Configurare AutoML per eseguire il training di un modello di previsione di serie temporali con SDK e interfaccia della riga di comando
SI APPLICA A: Estensione per Machine Learning dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione per Machine Learning dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Questo articolo descrive come configurare AutoML per la previsione di serie temporali con Machine Learning automatizzato di Azure Machine Learning in Azure Machine Learning Python SDK.
A tale scopo, è necessario:
- Preparare i dati per il training.
- Configurare parametri specifici della serie temporale in un processo di previsione.
- Orchestrare il training, l'inferenza e la valutazione del modello usando componenti e pipeline.
Per un'esperienza con poco codice, vedere l'Esercitazione: Prevedere la domanda con Machine Learning automatizzato per un esempio di previsione di serie temporali usando Machine Learning automatizzato nello studio di Azure Machine Learning.
AutoML usa modelli di Machine Learning standard insieme a modelli di serie temporali noti per creare previsioni. L'approccio usato incorpora informazioni cronologiche sulla variabile di destinazione, le funzionalità fornite dall'utente nei dati di input e le funzionalità compilate automaticamente. Gli algoritmi di ricerca dei modelli si attivano quindi per trovare un modello con la migliore accuratezza predittiva. Per altre informazioni, vedere gli articoli sulla metodologia di previsione e sulla ricerca di modelli.
Prerequisiti
Per questo articolo sono necessari:
Un'area di lavoro di Azure Machine Learning. Per creare l'area di lavoro, vedere Creare risorse dell'area di lavoro.
Possibilità di avviare processi di training di AutoML. Per informazioni dettagliate, seguire la Guida pratica per configurare AutoML.
Dati di training e convalida
I dati di input per la previsione di AutoML devono contenere serie temporali valide in formato tabulare. Ogni variabile deve avere una propria colonna corrispondente nella tabella dati. AutoML richiede almeno due colonne: una colonna temporale che rappresenta l'asse temporale e la colonna di destinazione che rappresenta la quantità da prevedere. Altre colonne possono fungere da predittori. Per altri dettagli, vedere Modo in cui AutoML usa i dati.
Importante
Quando si esegue il training di un modello per la previsione di valori futuri, assicurarsi che tutte le funzionalità usate nel training possano essere usate quando si eseguono stime per l'orizzonte previsto.
Ad esempio, una funzionalità per il prezzo azionario corrente potrebbe aumentare notevolmente l'accuratezza del training. Se, tuttavia, si vogliono effettuare previsioni con un orizzonte lungo, potrebbe non essere possibile stimare in modo accurato i valori dei titoli azionari futuri corrispondenti ai punti futuri della serie temporale e l'accuratezza del modello potrebbe risentirne.
I processi di previsione di AutoML richiedono che i dati di training siano rappresentati come oggetto MLTable. Un oggetto MLTable specifica un'origine dati e i passaggi per il caricamento dei dati. Per altre informazioni e casi d'uso, vedere la Guida pratica per MLTable. Come esempio semplice, si supponga che i dati di training si trovino in un file CSV in una directory locale, ./train_data/timeseries_train.csv.
È possibile creare un oggetto MLTable usando mltable Python SDK, come illustrato nell'esempio seguente:
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
Questo codice crea un nuovo file, ./train_data/MLTable, che contiene il formato di file e le istruzioni di caricamento.
A questo punto si definisce un oggetto dati di input, necessario per avviare un processo di training, usando Azure Machine Learning Python SDK come indicato di seguito:
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
I dati di convalida vengono specificati in modo analogo, creando un oggetto MLTable e specificando un input di dati di convalida. In alternativa, se non si forniscono dati di convalida, AutoML crea automaticamente divisioni di convalida incrociata dai dati di training da usare per la selezione del modello. Per altri dettagli, vedere l'articolo sullaselezione del modello di previsione. Vedere anche i requisiti di lunghezza dei dati di training per informazioni dettagliate sulla quantità di dati di training necessari per eseguire correttamente il training di un modello di previsione.
