Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() Edge 1.5
Edge 1.5
Importante
IoT Edge 1.5 LTS è la versione supportata. IoT Edge 1.4 LTS è di fine vita a partire dal 12 novembre 2024. Se si usa una versione precedente, vedere Aggiornare IoT Edge.
In questo articolo vengono illustrati i concetti e le tecniche per l'implementazione delle dimensioni di osservabilità: misurazione e monitoraggio erisoluzione dei problemi. Vengono illustrati gli argomenti seguenti:
- Definire gli indicatori di prestazioni del servizio da monitorare
- Misurare gli indicatori di prestazioni del servizio usando le metriche
- Monitorare le metriche e rilevare i problemi usando le cartelle di lavoro di Monitoraggio di Azure
- Risolvere i problemi di base usando cartelle di lavoro curate
- Risolvere i problemi avanzati usando la traccia distribuita e i log correlati
- Facoltativamente, distribuire uno scenario di esempio in Azure per praticare le informazioni apprese
Sceneggiatura
Per andare oltre le considerazioni astratte, si userà uno scenario reale che raccoglie le temperature della superficie dell'oceano dai sensori in Azure IoT.
La Niña
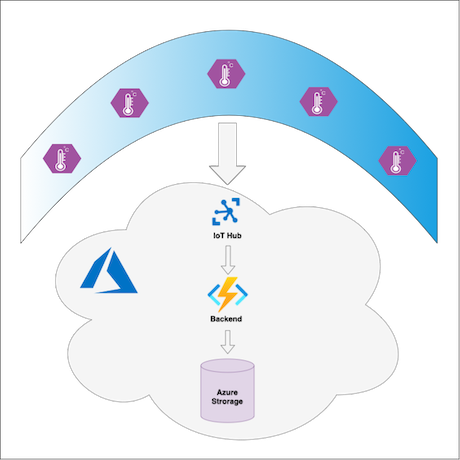
Il servizio La Niña misura la temperatura della superficie nell'Oceano Pacifico per prevedere gli invernali di La Niña. I buoi nell'oceano hanno dispositivi IoT Edge che inviano dati sulla temperatura della superficie al cloud di Azure. Un modulo personalizzato in ogni dispositivo IoT Edge pre-elabora i dati di telemetria prima di inviarli al cloud. Nel cloud, le Azure Functions di backend elaborano i dati e li salvano in Azure Blob Storage. I client del servizio, ad esempio flussi di lavoro di inferenza ml, sistemi decisionali e interfacce utente diverse, possono ottenere messaggi con dati relativi alla temperatura da Archiviazione BLOB di Azure.
Misurazione e monitoraggio
Ora verrà creata una soluzione di misurazione e monitoraggio per il servizio La Niña incentrata sul valore aziendale.
Oggetto della misurazione e del monitoraggio
Per comprendere ciò che verrà monitorato, è necessario comprendere cosa fa effettivamente il servizio e quali sono i client del servizio previsti dal sistema. In questo scenario, le aspettative di un consumer di servizi La Niña comune potrebbero essere classificate in base ai fattori seguenti:
- Copertura. I dati provengono dalla maggior parte delle boe installate
- Aggiornamento. I dati provenienti dalle boe sono aggiornati e pertinenti
- Velocità effettiva. I dati sulla temperatura vengono forniti dalle boe senza ritardi significativi
- Correttezza. Il rapporto dei messaggi persi (errori) è ridotto
La soddisfazione relativa a questi fattori implica che il servizio funziona in base alle aspettative del cliente.
Il passaggio successivo consiste nella definizione di strumenti per misurare i valori di tali fattori. Questo processo viene eseguito dagli indicatori del livello di servizio (SLI) seguenti:
| Indicatore del livello di servizio | Fattori |
|---|---|
| Rapporto tra i dispositivi on-line e il numero totale di dispositivi | Copertura |
| Rapporto tra i dispositivi che segnalano frequentemente e il numero di dispositivi che segnalano | Aggiornamento, velocità effettiva |
| Rapporto tra i dispositivi che consegnano correttamente i messaggi e il numero totale di dispositivi | Correttezza |
| Rapporto tra i dispositivi che consegnano rapidamente i messaggi e il numero totale di dispositivi | Velocità effettiva. |
A tale scopo, è possibile applicare una scala scorrevole su ogni indicatore e definire valori di soglia esatti che rappresentano ciò che comporta per il cliente essere "soddisfatto". Per questo scenario, vengono selezionati i valori soglia di esempio, come descritto nella tabella seguente con obiettivi formali del livello di servizio :For this scenario, we select sample threshold values as laid out in the following table with formal Service Level Objectives (SLOs):
| Obiettivo del livello di servizio | Fattore |
|---|---|
| Il 90% dei dispositivi ha segnalato metriche non oltre di 10 minuti fa (erano online) per l'intervallo di osservazione | Copertura |
| Il 95% dei dispositivi online invia la temperatura 10 volte al minuto per l'intervallo di osservazione | Aggiornamento, velocità effettiva |
| Il 99% dei dispositivi online consegna correttamente i messaggi con meno del 5% degli errori per l'intervallo di osservazione | Correttezza |
| Il 95% dei dispositivi online recapita il 90° percentile dei messaggi entro 50 ms per l'intervallo di osservazione | Velocità effettiva. |
La definizione degli SLO deve descrivere anche l'approccio del modo in cui vengono misurati i valori degli indicatori:
- Intervallo di osservazione: 24 ore. Le affermazioni SLO sono vere nelle ultime 24 ore. Ciò significa che se un SLI si interrompe e viola un SLO corrispondente, sono necessarie 24 ore dopo che l'SLI è stato risolto per considerare di nuovo valido l'SLO.
