Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive come usare il componente Execute R Script (Esegui script R) per eseguire il codice R nella pipeline della finestra di progettazione di Azure Machine Learning.
Con R è possibile eseguire attività non supportate dai componenti esistenti, ad esempio:
- Creare trasformazioni di dati personalizzate
- Usare le metriche personalizzate per valutare le stime
- Compilare modelli usando algoritmi non implementati come componenti autonomi nella finestra di progettazione
Supporto della versione R
La finestra di progettazione di Azure Machine Learning usa la distribuzione CRAN (Comprehensive R Archive Network) di R. La versione attualmente usata è CRAN 3.5.1.
Pacchetti R supportati
L'ambiente R è preinstallato con più di 100 pacchetti. Per un elenco completo, vedere la sezione Pacchetti R preinstallati.
È anche possibile aggiungere il codice seguente a qualsiasi componente Execute R Script (Esegui script R) per visualizzare i pacchetti installati.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Nota
Se la pipeline contiene più componenti Execute R Script che richiedono pacchetti che non sono inclusi nell'elenco preinstallato, installare i pacchetti in ogni componente.
Installazione di pacchetti R
Per installare pacchetti R aggiuntivi, usare il install.packages() metodo . I pacchetti vengono installati per ogni componente Execute R Script. Non vengono condivisi tra altri componenti Execute R Script.
Nota
Non è consigliabile installare il pacchetto R dal bundle di script. È consigliabile installare i pacchetti direttamente nell'editor di script.
Specificare il repository CRAN durante l'installazione di pacchetti, ad esempio install.packages("zoo",repos = "https://cloud.r-project.org").
Avviso
Il componente Excute R Script non supporta l'installazione di pacchetti che richiedono la compilazione nativa, ad esempio qdap il pacchetto che richiede JAVA e drc il pacchetto che richiede C++. Questo perché questo componente viene eseguito in un ambiente preinstallato con autorizzazione non amministratore.
Non installare pacchetti predefiniti per Windows, perché i componenti della finestra di progettazione sono in esecuzione in Ubuntu. Per verificare se un pacchetto è predefinito nelle finestre, è possibile passare a CRAN e cercare il pacchetto, scaricare un file binario in base al sistema operativo e selezionare Built: part nel file DESCRIPTION. Di seguito è riportato un esempio: 
Questo esempio illustra come installare Zoo:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Nota
Prima di installare un pacchetto, verificare se esiste già in modo da non ripetere un'installazione. Le installazioni ripetute potrebbero causare il timeout delle richieste del servizio Web.
Accesso al set di dati registrato
È possibile fare riferimento al codice di esempio seguente per accedere ai set di dati registrati nell'area di lavoro:
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Come configurare Execute R Script
Il componente Execute R Script contiene il codice di esempio come punto di partenza.
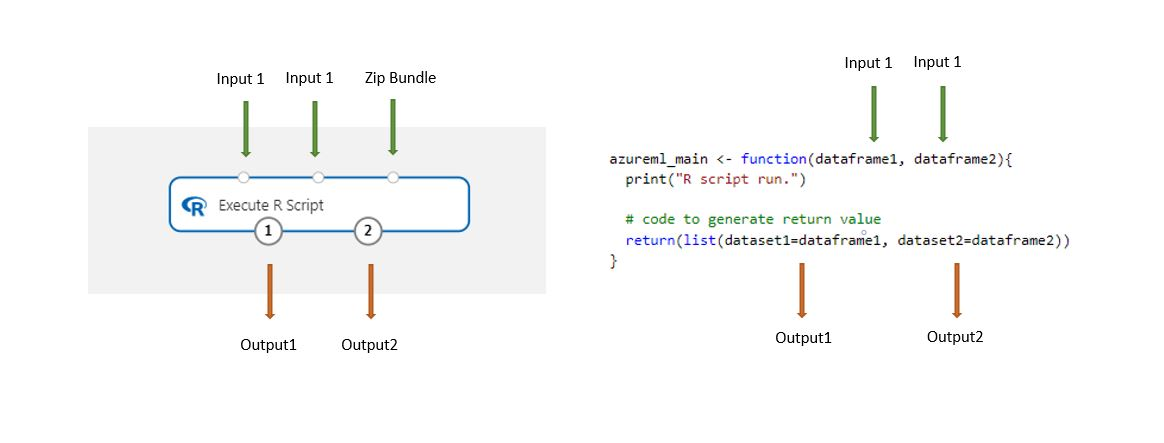
I set di dati archiviati nella finestra di progettazione vengono convertiti automaticamente in un frame di dati R quando viene caricato con questo componente.
