Data science con Data Science Virtual Machine per Ubuntu in Azure
Questa procedura dettagliata illustra come eseguire diverse attività comuni di data science tramite la Data Science Virtual Machine (DSVM) per Ubuntu. La DSVM per Ubuntu è un'immagine di macchina virtuale disponibile in Azure che è preinstallata con una raccolta di strumenti usati comunemente per analisi dei dati e l'apprendimento automatico. I componenti software principali sono elencati in Effettuare il provisioning della Data Science Virtual Machine per Ubuntu. L'immagine DSVM consente di iniziare le attività di data science in pochi minuti, senza dover installare e configurare ogni strumento singolarmente. Se necessario, è possibile aumentare facilmente le prestazioni della DSVM e arrestarla quando non è in uso. La risorsa DSVM è sia flessibile che conveniente.
Questa procedura dettagliata illustra il set di dati spambase. Spambase è un set di messaggi di posta elettronica contrassegnati come posta indesiderata o non indesiderata. Contiene anche alcune statistiche sul contenuto dei messaggi di posta elettronica. Le statistiche verranno illustrate più avanti nella procedura dettagliata.
Prerequisiti
Per poter usare una DVSM per Linux, è necessario soddisfare i prerequisiti seguenti:
Sottoscrizione di Azure. Per ottenere una sottoscrizione di Azure, vedere Crea subito il tuo account Azure gratuito.
Data Science Virtual Machine per Ubuntu. Per informazioni sul provisioning della macchina virtuale, vedere Effettuare il provisioning della Data Science Virtual Machine per Linux.
X2Go installato nel computer con una sessione di XFCE aperta. Per altre informazioni, vedere Installare e configurare il client X2Go.
Scaricare il set di dati spambase
Il set di dati spambase è un set di dati relativamente piccolo che contiene 4.601 esempi. Grazie alle dimensioni ridotte, il set di dati può essere usato per dimostrare alcune delle funzionalità principali della DSVM, perché i requisiti in termini di risorse rimangono contenuti.
Nota
Questa procedura dettagliata è stata creata con una DSVM per Linux di dimensioni D2 v2. Per completare le procedure illustrate, è possibile usare una DSVM di queste dimensioni.
Se è necessario più spazio di archiviazione, è possibile creare altri dischi e collegarli alla DSVM. Poiché questi dischi usano l'archiviazione di Azure persistente, i relativi dati vengono conservati anche se il server viene arrestato o sottoposto a un nuovo provisioning in seguito a un ridimensionamento. Per aggiungere un disco e collegarlo alla DSVM, seguire la procedura illustrata in Aggiungere un disco a una VM Linux. Nella procedura per l'aggiunta di un disco viene usata l'interfaccia della riga di comando di Azure, già installata nella DSVM. È possibile completare la procedura interamente dalla DSVM stessa. Per aumentare lo spazio di archiviazione, è anche possibile usare File di Azure.
Per scaricare i dati, aprire una finestra del terminale e quindi eseguire questo comando:
wget --no-check-certificate https://archive.ics.uci.edu/ml/machine-learning-databases/spambase/spambase.data
Il file scaricato non contiene una riga di intestazione. Viene ora creato un altro file che contiene un'intestazione. Eseguire questo comando per creare un file con le intestazioni appropriate:
echo 'word_freq_make, word_freq_address, word_freq_all, word_freq_3d,word_freq_our, word_freq_over, word_freq_remove, word_freq_internet,word_freq_order, word_freq_mail, word_freq_receive, word_freq_will,word_freq_people, word_freq_report, word_freq_addresses, word_freq_free,word_freq_business, word_freq_email, word_freq_you, word_freq_credit,word_freq_your, word_freq_font, word_freq_000, word_freq_money,word_freq_hp, word_freq_hpl, word_freq_george, word_freq_650, word_freq_lab,word_freq_labs, word_freq_telnet, word_freq_857, word_freq_data,word_freq_415, word_freq_85, word_freq_technology, word_freq_1999,word_freq_parts, word_freq_pm, word_freq_direct, word_freq_cs, word_freq_meeting,word_freq_original, word_freq_project, word_freq_re, word_freq_edu,word_freq_table, word_freq_conference, char_freq_semicolon, char_freq_leftParen,char_freq_leftBracket, char_freq_exclamation, char_freq_dollar, char_freq_pound, capital_run_length_average,capital_run_length_longest, capital_run_length_total, spam' > headers
Concatenare quindi i due file:
cat spambase.data >> headers
mv headers spambaseHeaders.data
Il set di dati include diversi tipi di statistiche per ogni messaggio di posta elettronica:
- Le colonne come word_freq_WORD indicano la percentuale di parole nel messaggio di posta elettronica che corrisponde a WORD. Se ad esempio word_freq_make è 1, l'1% di tutte le parole nel messaggio di posta elettronica era costituito dalla parola make.
