Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive un componente nella finestra di progettazione di Azure Machine Learning.
Usare il componente Pre-elaborazione testo per pulire e semplificare il testo. Supporta queste operazioni comuni di elaborazione del testo:
- Rimozione di parole non significative
- Uso di espressioni regolari per cercare e sostituire stringhe di destinazione specifiche
- Lemmatizzazione, che converte più parole correlate in un'unica forma canonica
- Normalizzazione maiuscole/minuscole
- Rimozione di determinate classi di caratteri, ad esempio numeri, caratteri speciali e sequenze di caratteri ripetuti, ad esempio "aaaa"
- Identificazione e rimozione di messaggi di posta elettronica e URL
Il componente Pre-elaborazione testo supporta attualmente solo l'inglese.
Configurare la pre-elaborazione del testo
Aggiungere il componente Testo pre-elaborazione alla pipeline in Azure Machine Learning. È possibile trovare questo componente in Analisi del testo.
Connettere un set di dati con almeno una colonna contenente testo.
Selezionare la lingua dall'elenco a discesa Lingua .
Colonna di testo da pulire: selezionare la colonna da pre-elaborare.
Rimuovi parole non significative: selezionare questa opzione se si desidera applicare un elenco di parole non significative predefinito alla colonna di testo.
Gli elenchi di parole non significative sono dipendenti dalla lingua e personalizzabili.
Lemmatization: selezionare questa opzione se si desidera che le parole vengano rappresentate nel formato canonico. Questa opzione è utile per ridurre il numero di occorrenze univoche di token di testo altrimenti simili.
Il processo di lemmatizzazione è altamente dipendente dal linguaggio.
Rileva frasi: selezionare questa opzione se si vuole che il componente inserisca un contrassegno limite di frase durante l'esecuzione dell'analisi.
Questo componente usa una serie di tre caratteri
|||pipe per rappresentare il carattere di terminazione della frase.Eseguire operazioni di ricerca e sostituzione facoltative usando espressioni regolari. L'espressione regolare verrà elaborata in un primo momento, prima di tutte le altre opzioni predefinite.
- Espressione regolare personalizzata: definire il testo che si sta cercando.
- Stringa di sostituzione personalizzata: definire un singolo valore di sostituzione.
Normalizzare maiuscole in minuscolo: selezionare questa opzione se si desidera convertire i caratteri maiuscoli ASCII nelle forme minuscole.
Se i caratteri non sono normalizzati, la stessa parola in lettere maiuscole e minuscole viene considerata due parole diverse.
È anche possibile rimuovere i tipi di caratteri o sequenze di caratteri seguenti dal testo di output elaborato:
Rimuovi numeri: selezionare questa opzione per rimuovere tutti i caratteri numerici per la lingua specificata. I numeri di identificazione sono dipendenti dal dominio e dipendenti dalla lingua. Se i caratteri numerici sono parte integrante di una parola nota, il numero potrebbe non essere rimosso. Per altre informazioni, vedere Note tecniche.
Rimuovi caratteri speciali: usare questa opzione per rimuovere tutti i caratteri speciali non alfanumerici.
Rimuovi caratteri duplicati: selezionare questa opzione per rimuovere caratteri aggiuntivi in qualsiasi sequenza ripetuta per più di due volte. Ad esempio, una sequenza come "aaaaa" verrebbe ridotta a "aa".
Rimuovi indirizzi di posta elettronica: selezionare questa opzione per rimuovere qualsiasi sequenza del formato
<string>@<string>.Rimuovi URL: selezionare questa opzione per rimuovere qualsiasi sequenza che includa i prefissi URL seguenti:
http,https,ftp,www
Espandi le contrazioni verbo: questa opzione si applica solo alle lingue che usano contrazioni verbo, attualmente solo inglese.
Selezionando questa opzione, ad esempio, è possibile sostituire la frase "would't stay there" con "would not stay there".
Normalizzare le barre rovesciata per le barre: selezionare questa opzione per eseguire il mapping di tutte le istanze di
\\a/.Suddividere i token in caratteri speciali: selezionare questa opzione se si desidera interrompere le parole sui caratteri, ad
&esempio ,-e così via. Questa opzione può anche ridurre i caratteri speciali quando si ripete più di due volte.Ad esempio, la stringa
MS---WORDverrà separata in tre token,MS,-eWORD.Inviare la pipeline.
Note tecniche
Il componente preprocess-text in Studio (versione classica) e la finestra di progettazione usano modelli linguistici diversi. La finestra di progettazione usa un modello con training CNN con più attività da spaCy. I diversi modelli offrono tokenizer e tagger part-of-speech diversi, che portano a risultati diversi.
Ecco alcuni esempi:
| Impostazione | Risultato dell'output |
|---|---|
| Con tutte le opzioni selezionate Spiegazione: per i casi come "3test" nel "WC-3 3test 4test", la finestra di progettazione rimuove l'intera parola "3test", poiché in questo contesto, il tagger part-of-speech specifica questo token "3test" come numerale e, in base alla parte del parlato, il componente lo rimuove. |
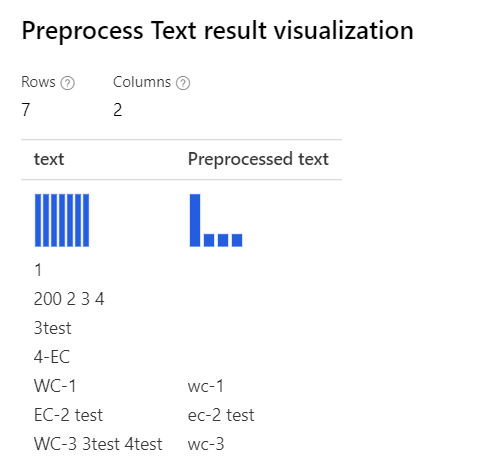
|
Con solo Removing number spiegazione selezionata : per i casi come "3test", "4-EC", la dose del tokenizer della finestra di progettazione non suddivide questi casi e li considera come interi token. Quindi non rimuoverà i numeri in queste parole. |

|
È anche possibile usare l'espressione regolare per restituire risultati personalizzati:
| Impostazione | Risultato dell'output |
|---|---|
| Con tutte le opzioni selezionate Espressione regolare personalizzata: (\s+)*(-|\d+)(\s+)*stringa di sostituzione personalizzata: \1 \2 \3 |

|
Con solo Removing number l'opzione Espressione regolare personalizzata selezionata : (\s+)*(-|\d+)(\s+)*Stringa di sostituzione personalizzata: \1 \2 \3 |
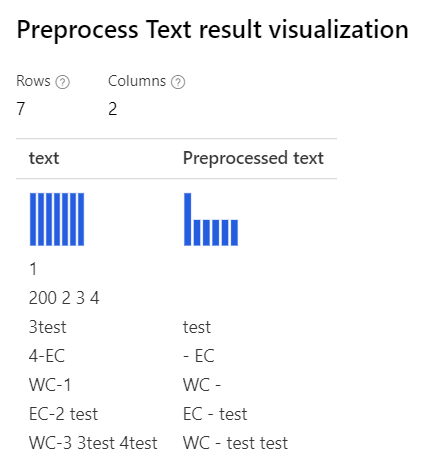
|
Passaggi successivi
Vedere il set di componenti disponibili per Azure Machine Learning.