Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive un componente nella finestra di progettazione di Azure Machine Learning. Usare il componente Extract N-Gram Features from Text (Estrai funzionalità N-Gram dal testo) per definire le caratteristiche di testo non strutturate.
Configurazione del componente Extract N-Gram Features from Text
Il componente supporta gli scenari seguenti per l'uso di un dizionario n-gram:
Creare un nuovo dizionario n-gram da una colonna di testo libero.
Usare un set esistente di funzionalità di testo per definire una colonna di testo libero.
Assegnare un punteggio o distribuire un modello che usa n-grammi.
Creare un nuovo dizionario n-gram
Aggiungere il componente Extract N-Gram Features from Text alla pipeline e connettere il set di dati con il testo da elaborare.
Utilizzare La colonna Testo per scegliere una colonna di tipo stringa contenente il testo da estrarre. Poiché i risultati sono verbosi, è possibile elaborare solo una singola colonna alla volta.
Impostare la modalità Vocabolario su Crea per indicare che si sta creando un nuovo elenco di funzionalità n-gram.
Impostare N-Grammi dimensioni per indicare la dimensione massima dei n-grammi da estrarre e archiviare.
Ad esempio, se si immettono 3, unigrammi, bigrams e trigrammi verranno creati.
La funzione di ponderazione specifica come compilare il vettore di funzionalità del documento e come estrarre il vocabolario dai documenti.
Peso binario: assegna un valore di presenza binaria all'estratto n-grammi. Il valore per ogni n-gram è 1 quando esiste nel documento e 0 in caso contrario.
Peso TF: assegna un punteggio di frequenza termini (TF) all'estratto n-grammi. Il valore per ogni n-gram è la frequenza di occorrenza nel documento.
Peso IDF: assegna un punteggio IDF (Inverse Document Frequency) all'estratto n-grammi. Il valore per ogni n-gram è il log delle dimensioni del corpus diviso per la frequenza di occorrenza nell'intero corpus.
IDF = log of corpus_size / document_frequencyTf-IDF Weight (Peso TF-IDF): assegna un punteggio di frequenza/inversa della frequenza dei documenti (TF/IDF) all'estratto n-grammi. Il valore per ogni n-gram è il punteggio TF moltiplicato per il punteggio IDF.
Impostare Lunghezza minima parola sul numero minimo di lettere che possono essere utilizzate in qualsiasi singola parola in un n-gram.
Utilizzare Lunghezza massima parola per impostare il numero massimo di lettere che possono essere utilizzate in qualsiasi singola parola in un n-gram.
Per impostazione predefinita, sono consentiti fino a 25 caratteri per parola o token.
Utilizzare frequenza assoluta minima del documento n-gram per impostare le occorrenze minime necessarie per includere qualsiasi n-gram nel dizionario n-gram.
Ad esempio, se si utilizza il valore predefinito 5, qualsiasi n-gram deve apparire almeno cinque volte nel corpus per essere incluso nel dizionario n-gram.
Impostare Rapporto massimo documento n-gram al rapporto massimo del numero di righe che contengono un particolare n-gram, oltre il numero di righe nel corpus complessivo.
Ad esempio, un rapporto di 1 indica che, anche se un n-gram specifico è presente in ogni riga, il n-gram può essere aggiunto al dizionario n-gram. Più in genere, una parola che si verifica in ogni riga sarebbe considerata una parola non significativa e verrebbe rimossa. Per filtrare le parole non significative dipendenti dal dominio, provare a ridurre questo rapporto.
Importante
La frequenza di occorrenza di parole particolari non è uniforme. Varia da documento a documento. Ad esempio, se si analizzano i commenti dei clienti su un prodotto specifico, il nome del prodotto potrebbe essere molto elevato e vicino a una parola non significativa, ma essere un termine significativo in altri contesti.
Selezionare l'opzione Normalize n-gram feature vectors (Normalizza vettori di funzionalità n-gram) per normalizzare i vettori di funzionalità. Se questa opzione è abilitata, ogni vettore di funzionalità n-gram viene diviso per la norma L2.
Inviare la pipeline.
Usare un dizionario n-gram esistente
Aggiungere il componente Extract N-Gram Features from Text alla pipeline e connettere il set di dati con il testo da elaborare alla porta Dataset .
Utilizzare la colonna Testo per selezionare la colonna di testo contenente il testo da definire. Per impostazione predefinita, il componente seleziona tutte le colonne di tipo string. Per ottenere risultati ottimali, elaborare una singola colonna alla volta.
Aggiungere il set di dati salvato che contiene un dizionario n-gram generato in precedenza e connetterlo alla porta del vocabolario di input. È anche possibile connettere l'output del vocabolario Result di un'istanza upstream del componente Extract N-Gram Features from Text.You can also connect the Result vocabolariy output of an upstream instance of the Extract N-Gram Features from Text component.
Per Modalità vocabolario selezionare l'opzione ReadOnly update dall'elenco a discesa.