- Le colonne come char_freq_CHAR indicano la percentuale di caratteri CHAR nel messaggio di posta elettronica.
- capital_run_length_longest è la lunghezza massima di una sequenza di lettere maiuscole.
- capital_run_length_average è la lunghezza media di tutte le sequenze di lettere maiuscole.
- capital_run_length_total è la lunghezza totale di tutte le sequenze di lettere maiuscole.
- spam indica se il messaggio di posta elettronica è stato considerato posta indesiderata o meno: 1 = posta indesiderata, 0 = posta non indesiderata.
Esplorare il set di dati tramite R Open
Si procederà ora all'esame dei dati e all'esecuzione di alcune attività di apprendimento automatico di base utilizzando R. La DSVM viene fornita con CRAN R preinstallato.
Per ottenere copie degli esempi di codice usati in questa procedura dettagliata, clonare il repository Azure-Machine-Learning-Data-Science usando Git, che è preinstallato nella DSVM. Dalla riga di comando di Git, eseguire:
git clone https://github.com/Azure/Azure-MachineLearning-DataScience.git
Aprire una finestra del terminale e avviare una nuova sessione di R nella console interattiva di R. Per importare i dati e configurare l'ambiente:
data <- read.csv("spambaseHeaders.data")
set.seed(123)
Per visualizzare le statistiche di riepilogo relative a ogni colonna, usare:
summary(data)
Per una visualizzazione diversa dei dati, usare:
str(data)
Questa visualizzazione mostra il tipo di ogni variabile e i primi valori nel set di dati.
La colonna spam è stata letta come Integer, ma in realtà si tratta di un fattore o una variabile categorica. Per impostarne il tipo, usare:
data$spam <- as.factor(data$spam)
Per effettuare alcune analisi esplorative, usare il pacchetto ggplot2, una libreria grafica per R molto diffusa preinstallata nella DSVM. In base ai dati di riepilogo visualizzati in precedenza, sono disponibili statistiche di riepilogo sulla frequenza del carattere punto esclamativo. I comandi seguenti consentono di tracciare tali frequenze:
library(ggplot2)
ggplot(data) + geom_histogram(aes(x=char_freq_exclamation), binwidth=0.25)
Per eliminare l'alterazione causata dalla barra dello zero, usare:
email_with_exclamation = data[data$char_freq_exclamation > 0, ]
ggplot(email_with_exclamation) + geom_histogram(aes(x=char_freq_exclamation), binwidth=0.25)
La densità non semplice superiore a 1 sembra interessante. Per esaminare solo quei dati, eseguire:
ggplot(data[data$char_freq_exclamation > 1, ]) + geom_histogram(aes(x=char_freq_exclamation), binwidth=0.25)
Per dividere quindi i dati in posta indesiderata e non indesiderata, eseguire:
ggplot(data[data$char_freq_exclamation > 1, ], aes(x=char_freq_exclamation)) +
geom_density(lty=3) +
geom_density(aes(fill=spam, colour=spam), alpha=0.55) +
xlab("spam") +
ggtitle("Distribution of spam \nby frequency of !") +
labs(fill="spam", y="Density")
Questi esempi consentono di creare tracciati simili ed esplorare i dati nelle altre colonne.