Altre informazioni sul modo in cui il AutoML applica la convalida incrociata per impedire l'overfitting.
Calcolo per eseguire l'esperimento
AutoML usa l'ambiente di calcolo di Azure Machine Learning, ovvero una risorsa di calcolo completamente gestita, per eseguire il processo di training. Nell'esempio seguente viene creato un cluster di calcolo denominato cpu-compute:
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()Configurare l'esperimento
Usare le funzioni di factory automl per configurare i processi di previsione in Python SDK. L'esempio seguente illustra come creare un processo di previsione impostando la metrica primaria e impostando i limiti per l'esecuzione del training:
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
Impostazioni del processo di previsione
Le attività di previsione hanno molte impostazioni specifiche per la previsione. Le impostazioni più semplici sono il nome della colonna temporale nei dati di training e l'orizzonte di previsione.
Usare i metodi di ForecastingJob per configurare queste impostazioni:
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
Il nome della colonna temporale è un'impostazione obbligatoria e in genere è consigliabile impostare l'orizzonte di previsione in base allo scenario di previsione. Se i dati contengono più serie temporali, è possibile specificare i nomi delle colonne ID di serie temporali. Queste colonne, se raggruppate, definiscono le singole serie. Si supponga, ad esempio, di avere dati costituiti da vendite orarie da negozi e marchi diversi. L'esempio seguente illustra come impostare le colonne ID di serie temporali presupponendo che i dati contengano colonne denominate "store" e "brand":
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
AutoML prova a rilevare automaticamente le colonne ID di serie temporali nei dati, se non sono specificate.
Altre impostazioni sono facoltative e vengono esaminate nella sezione successiva.
Impostazioni facoltative del processo di previsione
Sono disponibili configurazioni facoltative per le attività di previsione, ad esempio l'abilitazione del Deep Learning e la specifica di un'aggregazione di finestra mobile di destinazione. Un elenco completo dei parametri è disponibile nella documentazione di riferimento per la previsione.
Impostazioni di ricerca del modello
Esistono due impostazioni facoltative che controllano lo spazio del modello in cui AutoML cerca il modello migliore, allowed_training_algorithms e blocked_training_algorithms. Per limitare lo spazio di ricerca a un determinato set di classi di modelli, usare il parametro allowed_training_algorithms, come illustrato nell'esempio seguente:
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
In questo caso, il processo di previsione esegue ricerche solo su classi Exponential Smoothing ed Elastic Net dei modelli. Per rimuovere un determinato set di classi di modelli dallo spazio di ricerca, usare blocked_training_algorithms, come illustrato nell'esempio seguente:
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
Il processo esegue ora la ricerca in tutte le classi di modelli tranne Prophet. Per un elenco dei nomi dei modelli di previsione accettati in allowed_training_algorithms e blocked_training_algorithms, vedere la documentazione di riferimento sulle proprietà di training. È possibile applicare allowed_training_algorithms o blocked_training_algorithms a un'esecuzione di training, ma non entrambi.
Abilita Deep Learning
AutoML include un modello di rete neurale profonda personalizzato denominato TCNForecaster. Questo modello è unarete convoluzionale temporale, o TCN (Temporal Convolutional Network), che applica i metodi comuni delle attività di creazione dell'immagine alla modellazione delle serie temporali, ovvero le convoluzioni "causali" unidimensionali formano la struttura portante della rete e consentono al modello di apprendere criteri complessi in periodi di tempo prolungati nella cronologia del training. Per altri dettagli, vedere l'articolo su TCNForecaster.