- Frequenza di misurazione: 5 minuti. Le misurazioni vengono eseguite per valutare i valori SLI ogni 5 minuti.
- Oggetto delle misurazioni: l'interazione tra il dispositivo IoT e il cloud, un ulteriore consumo dei dati sulla temperatura non rientra nell'ambito.
Come viene eseguita la misurazione
A questo punto, è chiaro cosa verrà misurato e quali valori di soglia verranno usati per determinare se il servizio viene eseguito in base alle aspettative.
È una pratica comune misurare gli indicatori del livello di servizio, come quelli definiti, tramite metriche. Questo tipo di dati di osservabilità è considerato relativamente piccolo in valori. Viene prodotto da vari componenti di sistema e raccolto in un back-end di osservabilità centrale da monitorare con dashboard, cartelle di lavoro e avvisi.
Quali sono i componenti di cui è costituito il servizio La Niña:
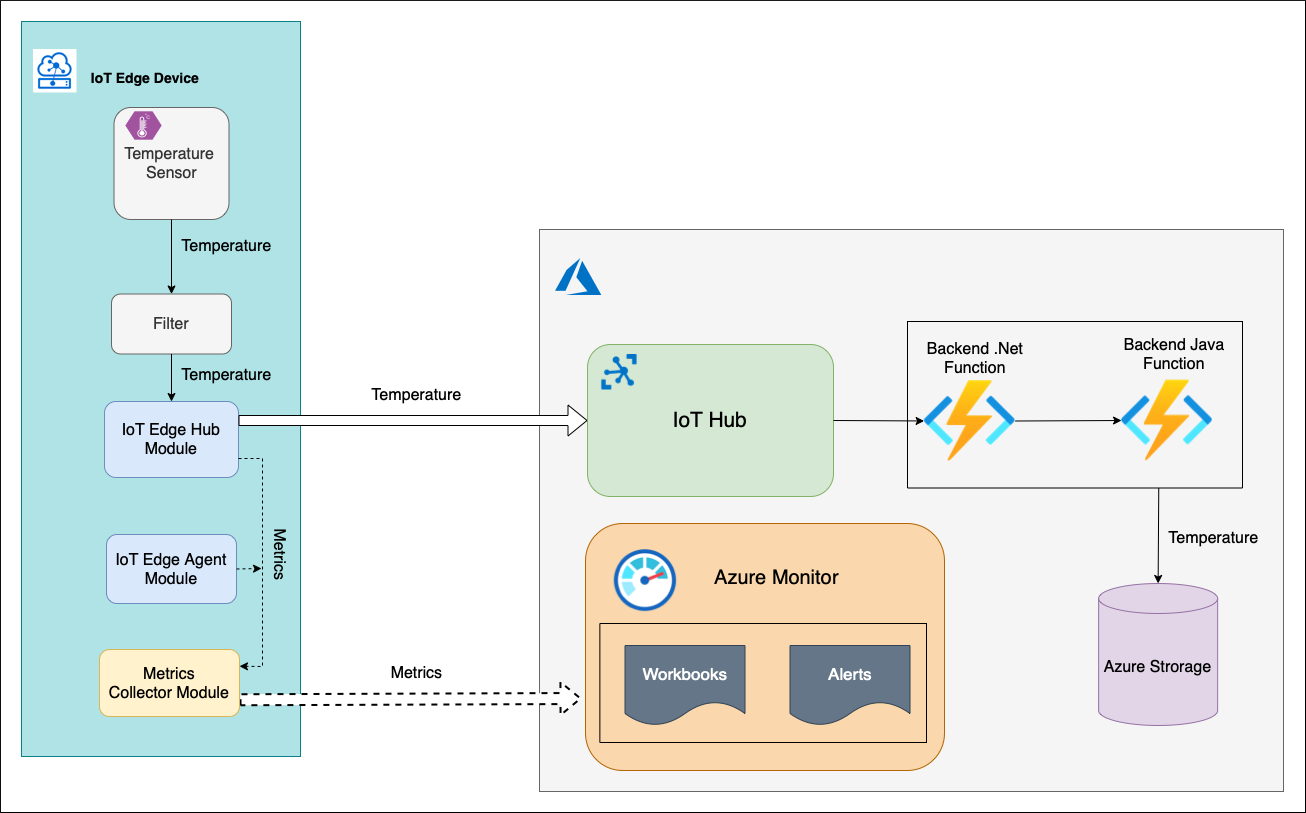
Esiste un dispositivo IoT Edge con Temperature Sensor modulo personalizzato (C#) che genera un valore di temperatura e lo invia a monte con un messaggio di telemetria. Per questo messaggio viene instradato a un altro modulo personalizzato Filter (C#). Questo modulo controlla la temperatura ricevuta rispetto a una finestra di soglia (0-100 gradi Celsius). Se la temperatura si trova all'interno della finestra, FilterModule invia il messaggio di telemetria al cloud.