Eseguire il training e il test di un modello di Machine Learning
Si procederà ora a eseguire il training di un paio di modelli di Machine Learning per classificare i messaggi di posta elettronica nel set di dati come posta indesiderata o non indesiderata. In questa sezione si eseguirà il training di un modello di albero delle decisioni e di un modello di foresta casuale. Verrà quindi eseguito il test dell'accuratezza delle stime.
Nota
Il pacchetto rpart (Recursive Partitioning and Regression Trees, partizionamento ricorsivo e alberi di regressione) usato nel codice seguente è già installato nella DSVM.
Dividere prima di tutto il set di dati in set di training e set di test:
rnd <- runif(dim(data)[1])
trainSet = subset(data, rnd <= 0.7)
testSet = subset(data, rnd > 0.7)
Creare quindi un albero delle decisioni per classificare i messaggi di posta elettronica:
require(rpart)
model.rpart <- rpart(spam ~ ., method = "class", data = trainSet)
plot(model.rpart)
text(model.rpart)
Il risultato è il seguente:
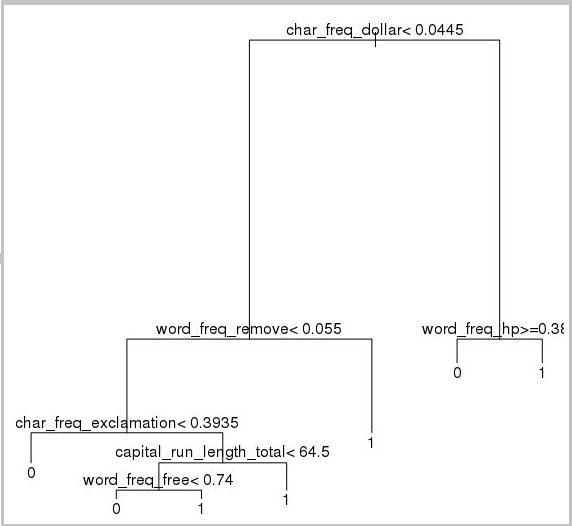
Per determinarne le prestazioni sul set di training, usare il codice seguente:
trainSetPred <- predict(model.rpart, newdata = trainSet, type = "class")
t <- table(`Actual Class` = trainSet$spam, `Predicted Class` = trainSetPred)
accuracy <- sum(diag(t))/sum(t)
accuracy
Per determinarne le prestazioni sul set di test, eseguire:
testSetPred <- predict(model.rpart, newdata = testSet, type = "class")
t <- table(`Actual Class` = testSet$spam, `Predicted Class` = testSetPred)
accuracy <- sum(diag(t))/sum(t)
accuracy
Viene ora esaminato un modello di foresta casuale. Le foreste casuali consentono di eseguire il training di numerosi alberi delle decisioni e restituiscono una classe che rappresenta la modalità delle classificazioni da tutti i singoli alberi delle decisioni. Offrono un approccio di Machine Learning più efficace perché compensano la tendenza all'overfitting del set di dati di training da parte del modello di albero delle decisioni.
require(randomForest)
trainVars <- setdiff(colnames(data), 'spam')
model.rf <- randomForest(x=trainSet[, trainVars], y=trainSet$spam)
trainSetPred <- predict(model.rf, newdata = trainSet[, trainVars], type = "class")
table(`Actual Class` = trainSet$spam, `Predicted Class` = trainSetPred)
testSetPred <- predict(model.rf, newdata = testSet[, trainVars], type = "class")
t <- table(`Actual Class` = testSet$spam, `Predicted Class` = testSetPred)
accuracy <- sum(diag(t))/sum(t)
accuracy
Esercitazioni e procedure dettagliate di Deep Learning
Oltre a esempi basati su framework, viene fornito anche un set di procedure dettagliate complete. Queste procedure dettagliate consentono di iniziare subito a sviluppare applicazioni di apprendimento avanzato in domini come la comprensione delle immagini e del linguaggio/testo.