Aggiungere il componente Execute R Script (Esegui script R) alla pipeline.
Connettere gli input necessari allo script. Gli input sono facoltativi e possono includere dati e codice R aggiuntivo.
Dataset1: fare riferimento al primo input come
dataframe1. Il set di dati di input deve essere formattato come file CSV, TSV o ARFF. In alternativa, è possibile connettere un set di dati di Azure Machine Learning.Dataset2: fare riferimento al secondo input come
dataframe2. Questo set di dati deve anche essere formattato come file CSV, TSV o ARFF o come set di dati di Azure Machine Learning.Bundle di script: il terzo input accetta .zip file. Un file compresso può contenere più file e più tipi di file.
Nella casella di testo Script R digitare o incollare uno script R valido.
Nota
Prestare attenzione quando si scrive lo script. Assicurarsi che non siano presenti errori di sintassi, ad esempio l'uso di variabili non dichiarate o componenti o funzioni non importanti. Prestare particolare attenzione all'elenco di pacchetti preinstallati alla fine di questo articolo. Per usare pacchetti non elencati, installarli nello script. Un esempio è
install.packages("zoo",repos = "https://cloud.r-project.org").Per iniziare, la casella di testo Script R è prepopolata con il codice di esempio, che è possibile modificare o sostituire.
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }La funzione del punto di ingresso deve avere gli argomenti
Param<dataframe1>di input eParam<dataframe2>, anche quando questi argomenti non vengono usati nella funzione .Nota
Ai dati passati al componente Execute R Script viene fatto riferimento come
dataframe1edataframe2, che è diverso dalla finestra di progettazione di Azure Machine Learning (riferimento alla finestra di progettazione comedataset1,dataset2). Assicurarsi che il riferimento ai dati di input sia corretto nello script.Nota
Il codice R esistente potrebbe richiedere modifiche secondarie da eseguire in una pipeline di progettazione. Ad esempio, i dati di input forniti in formato CSV devono essere convertiti in modo esplicito in un set di dati prima di poterli usare nel codice. I tipi di dati e di colonna usati nel linguaggio R differiscono anche in alcuni modi rispetto ai tipi di dati e di colonna usati nella finestra di progettazione.
Se lo script è maggiore di 16 KB, usare la porta bundle di script per evitare errori come CommandLine supera il limite di 16597 caratteri.
- Aggregare lo script e altre risorse personalizzate a un file ZIP.
- Caricare il file ZIP come set di dati di file nello studio.
- Trascinare il componente del set di dati dall'elenco Set di dati nel riquadro del componente sinistro nella pagina di creazione della finestra di progettazione.
- Connettere il componente del set di dati alla porta bundle script del componente Execute R Script .
Di seguito è riportato il codice di esempio per usare lo script nel bundle di script:
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }Per Valore di inizializzazione casuale immettere un valore da usare all'interno dell'ambiente R come valore di inizializzazione casuale. Questo parametro equivale a chiamare
set.seed(value)nel codice R.Inviare la pipeline.
Risultati
I componenti Execute R Script possono restituire più output, ma devono essere forniti come frame di dati R. La finestra di progettazione converte automaticamente i frame di dati in set di dati per la compatibilità con altri componenti.
I messaggi e gli errori standard di R vengono restituiti al log del componente.
Se è necessario stampare i risultati nello script R, è possibile trovare i risultati stampati in 70_driver_log nella scheda Output e log nel pannello destro del componente.
Script di esempio
Esistono molti modi per estendere la pipeline usando script R personalizzati. Questa sezione fornisce codice di esempio per le attività comuni.
Aggiungere uno script R come input
Il componente Execute R Script supporta i file di script R arbitrari come input. Per usarli, è necessario caricarli nell'area di lavoro come parte del file .zip.
Per caricare un file di .zip che contiene codice R nell'area di lavoro, passare alla pagina asset Set di dati . Selezionare Crea set di dati e quindi selezionare Da file locale e l'opzione Tipo di set di dati file.
Verificare che il file compresso venga visualizzato in My Datasets ( Set di dati personali) nella categoria Set di dati nell'albero dei componenti sinistro.
Connettere il set di dati alla porta di input del bundle di script.
Tutti i file nel file .zip sono disponibili durante l'esecuzione della pipeline.
Se il file bundle di script contiene una struttura di directory, la struttura viene mantenuta. È tuttavia necessario modificare il codice per anteporre la directory ./Script Bundle al percorso.