Nel cloud, il messaggio viene elaborato dal back-end. Il back-end è costituito da una catena di due funzioni di Azure e un account di archiviazione. La funzione .NET di Azure preleva il messaggio di telemetria dall'endpoint degli eventi dell'hub IoT, lo elabora e lo invia alla funzione Java di Azure. La funzione Java salva il messaggio nel contenitore BLOB dell'account di archiviazione.
Un dispositivo hub IoT include i moduli di sistema edgeHub e edgeAgent. Questi moduli espongono tramite un endpoint Prometheus un elenco di metriche predefinite. Queste metriche vengono raccolte e inviate al servizio Log Analytics di Monitoraggio di Azure dal modulo dell'agente di raccolta metriche in esecuzione nel dispositivo IoT Edge. Oltre ai moduli di sistema, i moduli Temperature Sensor e Filter possono essere instrumentati anche con alcune metriche specifiche dell'azienda. Tuttavia, gli indicatori del livello di servizio definiti possono essere misurati solo con le metriche predefinite. A questo punto, quindi, non occorrono ulteriori implementazioni.
In questo scenario esiste una flotta di 10 boe. Una delle boe è intenzionalmente configurata per il malfunzionamento in modo da poter dimostrare il rilevamento e la successiva risoluzione del problema.
Come si esegue il monitoraggio
Verranno monitorati gli obiettivi del livello di servizio (SLO) e gli indicatori del livello di servizio (SLI) corrispondenti con le cartelle di lavoro di Monitoraggio di Azure. Questa distribuzione dello scenario include la cartella di lavoro SLO/SLI La Nina assegnata all'hub IoT.
Per ottimizzare l'esperienza utente, le cartelle di lavoro sono progettate per seguire il concetto glance - >scan - > commit:
Occhiata
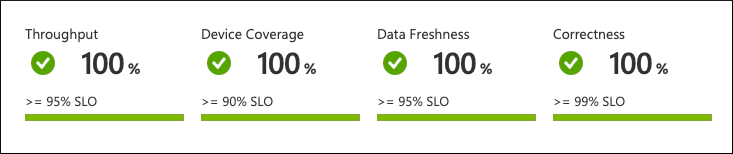
A questo livello, è possibile vedere l'intera immagine a colpo d'occhio. I dati vengono aggregati e rappresentati a livello di flotta:
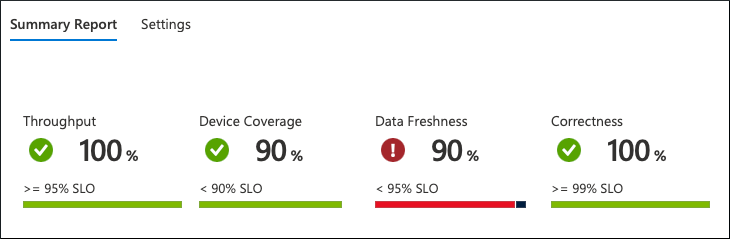
Da ciò che è possibile vedere, il servizio non funziona in base alle aspettative. C'è una violazione dell'SLO relativo all'aggiornamento dei dati. Solo il 90% dei dispositivi invia i dati frequentemente, mentre i clienti del servizio si attendono il 95%.
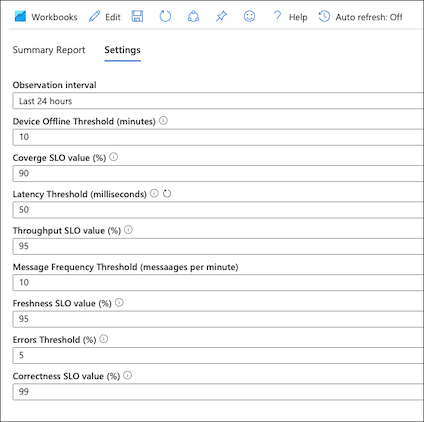
Tutti i valori SLO e soglia sono configurabili nella scheda delle impostazioni della cartella di lavoro:
Scansione
Facendo clic sullo SLO violato, è possibile eseguire il drill-down al livello scan e vedere come i dispositivi contribuiscono al valore SLI aggregato.