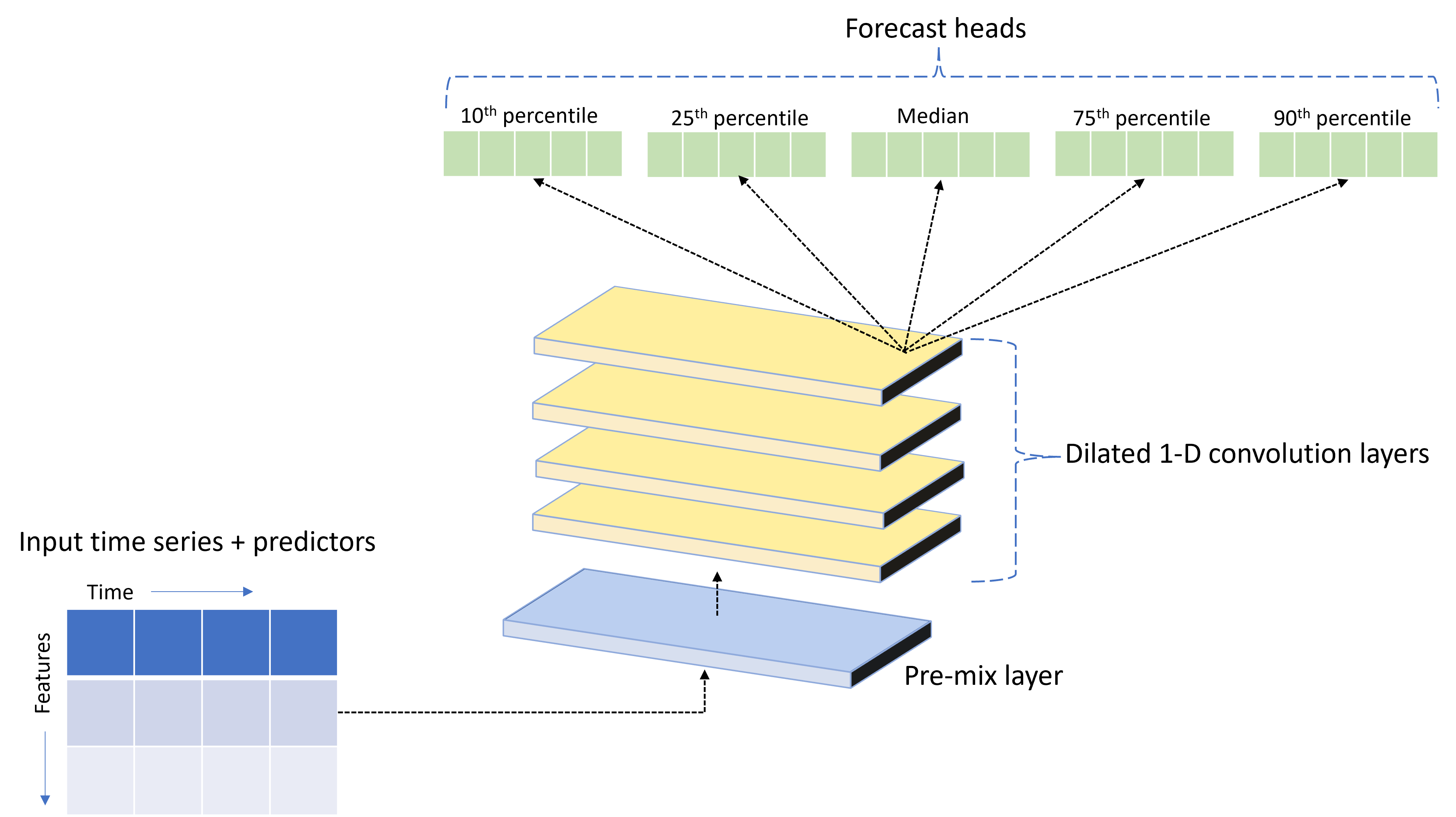
TCNForecaster ottiene spesso un'accuratezza superiore rispetto ai modelli di serie temporali standard quando sono presenti migliaia o anche più osservazioni nella cronologia di training. Il training e lo sweep dei modelli TCNForecaster richiedono tuttavia più tempo a causa della capacità più elevata.