Elaborazione dei dati
L'esempio seguente illustra come ridimensionare e normalizzare i dati di input:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Leggere un file .zip come input
Questo esempio illustra come usare un set di dati in un file .zip come input per il componente Execute R Script ( Esegui script R).
- Creare il file di dati in formato CSV e denominarlo mydatafile.csv.
- Creare un file .zip e aggiungere il file CSV all'archivio.
- Caricare il file compresso nell'area di lavoro di Azure Machine Learning.
- Connettere il set di dati risultante all'input ScriptBundle del componente Esegui script R.
- Usare il codice seguente per leggere i dati CSV dal file compresso.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
Replicare le righe
Questo esempio illustra come replicare record positivi in un set di dati per bilanciare l'esempio:
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
Passare oggetti R tra i componenti Execute R Script
È possibile passare oggetti R tra istanze del componente Execute R Script usando il meccanismo di serializzazione interno. In questo esempio si presuppone che si voglia spostare l'oggetto R denominato A tra due componenti Execute R Script.
Aggiungere il primo componente Execute R Script (Esegui script R) alla pipeline. Immettere quindi il codice seguente nella casella di testo R Script per creare un oggetto
Aserializzato come colonna nella tabella dei dati di output del componente:azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }La conversione esplicita in tipo integer viene eseguita perché la funzione di serializzazione restituisce dati nel formato R
Raw, che la finestra di progettazione non supporta.Aggiungere una seconda istanza del componente Execute R Script e connetterla alla porta di output del componente precedente.
Digitare il codice seguente nella casella di testo R Script per estrarre l'oggetto
Adalla tabella dei dati di input.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
Pacchetti R preinstallati
Sono attualmente disponibili i pacchetti R preinstallati seguenti:
| Pacchetto | Versione |
|---|---|
| askpass | 1.1 |
| assicura che | 0.2.1 |
| retroportazioni | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| stivale | 1.3-22 |
| Scopa | 0.5.2 |
| chiamante | 3.2.0 |
| Cursore | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| classe | 7.3-15 |
| CLI | 1.1.0 |
| Clipr | 0.6.0 |
| raggruppamento | 2.0.7-1 |
| strumenti per la codifica | 0.2-16 |
| spazio di colore | 1.4-1 |
| compilatore | 3.5.1 |
| pastello | 1.3.4 |
| curva | 3.3 |
| tabella di dati | 1.12.2 |
| Insiemi di dati | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digerire | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| valutare | 0.14 |
| fan | 0.4.0 |
| forzati | 0.3.0 |
| foreach | 1.4.4 |
| straniero | 0.8-71 |
| Fs | 1.3.1 |
| gdata | 2.18.0 |
| elementi generici | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| colla | 1.3.1 |
| Gower | 0.2.1 |
| gnuots | 3.0.1.1 |
| grafica | 3.5.1 |
| grDispositivi | 3.5.1 |
| griglia | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| rifugio | 2.1.0 |
| più alto | 0,8 |
| HMS | 0.4.2 |
| strumenti HTML | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| Iteratori | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| magliare | 1.23 |
| Etichettatura | 0,3 |
| Lattice | 0.20-38 |
| Java | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1,5 |
| Markdown | 1 |
| Massa | 7.3-51.4 |
| Matrice | 1.2-17 |
| metodi | 3.5.1 |
| mgcv | 1.8-28 |
| mimo | 0,7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallelo | 3.5.1 |
| Concetto fondamentale | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| Avanzamento | 1.2.2 |
| P.S. | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| quantimod | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp (una libreria per il linguaggio di programmazione R) | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl (software per leggere documenti Excel) | 1.3.1 |
| ricette | 0.1.5 |
| nuovo incontro | 1.0.1 |
| esempio riproducibile (reprex) | 0.3.0 |
| reshape2 | 1.4.3 |
| reticolate | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0,1 |
| rvest | 0.3.4 |
| Scalabilità | 1.0.0 |
| selettore | 0.4-1 |
| spaziale | 7.3-11 |
| Spline | 3.5.1 |
| SQUAREM | 2017.10-1 |
| statistiche | 3.5.1 |
| statistiche4 | 3.5.1 |
| perizoma | 1.4.3 |
| stringr | 1.3.1 |
| Sopravvivenza | 2.44-1.1 |
| sys | 3.2 |
| tcltk | 3.5.1 |
| Tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| data e ora | 3043.102 |
| tinytex | 0.13 |
| strumenti | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| Utilità | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| baffi | 0,3-2 |
| withr | 2.1.2 |
| xfun | 0,8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| zoo | 1.8-6 |
Passaggi successivi
Vedere il set di componenti disponibili per Azure Machine Learning.