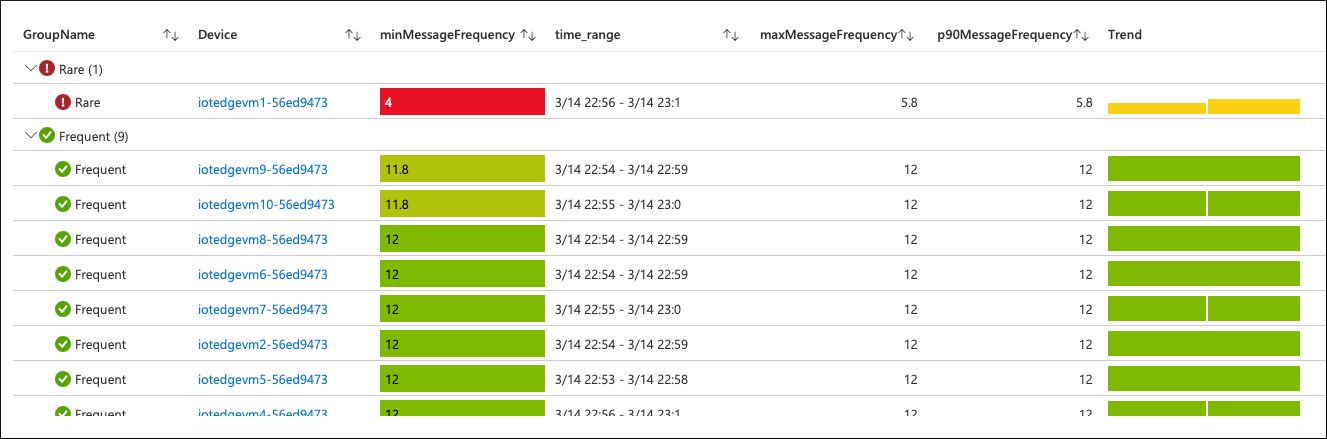
È presente un singolo dispositivo (su 10) che invia i dati di telemetria al cloud "raramente". Nella definizione di SLO è stato dichiarato che "frequentemente" significa almeno 10 volte al minuto. La frequenza di questo dispositivo è al di sotto di tale soglia.
Conferma
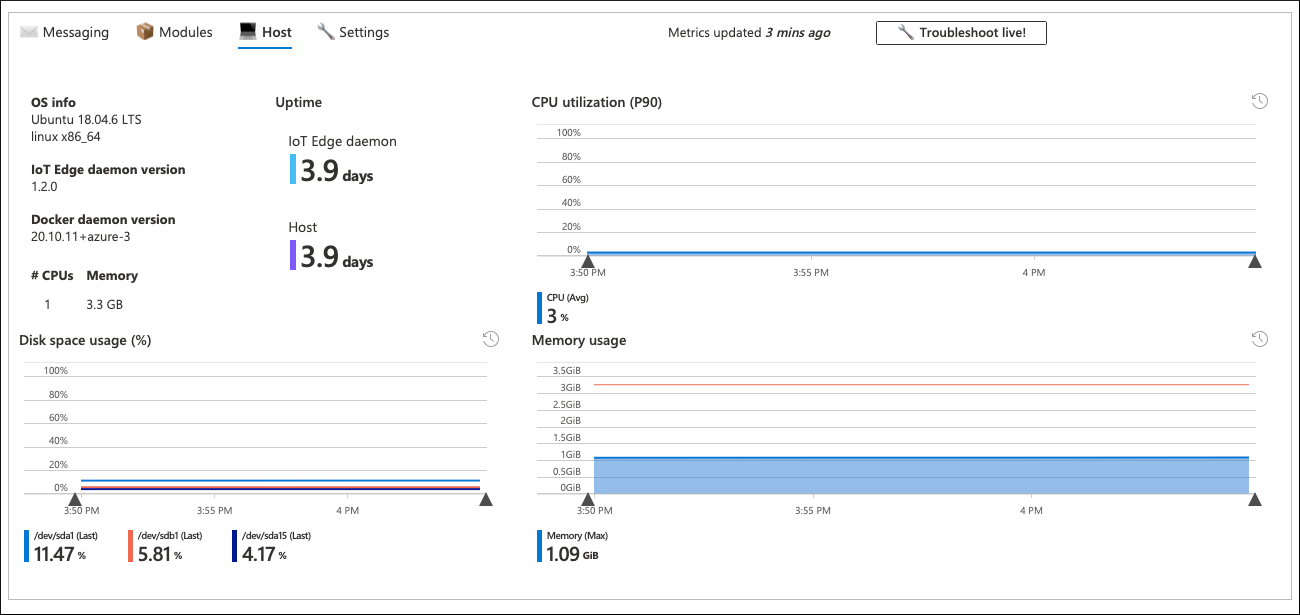
Facendo clic sul dispositivo problematico, verrà eseguito il drill-down al livello commit. Questa è una cartella di lavoro curata Dettagli dispositivo fornita già pronta con l'offerta di monitoraggio dell'hub IoT. La cartella di lavoro SLO/SLI La Nina lo riutilizza per visualizzare i dettagli delle prestazioni del dispositivo specifico.
Risoluzione dei problemi
Misurazione e monitoraggio consente di osservare e prevedere il comportamento del sistema, confrontarlo con le aspettative definite e rilevare, infine, problemi esistenti o potenziali. La risoluzione dei problemi, d’altro canto, consente di identificare e individuare la causa del problema.