È possibile abilitare TCNForecaster in AutoML impostando il flag enable_dnn_training nella configurazione di training come indicato di seguito:
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
Per impostazione predefinita, il training di TCNForecaster è limitato a un singolo nodo di calcolo e a una singola GPU, se disponibile, per ogni prova del modello. Per scenari di dati di grandi dimensioni, è consigliabile distribuire ogni prova di TCNForecaster su più core/GPU e nodi. Per altre informazioni ed esempi di codice, vedere la sezione dell'articolo relativo al training distribuito.
Per abilitare la rete neurale profonda per un esperimento di AutoML creato nello studio di Azure Machine Learning, vedere le impostazioni del tipo di attività nella procedura per l'interfaccia utente di studio.
Nota
- Quando si abilita la rete neurale profonda per gli esperimenti creati con l'SDK, le spiegazioni del modello migliori sono disabilitate.
- Il supporto della rete neurale profonda per la previsione in Machine Learning automatizzato non è disponibile per le esecuzioni avviate in Databricks.
- I tipi di calcolo della GPU sono consigliati quando è abilitato il training della rete neurale profonda
Funzionalità di ritardo e finestra mobile
I valori recenti della destinazione sono spesso funzionalità rilevanti in un modello di previsione. Di conseguenza, AutoML può creare funzionalità di aggregazione con ritardo e finestra mobile per migliorare potenzialmente l'accuratezza del modello.
Si consideri uno scenario di previsione della domanda energetica in cui sono disponibili i dati meteo e la domanda cronologica. La tabella mostra la progettazione della funzionalità risultante che si verifica quando l'aggregazione delle finestre viene applicata nelle ultime tre ore. Le colonne per i valori minimo, massimo e somma vengono generate in una finestra temporale scorrevole di tre ore in base alle impostazioni definite. Ad esempio, per l'osservazione valida l'8 settembre 2017 alle ore 4:00, i valori massimo, minimo e somma vengono calcolati usando i valori della domanda per l'8 settembre 2017 tra l'1:00 e le 3:00. Questa finestra di tre ore scorre in avanti per popolare i dati per le righe rimanenti. Per altri dettagli ed esempi, vedere l'articolo relativo alla funzionalità di ritardo.

È possibile abilitare le funzionalità di aggregazione di ritardo e finestra mobile per la destinazione impostando le dimensioni della finestra mobile, che corrispondevano a tre nell'esempio precedente, e gli ordini di ritardo da creare. È anche possibile abilitare i ritardi per le funzionalità con l'impostazione feature_lags. Nell'esempio seguente tutte queste impostazioni vengono impostate su auto in modo che AutoML possa determinare automaticamente le impostazioni analizzando la struttura di correlazione dei dati:
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
Gestione di serie brevi
Machine Learning automatizzato considera una serie temporale come una serie breve se non sono presenti punti dati sufficienti per eseguire le fasi di training e convalida dello sviluppo di modelli. Per altre informazioni sui requisiti di lunghezza, vedere Requisiti di lunghezza dei dati di training.
