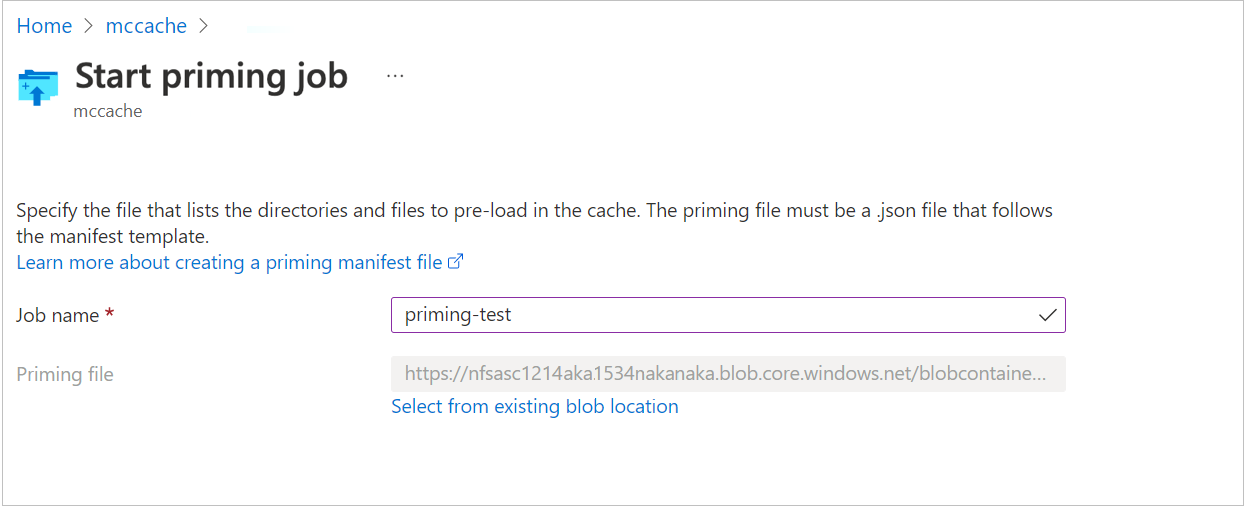
Per selezionare il file manifesto di priming, fare clic sul collegamento per selezionare una destinazione di archiviazione. Selezionare, quindi, il contenitore in cui è archiviato il file manifesto .json.
Se non è possibile trovare il file manifesto, la cache potrebbe non essere in grado di accedere al contenitore del file. Accertarsi che la cache disponga della connettività di rete all'account di archiviazione e sia in grado di leggere i dati dal contenitore.
Gestire processi di priming
I processi di priming sono elencati nella pagina Priming cache nel portale di Azure.
Questa pagina mostra il nome di ogni processo, lo stato, lo stato corrente e le statistiche di riepilogo sullo stato del priming. Il riepilogo nella colonna Dettagli viene aggiornato periodicamente mano a mano che il processo procede. Il campo Stato processo viene popolato all'avvio di un processo di priming; questo campo fornisce anche informazioni su errori di base, ad esempio Manifesto non valido, se si verifica un problema.
Durante l'esecuzione di un processo, la colonna Percentuale di completamento mostra una stima dello stato.
Prima dell'avvio di un processo di priming, lo stato è In coda. I campi Stato processo, Percentuale di completamento e Dettagli sono vuoti.
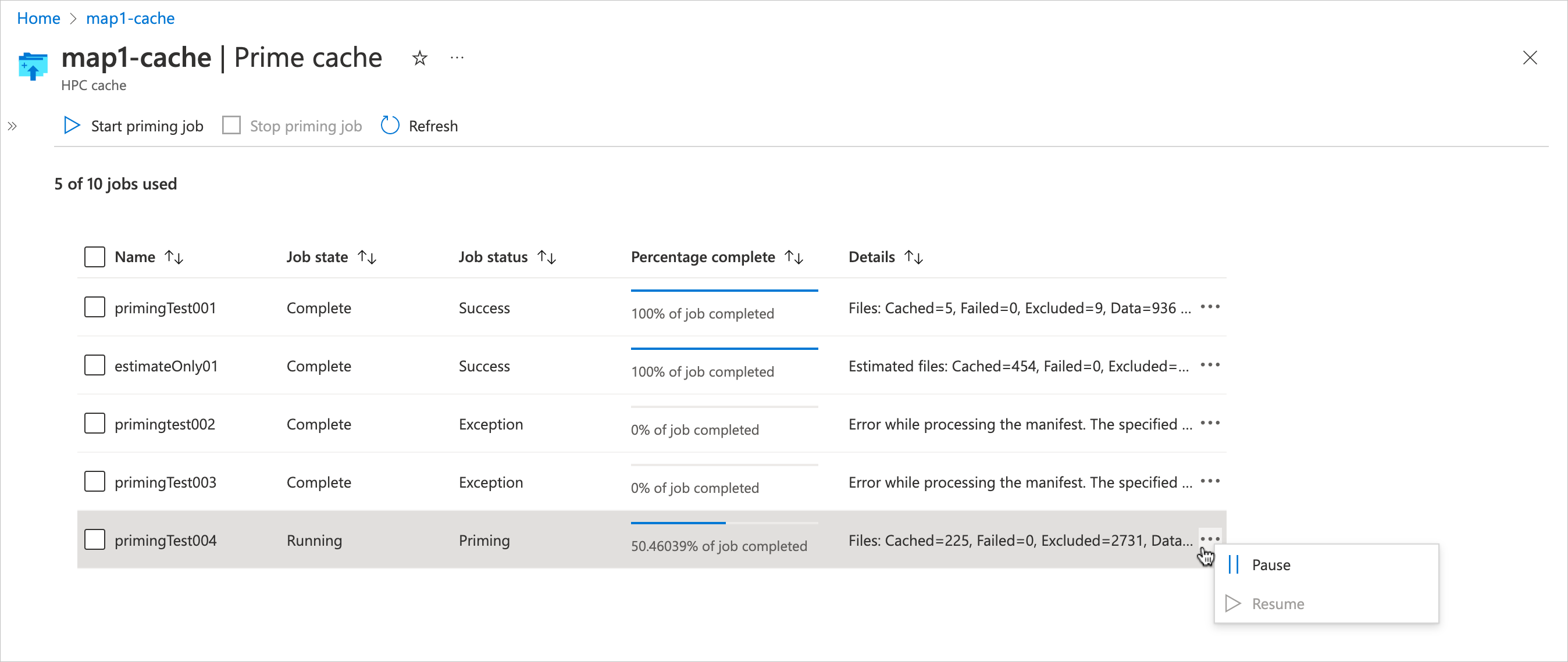
Fare clic sulla sezione ... a destra della tabella per sospendere o riprendere un processo di priming. L’aggiornamento dello stato potrebbe richiedere alcuni minuti.