Risoluzione dei problemi di base
La cartella di lavoro a livello di commit fornisce informazioni dettagliate sull'integrità del dispositivo. Ciò include l'utilizzo delle risorse a livello di modulo e dispositivo, latenza dei messaggi, frequenza, QLen e altro ancora. In molti casi, queste informazioni possono aiutare a individuare la radice del problema.
In questo scenario, tutti i parametri del dispositivo di problemi sembrano normali e non è chiaro perché il dispositivo invia messaggi meno frequentemente del previsto. La scheda messaggistica della cartella di lavoro a livello di dispositivo conferma anche quanto segue:
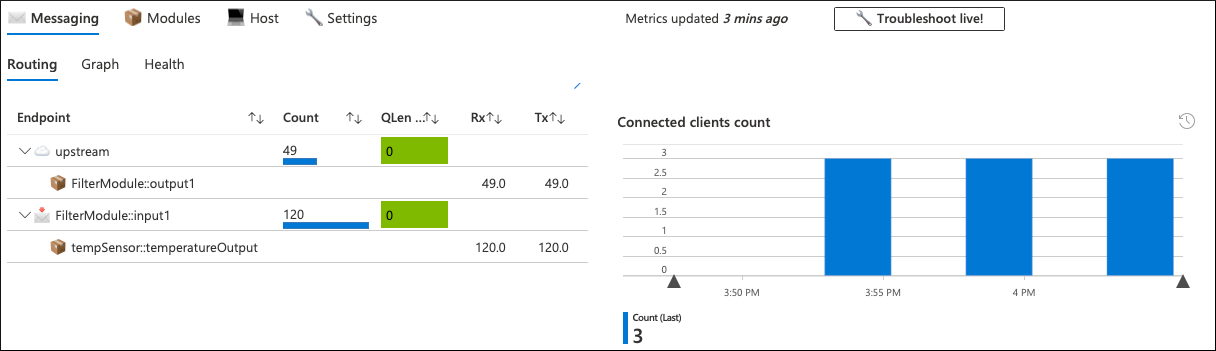
Il modulo Temperature Sensor (tempSensor) ha generato 120 messaggi di telemetria, ma solo 49 di essi erano upstream nel cloud.
Prima di tutto, controllare i log prodotti dal Filter modulo. Selezionare Risoluzione dei problemi live!, quindi selezionare il Filter modulo.
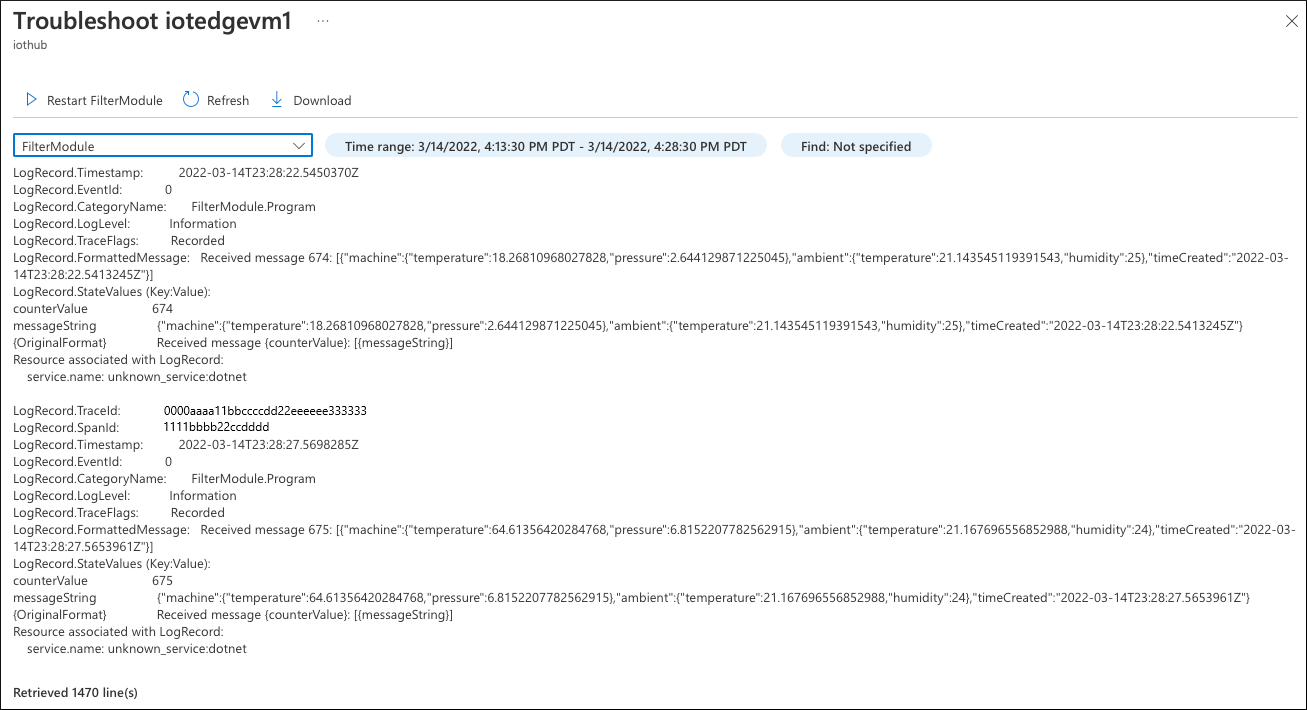
L'analisi dei log del modulo non rivela il problema. Il modulo riceve messaggi e non sono presenti errori. Tutto sembra in ordine.
