Componente di partizione e di esempio
Questo articolo descrive un componente nella finestra di progettazione di Azure Machine Learning.
Usare il componente Partition and Sample per eseguire il campionamento in un set di dati o per creare partizioni dal set di dati.
Il campionamento è uno strumento importante nell'apprendimento automatico perché consente di ridurre le dimensioni di un set di dati mantenendo allo stesso tempo lo stesso rapporto di valori. Questo componente supporta diverse attività correlate importanti in Machine Learning:
Divisione dei dati in più sottosezioni della stessa dimensione.
È possibile usare le partizioni per la convalida incrociata o per assegnare casi a gruppi casuali.
Separazione dei dati in gruppi e utilizzo dei dati da un gruppo specifico.
Dopo aver assegnato in modo casuale i case a gruppi diversi, potrebbe essere necessario modificare le funzionalità associate a un solo gruppo.
Campionamento.
È possibile estrarre una percentuale dei dati, applicare il campionamento casuale o scegliere una colonna da usare per bilanciare il set di dati ed eseguire il campionamento stratificato sui relativi valori.
Creazione di un set di dati più piccolo per il test.
Se si dispone di molti dati, è possibile usare solo le prime n righe durante la configurazione della pipeline e quindi passare all'uso del set di dati completo quando si compila il modello. È anche possibile usare il campionamento per creare un set di dati più piccolo da usare in fase di sviluppo.
Configurare il componente
Questo componente supporta i metodi seguenti per dividere i dati in partizioni o per il campionamento. Scegliere prima il metodo e quindi impostare opzioni aggiuntive richieste dal metodo.
- Head
- Campionamento
- Assegna a pieghe
- Selezione piega
Ottenere le righe TOP N da un set di dati
Usare questa modalità per ottenere solo le prime n righe. Questa opzione è utile se si vuole testare una pipeline su un numero ridotto di righe e non è necessario che i dati vengano bilanciati o campionati in alcun modo.
Aggiungere il componente Partition and Sample alla pipeline nell'interfaccia e connettere il set di dati.
Modalità di partizione o di esempio: impostare questa opzione su Head.
Numero di righe da selezionare: immettere il numero di righe da restituire.
Il numero di righe deve essere un numero intero non negativo. Se il numero di righe selezionate è maggiore del numero di righe nel set di dati, viene restituito l'intero set di dati.
Inviare la pipeline.
Il componente restituisce un singolo set di dati che contiene solo il numero specificato di righe. Le righe vengono sempre lette dalla parte superiore del set di dati.
Creare un esempio di dati
Questa opzione supporta il campionamento casuale semplice o il campionamento casuale stratificato. È utile se si vuole creare un set di dati di esempio rappresentativo più piccolo per il test.
Aggiungere il componente Partition and Sample alla pipeline e connettere il set di dati.
Modalità di partizione o di esempio: impostare questa opzione su Campionamento.
Frequenza di campionamento: immettere un valore compreso tra 0 e 1. questo valore specifica la percentuale di righe del set di dati di origine che deve essere incluso nel set di dati di output.
Ad esempio, se si vuole solo metà del set di dati originale, immettere
0.5per indicare che la frequenza di campionamento deve essere del 50%.Le righe del set di dati di input vengono inserite in modo casuale e selettivo nel set di dati di output, in base al rapporto specificato.
Valore di inizializzazione casuale per il campionamento: facoltativamente, immettere un numero intero da usare come valore di inizializzazione.
Questa opzione è importante se si desidera che le righe vengano divise allo stesso modo ogni volta. Il valore predefinito è 0, vale a dire che viene generato un valore di inizializzazione in base all'orologio di sistema. Questo valore può portare a risultati leggermente diversi ogni volta che si esegue la pipeline.
Suddivisione stratificata per il campionamento: selezionare questa opzione se è importante che le righe nel set di dati vengano divise in modo uniforme per alcune colonne chiave prima del campionamento.