AutoML include diverse azioni che possono essere eseguite per serie brevi. Queste azioni sono configurabili con l'impostazione short_series_handling_config. Il valore predefinito è "auto". La tabella seguente descrive le impostazioni:
| Impostazione | Descrizione |
|---|---|
auto |
Valore predefinito per la gestione di serie brevi. - Se tutte le serie sono brevi, eseguire il riempimento dei dati. - Se non tutte le serie sono brevi, eliminare le serie brevi. |
pad |
Se short_series_handling_config = pad, Machine Learning automatizzato aggiunge valori casuali a ogni serie breve trovata. Di seguito sono elencati i tipi di colonna e gli elementi con cui vengono riempiti: - Colonne oggetto con valori "non un numero" - Colonne numeriche con 0 - Colonne booleane/logiche con False - La colonna di destinazione viene riempita con rumore bianco. |
drop |
Se short_series_handling_config = drop, Machine Learning automatizzato elimina la serie breve e non verrà usata per il training o la previsione. Le previsioni per queste serie restituiranno non un numero (NaN). |
None |
Nessuna serie viene riempita o eliminata |
Nell'esempio seguente viene impostata la gestione delle serie brevi in modo che tutte le serie brevi vengano riempite fino alla lunghezza minima:
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
Avviso
Il riempimento può influire sull'accuratezza del modello risultante, poiché vengono introdotti dati artificiali per evitare errori di training. Se molte delle serie sono brevi, si potrebbe anche notare un certo impatto nei risultati esplicativi
Frequenza e aggregazione dei dati di destinazione
Usare le opzioni di frequenza e aggregazione dei dati per evitare errori causati da dati irregolari. I dati sono irregolari se non seguono una cadenza impostata nel tempo, ad esempio ogni ora oppure ogni giorno. I dati POS (Point Of Sale) sono un buon esempio di dati irregolari. In questi casi AutoML può aggregare i dati a una frequenza desiderata e quindi creare un modello di previsione dalle aggregazioni.
È necessario configurare le impostazioni frequency e target_aggregate_function per gestire i dati irregolari. L'impostazione della frequenza accetta stringhe DateOffset Pandas come input. I valori supportati per la funzione di aggregazione sono:
| Funzione | Descrizione |
|---|---|
sum |
Somma dei valori di destinazione |
mean |
Media dei valori di destinazione |
min |
Valore minimo di una destinazione |
max |
Valore massimo di una destinazione |
- I valori delle colonne di destinazione vengono aggregati in base all'operazione specificata. La somma è in genere appropriata per la maggior parte degli scenari.
- Le colonne del predittore numerico nei dati vengono aggregate per somma, media, valore minimo e valore massimo. Di conseguenza, Machine Learning automatizzato genera nuove colonne che hanno come suffisso il nome della funzione di aggregazione e applica l'operazione di aggregazione selezionata.
- Per le colonne del predittore categorico, i dati vengono aggregati in base alla modalità, la categoria più importante nella finestra.
- Le colonne del predittore di data vengono aggregate in base al valore minimo, al valore massimo e alla modalità.
L'esempio seguente imposta la frequenza su oraria e la funzione di aggregazione su somma:
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
Impostazioni di convalida incrociata personalizzate
Esistono due impostazioni personalizzabili che controllano la convalida incrociata per i processi di previsione: il numero di riduzioni, n_cross_validations, e le dimensioni del passaggio che definiscono l'offset di tempo tra le riduzioni, cv_step_size. Per altre informazioni sul significato di questi parametri, vedere Selezione del modello di previsione. Per impostazione predefinita, AutoML configura automaticamente entrambe le impostazioni in base alle caratteristiche dei dati, ma è possibile che gli utenti avanzati le vogliano configurare manualmente. Si supponga, ad esempio, di avere dati di vendita giornalieri e di volere che la configurazione della convalida sia costituita da cinque riduzioni con un offset di sette giorni tra le riduzioni adiacenti. L'esempio di codice seguente illustra come impostare questi elementi:
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
Definizione delle funzionalità personalizzata
Per impostazione predefinita, AutoML aumenta i dati di training con funzionalità ingegnerizzate per incrementare l'accuratezza dei modelli. Per altre informazioni, vedere Progettazione automatizzata delle funzionalità. Alcuni dei passaggi di pre-elaborazione possono essere personalizzati usando la configurazione della definizione delle funzionalità del processo di previsione.