Risoluzione dei problemi completa
Due strumenti di osservabilità servono a scopi di risoluzione dei problemi profondi: tracce e log. In questo scenario, le tracce mostrano come un messaggio di telemetria con la temperatura della superficie dell'oceano viaggia dal sensore fino all'archiviazione nel cloud, cosa invoca cosa e con quali parametri. I log mostrano cosa accade all'interno di ogni componente di sistema durante questo processo. La vera potenza delle tracce e dei log si ottiene quando vengono correlati. Con questa configurazione è possibile leggere i log di un componente di sistema specifico, ad esempio un modulo in un dispositivo IoT o una funzione back-end, mentre elabora un messaggio di telemetria specifico.
Il servizio La Niña usa OpenTelemetry per produrre e raccogliere tracce e log in Monitoraggio di Azure.
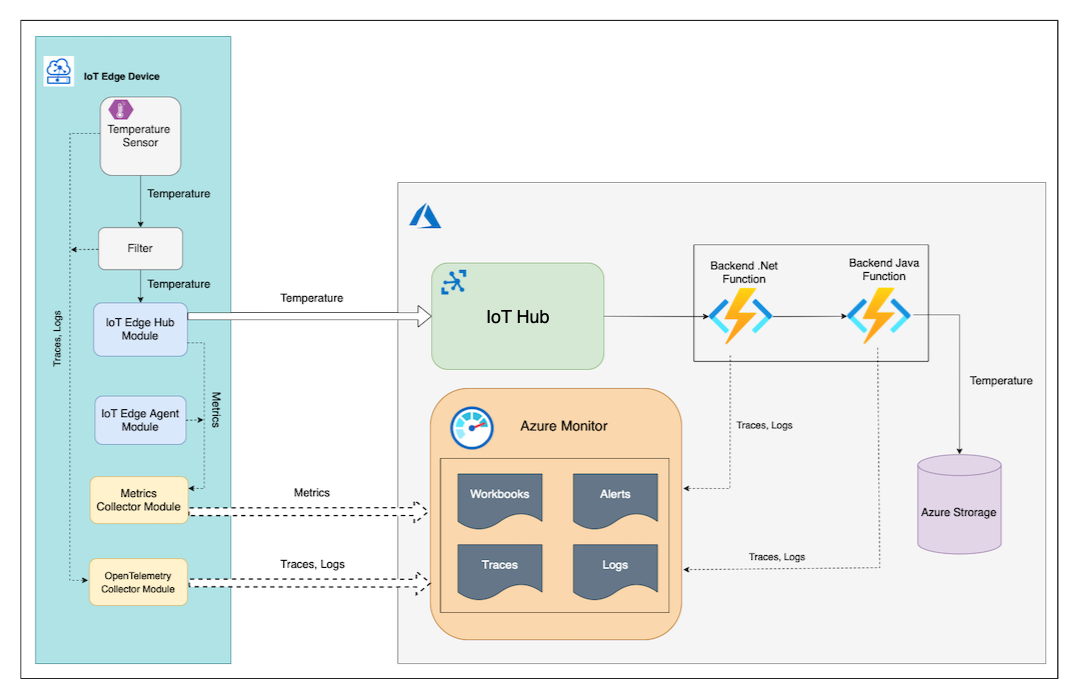
I moduli Temperature Sensor IoT Edge esportano Filter i log e i dati di traccia usando OTLP (OpenTelemetry Protocol) nel modulo OpenTelemetryCollector in esecuzione nello stesso dispositivo perimetrale. Il OpenTelemetryCollector modulo esporta quindi i log e le tracce in Azure Monitor Application Insights.
La funzione .NET di Azure invia i dati di traccia ad Application Insights con l'esportatore diretto Azure Monitor Open Telemetry. Invia anche i log correlati direttamente ad Application Insights usando un'istanza ILogger configurata.
La funzione back-end Java usa l’agente Java di strumentazione automatica OpenTelemetry per produrre ed esportare i dati di traccia e i log correlati all'istanza di Application Insights.
Per impostazione predefinita, i moduli IoT Edge nei dispositivi del servizio La Niña non sono impostati per produrre dati di traccia e il livello di registrazione è impostato su Information. La quantità di dati di traccia è controllata da un campionatore a rapporto. Il campionatore viene impostato con una probabilità che una determinata attività venga inclusa in una traccia. Per impostazione predefinita, la probabilità è 0. Con questa configurazione, i dispositivi evitano di sovraccaricare Azure Monitor con dati di osservabilità dettagliati quando non sono necessari.