Per La colonna chiave di stratificazione per il campionamento, selezionare una singola colonna strata da usare durante la divisione del set di dati. Le righe nel set di dati vengono quindi divise nel modo seguente:
Tutte le righe di input vengono raggruppate (stratificate) in base ai valori nella colonna strata specificata.
Le righe vengono casuali all'interno di ogni gruppo.
Ogni gruppo viene aggiunto in modo selettivo al set di dati di output per soddisfare il rapporto specificato.
Inviare la pipeline.
Con questa opzione, il componente restituisce un singolo set di dati che contiene un campionamento rappresentativo dei dati. La parte rimanente non sottoposta aampling del set di dati non viene restituita.
Suddividere i dati in partizioni
Usare questa opzione quando si vuole dividere il set di dati in subset dei dati. Questa opzione è utile anche quando si desidera creare un numero personalizzato di riduzioni per la convalida incrociata o suddividere le righe in più gruppi.
Aggiungere il componente Partition and Sample alla pipeline e connettere il set di dati.
Per Partizione o modalità di esempio selezionare Assegna a pieghe.
Usare la sostituzione nel partizionamento: selezionare questa opzione se si desidera che la riga campionata venga reinvertita nel pool di righe per un potenziale riutilizzo. Di conseguenza, la stessa riga potrebbe essere assegnata a diverse riduzioni.
Se non si usa la sostituzione (opzione predefinita), la riga campionata non viene inserita nel pool di righe per un potenziale riutilizzo. Di conseguenza, ogni riga può essere assegnata a una sola piega.
Suddivisione casuale: selezionare questa opzione se si desidera che le righe vengano assegnate in modo casuale alle riduzioni.
Se non si seleziona questa opzione, le righe vengono assegnate alle riduzioni tramite il metodo round robin.
Valore di inizializzazione casuale: facoltativamente, immettere un numero intero da usare come valore di inizializzazione. Questa opzione è importante se si desidera che le righe vengano divise allo stesso modo ogni volta. In caso contrario, il valore predefinito 0 indica che verrà usato un valore di inizializzazione iniziale casuale.
Specificare il metodo partitioner: indicare come si desidera che i dati vengano ripartiti in ogni partizione usando queste opzioni:
Partizione in modo uniforme: usare questa opzione per inserire un numero uguale di righe in ogni partizione. Per specificare il numero di partizioni di output, immettere un numero intero nella casella Specificare il numero di riduzioni da suddividere in modo uniforme.
Partizione con proporzioni personalizzate: usare questa opzione per specificare le dimensioni di ogni partizione come elenco delimitato da virgole.
Si supponga, ad esempio, di voler creare tre partizioni. La prima partizione conterrà il 50% dei dati. Le due partizioni rimanenti conterranno ognuna il 25% dei dati. Nella casella Elenco di proporzioni separate da virgola immettere i numeri seguenti: .5, .25, .25.
La somma di tutte le dimensioni delle partizioni deve essere aggiunta esattamente a 1.
Se si immettono numeri che aggiungono fino a meno di 1, viene creata una partizione aggiuntiva per contenere le righe rimanenti. Ad esempio, se si immettono i valori 2 e 3, viene creata una terza partizione per contenere il 50% rimanente di tutte le righe.
Se si immettono numeri che aggiungono fino a più di 1, viene generato un errore quando si esegue la pipeline.
Suddivisione stratificata: selezionare questa opzione se si desidera che le righe vengano stratificate durante la suddivisione e quindi scegliere la colonna strata.
Inviare la pipeline.
Con questa opzione, il componente restituisce più set di dati. I set di dati vengono partizionati in base alle regole specificate.
Usare i dati da una partizione predefinita
Usare questa opzione quando un set di dati è stato diviso in più partizioni e ora si vuole caricare ogni partizione a sua volta per un'ulteriore analisi o elaborazione.