L'opzione ReadOnly rappresenta il corpus di input per il vocabolario di input. Anziché calcolare le frequenze dei termini dal nuovo set di dati di testo (nell'input a sinistra), i pesi n-gram dal vocabolario di input vengono applicati così come sono.
Suggerimento
Usare questa opzione quando si classifica un classificatore di testo.
Per tutte le altre opzioni, vedere le descrizioni delle proprietà nella sezione precedente.
Inviare la pipeline.
Creare una pipeline di inferenza che usa n-grammi per distribuire un endpoint in tempo reale
Una pipeline di training che contiene la funzionalità Extract N-Grams From Text and Score Model per eseguire una stima sul set di dati di test, è compilata nella struttura seguente:
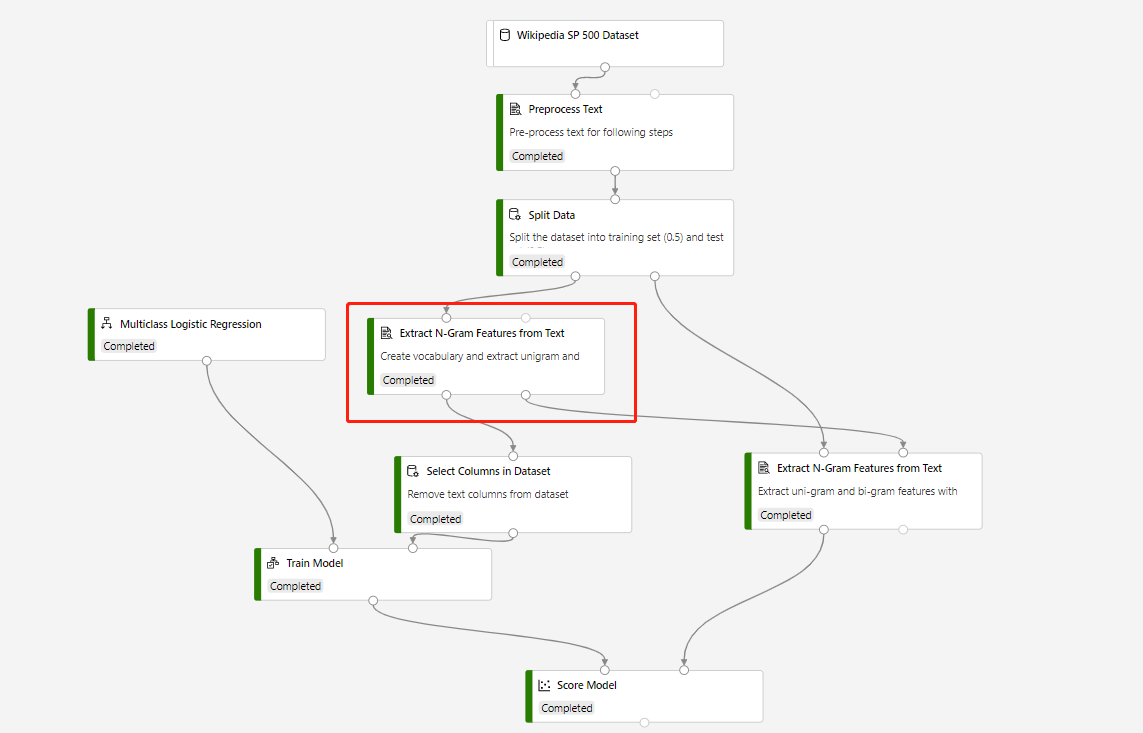
La modalità vocabolario del componente Extract N-Grams Feature From Text cerchiata è Create e la modalità Vocabolario del componente che si connette al componente Score Model è ReadOnly.
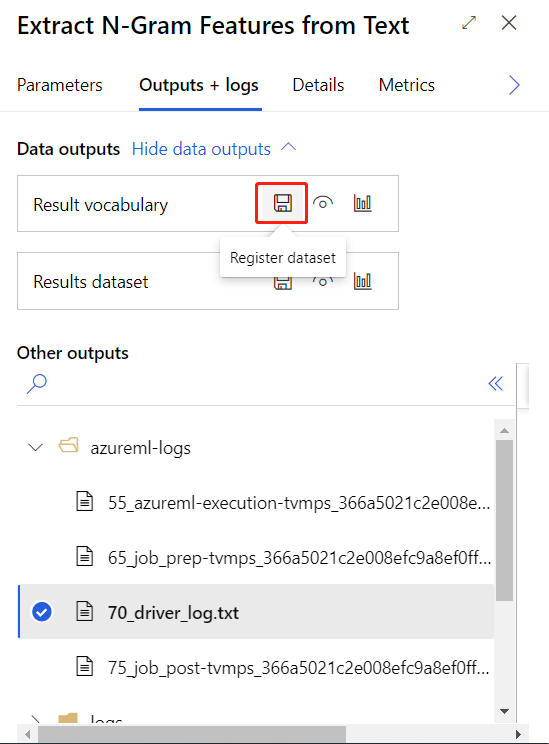
Dopo aver inviato correttamente la pipeline di training precedente, è possibile registrare l'output del componente cerchiato come set di dati.