Le personalizzazioni supportate per la previsione sono riportate nella tabella seguente:
| Personalizzazione | Descrizione | Opzioni |
|---|---|---|
| Aggiornamento dello scopo della colonna | Esegue l'override del tipo di funzionalità rilevato automaticamente per la colonna specificata. | "Categorical", "DateTime", "Numeric" |
| Aggiornamento dei parametri del trasformatore | Aggiorna i parametri per l'imputer specificato. | {"strategy": "constant", "fill_value": <value>}, {"strategy": "median"}, {"strategy": "ffill"} |
Si supponga, ad esempio, di avere uno scenario di domanda al dettaglio in cui i dati includono prezzi, un flag "on sale" e un tipo di prodotto. L'esempio seguente illustra come impostare tipi e imputer personalizzati per queste funzionalità:
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
Se si usa lo studio di Azure Machine Learning per l'esperimento, vedere Come usare la definizione delle funzionalità personalizzata nello studio.
Invio di un processo di previsione
Dopo aver configurato tutte le impostazioni, si avvia il processo di previsione come indicato di seguito:
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
Dopo l'invio del processo, AutoML effettuerà il provisioning delle risorse di calcolo, applicherà la definizione delle funzionalità e altri passaggi di preparazione ai dati di input, quindi inizierà a eseguire lo sweep dei modelli di previsione. Per altre informazioni, vedere gli articoli sulla metodologia di previsione e sulla ricerca di modelli.
Orchestrazione di training, inferenza e valutazione con componenti e pipeline
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza contratto di servizio, pertanto se ne sconsiglia l’uso per i carichi di lavoro in ambienti di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate.
Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Il flusso di lavoro di Machine Learning richiede probabilmente più del semplice training. L'inferenza o il recupero di previsioni del modello su dati più recenti e la valutazione dell'accuratezza del modello in un set di test con valori di destinazione noti sono altre attività comuni che è possibile orchestrare in AzureML insieme ai processi di training. Per supportare le attività di inferenza e valutazione, AzureML fornisce componenti, che sono parti di codice autonome che eseguono un passaggio in una pipeline di AzureML.
Nell'esempio seguente viene recuperato il codice del componente da un registro client:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
Viene quindi definita una funzione di factory che crea pipeline che orchestrano il training, l'inferenza e il calcolo delle metriche. Per altre informazioni sulle impostazioni di training, vedere la sezione Configurazione del training.
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
A questo punto si definiscono gli input dei dati di training e test, presupponendo che siano contenuti in cartelle locali, ./train_data e ./test_data:
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
Si costruisce infine la pipeline, si imposta l'ambiente di calcolo predefinito e si invia il processo:
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
Dopo l'invio, la pipeline esegue il training di AutoML, l'inferenza di valutazione in sequenza e il calcolo delle metriche. È possibile monitorare e controllare l'esecuzione nell'interfaccia utente dello studio. Al termine dell'esecuzione, le previsioni in sequenza e le metriche di valutazione possono essere scaricate nella directory di lavoro locale:
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
È quindi possibile trovare i risultati delle metriche in ./named-outputs/metrics_results/evaluationResult/metrics.json e le previsioni, in formato righe JSON, in ./named-outputs/rolling_fcst_result/inference_output_file.
Per altre informazioni sulla valutazione in sequenza, vedere l'articolo sulla valutazione del modello di previsione.
Previsione su larga scala: molti modelli
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza contratto di servizio, pertanto se ne sconsiglia l’uso per i carichi di lavoro in ambienti di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate.
Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
I numerosi componenti dei modelli in AutoML consentono di eseguire il training e gestire milioni di modelli in parallelo. Per altre informazioni sui concetti relativi all'approccio con molti modelli, vedere la sezione Molti modelli dell'articolo.