Dopo aver analizzato i log di Information livello del Filter modulo, è necessario approfondire la causa del problema. Aggiornare le proprietà nei gemelli dei moduli Temperature Sensor e Filter, aumentare il loggingLevel fino a Debug, e modificare il traceSampleRatio da 0 a 1:
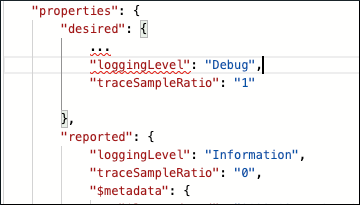
Dopo aver apportato queste modifiche, riavviare i Temperature Sensor moduli e Filter :
In pochi minuti, le tracce e i log dettagliati arrivano in Monitoraggio di Azure dal dispositivo con problemi. L'intero flusso di messaggi end-to-end dal sensore nel dispositivo all'archiviazione nel cloud è disponibile per il monitoraggio con la mappa delle applicazioni in Application Insights:
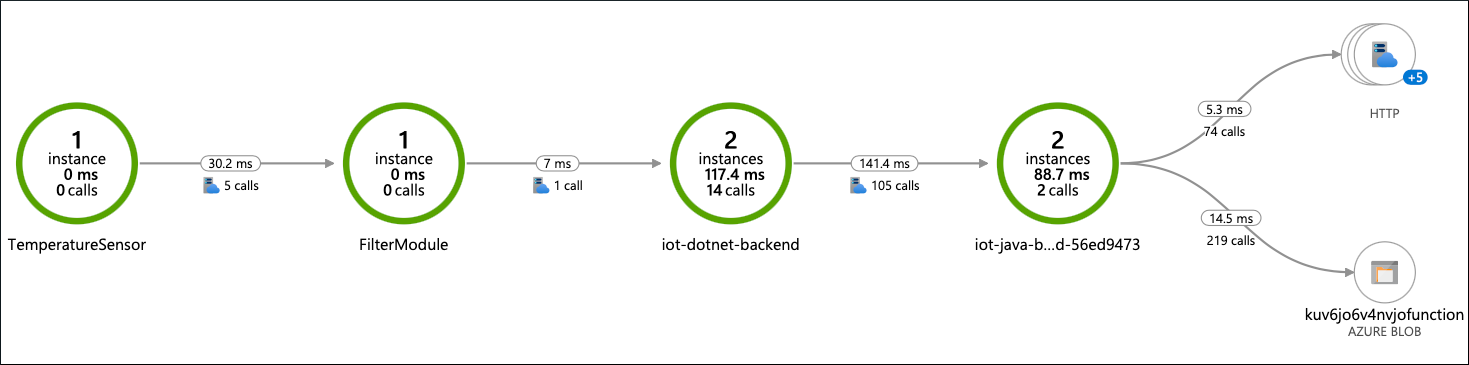
Da questa mappa è possibile eseguire il drill-down delle tracce. Alcune tracce sembrano normali e contengono tutti i passaggi del flusso, ma alcuni sono brevi, quindi non accade nulla dopo il Filter modulo.
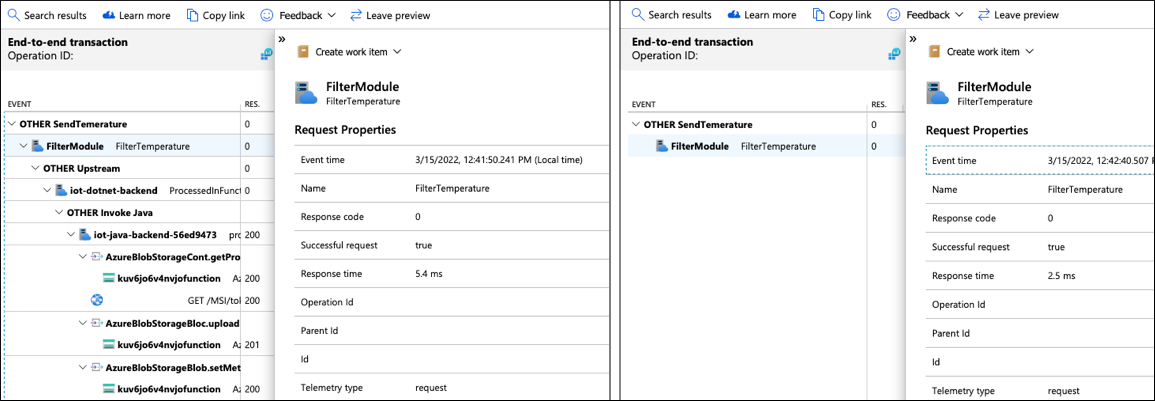
Analizzare una di queste brevi tracce per scoprire cosa è successo nel Filter modulo e perché non ha inviato il messaggio upstream al cloud.