Per eliminare un processo di priming, selezionarlo nell'elenco e usare il controllo Arresta nella parte superiore della tabella. È possibile usare il controllo Arresta per eliminare un processo in qualunque stato.
API REST di Azure
È possibile usare questi endpoint dell’API REST per creare e gestire processi di priming della cache HPC. Fanno parte della versione 2022-05-01 dell'API REST, per cui occorre accertarsi di usare tale stringa nel termine api_version.
Per informazioni su come usare questi strumenti, leggere Informazioni di riferimento sull'API REST di Azure.
Aggiungere un nuovo processo di priming
L'interfaccia startPrimingJob crea e accoda un processo di priming. Il processo viene avviato automaticamente quando sono disponibili le risorse.
URL: POST
https://MY-ARM-HOST/subscriptions/MY-SUBSCRIPTION-ID/resourceGroups/MY-RESOURCE-GROUP-NAME/providers/Microsoft.StorageCache/caches/MY-CACHE-NAME/startPrimingJob?api-version=2022-05-01
BODY:
{
"primingJobName": "MY-PRIMING-JOB",
"primingManifestUrl": "MY-JSON-MANIFEST-FILE-URL"
}
Per il valore primingManifestUrl, passare l'URL SAS del file o a un altro URL HTTPS accessibile alla cache. Per altre informazioni, leggere Caricare un file manifesto di priming.
Arrestare un processo di priming
L'interfaccia stopPrimingJob annulla un processo (se è in esecuzione) e lo rimuove dall'elenco di processi. Usare questa interfaccia per eliminare un processo di priming in qualunque stato.
URL: POST
https://MY-ARM-HOST/subscriptions/MY-SUBSCRIPTION-ID/resourceGroups/MY-RESOURCE-GROUP-NAME/providers/Microsoft.StorageCache/caches/MY-CACHE-NAME/stopPrimingJob?api-version=2022-05-01
BODY:
{
"primingJobId": "MY-JOB-ID-TO-REMOVE"
}
Ottenere i processi di priming
Usare l'API Get cache per elencare i processi di priming della cache. Questa API restituisce numerose informazioni sulla cache; cercare le informazioni sul processo di priming nella sezione "proprietà cache".
Vengono restituiti i nomi e gli ID dei processi di priming, insieme ad altre informazioni.
URL: GET
https://MY-ARM-HOST/subscriptions/MY-SUBSCRIPTION-ID/resourceGroups/MY-RESOURCE-GROUP-NAME/providers/Microsoft.StorageCache/caches/MY-CACHE-NAME?api-version=2022-05-01
BODY:
Sospendere un processo di priming
L'interfaccia pausePrimingJob sospende un processo in esecuzione.
URL: POST
https://MY-ARM-HOST/subscriptions/MY-SUBSCRIPTION-ID/resourceGroups/MY-RESOURCE-GROUP-NAME/providers/Microsoft.StorageCache/caches/MY-CACHE-NAME/pausePrimingJob?api-version=2022-05-01
BODY:
{
"primingJobId": "MY-JOB-ID-TO-PAUSE"
}
Riprendere un processo di priming
Usare l'interfaccia resumePrimingJob per riattivare un processo di priming sospeso.
URL: POST
https://MY-ARM-HOST/subscriptions/MY-SUBSCRIPTION-ID/resourceGroups/MY-RESOURCE-GROUP-NAME/providers/Microsoft.StorageCache/caches/MY-CACHE-NAME/resumePrimingJob?api-version=2022-05-01
BODY:
{
"primingJobId": "MY-JOB-ID-TO-RESUME"
}
Domande frequenti
È possibile riutilizzare processo di priming?
Non esattamente, perché ogni processo di priming nell'elenco deve avere un nome univoco. Dopo aver eliminato un processo di priming dall'elenco, è possibile creare un nuovo processo con lo stesso nome.
È possibile creare più processi di priming che fanno riferimento allo stesso file manifesto.
Per quanto tempo un processo di priming non riuscito o completato rimane nell'elenco?
I processi priming vengono mantenuti nell'elenco fino a quando vengono eliminati. Nella pagina Priming cache del portale, selezionare la casella di controllo accanto al processo, quindi selezionare il controllo Arresta nella parte superiore dell’elenco per eliminare il processo.
Cosa accade se il contenuto che si sta precaricando è più grande dello spazio di archiviazione della cache?
Se la cache si riempie, i file recuperati in un secondo momento sovrascriveranno i file di cui è già stato eseguite il priming.
Passaggi successivi
- Per altre informazioni sul priming della cache HPC, seguire il processo in Ottenere assistenza con Cache HPC di Azure.
- Altre informazioni sulle API REST di Azure