Configurazione del training con molti modelli
Il componente di training con molti modelli accetta un file di configurazione in formato YAML delle impostazioni di training di AutoML. Il componente applica queste impostazioni a ogni istanza di AutoML avviata. Questo file YAML ha la stessa specifica del Processo di previsione, oltre ai parametri aggiuntivi partition_column_names e allow_multi_partitions.
| Parametro | Descrizione |
|---|---|
| partition_column_names | Nomi di colonna nei dati che, se raggruppati, definiscono le partizioni di dati. Il componente di training con molti modelli avvia un processo di training indipendente in ogni partizione. |
| allow_multi_partitions | Flag facoltativo che consente il training di un modello per partizione quando ogni partizione contiene più di una serie temporale univoca. Il valore predefinito è Falso. |
L'esempio seguente fornisce un modello di configurazione:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
Negli esempi successivi si presuppone che la configurazione sia archiviata nel percorso ./automl_settings_mm.yml.
Pipeline con molti modelli
Viene quindi definita una funzione di factory che crea pipeline per l'orchestrazione del training con molti modelli, l'inferenza e il calcolo delle metriche. I parametri di questa funzione di factory sono descritti in dettaglio nella tabella seguente:
| Parametro | Descrizione |
|---|---|
| max_nodes | Numero di nodi di calcolo da usare nel processo di training |
| max_concurrency_per_node | Numero di processi di AutoML da eseguire in ogni nodo. Di conseguenza, la concorrenza totale di processi con molti modelli è max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Timeout del componente molti modelli specificato in numero di secondi. |
| retrain_failed_models | Flag per abilitare la ripetizione del training per i modelli non riusciti. Risulta utile se sono state eseguite in precedenza molte esecuzioni di modelli che hanno generato processi di AutoML non riusciti in alcune partizioni di dati. Quando questo flag è abilitato, molti modelli avviano solo i processi di training per le partizioni non riuscite in precedenza. |
| forecast_mode | Modalità di inferenza per la valutazione del modello. I valori validi sono "recursive" e "rolling". Per altre informazioni, vedere l'articolo sulla valutazione del modello. |
| forecast_step | Dimensioni del passaggio per la previsione in sequenza. Per altre informazioni, vedere l'articolo sulla valutazione del modello. |
L'esempio seguente illustra un metodo factory per costruire il training con molti modelli e le pipeline di valutazione del modello:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
A questo punto si costruisce la pipeline tramite la funzione di factory, presupponendo che i dati di training e test si trovino in cartelle locali, rispettivamente ./data/train e ./data/test. Si imposta infine l'ambiente di calcolo predefinito e si invia il processo come illustrato nell'esempio seguente:
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Al termine del processo, le metriche di valutazione possono essere scaricate in locale usando la stessa procedura della pipeline di esecuzione di training singola.
Per un esempio più dettagliato, vedere anche il notebook relativo alla previsione della domanda con molti modelli.
Nota
I componenti di training e inferenza con molti modelli partizionano in modo condizionale i dati in base all'impostazione partition_column_names in modo che ogni partizione si trovi nel proprio file. Questo processo può essere molto lento o presentare errori quando i dati sono molto grandi. In questo caso è consigliabile partizionare manualmente i dati prima di eseguire il training o l'inferenza con molti modelli.
Previsione su larga scala: serie temporale gerarchica
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza contratto di servizio, pertanto se ne sconsiglia l’uso per i carichi di lavoro in ambienti di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate.
Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
I componenti della serie temporale gerarchica (HTS, Hierarchical Time Series) in AutoML consentono di eseguire il training di un numero elevato di modelli sui dati con struttura gerarchica. Per altre informazioni, vedere la sezione relativa alla serie temporale gerarchica dell'articolo.
Configurazione del training della serie temporale gerarchica
Il componente di training con serie temporale gerarchica accetta un file di configurazione in formato YAML delle impostazioni di training di AutoML. Il componente applica queste impostazioni a ogni istanza di AutoML avviata. Questo file YAML ha la stessa specifica del Processo di previsione, oltre a parametri aggiuntivi correlati alle informazioni sulla gerarchia:
| Parametro | Descrizione |
|---|---|
| hierarchy_column_names | Elenco di nomi di colonna nei dati che definiscono la struttura gerarchica dei dati. L'ordine delle colonne in questo elenco determina i livelli della gerarchia. Il grado di aggregazione diminuisce con l'indice di elenco, ovvero l'ultima colonna nell'elenco definisce il livello foglia (più disaggregato) della gerarchia. |
| hierarchy_training_level | Livello gerarchia da usare per il training del modello di previsione. |
Di seguito è illustrata una configurazione di esempio:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
Negli esempi successivi si presuppone che la configurazione sia archiviata nel percorso ./automl_settings_hts.yml.