Poiché i log sono correlati alle tracce, è possibile eseguire query sui log specificando TraceId e SpanId per recuperare i log per questa istanza di esecuzione del Filter modulo:
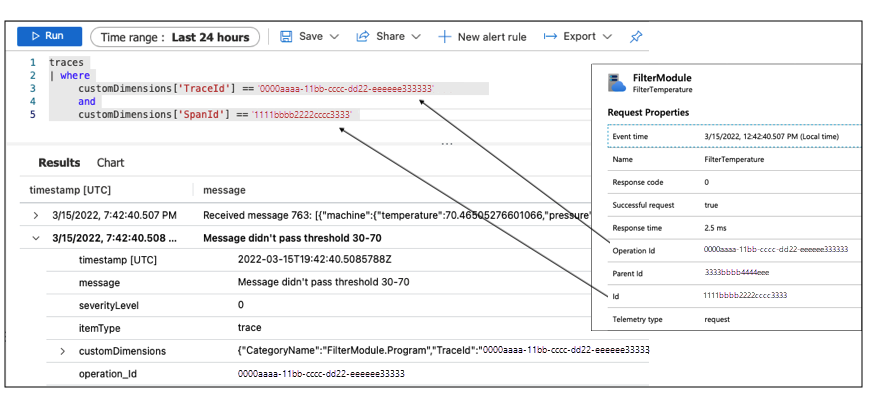
I log mostrano che il modulo ha ricevuto un messaggio con una temperatura di 70,465 gradi. Tuttavia, la soglia di filtro impostata su questo dispositivo è da 30 a 70. Quindi il messaggio non ha superato la soglia. Questo dispositivo è configurato in modo non corretto. Questa configurazione è la causa del problema rilevato durante il monitoraggio delle prestazioni del servizio La Niña con la cartella di lavoro.
Correggere la configurazione del Filter modulo in questo dispositivo aggiornando le proprietà nel modulo gemello. Inoltre, ridurre loggingLevel a Information e impostare traceSampleRatio su 0:

Dopo aver apportato queste modifiche, riavviare il modulo. In pochi minuti, il dispositivo segnala nuovi valori delle metriche a Monitoraggio di Azure. I grafici delle cartelle di lavoro riflettono questi aggiornamenti:
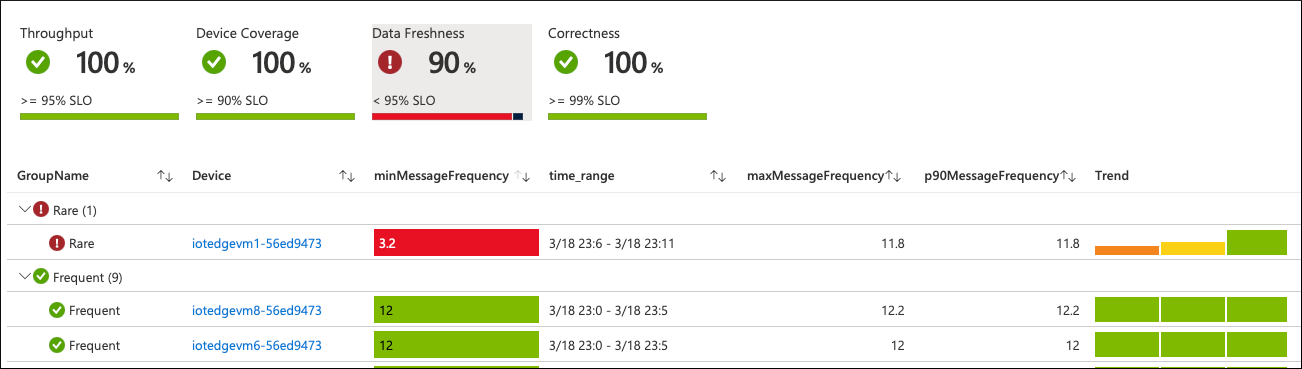
La frequenza dei messaggi nel dispositivo problematico torna normale. Il valore SLO complessivo diventa di nuovo verde se non accade altro durante l'intervallo di osservazione configurato:
Provare l’esempio
A questo punto, è possibile distribuire l'esempio di scenario in Azure per seguire i passaggi e provare i propri casi d'uso.
Per distribuire questa soluzione, è necessario:
- PowerShell
- Interfaccia della riga di comando di Azure
- Un account Azure con una sottoscrizione attiva. Crearne una gratuitamente.
Clonare il repository IoT Elms.
git clone https://github.com/Azure-Samples/iotedge-logging-and-monitoring-solution.gitAprire una console di PowerShell ed eseguire lo script
deploy-e2e-tutorial.ps1../Scripts/deploy-e2e-tutorial.ps1
Passaggi successivi
In questo articolo viene configurata una soluzione con funzionalità di osservabilità end-to-end per il monitoraggio e la risoluzione dei problemi. Una sfida comune in queste soluzioni per i sistemi IoT consiste nell'inviare dati di osservabilità dai dispositivi al cloud. I dispositivi in questo scenario dovrebbero essere online e abbiano una connessione stabile ad Azure Monitor, ma questo non è sempre il caso.
Consulta gli articoli di approfondimento, ad esempio *Distributed Tracing with IoT Edge*, per consigli e tecniche per gestire gli scenari in cui i dispositivi sono in genere offline o hanno connessioni limitate o ristrette sul backend di osservabilità nel cloud.