Esecuzione di reti neurali in diversi framework: procedura dettagliata completa che illustra come eseguire la migrazione del codice da un framework a un altro. Illustra anche come confrontare le prestazioni del modello e di runtime fra i framework.
Guida dettagliata alla creazione di una soluzione end-to-end per individuare prodotti all'interno di immagini: il rilevamento di immagini è una tecnica che consente di individuare e classificare gli oggetti all'interno delle immagini. Questa tecnologia può offrire enormi vantaggi per molte applicazioni aziendali reali. Ad esempio, i negozianti possono usare questa tecnica per determinare quale prodotto un cliente ha prelevato dallo scaffale. Queste informazioni a loro volta consentono ai negozi di gestire l'inventario dei prodotti.
Deep learning per audio: questa esercitazione illustra come eseguire il training di un modello di deep learning per il rilevamento di eventi audio nel set di dati Urban Sounds. Nell'esercitazione viene fornita una panoramica su come usare i dati audio.
Classificazione di documenti di testo: questa procedura dettagliata illustra come creare ed eseguire il training di due architetture di rete neurale differenti: rete Hierarchical Attention Network e Long Short Term Memory (LSTM). Queste reti neurali usano l'API Keras per l'apprendimento avanzato per classificare i documenti di testo. Keras è un front-end a tre dei più popolari framework di apprendimento avanzato: Microsoft Cognitive Toolkit, TensorFlow e Theano.
Altri strumenti
Le sezioni rimanenti illustrano come usare alcuni degli strumenti installati nella DSVM per Linux. Verranno descritti gli strumenti seguenti:
- XGBoost
- Python
- JupyterHub
- Rattle
- PostgreSQL e SQuirrel SQL
- Azure Synapse Analytics (in precedenza SQL DW)
XGBoost
XGBoost consente un'implementazione di albero con boosting rapida e accurata.
require(xgboost)
data <- read.csv("spambaseHeaders.data")
set.seed(123)
rnd <- runif(dim(data)[1])
trainSet = subset(data, rnd <= 0.7)
testSet = subset(data, rnd > 0.7)
bst <- xgboost(data = data.matrix(trainSet[,0:57]), label = trainSet$spam, nthread = 2, nrounds = 2, objective = "binary:logistic")
pred <- predict(bst, data.matrix(testSet[, 0:57]))
accuracy <- 1.0 - mean(as.numeric(pred > 0.5) != testSet$spam)
print(paste("test accuracy = ", accuracy))
Questo strumento consente anche di eseguire chiamate da Python o da una riga di comando.
Python
Per lo sviluppo tramite Python, sono installate le distribuzioni Anaconda Python 3.5 e 2.7 nella DSVM.
Nota
La distribuzione Anaconda include Conda. È possibile usare Conda per creare ambienti Python personalizzati con versioni o pacchetti diversi installati.
Leggere una parte del set di dati spambase e classificare i messaggi di posta elettronica con macchine a vettori di supporto in Scikit-learn:
import pandas
from sklearn import svm
data = pandas.read_csv("spambaseHeaders.data", sep = ',\s*')
X = data.ix[:, 0:57]
y = data.ix[:, 57]
clf = svm.SVC()
clf.fit(X, y)
Per eseguire previsioni, usare:
clf.predict(X.ix[0:20, :])
Per illustrare come pubblicare un endpoint di Azure Machine Learning, verrà creato un modello più semplice. Verranno usate le tre variabili usate quando è stato pubblicato il modello R in precedenza:
X = data[["char_freq_dollar", "word_freq_remove", "word_freq_hp"]]
y = data.ix[:, 57]
clf = svm.SVC()
clf.fit(X, y)
JupyterHub
La distribuzione Anaconda nella DSVM include Jupyter Notebook, un ambiente multipiattaforma per la condivisione di codice e analisi Python, R o Julia. Jupyter Notebook è accessibile tramite JupyterHub. Per eseguire l'accesso, usare il nome utente e la password Linux locali all'indirizzo https://<Nome DNS o indirizzo IP della DSVM>:8000/. Tutti i file di configurazione per JupyterHub si trovano in/etc/jupyterhub.