Aggiungere il componente Partition e Sample alla pipeline.
Connettere il componente all'output di un'istanza precedente di Partition e Sample. L'istanza deve avere utilizzato l'opzione Assegna a riduzioni per generare un numero di partizioni.
Modalità di partizione o di esempio: selezionare Seleziona piega.
Specificare la piega da cui eseguire il campionamento: selezionare una partizione da usare immettendone l'indice. Gli indici di partizione sono basati su 1. Ad esempio, se si divide il set di dati in tre parti, le partizioni avranno gli indici 1, 2 e 3.
Se si immette un valore di indice non valido, viene generato un errore in fase di progettazione: "Errore 0018: Il set di dati contiene dati non validi".
Oltre a raggruppare il set di dati in base alle riduzioni, è possibile separare il set di dati in due gruppi: una riduzione di destinazione e tutto il resto. A tale scopo, immettere l'indice di una singola piega e quindi selezionare l'opzione Seleziona complemento della piega selezionata per ottenere tutto, ma i dati nella piega specificata.
Se si usano più partizioni, è necessario aggiungere altre istanze del componente Partition and Sample per gestire ogni partizione.
Ad esempio, il componente Partition and Sample nella seconda riga è impostato su Assign to Folds e il componente nella terza riga è impostato su Pick Fold.
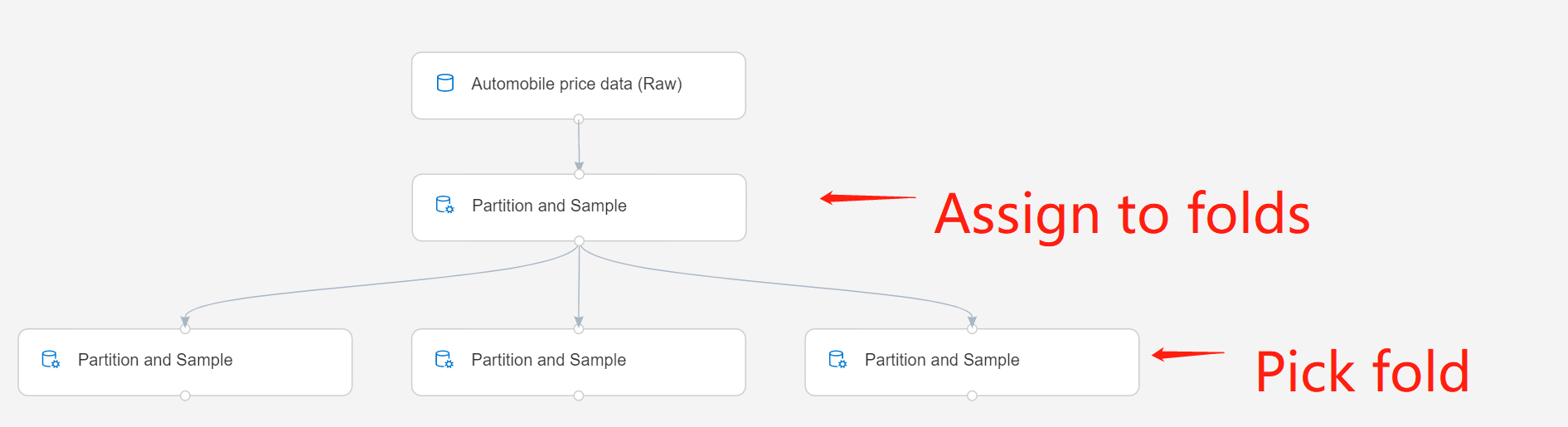
Inviare la pipeline.
Con questa opzione, il componente restituisce un singolo set di dati che contiene solo le righe assegnate a tale riduzione.
Nota
Non è possibile visualizzare direttamente le designazioni delle riduzioni. Sono presenti solo nei metadati.
Passaggi successivi
Vedere il set di componenti disponibili per Azure Machine Learning.