Pipeline della serie temporale gerarchica
Viene quindi definita una funzione di factory che crea pipeline per l'orchestrazione del training con serie temporale gerarchica, l'inferenza e il calcolo delle metriche. I parametri di questa funzione di factory sono descritti in dettaglio nella tabella seguente:
| Parametro | Descrizione |
|---|---|
| forecast_level | Livello della gerarchia per cui recuperare le previsioni |
| allocation_method | Metodo di allocazione da usare quando le previsioni sono disaggregate. I valori validi sono "proportions_of_historical_average" e "average_historical_proportions". |
| max_nodes | Numero di nodi di calcolo da usare nel processo di training |
| max_concurrency_per_node | Numero di processi di AutoML da eseguire in ogni nodo. Di conseguenza, la concorrenza totale di un processo di serie temporale gerarchica è max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Timeout del componente molti modelli specificato in numero di secondi. |
| forecast_mode | Modalità di inferenza per la valutazione del modello. I valori validi sono "recursive" e "rolling". Per altre informazioni, vedere l'articolo sulla valutazione del modello. |
| forecast_step | Dimensioni del passaggio per la previsione in sequenza. Per altre informazioni, vedere l'articolo sulla valutazione del modello. |
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
A questo punto si costruisce la pipeline tramite la funzione di factory, presupponendo che i dati di training e test si trovino in cartelle locali, rispettivamente ./data/train e ./data/test. Si imposta infine l'ambiente di calcolo predefinito e si invia il processo come illustrato nell'esempio seguente:
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Al termine del processo, le metriche di valutazione possono essere scaricate in locale usando la stessa procedura della pipeline di esecuzione di training singola.
Per un esempio più dettagliato, vedere anche il notebook relativo alla previsione della domanda con serie temporale gerarchica.
Nota
I componenti di training e inferenza con serie temporale gerarchica partizionano in modo condizionale i dati in base all'impostazione hierarchy_column_names in modo che ogni partizione si trovi nel proprio file. Questo processo può essere molto lento o presentare errori quando i dati sono molto grandi. In questo caso è consigliabile partizionare manualmente i dati prima di eseguire il training o l'inferenza con serie temporale gerarchica.
Previsione su larga scala: training distribuito con rete neurale profonda
- Per informazioni sul funzionamento del training distribuito per le attività di previsione, vedere l'articolo relativo alla previsione su larga scala.
- Per esempi di codice, vedere la sezione relativa alla configurazione del training distribuito per i dati tabulari dell'articolo.
Notebook di esempio
Per esempi di codice dettagliati sulla configurazione di previsione avanzata, vedere i notebook di esempio della previsione, tra cui:
- Esempi di pipeline di previsione della domanda
- Modelli di Deep Learning
- Rilevamento festività e definizione delle funzionalità
- Configurazione manuale per i ritardi e le funzionalità di aggregazione delle finestre mobili
Passaggi successivi
- Altre informazioni su Come distribuire un modello di Machine Learning automatizzato in un endpoint online.
- Informazioni sull'Interpretabilità: spiegazioni del modello in Machine Learning automatizzato (anteprima).
- Informazioni su Modalità con cui AutoML compila modelli di previsione.
- Informazioni sulle previsioni su larga scala.
- Informazioni su come Configurare AutoML per vari scenari di previsione.
- Informazioni su inferenza e valutazione dei modelli di previsione.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per