Nota
Per usare Python Package Manager (tramite il comando pip) da Jupyter Notebook nel kernel corrente, usare il comando seguente nella cella di codice:
import sys
! {sys.executable} -m pip install numpy -y
Per usare il programma di installazione di Conda (tramite il comando conda) da Jupyter Notebook nel kernel corrente, usare il comando seguente in una cella di codice:
import sys
! {sys.prefix}/bin/conda install --yes --prefix {sys.prefix} numpy
Nella DSVM sono già installati diversi notebook di esempio:
- Notebook di Python di esempio:
- Notebook R di esempio:
Nota
Il linguaggio Julia è disponibile anche dalla riga di comando nella DSVM per Linux.
Rattle
Rattle (RAnalytical Tool To Learn Easily) è uno strumento grafico di R per il data mining. È dotato di un'interfaccia intuitiva che consente di caricare, esplorare e trasformare i dati e di creare e valutare i modelli. Rattle: A Data Mining GUI for R (Rattle: un'interfaccia utente grafica di data mining per R) fornisce una procedura dettagliata di dimostrazione delle funzionalità di Rattle.
Installare e avviare Rattle eseguendo questi comandi:
if(!require("rattle")) install.packages("rattle")
require(rattle)
rattle()
Nota
Non è necessario installare Rattle nella DSVM. Potrebbe essere richiesto tuttavia di installare pacchetti aggiuntivi quando si apre Rattle.
Rattle usa un'interfaccia basata su schede. La maggior parte delle schede corrisponde ai passaggi del Processo Team Data Science, come il caricamento o l'esplorazione dei dati. Il processo di analisi scientifica dei dati va da sinistra a destra nelle schede, con l'ultima scheda che contiene un log dei comandi R eseguiti da Rattle.
Per caricare e configurare il set di dati:
- Per caricare il file, selezionare la scheda Data (Dati).
- Fare clic sul selettore accanto a Filename (Nome file) e quindi selezionare spambaseHeaders.data.
- Per caricare il file, Selezionare Esegui. Verrà visualizzato un riepilogo di ogni colonna, incluso il tipo di dati identificato, se si tratta di un input, una destinazione o un altro tipo di variabile e il numero di valori univoci.
- Rattle ha identificato correttamente la colonna spam come destinazione. Selezionare la colonna spam e quindi impostare Target Data Type (Tipo di dati di destinazione) su Categoric (Categorico).
Per esplorare i dati:
- Selezionare la scheda Explore (Esplora).
- Fare clic su Summary (Riepilogo)>Execute (Esegui) per visualizzare alcune informazioni sui tipi di variabili e le statistiche di riepilogo.
- Per visualizzare altri tipi di statistiche sulle singole variabili, selezionare altre opzioni, ad esempio Describe (Descrizione) o Basics (Informazioni di base).
È anche possibile usare la scheda Explore (Esplora) per generare tracciati dettagliati. Per tracciare un istogramma dei dati:
- Scegliere Distributions(Distribuzioni).
- Per word_freq_remove e word_freq_you, selezionare Histogram (Istogramma).
- Seleziona Execute. Entrambi i tracciati di densità verranno visualizzati in un'unica area grafica, in cui appare chiaro che nei messaggi di posta elettronica la parola you è molto più frequente della parola remove.