È quindi possibile creare una pipeline di inferenza in tempo reale. Dopo aver creato la pipeline di inferenza, è necessario modificare manualmente la pipeline di inferenza come segue:
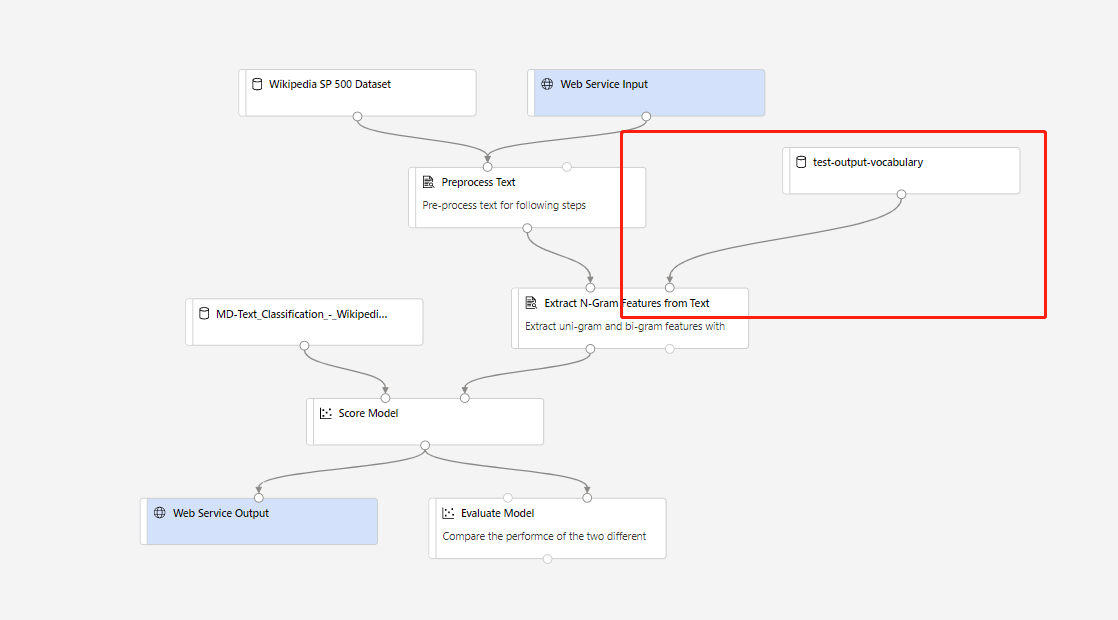
Inviare quindi la pipeline di inferenza e distribuire un endpoint in tempo reale.
Risultati
Il componente Extract N-Gram Features from Text crea due tipi di output:
Set di dati dei risultati: questo output è un riepilogo del testo analizzato combinato con gli n-grammi estratti. Le colonne non selezionate nell'opzione Colonna di testo vengono passate all'output. Per ogni colonna di testo analizzata, il componente genera queste colonne:
- Matrice di occorrenze n-gram: il componente genera una colonna per ogni n-gram trovato nel corpus totale e aggiunge un punteggio in ogni colonna per indicare il peso del n-gram per tale riga.
Vocabolario dei risultati: il vocabolario contiene il dizionario n-gram effettivo, insieme ai punteggi di frequenza dei termini generati come parte dell'analisi. È possibile salvare il set di dati per il riutilizzo con un set diverso di input o per un aggiornamento successivo. È anche possibile riutilizzare il vocabolario per la modellazione e l'assegnazione dei punteggi.
Vocabolario dei risultati
Il vocabolario contiene il dizionario n-gram con i punteggi di frequenza dei termini generati come parte dell'analisi. I punteggi DF e IDF vengono generati indipendentemente dalle altre opzioni.
- ID: identificatore generato per ogni n-gram univoco.
- NGram: n-gram. Gli spazi o altri separatori di parole vengono sostituiti dal carattere di sottolineatura.
- DF: punteggio di frequenza del termine per il n-gram nel corpus originale.
- IDF: punteggio di frequenza del documento inverso per il n-gram nel corpus originale.
È possibile aggiornare manualmente questo set di dati, ma è possibile introdurre errori. Ad esempio:
- Viene generato un errore se il componente trova righe duplicate con la stessa chiave nel vocabolario di input. Assicurarsi che nessuna delle due righe nel vocabolario abbia la stessa parola.
- Lo schema di input dei set di dati del vocabolario deve corrispondere esattamente, inclusi i nomi di colonna e i tipi di colonna.
- La colonna ID e la colonna DF devono essere di tipo integer.
- La colonna IDF deve essere di tipo float.
Nota
Non connettere direttamente l'output dei dati al componente Train Model.Don't connect the data output to the Train Model component directly. È consigliabile rimuovere colonne di testo libero prima che vengano inserite nel modello di training. In caso contrario, le colonne di testo libero verranno considerate come funzionalità categoriche.
Passaggi successivi
Vedere il set di componenti disponibili per Azure Machine Learning.