Anche i tracciati di correlazione sono interessanti. Per creare un tracciato:
- Per Type (Tipo), selezionare Correlation (Correlazione).
- Seleziona Execute.
- Rattle avvisa l'utente che è consigliabile usare un massimo di 40 variabili. Scegliere Yes (Sì) per visualizzare il tracciato.
Vengono evidenziate alcune correlazioni interessanti. Ad esempio, la parola technology è strettamente correlata a HP e labs. È strettamente correlata anche a 650, perché l'indicativo di località dei donatori di set di dati è 650.
I valori numerici per le correlazioni tra le parole sono disponibili nella finestra Explore (Esplora). È interessante notare, ad esempio, che la parola technology è correlata negativamente a your e money.
Rattle può trasformare il set di dati per gestire alcuni problemi comuni. Ad esempio, può ridimensionare le funzionalità, attribuire valori mancanti, gestire gli outlier e rimuovere variabili o osservazioni con dati mancanti. Rattle può anche identificare le regole di associazione tra le osservazioni e le variabili. Queste schede non rientrano nell'ambito di questa procedura dettagliata introduttiva.
Rattle può anche eseguire l'analisi dei cluster. Escludere ora alcune funzionalità per migliorare la leggibilità dell'output. Nella scheda Data (Dati) selezionare Ignore (Ignora) accanto a ogni variabile, a eccezione di questi 10 elementi:
- word_freq_hp
- word_freq_technology
- word_freq_george
- word_freq_remove
- word_freq_your
- word_freq_dollar
- word_freq_money
- capital_run_length_longest
- word_freq_business
- posta indesiderata
Tornare alla scheda Cluster. Selezionare KMeans, quindi impostare Number of clusters (Numero di cluster) su 4. Seleziona Execute. I risultati verranno visualizzati nella finestra di output. Un cluster ha una frequenza elevata di george e hp ed è probabilmente un messaggio di lavoro legittimo.
Per creare un modello di Machine Learning con albero delle decisioni:
- Scegliere la scheda Model (Modello).
- Per Type (Tipo), selezionare Tree (Albero).
- Selezionare Execute (Esegui) per visualizzare l'albero in formato testo nella finestra di output.
- Fare clic sul pulsante Draw (Disegna) per visualizzarne una versione grafica. L'albero delle decisioni è simile all'albero ottenuto in precedenza con rpart.
Una funzionalità interessante di Rattle è la possibilità di eseguire diversi metodi di Machine Learning e valutarli rapidamente. Di seguito sono riportati i passaggi necessari:
- Per Type (Tipo), selezionare All (Tutti).
- Seleziona Execute.
- Al termine dell'esecuzione di Rattle, è possibile selezionare qualsiasi valore per Type (Tipo), ad esempio SVM, e visualizzare i risultati.
- È anche possibile confrontare le prestazioni dei modelli nel set di convalida usando la scheda Evaluate (Valuta). Ad esempio, la selezione Error Matrix (Matrice degli errori) mostra la matrice di confusione, l'errore generale e l'errore medio di classe per ogni modello nel set di convalida. È anche possibile tracciare le curve ROC, eseguire analisi di sensibilità e altri tipi di valutazioni del modello.
Al termine della compilazione dei modelli, selezionare la scheda Log per visualizzare il codice R eseguito da Rattle durante la sessione. Per salvarlo, è possibile usare il pulsante Export (Esporta).
Nota
La versione corrente di Rattle contiene un bug. Per modificare lo script o usarlo per ripetere la procedura in un secondo momento, è necessario anteporre un carattere # a Export this log ...* (Esporta questo log) nel testo del log.
PostgreSQL e SQuirrel SQL
La DSVM viene fornita con PostgreSQL installato. PostgreSQL è un sofisticato database relazionale open source. Questa sezione illustra come eseguire query sul set di dati spambase dopo averlo caricato in PostgreSQL.
Prima di caricare i dati, è necessario consentire l'autenticazione della password da localhost. Al prompt dei comandi eseguire:
sudo gedit /var/lib/pgsql/data/pg_hba.conf
Verso la fine del file di configurazione sono presenti diverse righe con informazioni dettagliate sulle connessioni consentite:
# "local" is only for Unix domain socket connections:
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 ident
# IPv6 local connections:
host all all ::1/128 ident
Modificare la riga IPv4 local connections per l'uso di md5 anziché ident, in modo da poter eseguire l'accesso con un nome utente e una password:
# IPv4 local connections:
host all all 127.0.0.1/32 md5
Riavviare quindi il servizio PostgreSQL:
sudo systemctl restart postgresql
Per avviare come utente postgres predefinito psql, un terminale interattivo per PostgreSQL, eseguire questo comando:
sudo -u postgres psql
Creare un nuovo account utente con il nome utente dell'account Linux usato per l'accesso. Creare una password:
CREATE USER <username> WITH CREATEDB;
CREATE DATABASE <username>;
ALTER USER <username> password '<password>';
\quit
Accedere a psql:
psql
Importare i dati in un nuovo database:
CREATE DATABASE spam;
\c spam
CREATE TABLE data (word_freq_make real, word_freq_address real, word_freq_all real, word_freq_3d real,word_freq_our real, word_freq_over real, word_freq_remove real, word_freq_internet real,word_freq_order real, word_freq_mail real, word_freq_receive real, word_freq_will real,word_freq_people real, word_freq_report real, word_freq_addresses real, word_freq_free real,word_freq_business real, word_freq_email real, word_freq_you real, word_freq_credit real,word_freq_your real, word_freq_font real, word_freq_000 real, word_freq_money real,word_freq_hp real, word_freq_hpl real, word_freq_george real, word_freq_650 real, word_freq_lab real,word_freq_labs real, word_freq_telnet real, word_freq_857 real, word_freq_data real,word_freq_415 real, word_freq_85 real, word_freq_technology real, word_freq_1999 real,word_freq_parts real, word_freq_pm real, word_freq_direct real, word_freq_cs real, word_freq_meeting real,word_freq_original real, word_freq_project real, word_freq_re real, word_freq_edu real,word_freq_table real, word_freq_conference real, char_freq_semicolon real, char_freq_leftParen real,char_freq_leftBracket real, char_freq_exclamation real, char_freq_dollar real, char_freq_pound real, capital_run_length_average real, capital_run_length_longest real, capital_run_length_total real, spam integer);
\copy data FROM /home/<username>/spambase.data DELIMITER ',' CSV;
\quit
Si passa ora all'elaborazione dei dati e all'esecuzione di query con SQuirrel SQL, uno strumento grafico che può essere usato per interagire con i database tramite un driver JDBC.
Per iniziare, aprire SQuirrel SQL dal menu Applications (Applicazioni). Per configurare il driver:
- Selezionare Windows>View Drivers (Visualizza driver).
- Fare clic con il pulsante destro del mouse su PostgreSQL e scegliere Modify Driver (Modifica driver).
- Selezionare Extra Class Path (Percorso classe extra)>Add (Aggiungi).
- Per File Name (Nome file), immettere /usr/share/java/jdbcdrivers/postgresql-9.4.1208.jre6.jar.
- Selezionare Apri.
- Selezionare List Drivers (Elenca driver). Per Class Name (Nome classe), selezionare org.postgresql.Driver e quindi scegliere OK.
Per configurare la connessione al server locale:
- Selezionare Windows>View Aliases (Visualizza alias).
- Scegliere il pulsante + per creare un nuovo alias. Per il nuovo nome alias, immettere Spam database.
- Per Driver, selezionare PostgreSQL.
- Impostare l'URL su jdbc:postgresql://localhost/spam.
- Immettere nome utente e password.
- Seleziona OK.
- Per aprire la finestra Connection (Connessione), fare doppio clic sull'alias Spam database (Database di posta indesiderata).
- Selezionare Connetti.
Per eseguire alcune query:
- Selezionare la scheda SQL .
- Nella casella di query nella parte superiore della scheda SQL immettere una query di base, ad esempio
SELECT * from data;. - Premere CTRL+INVIO per eseguire la query. Per impostazione predefinita, SQuirrel SQL restituisce le prime 100 righe della query.
È possibile eseguire molte altre query per esplorare questi dati. Ad esempio, in cosa differisce la frequenza della parola make tra posta indesiderata e non indesiderata?
SELECT avg(word_freq_make), spam from data group by spam;
Oppure, quali sono le caratteristiche dei messaggi di posta elettronica che contengono spesso 3d?
SELECT * from data order by word_freq_3d desc;
La maggior parte dei messaggi di posta elettronica con un'occorrenza elevata di 3d risulta essere apparentemente posta indesiderata. Queste informazioni possono essere utili per la creazione di un modello predittivo per la classificazione dei messaggi di posta elettronica.
Se si desidera eseguire operazioni di Machine Learning con dati archiviati in un database PostgreSQL, è consigliabile usare MADlib.
Azure Synapse Analytics (in precedenza SQL DW)
Azure Synapse Analytics è un database scale-out basato su cloud, con possibilità di aumentare il numero di istanze, che può elaborare ingenti volumi di dati relazionali e non relazionali. Per altre informazioni, vedere Informazioni su Azure Synapse Analytics.
Per connettersi al data warehouse e creare la tabella, eseguire questo comando al prompt dei comandi:
sqlcmd -S <server-name>.database.windows.net -d <database-name> -U <username> -P <password> -I
Al prompt di sqlcmd eseguire questo comando:
CREATE TABLE spam (word_freq_make real, word_freq_address real, word_freq_all real, word_freq_3d real,word_freq_our real, word_freq_over real, word_freq_remove real, word_freq_internet real,word_freq_order real, word_freq_mail real, word_freq_receive real, word_freq_will real,word_freq_people real, word_freq_report real, word_freq_addresses real, word_freq_free real,word_freq_business real, word_freq_email real, word_freq_you real, word_freq_credit real,word_freq_your real, word_freq_font real, word_freq_000 real, word_freq_money real,word_freq_hp real, word_freq_hpl real, word_freq_george real, word_freq_650 real, word_freq_lab real,word_freq_labs real, word_freq_telnet real, word_freq_857 real, word_freq_data real,word_freq_415 real, word_freq_85 real, word_freq_technology real, word_freq_1999 real,word_freq_parts real, word_freq_pm real, word_freq_direct real, word_freq_cs real, word_freq_meeting real,word_freq_original real, word_freq_project real, word_freq_re real, word_freq_edu real,word_freq_table real, word_freq_conference real, char_freq_semicolon real, char_freq_leftParen real,char_freq_leftBracket real, char_freq_exclamation real, char_freq_dollar real, char_freq_pound real, capital_run_length_average real, capital_run_length_longest real, capital_run_length_total real, spam integer) WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = ROUND_ROBIN);
GO
Copiare i dati usando bcp:
bcp spam in spambaseHeaders.data -q -c -t ',' -S <server-name>.database.windows.net -d <database-name> -U <username> -P <password> -F 1 -r "\r\n"
Nota
Il file scaricato contiene terminazioni riga di tipo Windows. Lo strumento bcp prevede terminazioni riga di tipo Unix. Usare il flag -r per indicare bcp.
Eseguire quindi una query usando sqlcmd:
select top 10 spam, char_freq_dollar from spam;
GO
È anche possibile eseguire query usando SQuirreL SQL. Seguire le procedure come per PostgreSQL usando il driver JDBC di SQL Server. Il driver JDBC si trova nella cartella /usr/share/java/jdbcdrivers/sqljdbc42.jar.